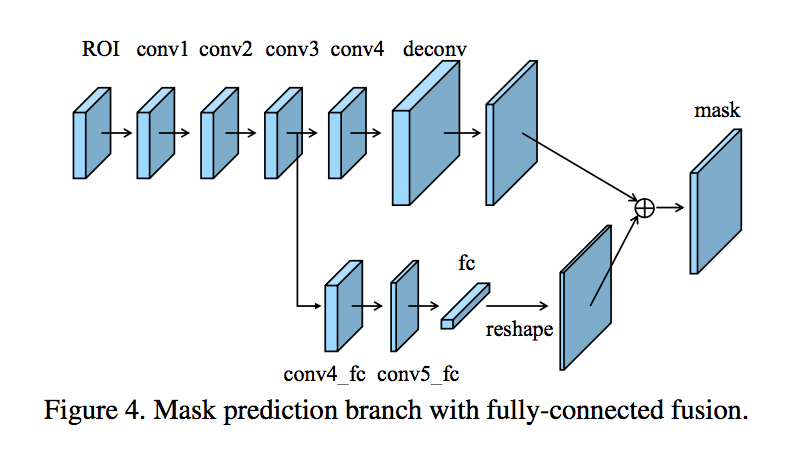
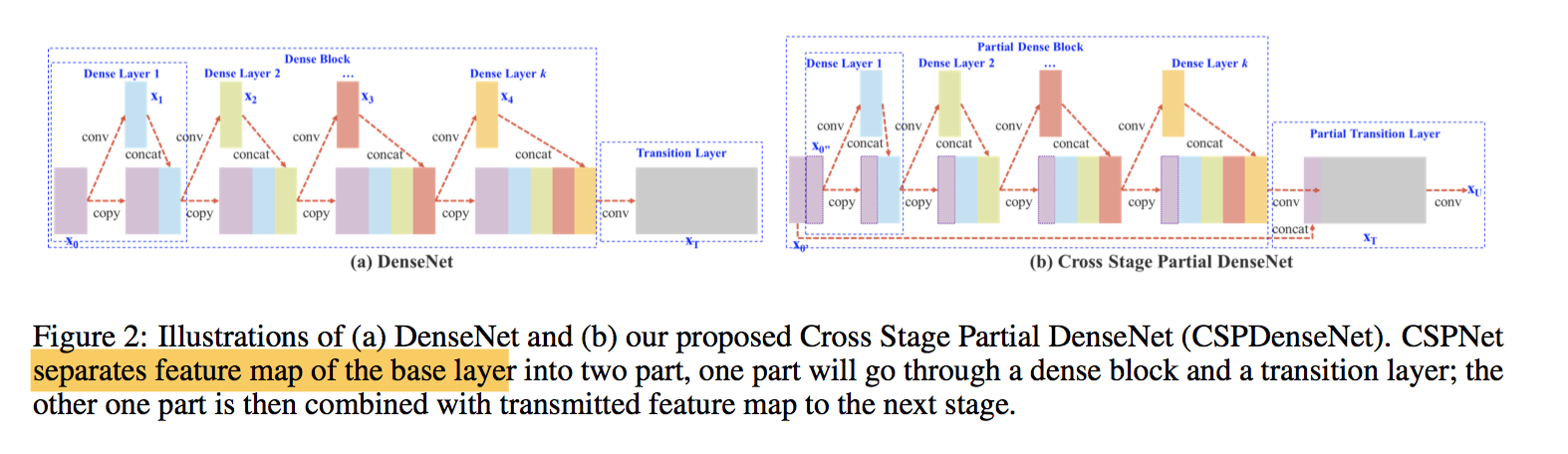
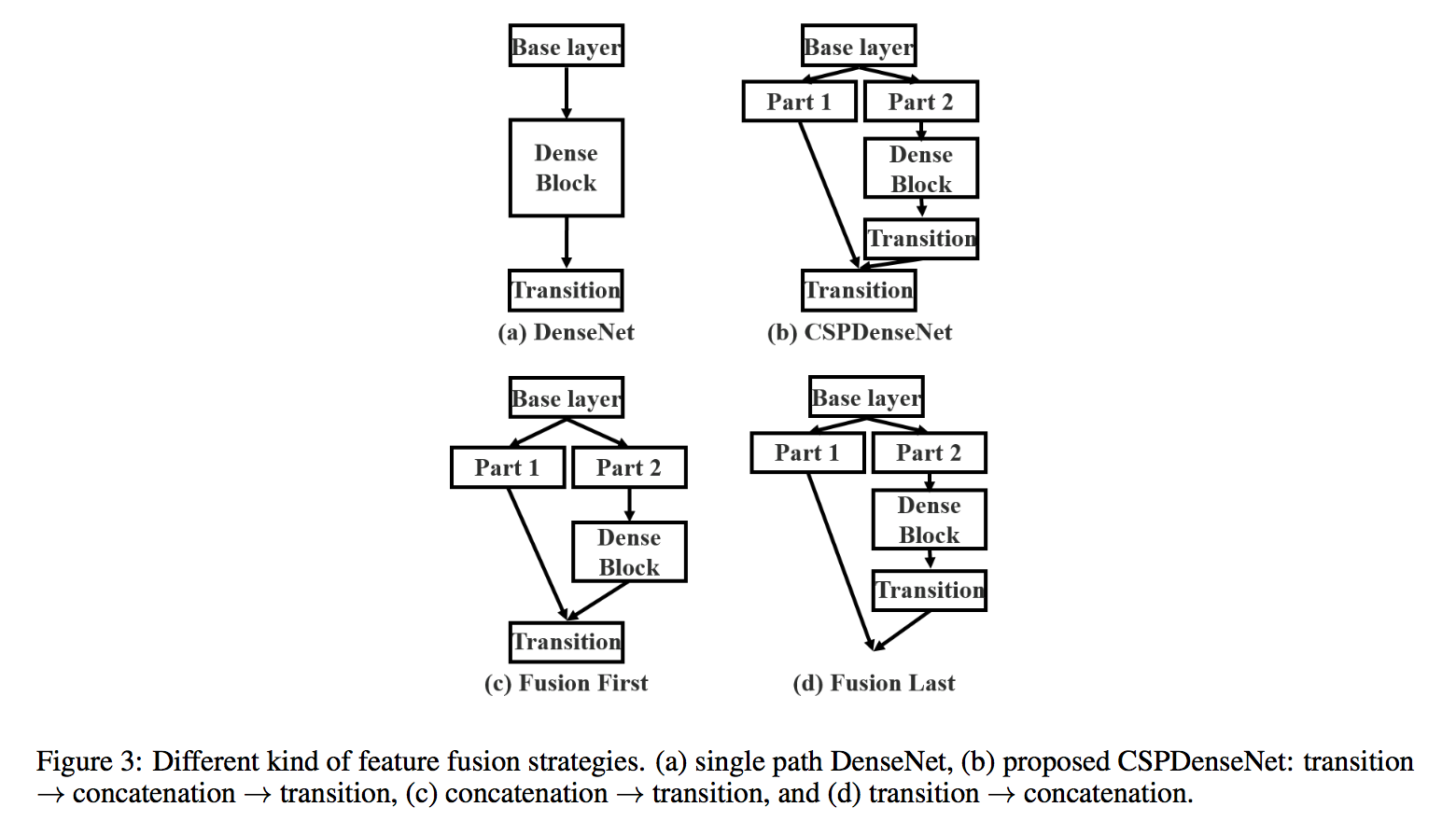
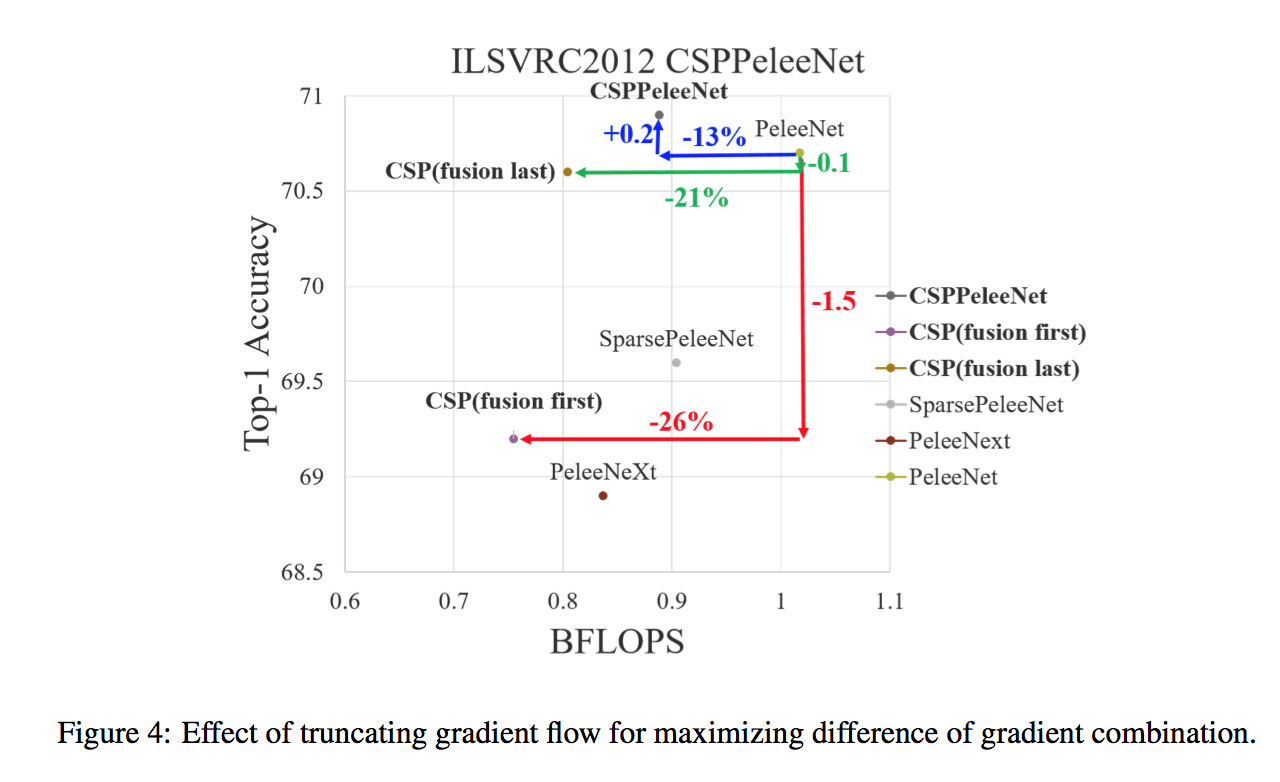
Corner Proposal Network for Anchor-free, Two-stage Object Detection
动机
- anchor-free
- two-stage
- 先找potential corner keypoints
- classify each proposal
- corner-based方法:对于objects of various scales有效,在训练中避免产生过多的冗余false-positive proposals,但是在结果上会出现更多的fp
- 得到的是competitive results
论点
- anchor-based methods对形状奇怪的目标容易漏检
anchor-free methods容易引入假阳caused by mistakely grouping
- thus an individual classifier is strongly required
Corner Proposal Network (CPN)
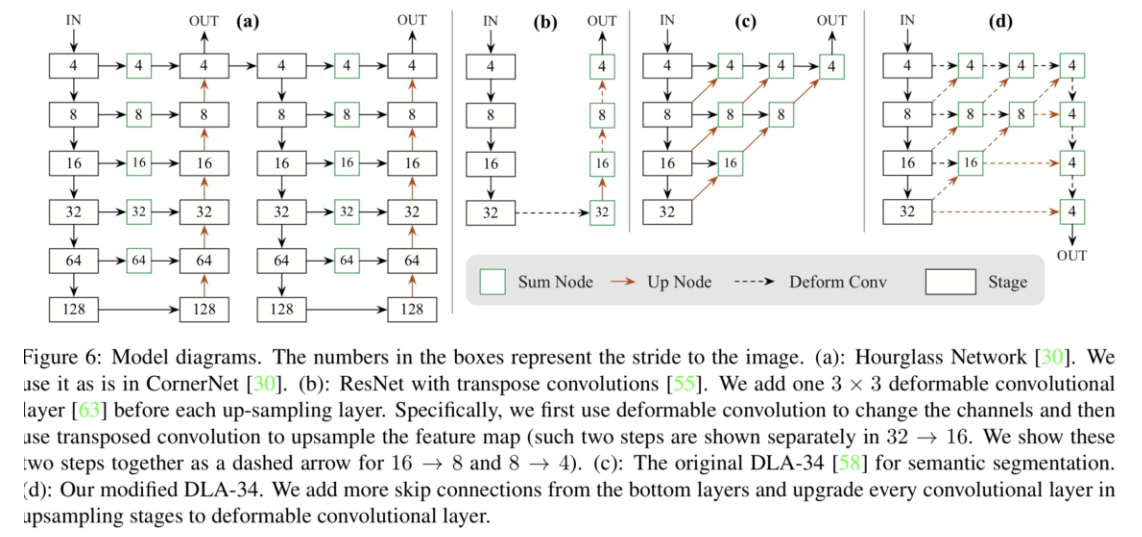
- use key-point detection in CornerNet
- 但是group阶段不再用embedding distance衡量,而是用a binary classifier
- 然后是multi-class classifier,operate on the survived objects
- 最后soft-NMS