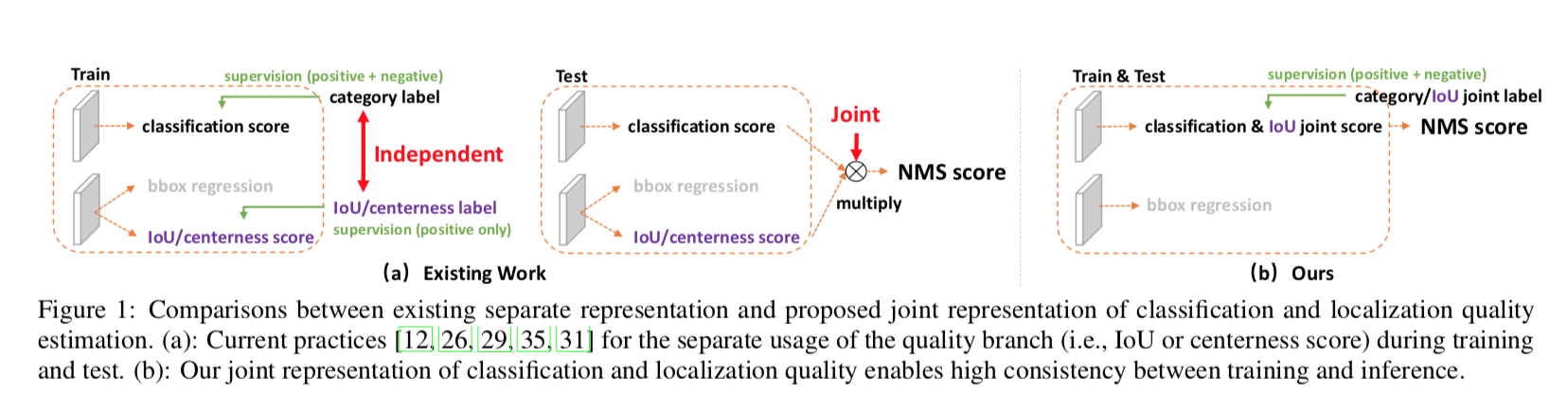
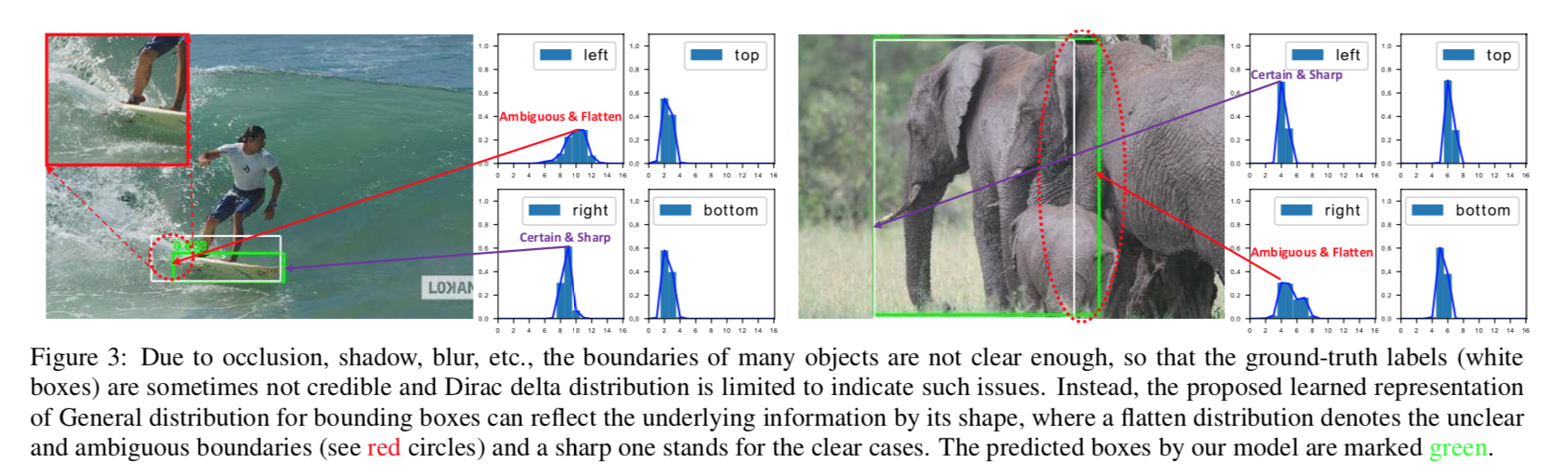
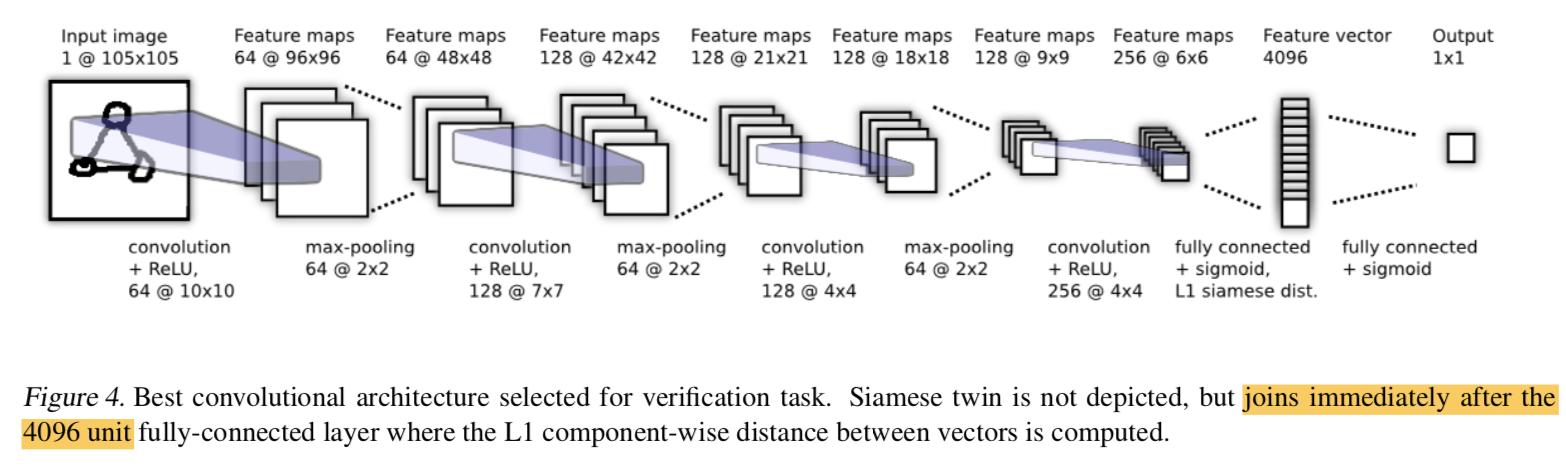
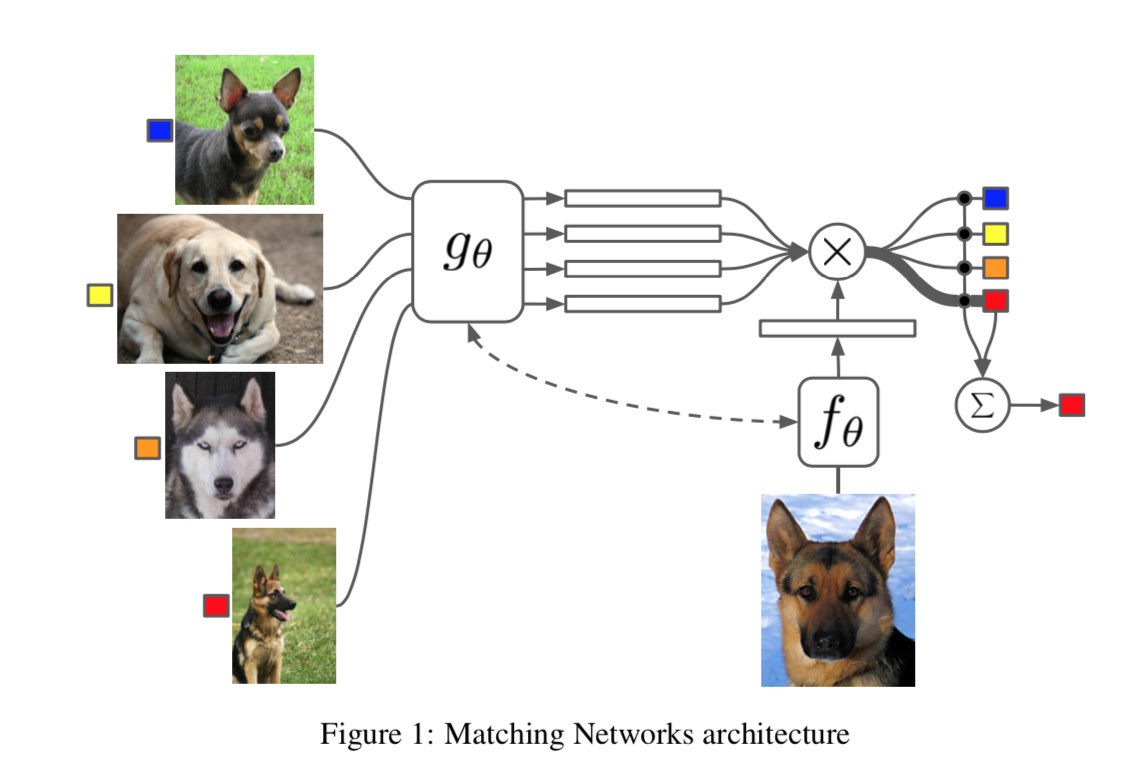
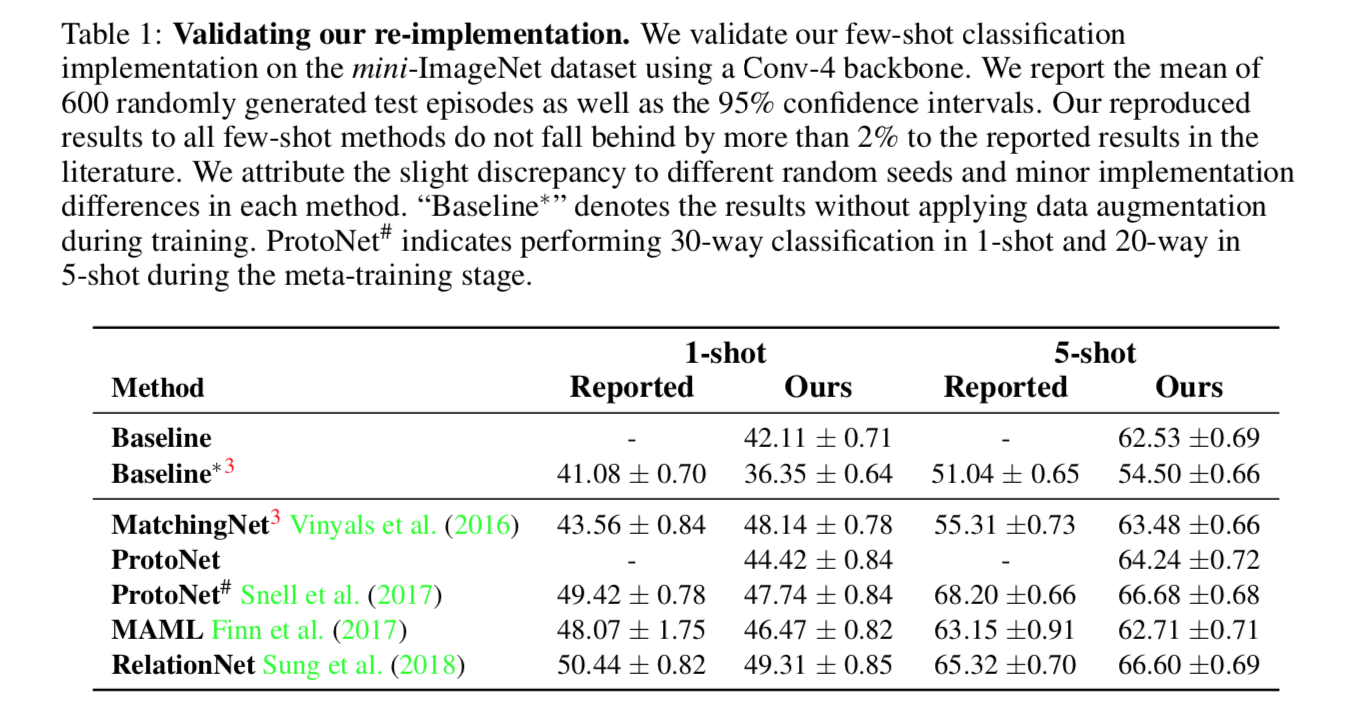
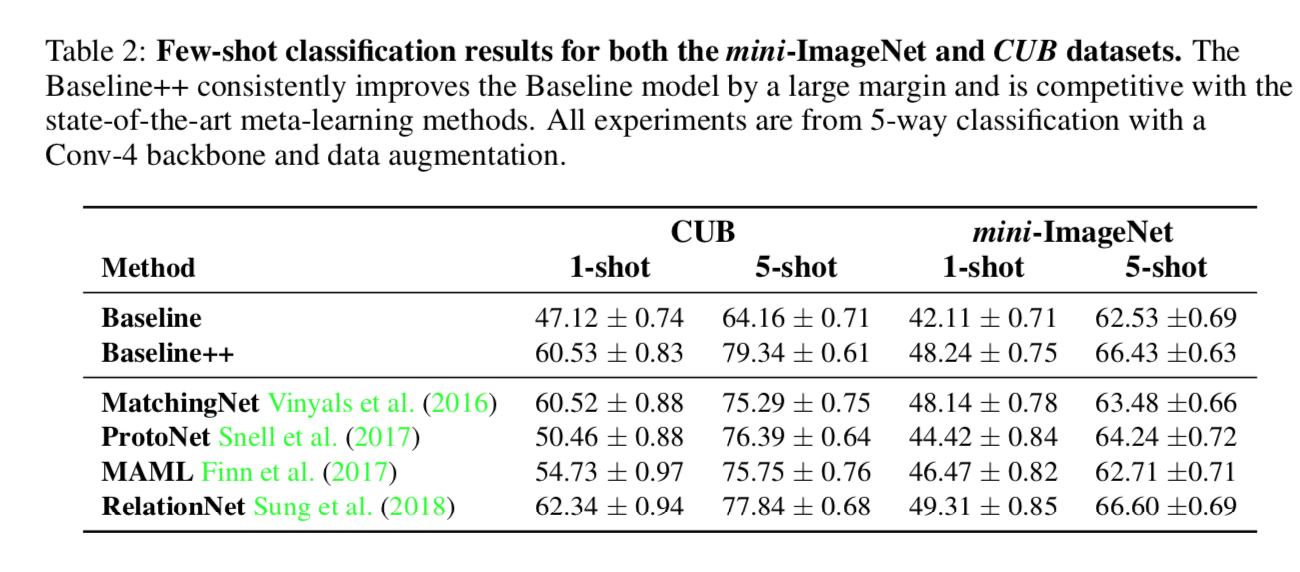
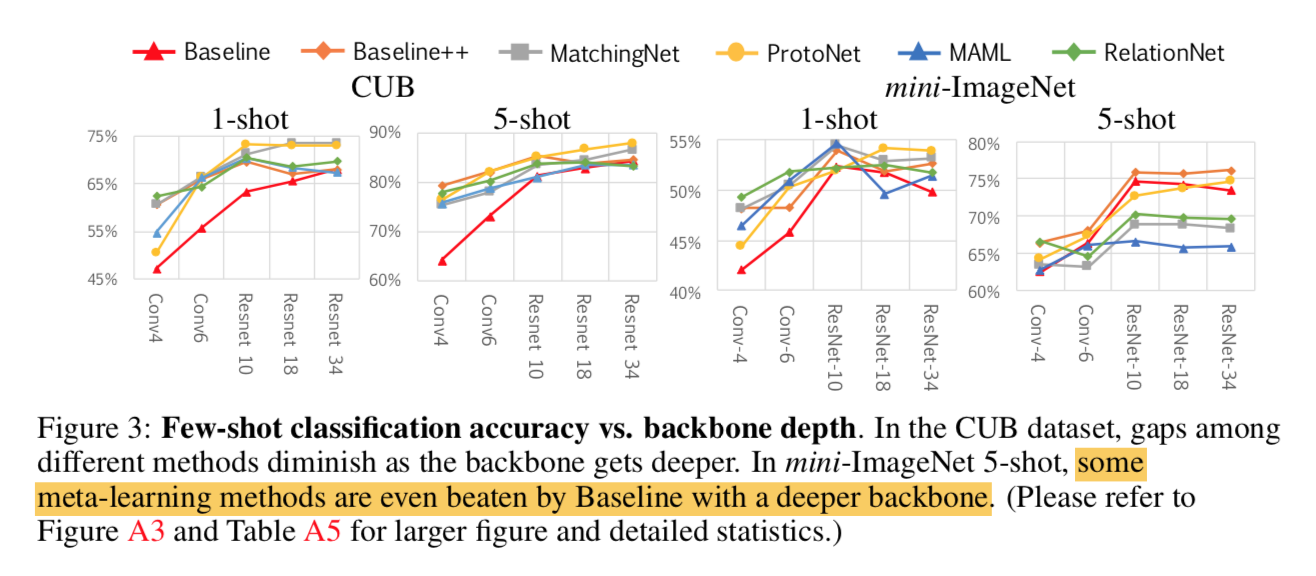
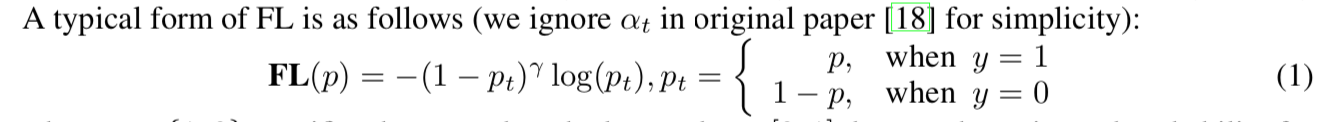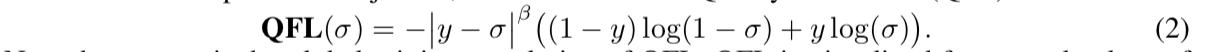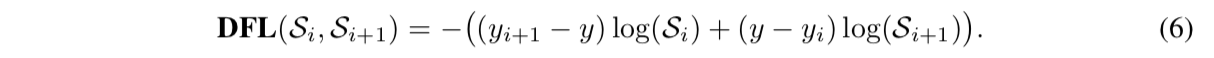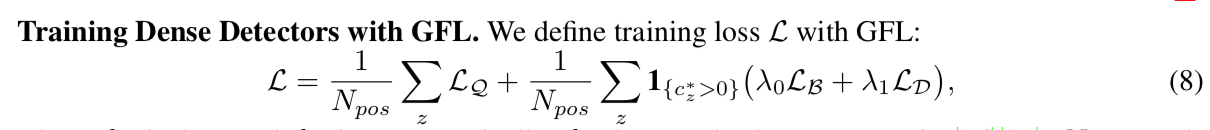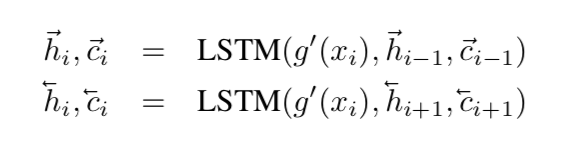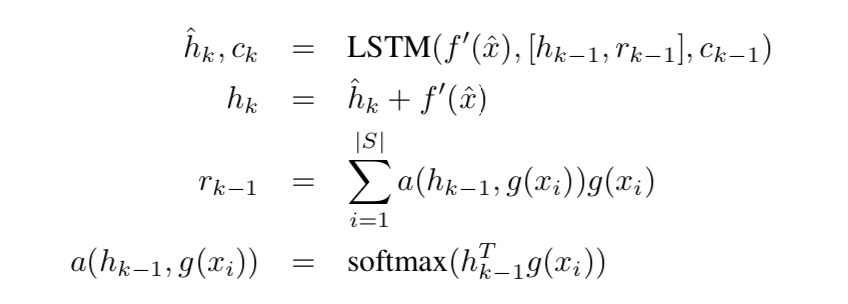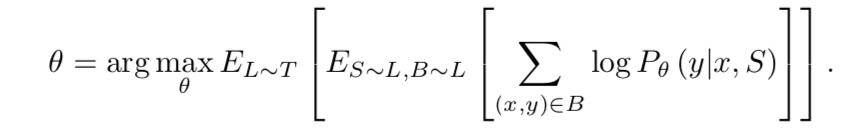reference:https://zhuanlan.zhihu.com/p/32903856
引用量:4193
R-FCN: Object Detection via Region-based Fully Convolutional Networks
动机
- region-based:
- 先框定region of interest的检测算法
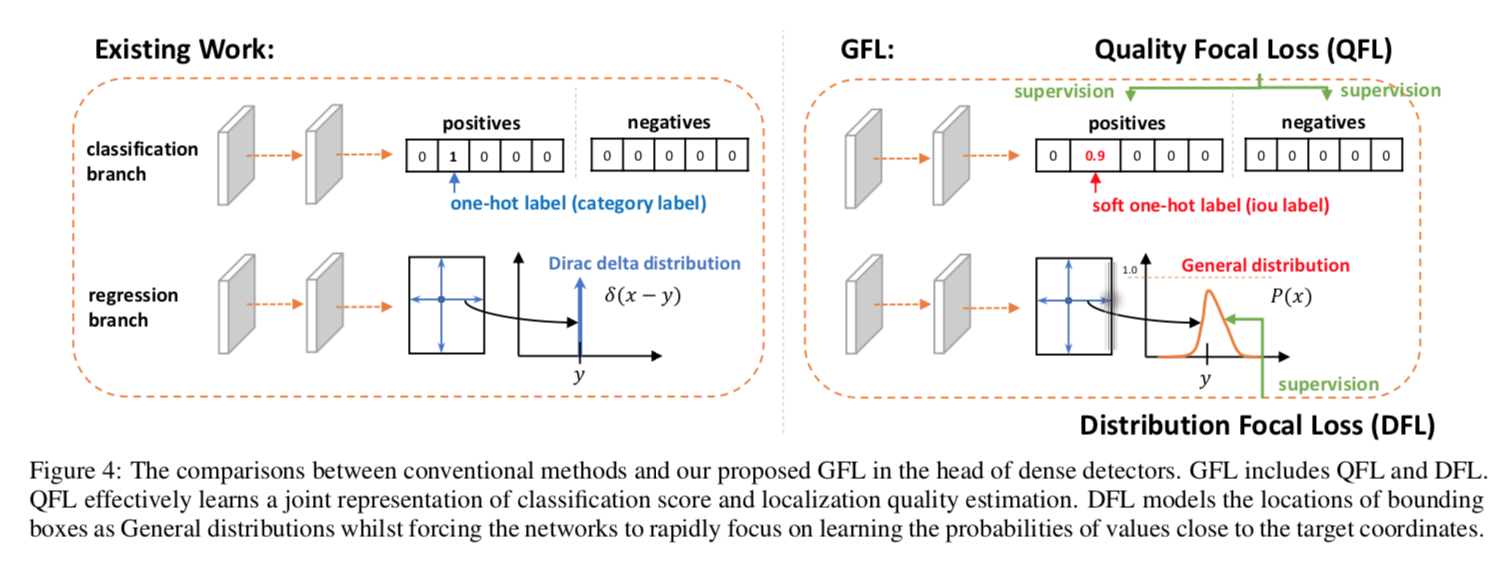
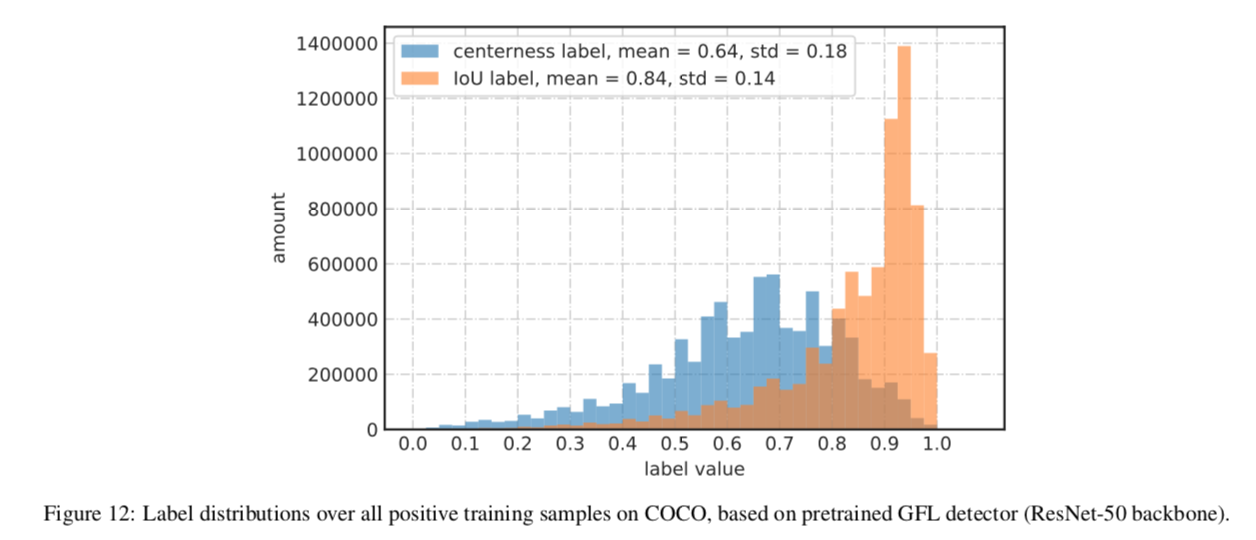
- previous methods:Fast/Faster R-CNN,apply costly per-region subnetwork hundreds of times
- fully convolutional
- 旨在解决Faster R-CNN第二阶段计算不共享,效率低的问题
- we propose position-sensitive score maps
- translation-invariance in image classification
- translation-variance in object detection
- verified on PASCAL VOC
- region-based:
论点
主流的两阶段检测架构
two subnetworks
- a shared fully convolutional:这一部分提取通用特征,作用于全图
- an RoI-wise subnetwork:这一部分不能共享计算,作用于proposals,因为是要针对每个位置的ROI进行分类和回归
也就是说,第一部分是位置不敏感的,第二部分是位置敏感的

网络越深越translation invariant,目标怎么扭曲、平移最终的分类结果都不变,多层pooling后的小feature map上也感知不到小位移,平移可变性(translation variance),对定位任务不友好
所以resnet-back-detector我们是把ROI Pooling放在stage4后面,跟一个RoI-wise的stage5
- improves accuracy
- lower speed due to RoI-wise
R-FCN
- 要解决的根本问题是RoI-wise部分不共享,速度慢:300个proposal要计算300次
- 单纯地将网络提前放到shared back里面不行,会造成translation invariant,位置精度会下降
必须通过其他方法加强网络的平移可变性,所以提出了position-sensitive score map
- 将全图划分为kxk个区域
- position-sensitive score map:生成kxkx(C+1)个特征图
- 每个位置对应C+1个特征图
- 做RoIPooling的时候,每个bin来自每个position对应的C+1个map(这咋想的,space dim到channel dim再到space dim?)
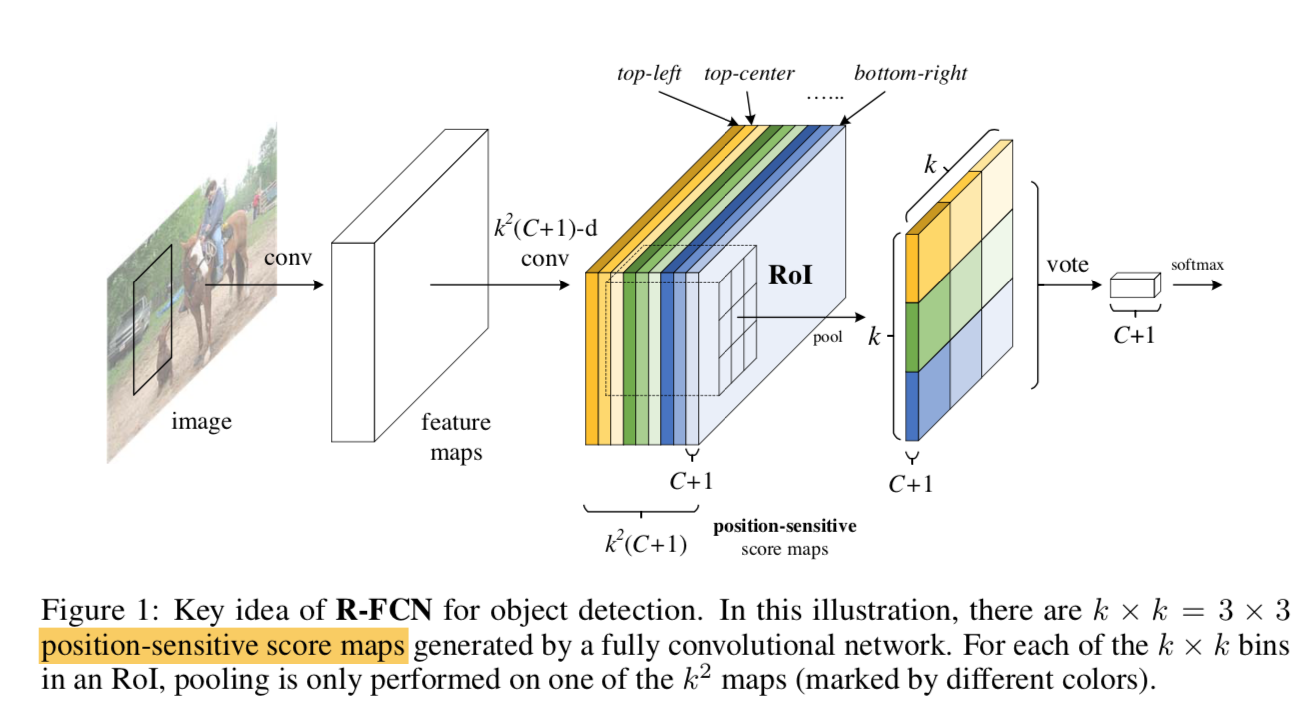
方法
overview
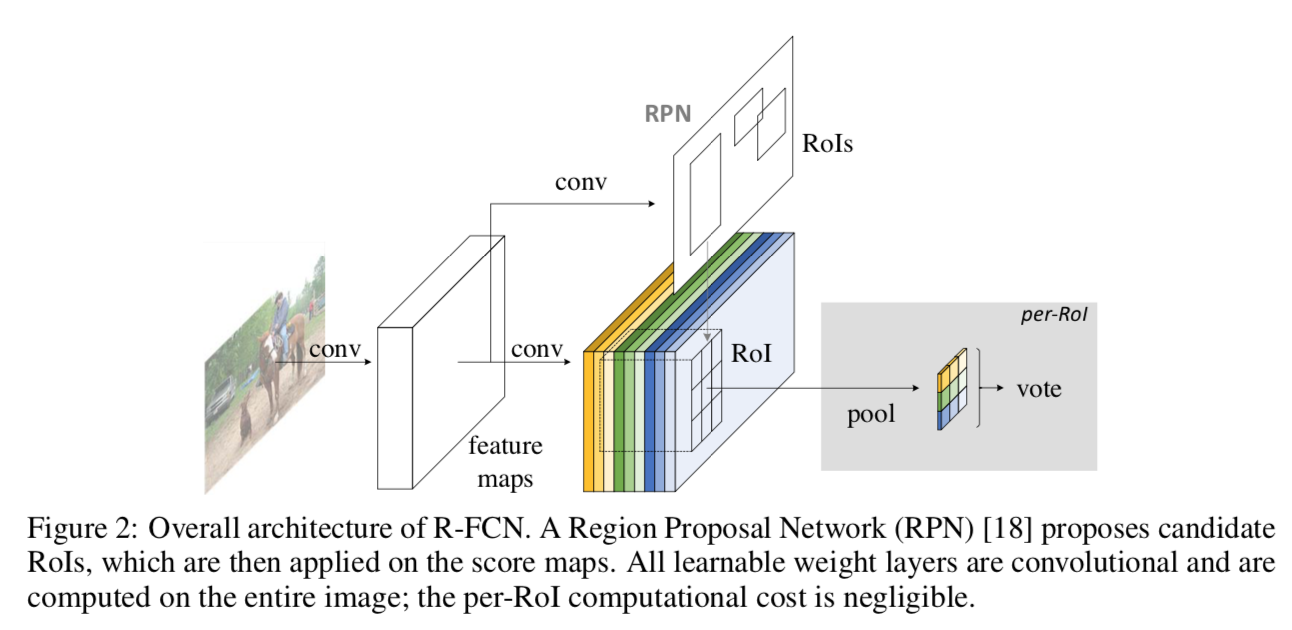
- two-stage
- region proposal:RPN
- region classification:the R-FCN
- R-FCN
- 全卷积
- 输出conv层有kxkx(C+1)个channel
- kxk对应grid positions
- C+1对应C个前景+background
- 最后是position-sensitive RoI pooling layer
- aggregates from last conv and RPN?
- generate scores for each RoI
- each bin aggregates responses from对应的position的channel score maps,而不是全部通道
- force模型在通道上形成对不同位置的敏感能力
- two-stage
R-FCN architecture
- back:ResNet-101,pre-trained on ImageNet,block5 输出是2048-d
- 然后接了random initialized 1x1 conv,降维
- cls brach
- 接$k^2(C+1)$的conv生成score maps
- 然后是Position-sensitive RoI pooling
- 将每个ROI均匀切分成kxk个bins
- 每个bin在对应的Position-sensitive score maps中找到唯一的通道,进行average pooling
- 最终得到kxk的pooling map,C+1个通道
- 将pooling map performs average pooling,得到C+1的vector,然后softmax
- box branch
- 接$4k^2$的conv生成score maps
- Position-sensitive RoI pooling
- 得到kxk的pooling map,4个通道
- average pooling,得到4d vector,作为回归值$(t_x,t_y,t_w,t_h)$
- there is no learnable layer after the ROI layer,enable nearly cost-free region-wise computation
Training
- R-FCN positives / negatives:和gt box的IoU>0.5的proposasl
- adopt OHEM
- sort all ROI loss and select the highest 128
- 其他settings基本和Faster-RCNN一致
- Atrous and stride
- 特别地,对resnet的block5进行了改变
- stride2改成stride1
- 所有的conv改成空洞卷积
- RPN是接在block4的输出上,所以不受空洞卷积的影响,只影响R-FCN head