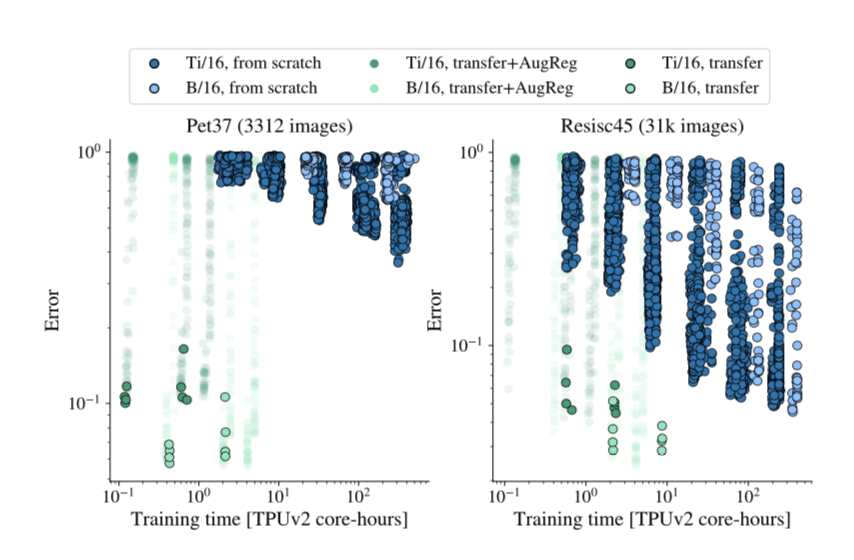
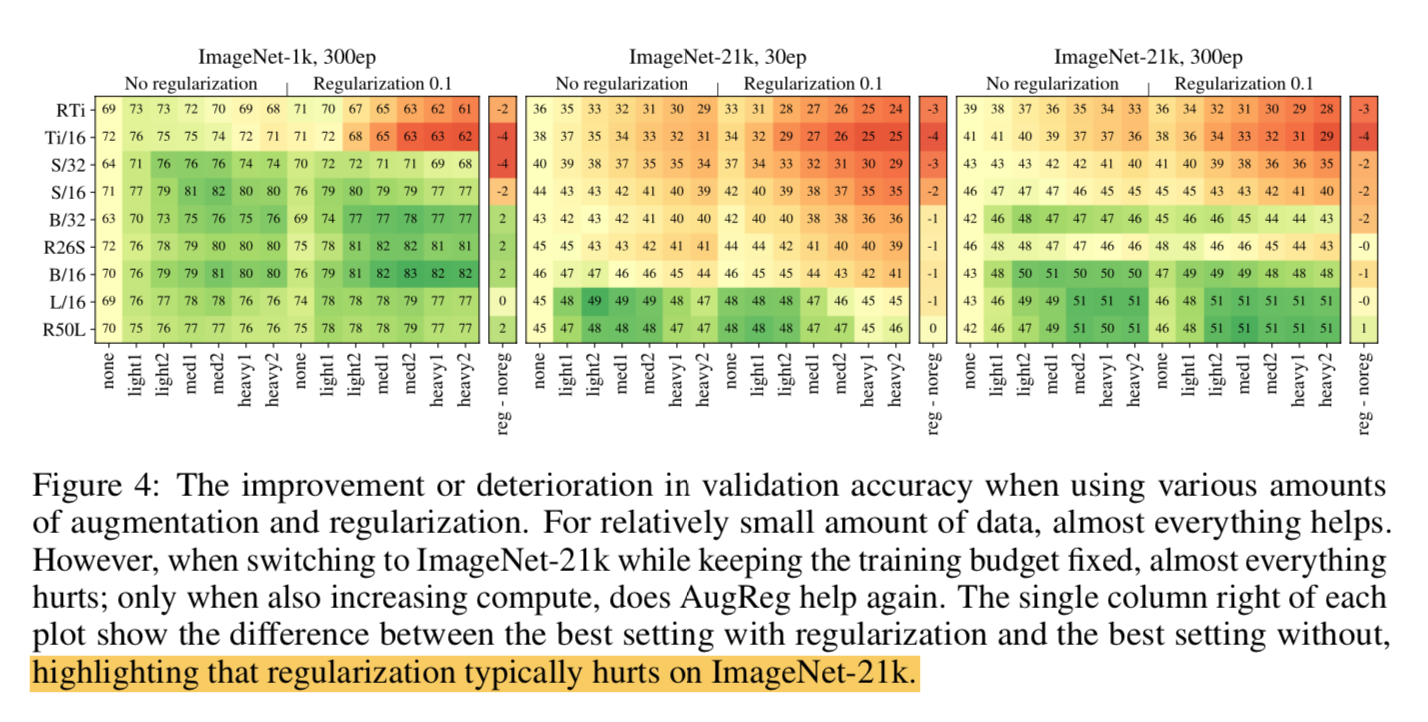
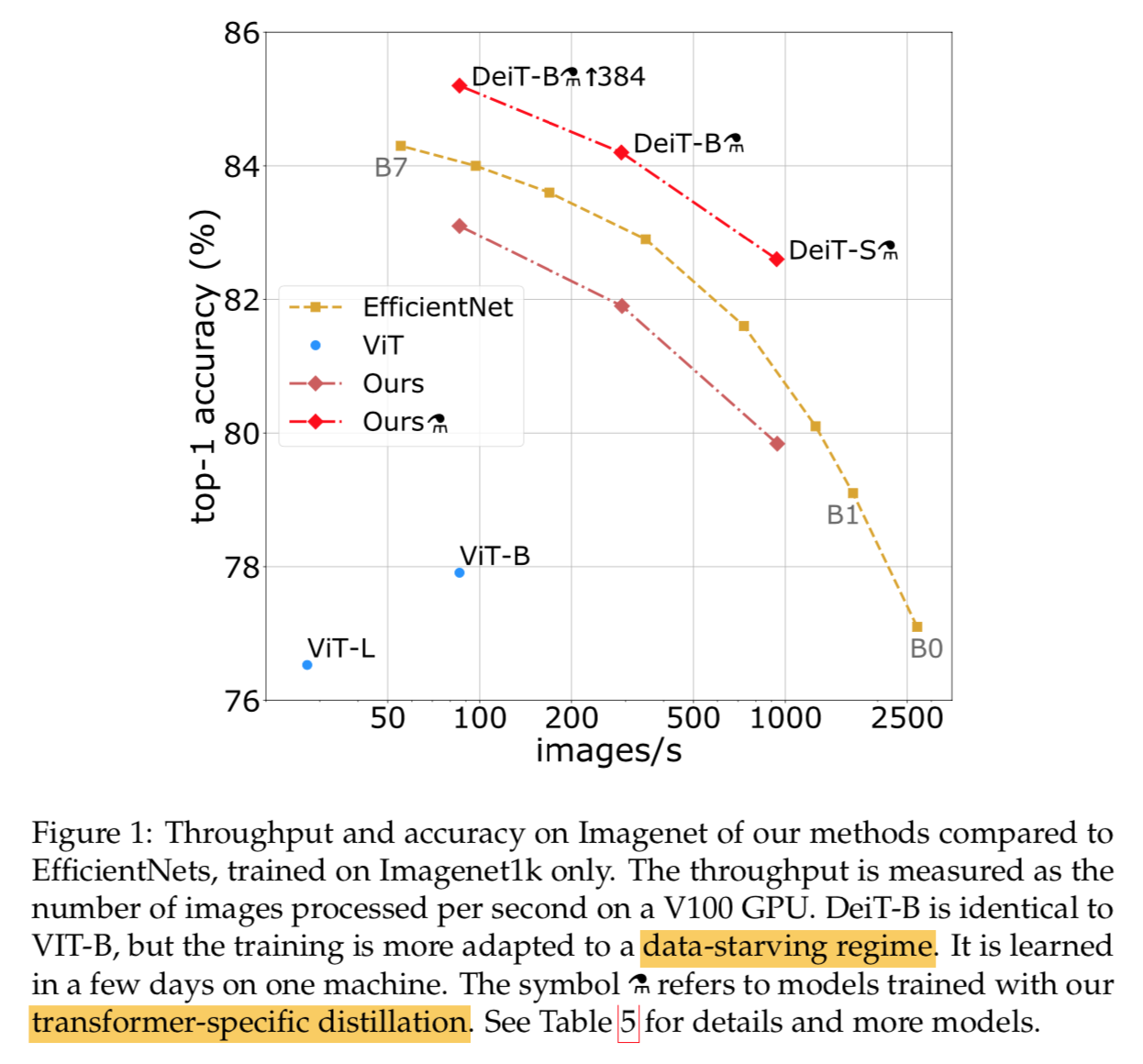
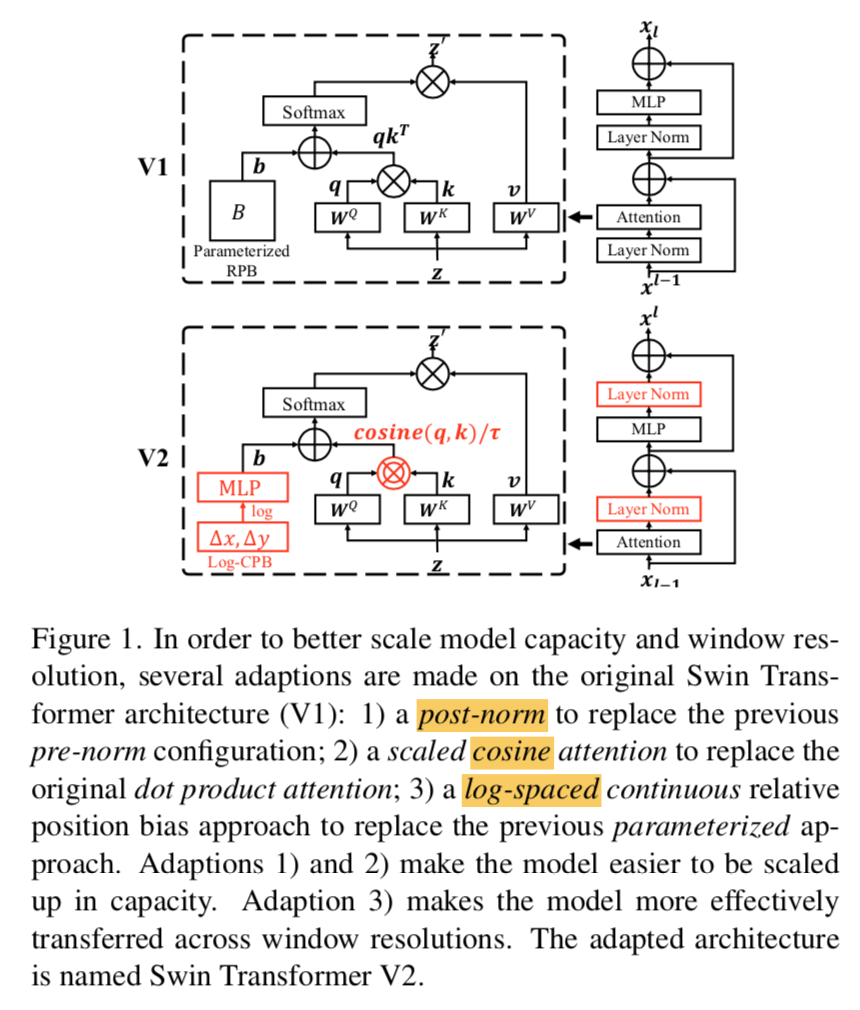
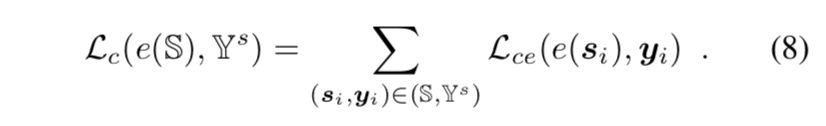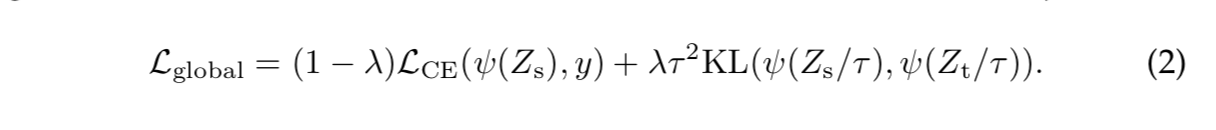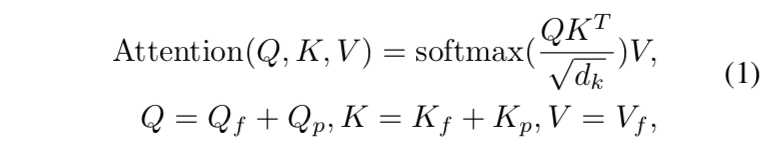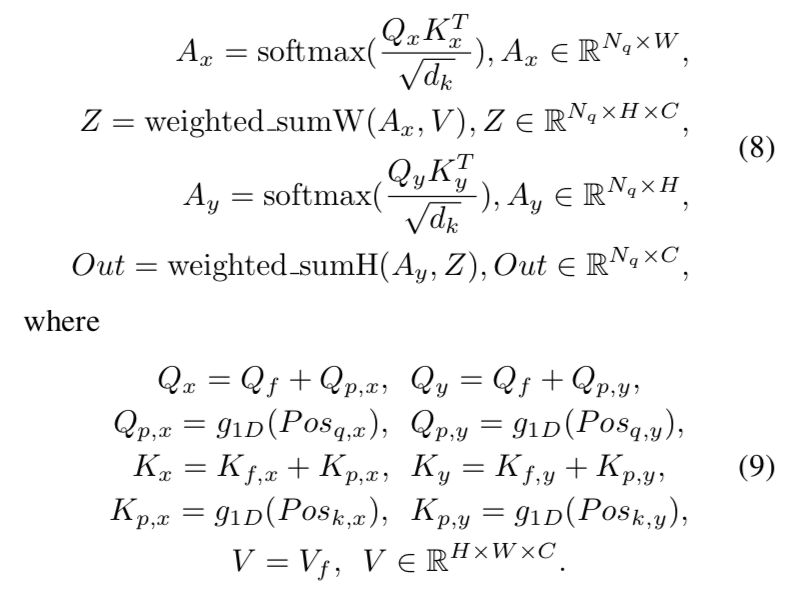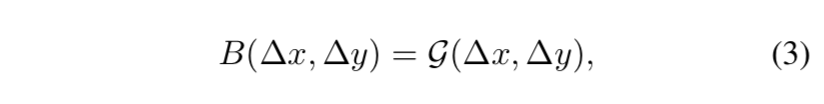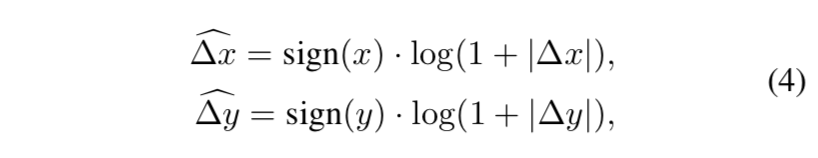一些metric loss特点的总结:
* margin-loss:样本与自身类簇心的距离要小于样本与其他类簇心的距离——标准center loss
* intra-loss:对样本和对应类簇心的距离做约束——小于一定距离
* inter-loss:对样本和其他类簇心的距离做约束——大于一定距离
* triplet-loss:样本与同类样本的距离要小于样本与其他类样本的距离

ArcFace: Additive Angular Margin Loss for Deep Face Recognition
动机
- 场景:人脸,
- 常规要素:
- hypersphere:投影空间
- metric learning:距离(Angles/Euclidean) & class centres
- we propose
- an additive angular margin loss:ArcFace
- has a clear geometric interpretation
- SOTA on face & video datasets
论点
- face recognition
- given face image
- pose normalisation
- Deep Convolutional Neural Network (DCNN)
- into feature that has small intra-class and large inter-class distance
- two main lines
- train a classifier:softmax
- 最后的分类层参数量与类别数成正比
- not discriminative enough for the open-set
- train embedding:triplet loss
- triplet-pair的数量激增,大数据集的iterations特别多
- sampling mining很重要,对精度&收敛速度
- train a classifier:softmax
- to enhance softmax loss
- center loss:在分类的基础上,压缩feature vecs的类内距离
- multiplicative angular margin penalty:类特别多的时候,center就不好更新了,用last fc weights能够替代center,但是会不稳定
- CosFace:直接计算logit的cosine margin penalty,better & easier
- ArcFace
- improve the discriminative power
- stabilise the training meanwhile
- margin-loss:Distance(类内)+m < Distance(类间)
- 核心idea:normed feature和normed weights的dot product等价于在求他俩的 cosine distance,我们用arccos就能得到feature vec和target weight的夹角,给这个夹角加上一个margin,然后求回cos,作为pred logit,最后softmax
- face recognition
方法
ArcFace
transitional softmax
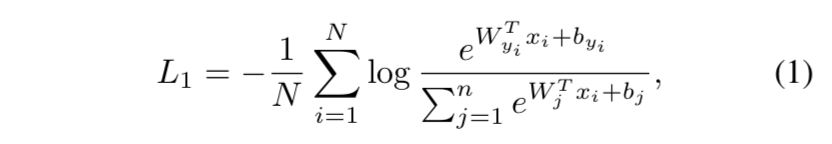
- not explicitly enforce intra-class similarity & inter-class diversity
- 对于类内variations大/large-scale测试集的场景往往有performance gap
our modification
fix the bias $b_j=0$ for simplicity
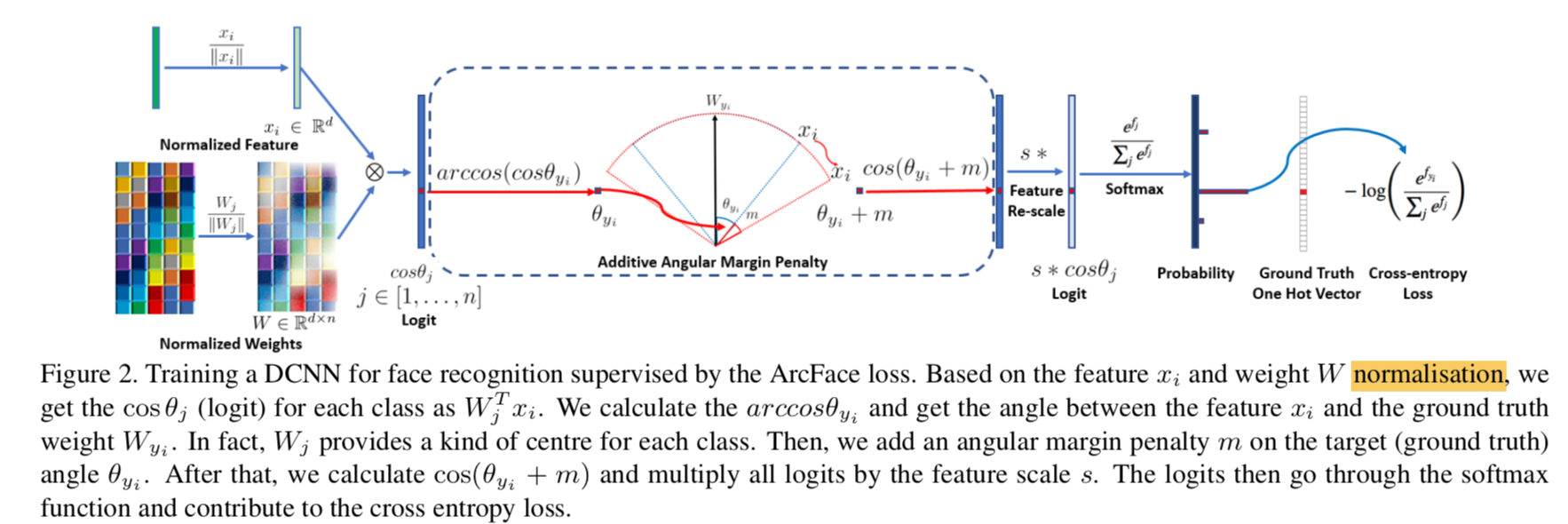
transform the logit $W_j^T x=||W_j||\ ||x||cos\theta_j$,$\theta_j$是weight $W_j \in R^d$和样本feature $x \in R^d$的夹角
fix the $||W_j||$ by l2 norm:$||W_j||=1$
fix the embedding $||x||$ by l2 norm and rescale: $||x||=s$
thus only depend on angle:这使得feature embedding分布在一个高维球面上,最小化与gt class的轴(对应channel的weight vec,也可以看作class center)夹角
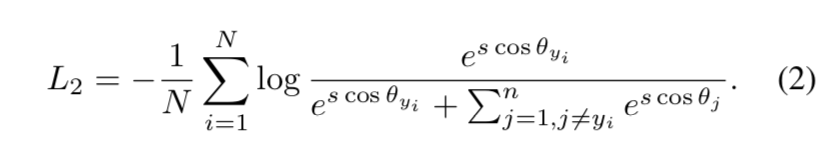
add an additive angular margin penalty:simultaneously enhance the intra-class compactness and inter-class discrepancy
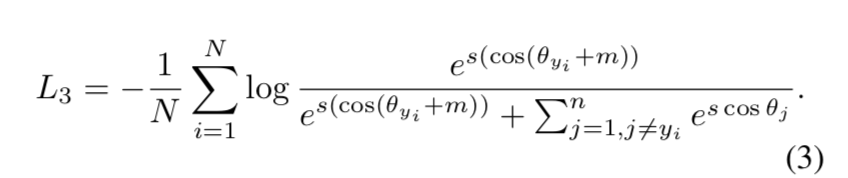
作用
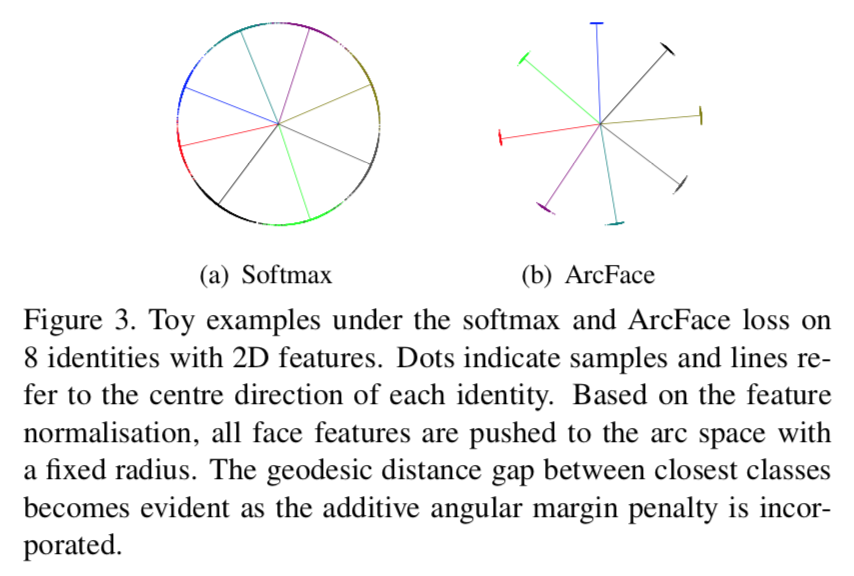
- softmax produce noticeable ambiguity in decision boundaries
ArcFace loss can enforce a more evident gap
pipeline
实现