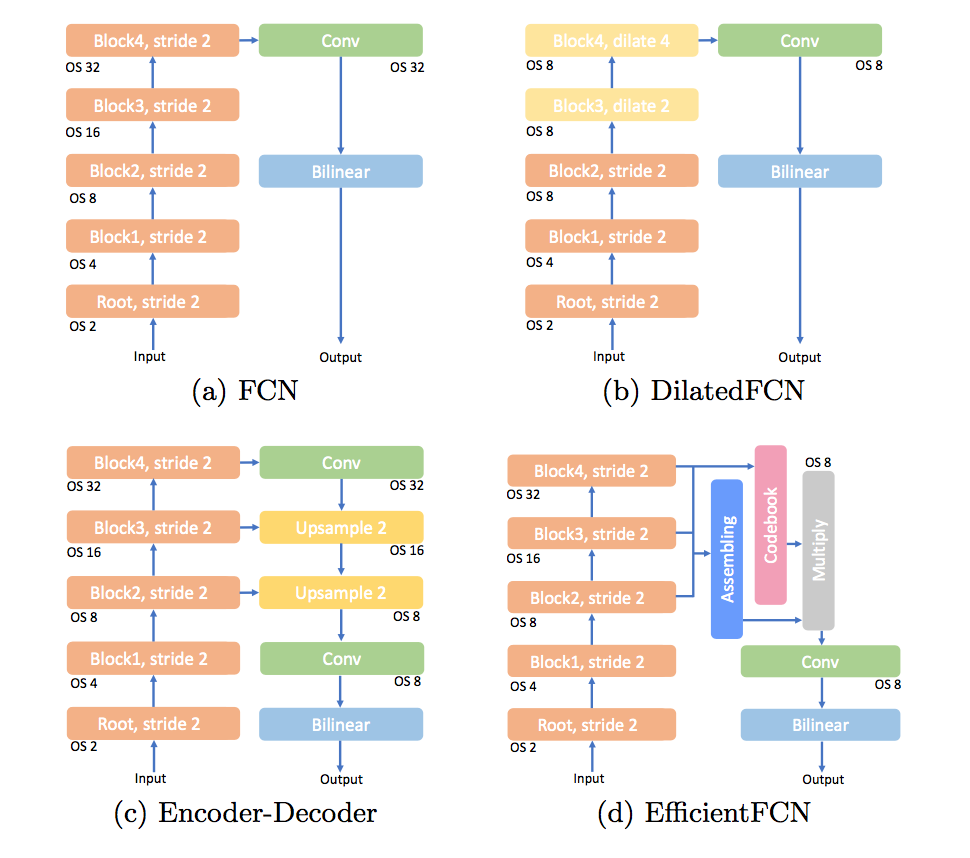
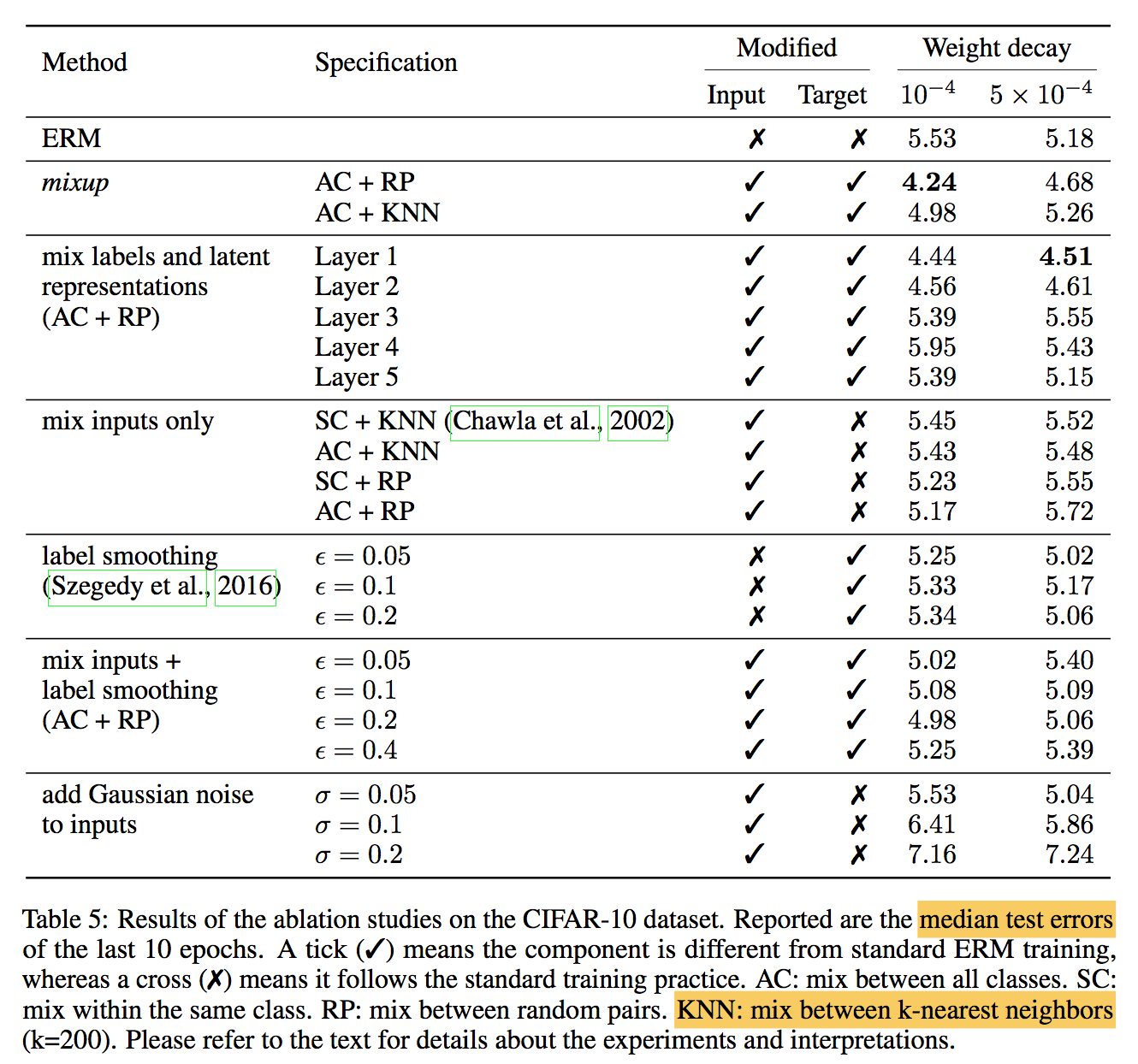
分类指标
- recall:召回率
- precision:准确率
- accuracy:正确率
- F-Measure
- sensitivity:灵敏度
- specificity:特异度
- TPR
- FPR
- ROC
- AUC
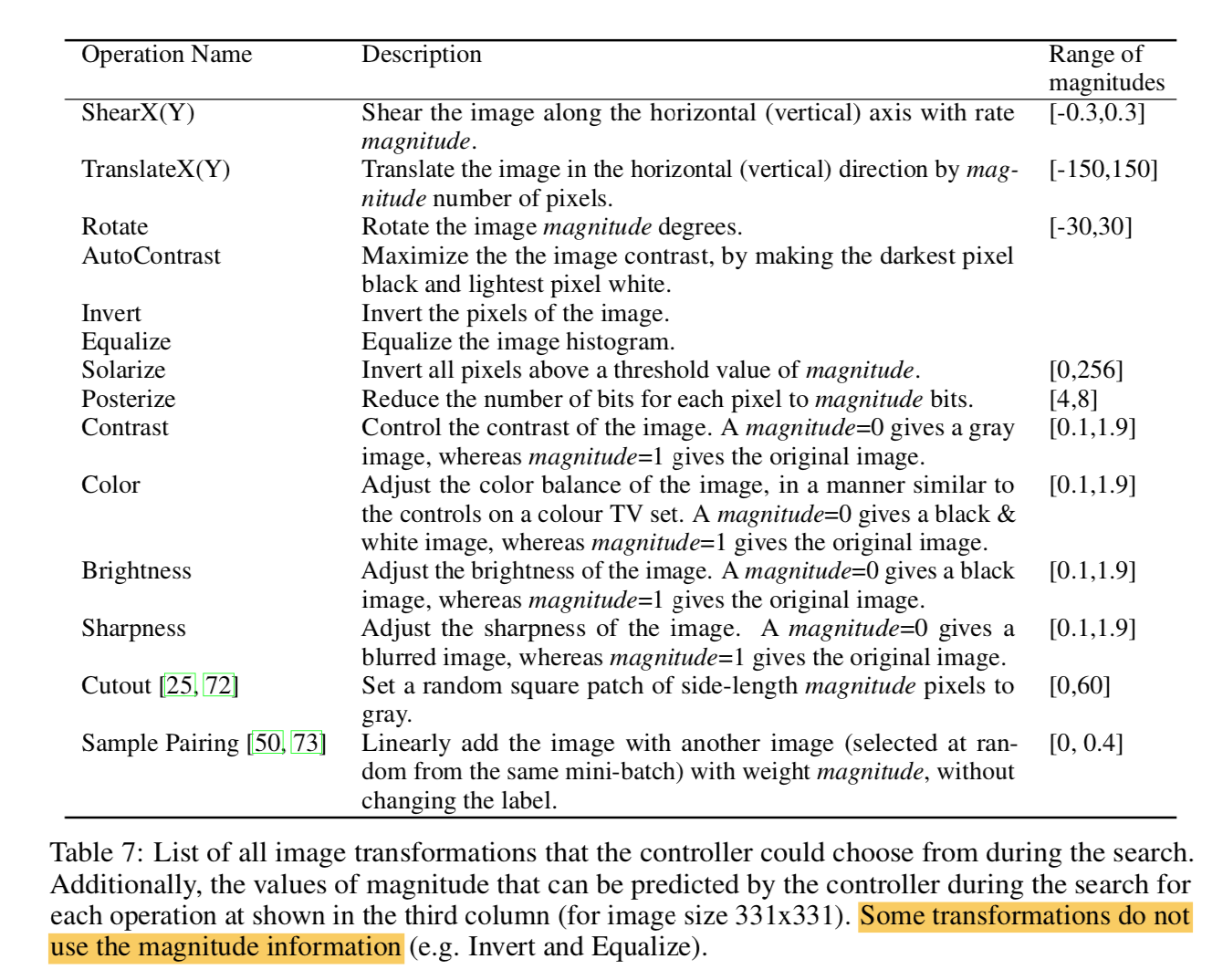
混淆矩阵
| | gt is p | gt is n |
| :———-: | :————: | :—————: |
| pred is p | tp | fp(假阳性) |
| pred is n | fn(漏检) | tn |- 注意区分fp和fn
- fp:被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数
- fn:被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数
recall
- 衡量查全率
- 对gt is p做统计
- $recall = \frac{tp}{tp+fn}$
precision
- 衡量查准率
- 对pred is p做统计
- $precision = \frac{tp}{tp+fp}$
accuracy
- 对的除以所有
- $accuracy = \frac{tp+tn}{p+n}$
sensitivity
- 衡量分类器对正例的识别能力
- 对gt is p做统计
- $sensitivity = \frac{tp}{p}=\frac{tp}{tp+fn}$
specificity
- 衡量分类器对负例的识别能力
- 对gt is n做统计
- $specificity =\frac{tn}{n}= \frac{tn}{fp+tn}$
F-measure
- 综合考虑P和R,是Precision和Recall加权调和平均
- $F = \frac{(a^2+1)PR}{a^2*P+R}$
- $F_1 = \frac{2PR}{P+R}$
TPR
- 将正例分对的概率
- 对gt is t做统计
- $TPR = \frac{tp}{tp+fn}$
FPR
- 将负例错分为正例的概率
- 对gt is n做统计
- $FPR = \frac{fp}{fp+tn}$
- FPR = 1 - 特异度
ROC
- 每个点的横坐标是FPR,纵坐标是TPR
- 描绘了分类器在TP(真正的正例)和FP(错误的正例)间的trade-off
- 通过变化阈值,得到不同的分类统计结果,连接这些点就形成ROC curve
- 曲线在对角线左上方,离得越远说明分类效果好
- P/R和ROC是两个不同的评价指标和计算方式,一般情况下,检索用前者,分类、识别等用后者
AUC
- AUC的值就是处于ROC curve下方的那部分面积的大小
- 通常,AUC的值介于0.5到1.0之间