- prev knowledge
DETR:Dectection Transformer,facebook,主要贡献是提出了query-based decoder的架构
deformable DETR:use multi-scale deformable attn,sensetime,主要贡献是deformable attn来降低计算复杂度,加速收敛
PETR: Position Embedding Transformation for Multi-View 3D Object Detection
introduction
将3D coordinates编码成PE,aggregate进image features,得到3D position-aware features
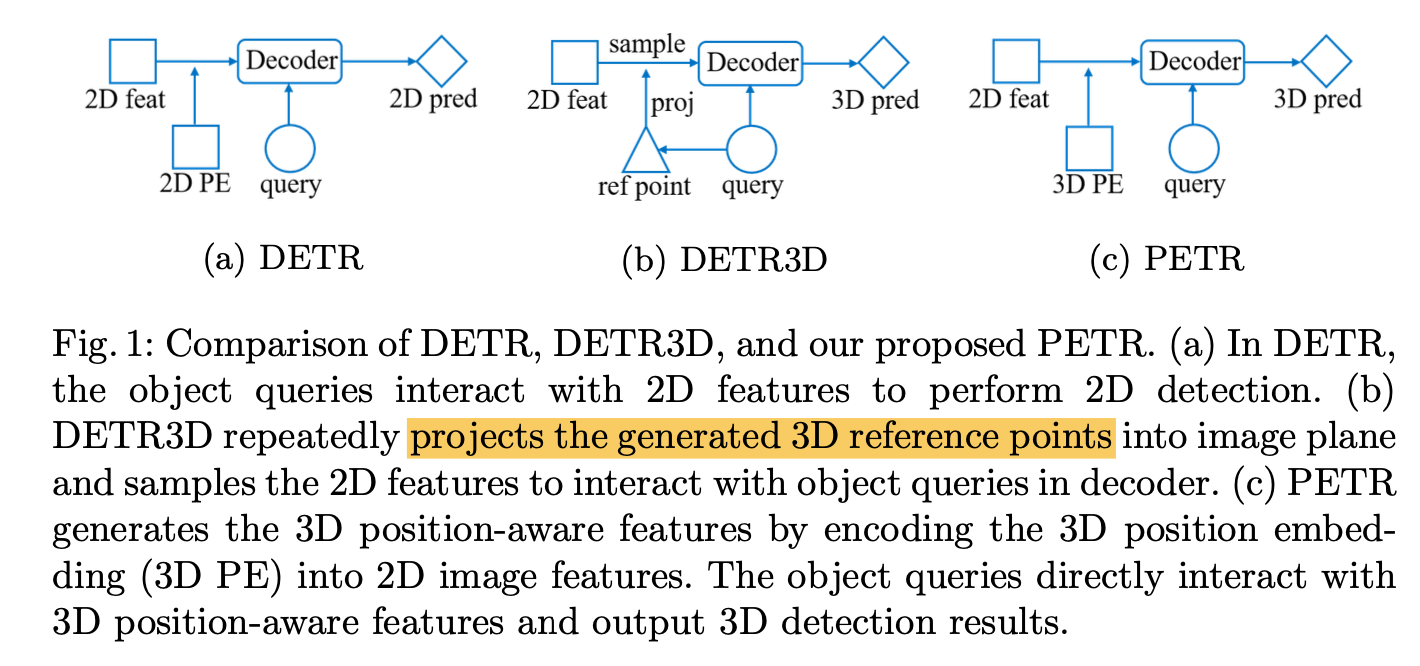
Comparison of DETR, DETR3D, PETR:区别就在PE上
- DETR适用于单张图场景,只用2D PE
- DETR3D可以用于multi-camera场景,PE是在3D ref points world coords通过相机参数转换到对应camera coords上
PETR直接使用3D world coords PE
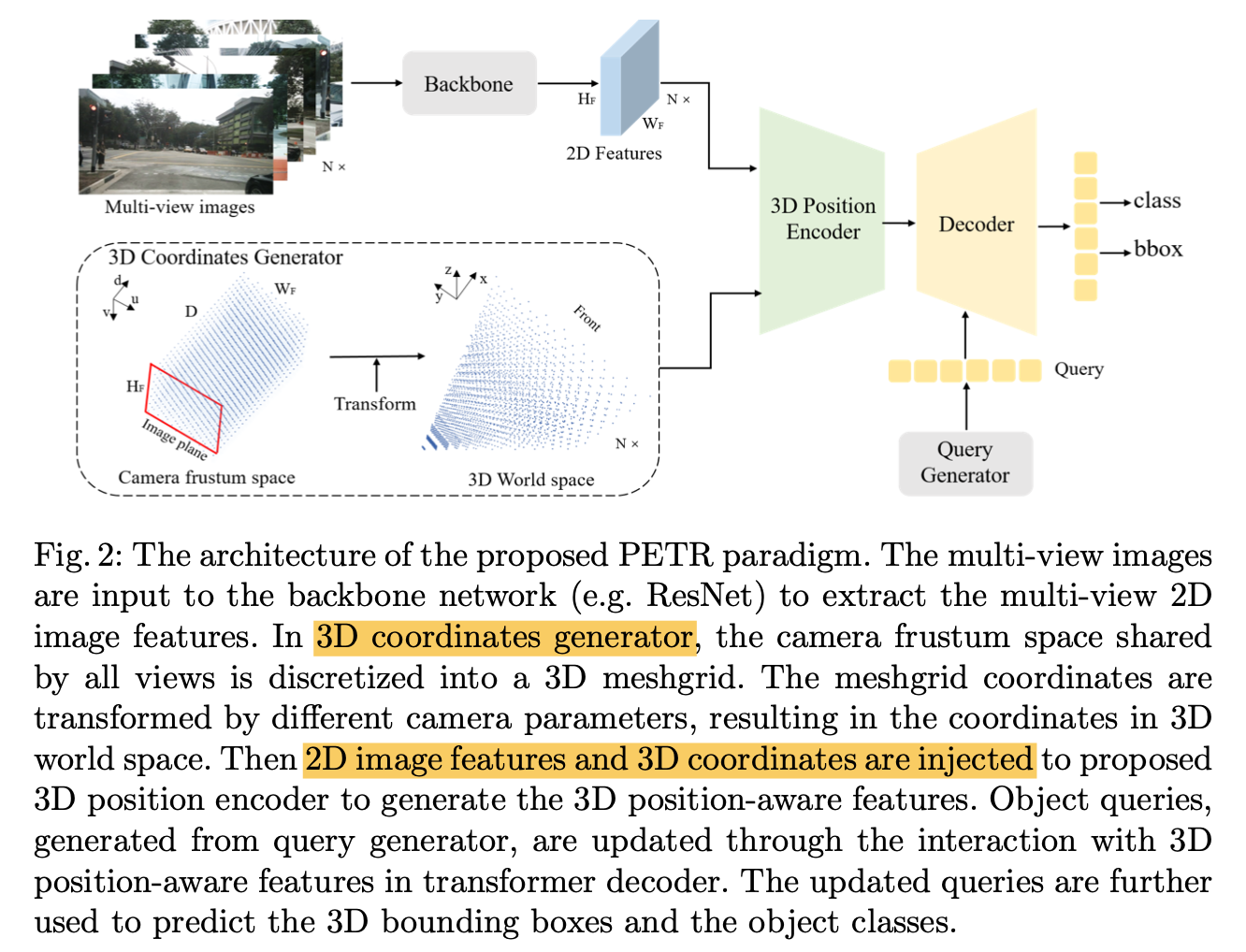
overview
- a 3D coordinates generator:将2D的image转化成3D的meshgrid,然后通过相机参数将3D meshgrid投影的世界坐标系
- a 3D position encoder:输入2D feature和3D grids coords,使得2D feature包含3D coords的信息—— 3D position-aware features
a query generator:这个还需要PE吗?
method
- 3D Coordinates Generator
- given meshgrid (H,W,D)
- 每个meshgrid的camera-3D坐标为$(ud,vd,d,1)$,uv是2D image的坐标,d是depth
- world 3D coord为$p_w = K^{-1} p_c$
- 最后对xyz分别normalize
- 3D Position Encoder
- given 2D features:N个HWC,先接1x1 conv降通道
- given 3D coords:N个HW3,先接MLP转化成embedding
- 两个通道对齐以后相加,作为decoder的context输入
- Query Generator
- learnable query被初始化为3D world space下的anchor points,也是用一个MLP编码成embedding
- Decoder
- standard decoder from DETR
- query heads
- classification:focal loss
- regression:预测anchor query的offsets,L1 loss
- 3D Coordinates Generator