BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
introduction
BEVFormer:lookup and aggregate
- spatial cross-attn:Transformer-based
temporal self-attn:with Temporal structure
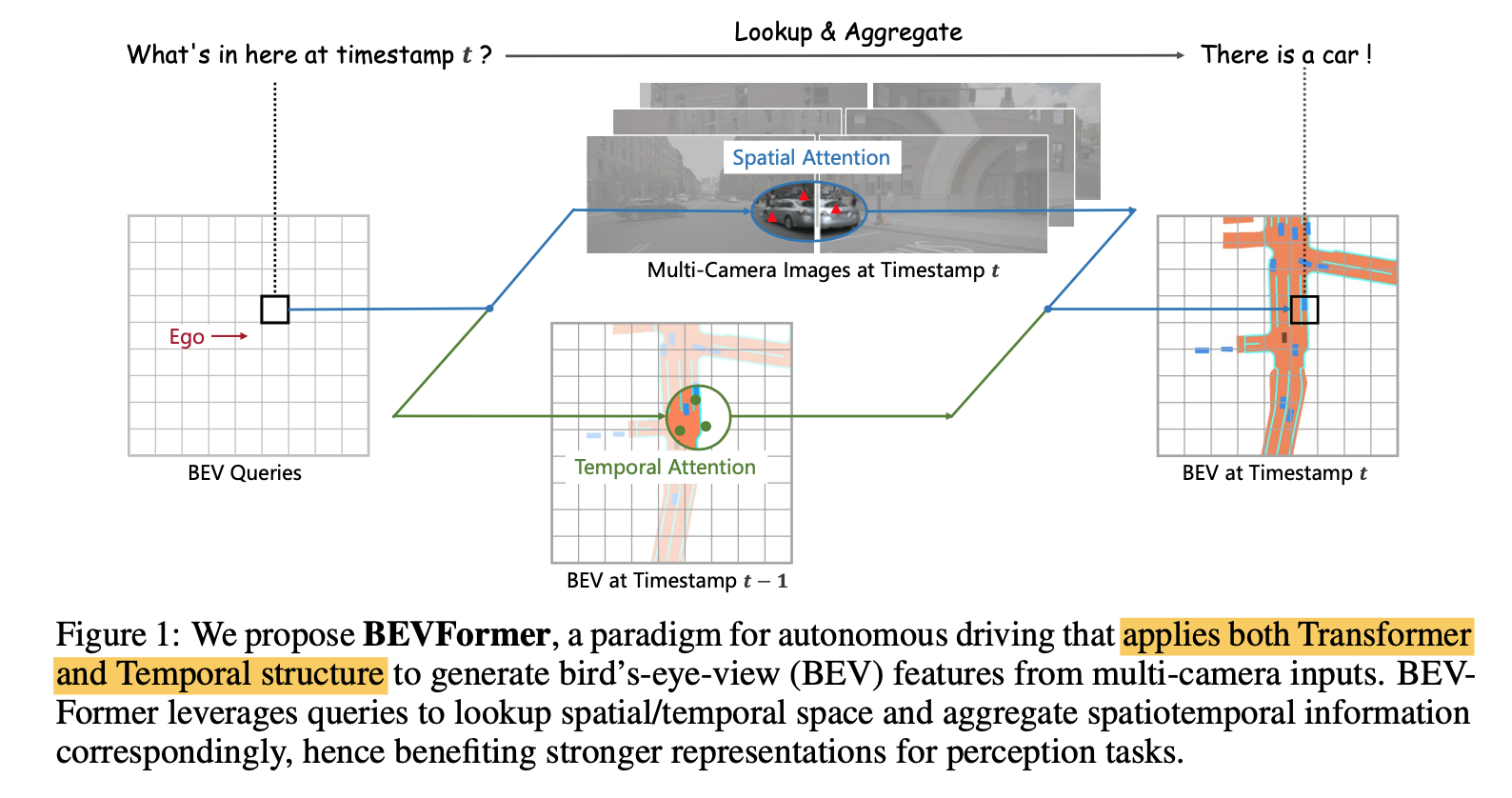
the BEV features can support
- 3D perception tasks such as 3D object detection
- map segmentation
Camera-based 3D Perception
- DETR3D projects learnable 3D queries in 2D images
- BEV:transform image features into BEV features and predict 3D bounding boxes from the top-down view
method
Overview
模型主体就是stacking encoder layers * 6,每个encoder layer包含三个部分
- running Q是grid-shaped BEV queries
- 先和前一个timestep的BEV feature做temporal self-attention
- 再和encoded multi-camera features做spatial cross-attention
- 最后是FFN,输出当前t的BEV feature
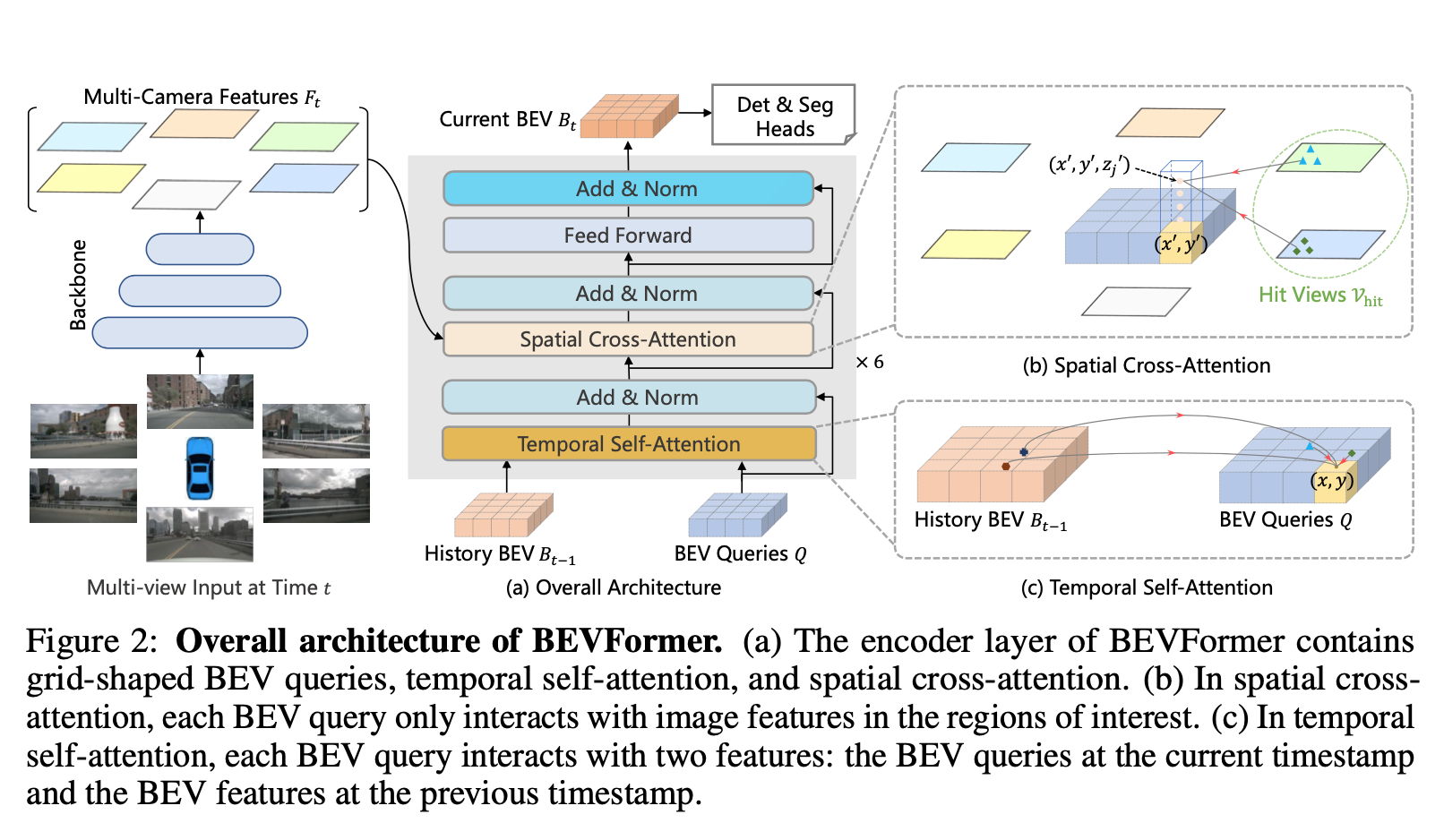
BEV Queries
- given the HW BEV plane,grid-shaped $Q\in R^{CHW}$负责grid feature
- BEV feature的中心点是自己
- add PE
Spatial Cross-Attention
deformable attention:query only interacts with its regions of interest across camera views
与原始的deformAttn不同,sampling不是learnable的:首先将query拉高成bin query,从bin query中采集3D reference points,然后再映射到2D view
- given grid scale s:real word loc $x^{‘}=(x-\frac{W}{2})s$, $y^{‘}=(y-\frac{W}{2})s$
- define a set of anchor heights $\{z_i^{‘}\}_{N_{ref}}$,定义采样点个数的高度
- 于是对每个grid query,都有N_ref个sampling choices
最后将world coord通过相机参数转换到2D map上
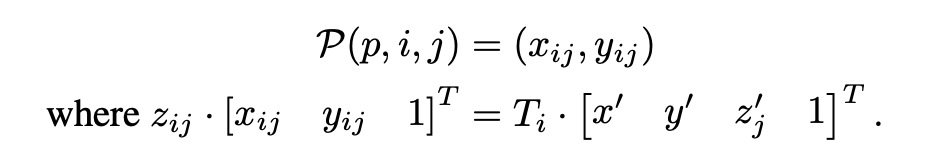
Temporal Self-Attention
- 首先要algin中心点
- 然后做deformable attn
- 与原始的deformAttn不同,learnable sampling不是在query上做的,而是在concat的query和aligned former query上做的
Applications
- given BEV feature CHW
- 3D Det based on DETR
- image feature替换成single-scale的BEV feature
- 预测 3D bounding boxes and velocity
- 3D boxes reg loss只用L1 loss
- map segmentation based on Panoptic SegFormer
- 跟mask2former的decoder基本一样
- 就是N个learnable的query做cross-self-attn,最后做semantic aggregate
- 3D Det based on DETR
- given BEV feature CHW