papers
[M2F] Masked-attention Mask Transformer for Universal Image Segmentation
[VITA 2022] VITA: Video Instance Segmentation via Object Token Association
[MobileViT v2] Separable Self-attention for Mobile Vision Transformers
VITA: Video Instance Segmentation via Object Token Association
introduction
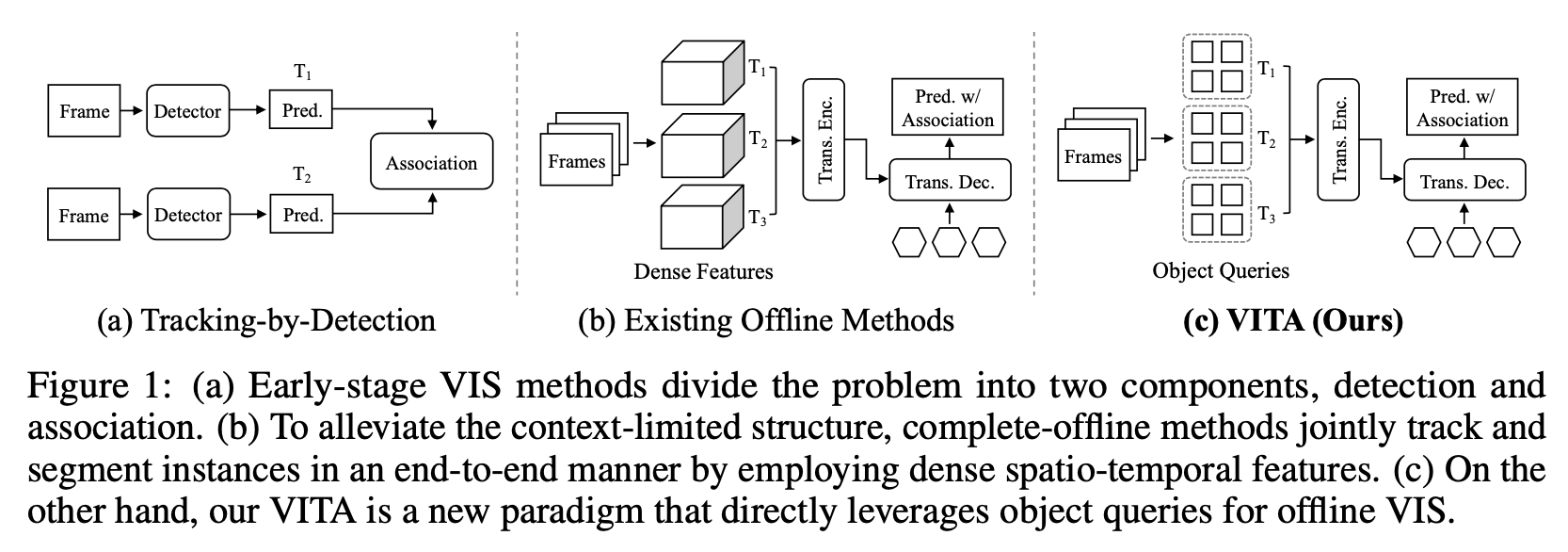
explicit object-oriented information can be a strong clue for understanding the context of the entire sequence
build video-level understanding through frame-level object tokens
- 不是用spatio-temporal structure,efficiency
- 也不是用frame-attention,long-term adaptive
built on top of an off-the-shelf Transformer-based frame-level detector
- 可以用图像预训练一个detector,然后冻结去训练video
- 可以handle long and high-resolution videos
VIS methods
- onlineVIS:一般是ref和cur通过association的方式,measure the similarities/correspondence
offlineVIS:involve整个video来预测,帧太多spatio-temporal attention太heavy,一般放在decoder上,instance-level的attn
method
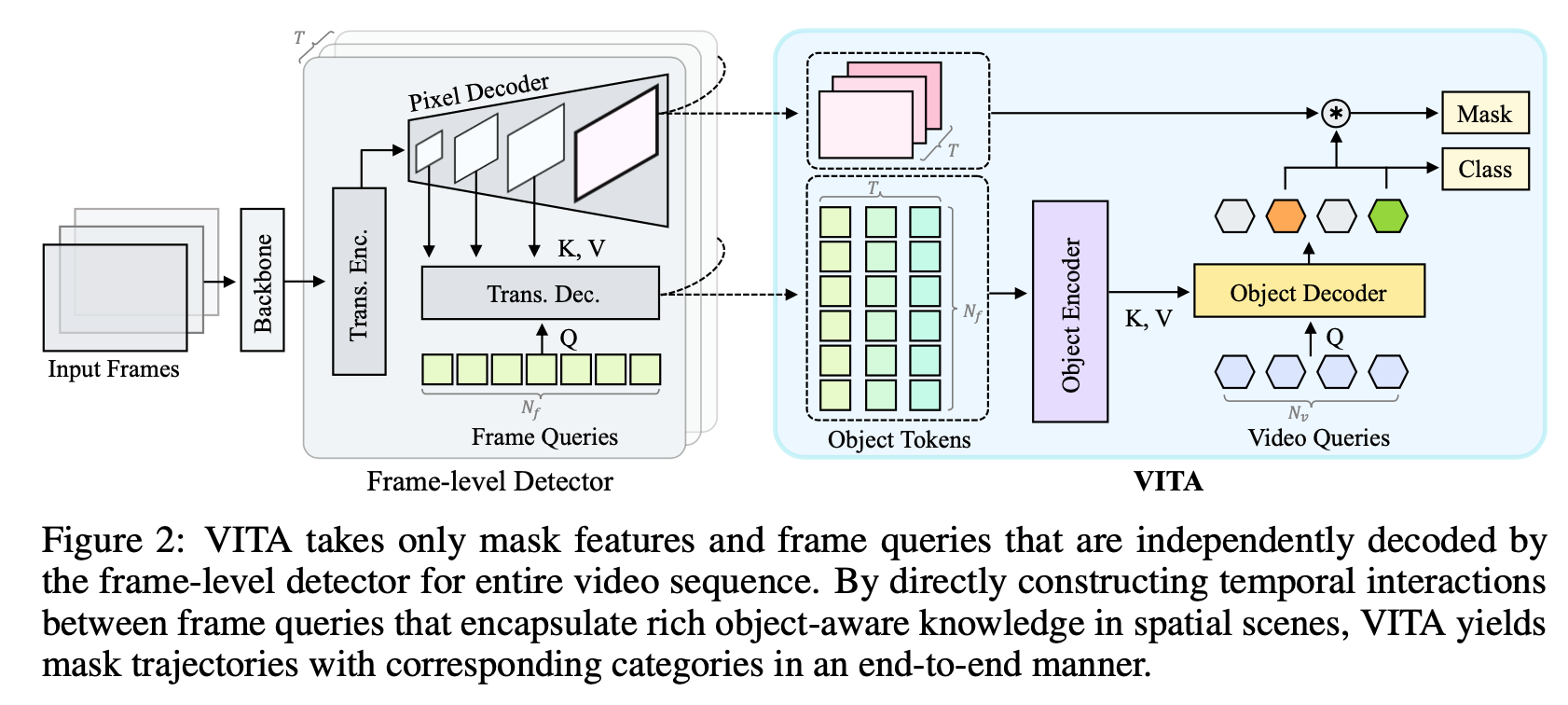
Frame-level Detector
- m2f
- frame-level predictions
- dynamic 1×1 convolutional weight from the frame queries $f \in R^{NC}$
- per-pixel embeddings from the pixel decoder $M \in R^{CHW}$
- 用frame queries去decode encoder feature,实现classifying&segmenting their matched objects
VITA Head
- input:
- collect the object-level frame queries throughout the whole video,$\{f_t \}^T_{t=1} \in R^{C(TN)}$
- frame features $\{M_t\}_{t=1}^T \in R^{CTHW}$
- Object Encoder
- build video-level information
- window-shifted self-attention along the temporal axis
- 这一步是为了将query-level的信息交互聚合成object-level的信息,在temporal上交互
- Object Decoder and Output heads
- 假设object tokens can provide sufficient instance-specific information
- 引入trainable video queries $v\in R^{CN_v}$作为Q
- 前面的T frame queries $tf \in R^{C(TN_f)}$作为KV
- 一样的几层cross+self attn block
- final predictions
- class embedding:$p \in R^{N_v (K+1)}$
- mask embedding:$m \in R^{N_v C}$
- 每个query代表的是tracklet of an instance over all frames
- 最终的predicted mask logits用mask embedding和frame masks做matmul得到
- input:
Clip-wise losses
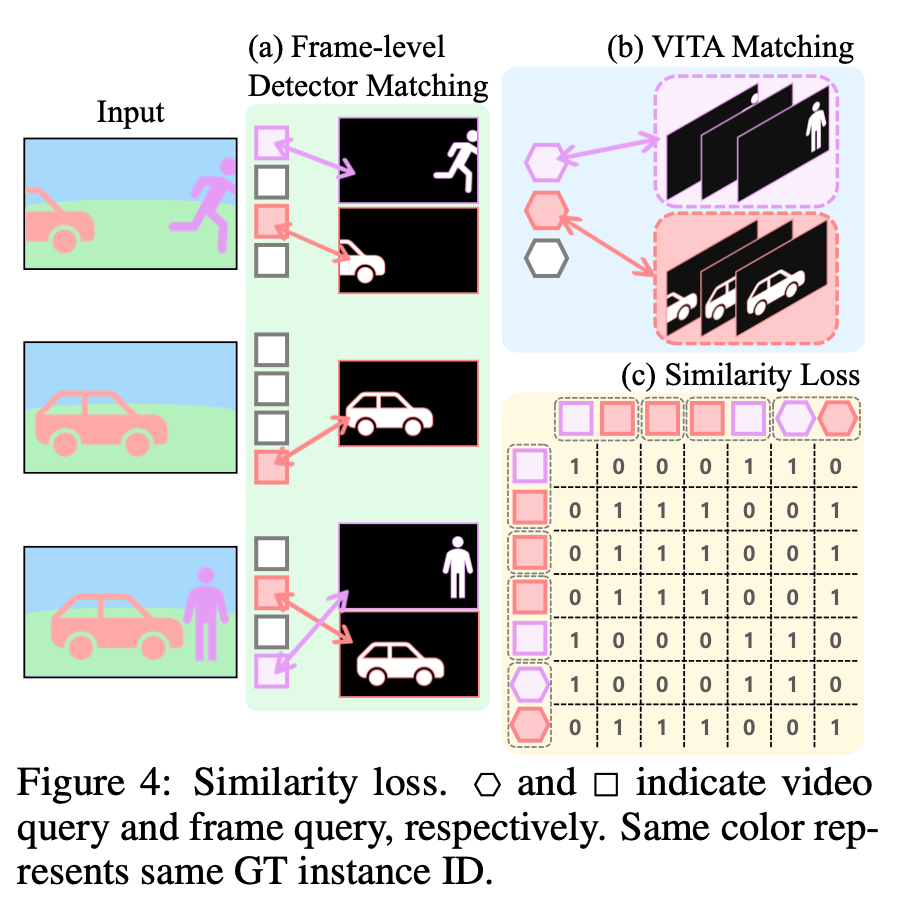
similarity loss
- frame-level matching的query id是变化的
- video-level mathcing的query id是绑定到固定instance的
- collect所有match到gt的frame queries和video queries,然后再进行query之间的pairing
- similarity pred:embed the collected queries by a linear layer,then measure the similarity by matmul
- similarity target:match到同一个gt instance的为1,否则为0,构建similarity matrix
用BCE来计算similarity loss
- total loss
- 首先是single-frame loss:M2F原始那套
- 然后是video mask loss:用video query预测的per-frame mask的loss
- 最后是similarity loss:用来match video query和frame query的
Separable Self-attention for Mobile Vision Transformers
introduction
- ViT的efficiency bottleneck是MHA
- multi-head:costly bmm & mm & softmax
- self-attention:需要O(n^2)的computation cost
- this paper propose separable self-attention
- O(n)
- uses element-wise operations for computing self-attention
- ViT的efficiency bottleneck是MHA
method
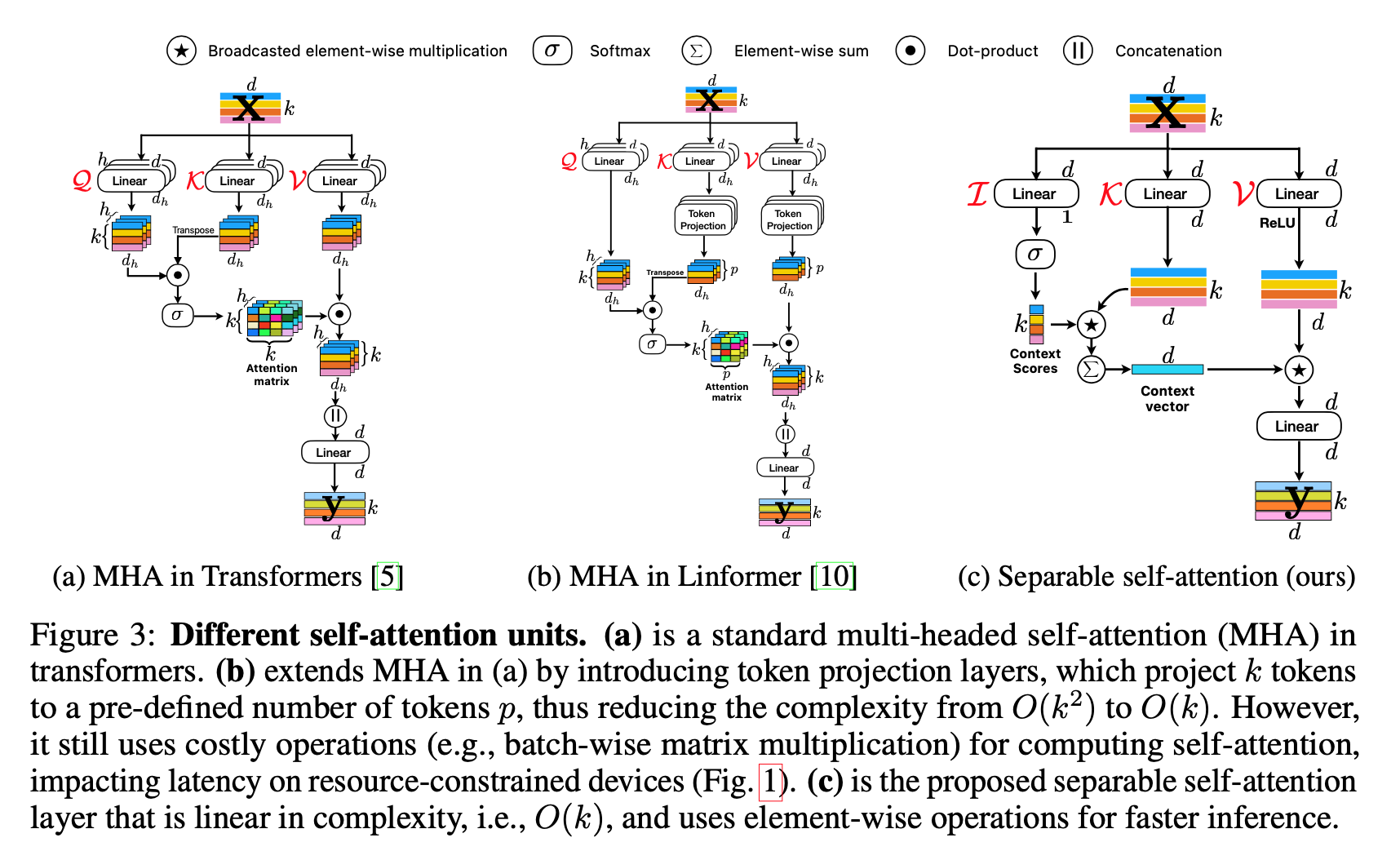
attention方式对比
- dense mm:两两做内积,然后对每个query指向的所有key的distance做归一化,attention是[b,q,q]
- separate method:对query[b,q,c]先计算一个context score [b,q],然后对key token [b,q,c]计算加权和[b,q,c],相当于对所有的key token基于context score做了reweight sum,来融合q & k,最终的attention是[b,q,c]
这样计算复杂度就与q-dim线形相关了
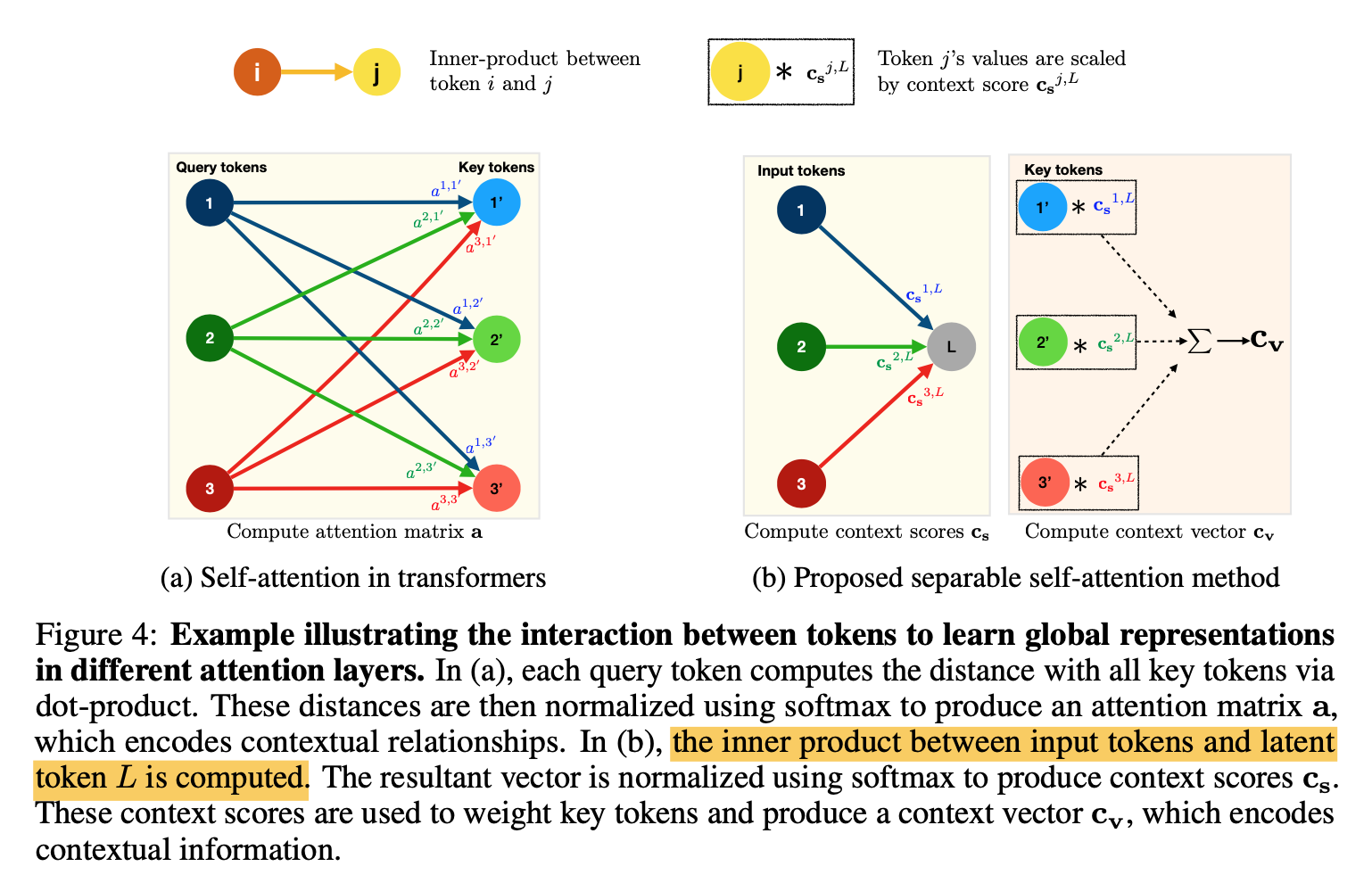
attention block结构对比
- standard MHA的attn有h个k*k的dense dot
- Linformer会压一下key/value token的长度,压到一个固定值,mm的算力下降,但是bmm的串行pipe还在
Separable self-attention
- query:[b,k,d]先fc到[b,k,1],然后softmax归一化得到context score,可以理解为各个query在整张图上的响应值高低
- key:[b,k,d]先fc到[b,k,d],然后与context score做broadcast乘得到[b,k,d],可以理解为基于query响应值高低对key做rescale来融合qk的信息,然后所有key vector相加得到[b,1,d],是全局的context vector
- value:[b,k,d]先fc-relu到[b,k,d],然后与context vector做broadcast乘得到[b,k,d],然后是project layer
code
1 | # https://github.com/apple/ml-cvnets/blob/main/cvnets/layers/linear_attention.py#L16 |