papers
[RVM 2021]: Robust High-Resolution Video Matting with Temporal Guidance
[SparseInst 2022]: Sparse Instance Activation for Real-Time Instance Segmentation
[GMA 2021]: Learning to Estimate Hidden Motions with Global Motion Aggregation
Robust High-Resolution Video Matting with Temporal Guidance
overview
- robust, real-time, high-resolution human video matting
- uses a recurrent architecture
- propose a new training strategy:多任务,既训matting,又训语义分割
LSTM & GRU & ConvLSTM & ConvGRU
Model Architecture
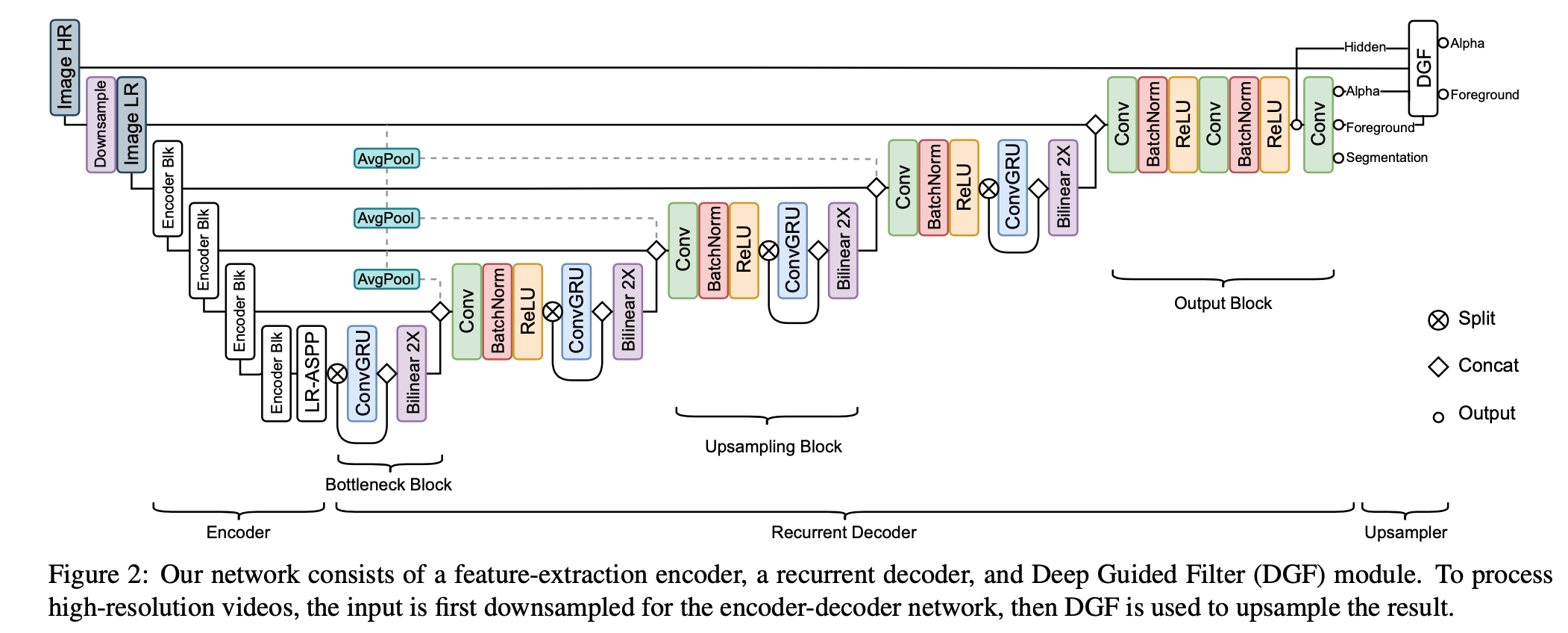
a single frame encoder
- MobileNetV3-Large:the last block of MobileNetV3 uses dilated convolutions,extract features [x2,x4,x8,x16]
- LR-ASPP
a recurrent decoder
- Bottleneck block
- 接在LRASPP后面的x16 feature上
- convgru只用了一半通道的feature,split&concat,因为convgru is computationally expansive,这样做既efficient,又能分解current frame feature和long-term temporal information
- 最后上采样
- Upsampling block
- 先concat上一个stage的feature,以及skip过来的encoder feature,以及input image downsampled by repeated 2x2 avg pool
- 然后conv-bn-relu:perform feature merging and channel reduction
- 然后是convgru block
- 最后上采样
- Output block
- 已经在原图尺度了,不做GRU了,only uses regular convolutions to refine the results
- 先concat input和上一个stage的feature
- 然后是2x conv-bn-relu
- 最后是prediction head
- 1-channel alpha prediction
- 3- channel foreground prediction
- 1-channel segmentation prediction
- Bottleneck block
- Deep Guided Filter Module for high-resolution upsampling
## Sparse Instance Activation for Real-Time Instance Segmentation
1. introduction
* Previous instance segmentation methods heavily rely on object detection and perform mask prediction based on bounding boxes or dense centers
* this paper
* propose a sparse set of instance activation maps(IAM),用来学习instance-level features
* bipartite matching机制抑制了dense prediction,不需要NMS
* object representation
<img src="VIS-methods/object representation.png" width="60%;" />
* center-based的点可能没有hit到instance上,导致获取的feature不准确
* region-based包含的内容又太多了
* IAM类似CAM,是instance-aware weighted maps,比较能抓住instance的主要特征
SparseInst
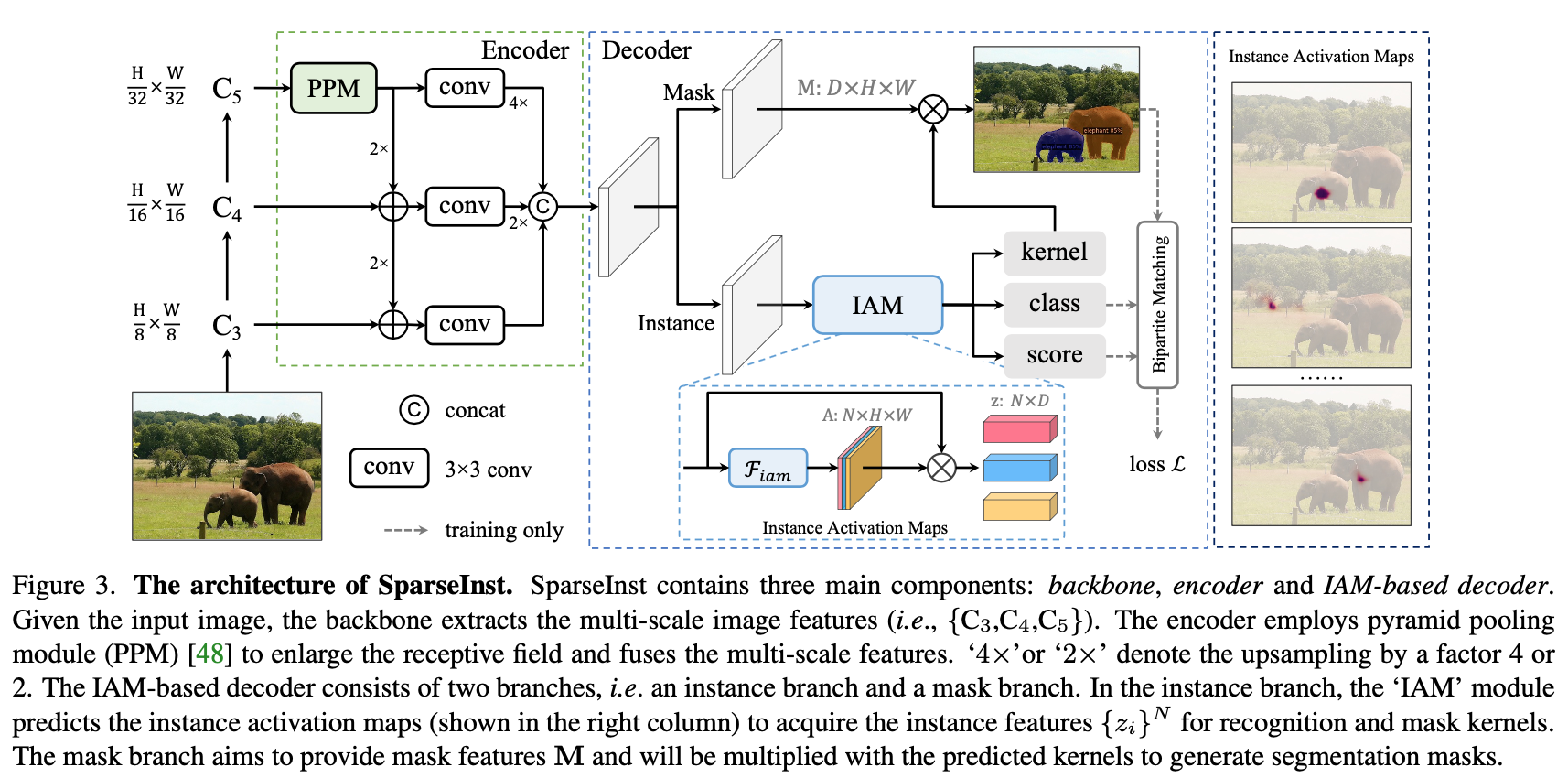
- encoder
- backbone: ResNet
- Instance Context Encoder: FPN,所有feature aggregate到x8一个level的输出
- IAM-based Segmentation Decoder
- mask branch
- instance branch
- 都是由 a stack of 3 × 3 convolutions with 256 channels构成
- encoder feature上还concat了xy的normed absolute coordinate
- Instance Activation Maps
- aim to highlight the informative regions for each object
- given image features $X \in R^{DHW}$
- IAM模块是a simple 3x3conv+ a sigmoid non-linearity:得到instance activation maps $A \in R^{NHW}$,N是sparse set,也可以用group conv(Group-IAM)
- instance features是instance activation maps乘image feature:相当于aggregate所有image feature according to attention区域,$z=\overline A \cdot X^T \in R^{ND}$
- 3 linear layers are applied for classification, objectness score, and mask kernel $\{w_i\}^N$
- IoU-aware Objectness
- 前背景比例不平衡,大部分predictions会被enforce成背景,整体的classification confidence会偏低,这会导致classification scores 和segmentation masks的效果的misalign
- 引入IoU prediction缓解这个问题
- at inference stage,classification probability被rescore成$\sqrt {probability * objectness}$
- Mask Head
- 每个mask kernel * mask feature
- encoder
grid sample
optical flow
光流是一个HxWx2的per-pixel矢量(u,v),表示img1到img2的偏移量:img1(x,y) = img2(x+u, y+u)
warp
1
2
3
4
5
6
7
8
9
10
11
12
13import torch
import torch.nn.functional as F
def warp(x, flow):
# x: [b,c,h,w]
# flow: [b,2,h,w]
h,w = x.shape[-2:]
grid_y, grid_x = torch.meshgrid(torch.arange(h), torch.arange(w))
grid_xy = torch.stack([grid_x, grid_y], dim=-1).unsqueeze(0) + flow.permute(0,2,3,1)
grid_xy[...,0] = 2 * grid_xy[...,0] / (w-1) - 1
grid_xy[...,1] = 2 * grid_xy[...,1] / (h-1) - 1 # norm to [-1,1]
warp_x = F.grid_sample(x, grid=grid_xy, mode='bilinear', padding_mode='border', align_corners=True)
return warp_xgrid sample
1
torch.nn.functional.grid_sample(input, grid, mode='bilinear', padding_mode='zeros', align_corners=None)
- input:BCHW
- grid:BHW2,取值范围在[-1,1]之间
- return:BCHW
- mode:[‘nearest’, ‘bilinear’]
- padding_mode:[‘zeros’, ‘border’, ‘reflection’]
deformable conv
采样点的值也可以用grid sample来实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class DeformConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size):
self.conv1 = nn.Conv2d(in_channels, kernel_size*kernel_size*2, kernel_size, padding=kernel_size//2)
self.conv2 = nn.Conv2d(in_channels, out_channels, kernel_size, stride=kernel_size, padding=kernel_size//2)
self.k = kernel_size
def forward(self, x):
b, c, h, w = x.shape
offsets = torch.split(self.conv1(x), [self.k*self.k*2, self.k], dim=1)
grid_y, grid_x = torch.meshgrid(torch.arange(h), torch.arange(w))
grid_xy = torch.stack([grid_x, grid_y], dim=1).unsqueeze(0)
kernel_feats = []
for i in range(self.k*self.k):
loc = grid_xy + offsets[:,k]
loc[:,0] = 2 * loc[:,0] / (w-1) - 1
loc[:,1] = 2 * loc[:,1] / (h-1) - 1
kernel_feats.append(F.grid_sample(x, grid=loc, mode='bilinear', padding_mode='border', align_corners=True)) # bchw
feats = torch.stack(kernel_feats, dim=-1).reshape(b,c,h,w,k,k)
feats = feats.permute(0,1,2,4,3,5).shape(b,c,h*k,w*k)
feats = slef.conv2(feats) # bchw
return feats1x1的deformable conv可以理解为对feature学习learnable flow
feature align