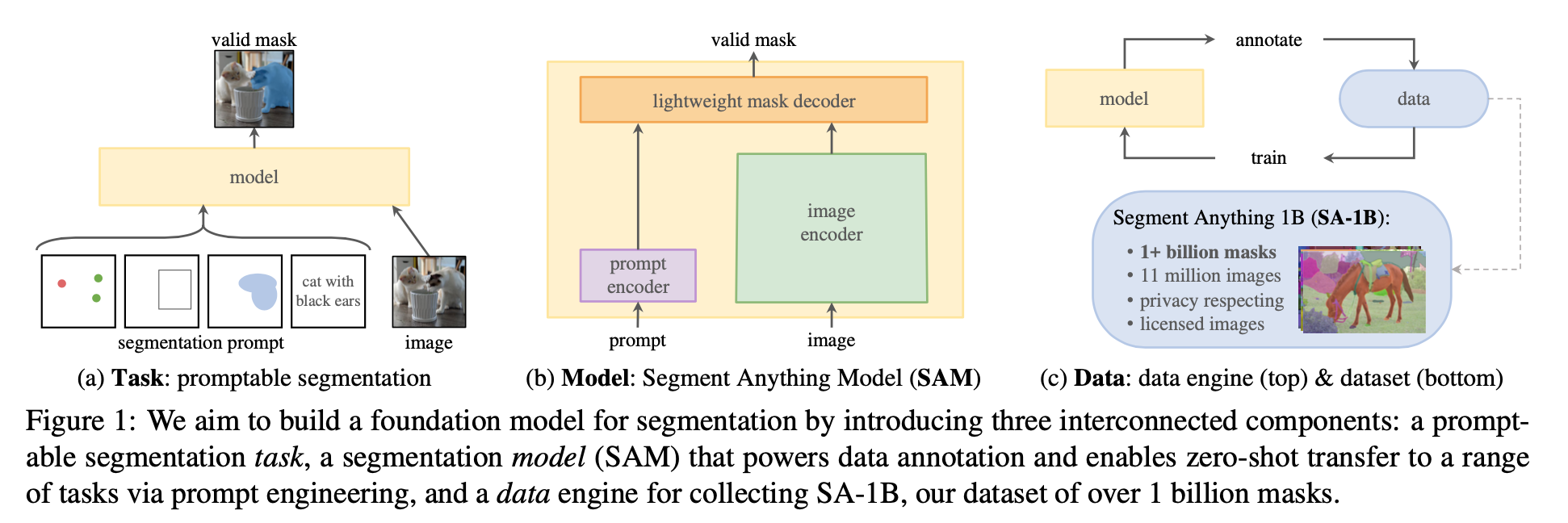
overview
- task:propose a prompt-able segmentation task
- model:build SAM model,promptable,enabling zero-shot
dataset:1B数据集,滚标注的半自动标注方案
introduction
- foundation model
- models that can generalize to unseen/untrained tasks and data
- often implemented with prompt engineering
- 图像领域最有名的就是CLIP/Align:aligns paired text and images from the web use contrastive learning
- SAM也被构建成foundation model
- pre-train it on a broad dataset,enables powerful generalization
- aim to solve a range of downstream segmentation problems on new data distributions using prompt engineering
- model constrains
- flexible prompt:point, box, and mask / initial results of free-form text prompts
- real-time:一张图的embedding可以被各种prompt复用,轻量的prompt encoder&mask decoder
- ambiguity-aware:一个prompt可以预测多个mask,allowing SAM to naturally handle ambiguity
- data engine
- stage1:assisted-manual,传统滚标注
- stage2:semi-automatic,用prompt的方式自动标注部分object,人工标注其余的
- stage3:fully automatic,将prompt设定为a regular grid of foreground points,自动全图标注
- foundation model
Segment Anything Task
- promptable segmentation task
- prompt:a set of foreground / background points, a rough box or mask, free-form text…
- return a valid segmentation mask:multiple object when ambiguous
- pre-training
- input:for each training sample,simulates a sequence of prompts (e.g., points, boxes, masks)
- supervision:compares the model’s mask predictions against the ground truth
- zero-shot transfer
- at inference time,模型已经具备对任何prompt作出相应的能力
- thus downstream tasks can be solved by engineering appropriate prompts,所以downstream tasks可以建模成prompts engineering的任务
- promptable segmentation task
Segment Anything Model
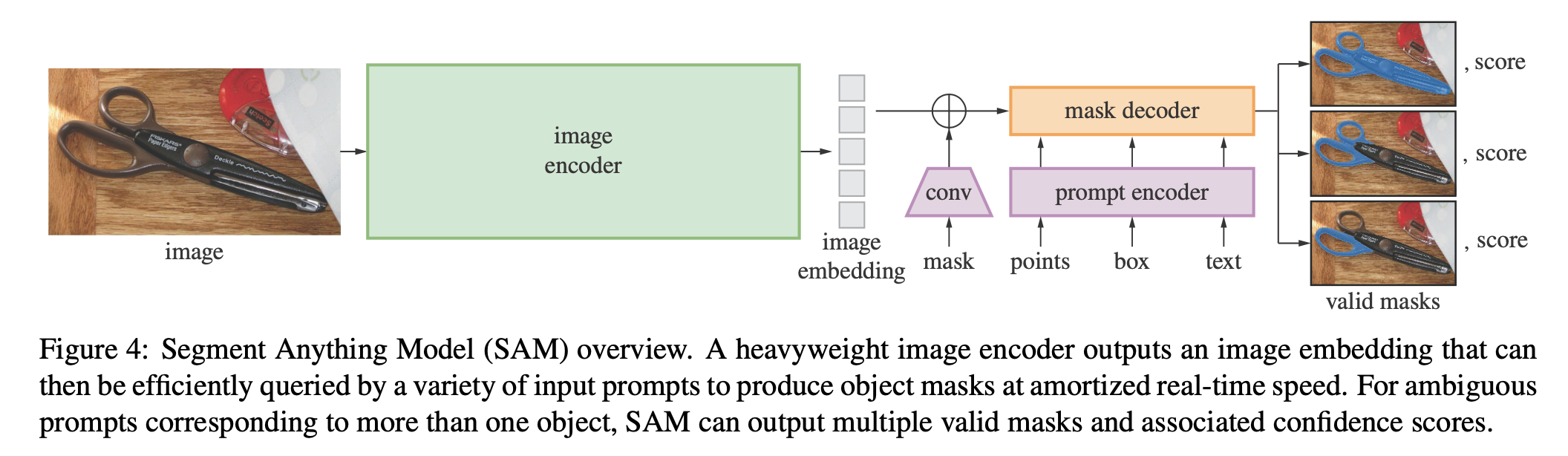
image encoder
- MAE pretrained ViT:ViT-H/16 with 14x14 windowed attention,1024×1024
- minimally adapted to process high resolution inputs
- outputs x16 image features:64x64
- into image embeddings:conv1,dim256 - LN - conv3-dim256 - LN
prompt encoder
- sparse prompts:
- point: a positional embedding + learned bg/fg embedding
- box: an embedding pair, (1) a left-top corner positional embedding + earned left-top corner embedding, (2) a bottom-right
- points/box: positional encodings + learned embeddings for each prompt type
- text: any text encoder from CLIP
- dim256
- dense prompts:
- input x4 ds masks: downscale additional x4
- 2x2,s2,dim4 conv - LN - GeLU
- 2x2,s2,dim16 conv - LN - GeLU
- 1x1,s1,dim256 conv - LN - GeLU
- elewise-add on image embeddings
- if there is no mask prompt: add a learned ‘no mask’ mask embedding
- input x4 ds masks: downscale additional x4
- sparse prompts:
mask decoder
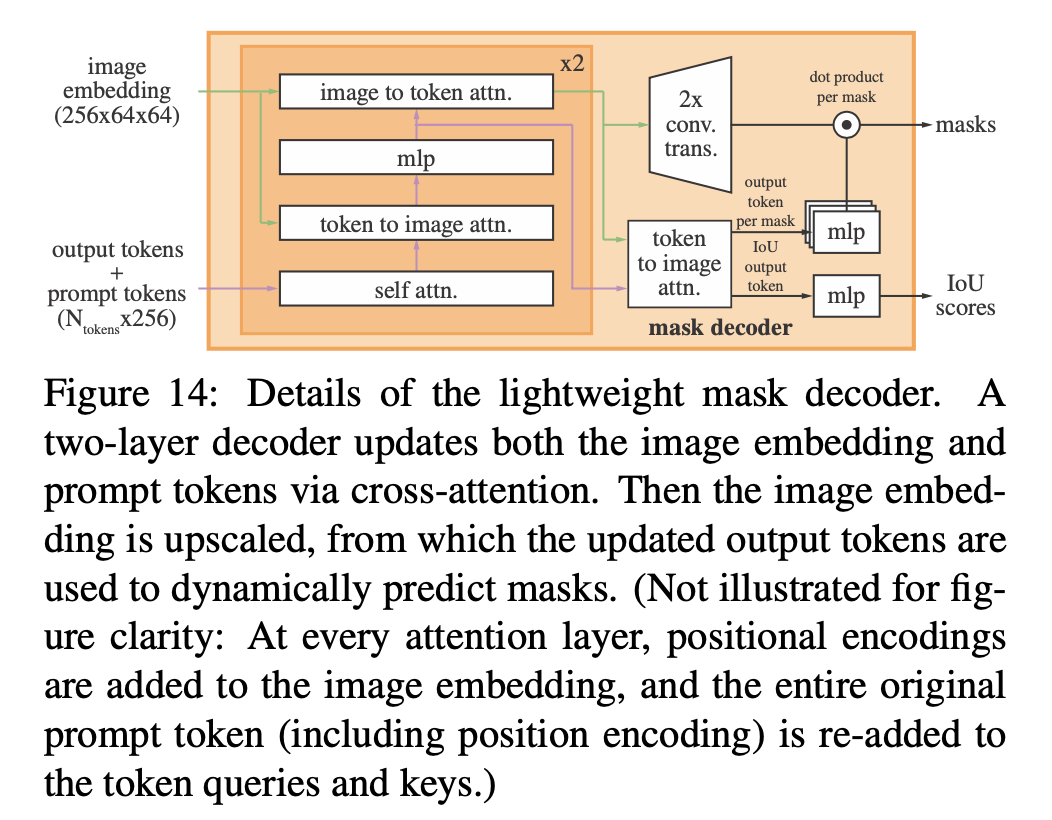
- insert a learned output token embedding:类似于cls token的东西,Nx256
- use a two-layer decoder
- 4 steps inside each decoder
- self-attention on the tokens
- cross-attention from tokens to images:QKVdim128
- a point-wise MLP updates each token
- cross-attention from the image to tokens:QKVdim128
- MLP:drop0.1,with residual,use LN,dim2048
- geometric和task type的强约束
- image emb每次参与attention都要加上positional encodings
- tokens每次参与attention都要加上原始的original prompt tokens
- dynamic prediction head
- upsample the updated image embedding by 4× with two transposed convs
- 2×2, s2, dim64 TransConv - GeLU - LN - 2×2, s2, dim32 TransConv - GeLU
- 得到upscaled mask embedding,64x64x32
- 用updated image embedding和updated tokens再做一次attn,提取output token,经过一个3-layer MLP得到一个vector:Nx32
- 最后通过dot product得到Nx64x64的prediction mask
- upsample the updated image embedding by 4× with two transposed convs
- ambiguity-aware
- use 3 output tokens,predict 3 masks(whole, part, and subpart)
- 计算3组mask loss,但是只回传the lowest loss的梯度
- 在output tokens上再接一个small head,用来estimates IOU,inference time用这个IoU prediction来rank3个mask
- loss
- mask loss:focal loss*20 + dice loss*1
- iou loss:pred iou和mask iou的MSE
- Training algorithm for one sample
- init prompt:随机选取points/boxes作为input prompt
- points从gt masks中随机抽
- boxes基于gt masks的外接框做随机noisy deviation
- 接下来的points从pred mask和gt mask的error region中抽取
- 然后把pred mask也作为一个mask prompt输入给model:用的是unthresholded mask logits,而不是binary mask
- 这样迭代8+2个iteration
- init prompt:随机选取points/boxes作为input prompt