papers
[tinyViT ECCV2022] TinyViT: Fast Pretraining Distillation for Small Vision Transformers:微软,swin的todevice版本,用CLIP做unlabel KD
[topformer CVPR2022] TopFormer: Token Pyramid Transformer for Mobile Semantic Segmentation:
[mobileViT ICLR2022] MOBILEVIT: LIGHT-WEIGHT, GENERAL-PURPOSE, AND MOBILE-FRIENDLY VISION TRANSFORMER:苹果
[mobileformer CVPR2022] Mobile-Former: Bridging MobileNet and Transformer:微软
TopFormer: Token Pyramid Transformer for Mobile Semantic Segmentation
abstract
- task:semantic segmentation
- take advantage of CNNs & ViTs
- CNN-based Token Pyramid Module:MobileNetV2 blocks
- a ViT-based module Semantics Extractor
- verified on
- ADE20K:比mobileNetV3高5%的miou,同时latency更低
method
overview
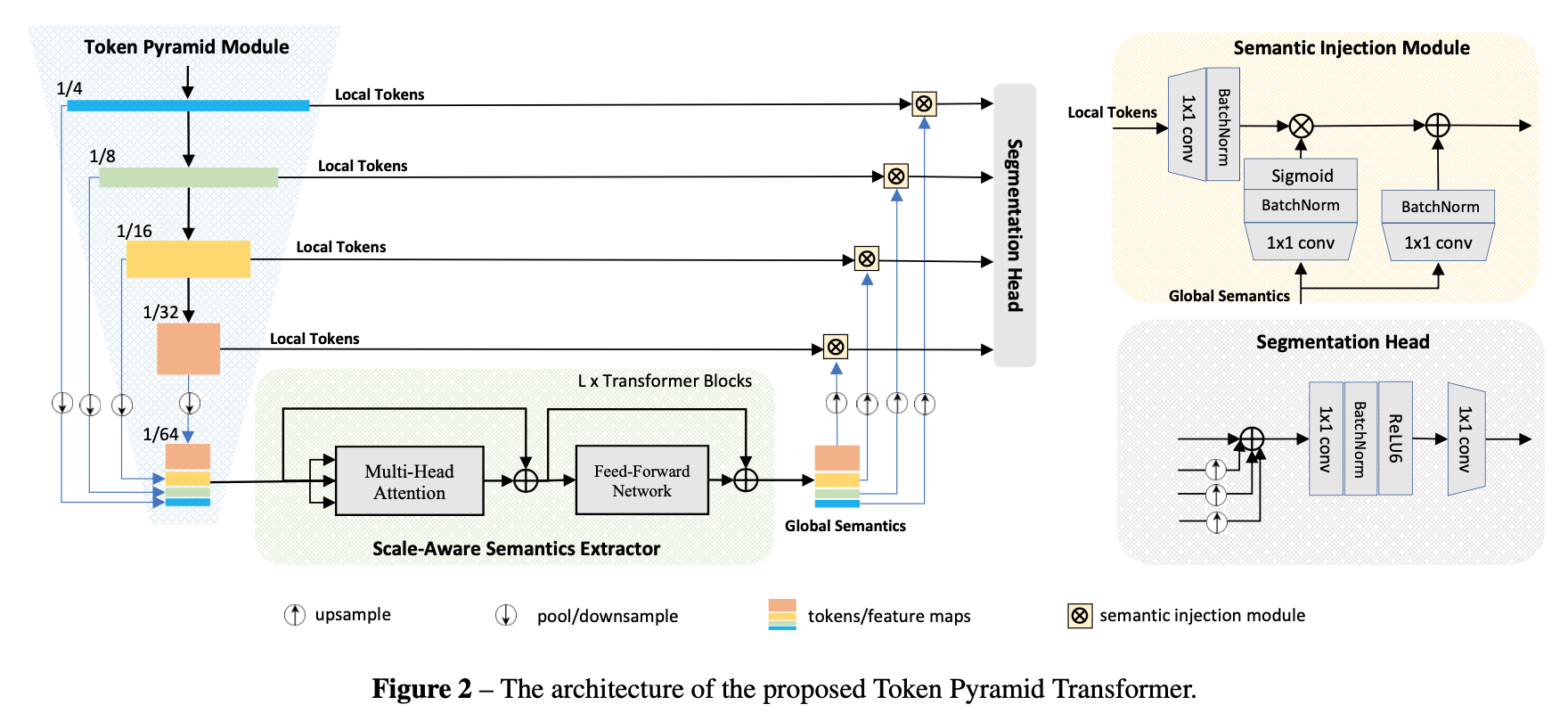
- Token Pyramid Module:输入image,输出token pyramid
- Semantics Extractor:输入token pyramid,输出scale-aware semantics
- Semantics Injection Module:将global semantics融合进对应level的local tokens里面,得到augmented representations
- Segmentation Head:fuse and predict
Token Pyramid Module
- use stacked MobileNet blocks来生成token pyramids
不是为了丰富的语义信息,也不是为了更大的感受野,只是为了得到multi-scale tokens,所以用比较少的层
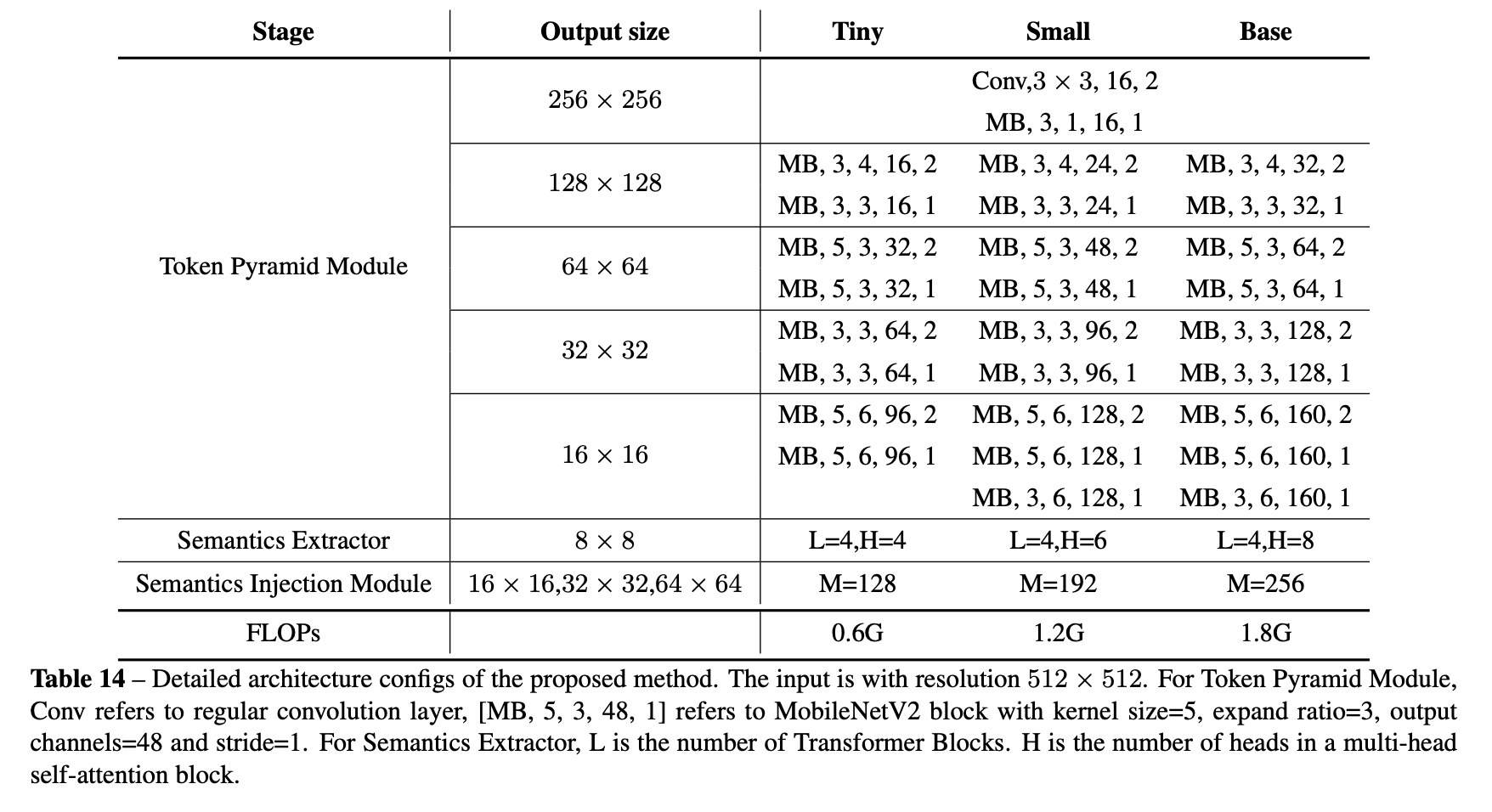
输入512x512的图
- 输出x4/x8/x16/x32的feature map
- 然后将multi-scale的features统一avg pool到x64,然后concat by dim,得到[b,(16+32+64+96),64,64]的tokens
Scale-aware Semantics Extractor
- 这部分用vision transformer来提取语义信息
- 首先为了keep the shape,将linear layer换成1x1 conv,把layernorm换成了batchnorm
- 所有ViT-stype GeLU换成ReLU6
- MSA的QK投影维度为16,V投影维度为32,降低similarity的计算量
- FFN的两层1x1卷积之间加了一个depth-wise卷积
Semantics Injection Module
- fuse local tokens 和 scale-aware semantics
- to alleviate the semantic gap
- local token经过一个1x1 conv-bn,用semantic token经过一个1x1conv-bn-sigmoid生成的weight map做加权
- 再加上一个1x1 conv-bn的semantic token
- (这个semantic token应该是要上采样的吧?)
Segmentation Head
- 所有的low-resolution tokens都上采样的high-resolution tokens的尺度(x8)
- 然后element-sum
- 然后两层卷积
实验
- datasets
- ADE20k:1+150,25k(20k/2k/3k)
- PASCAL Context:1+59,4998/5105
- COCO-Stuff10k:9k/1k
- training details
- iteration:ADE20k训练160k iteration,PASCAL和COCO训练80k iteration
- syncBN
- lr:baselr=0.00012,poly schedule with factor 1.0
- weight decay:0.01
TinyViT: Fast Pretraining Distillation for Small Vision Transformers
abstract
- tiny and efficient
- KD on large-scale datasets
- 用大模型的logits离线蒸馏
- 精度:21M:ImageNet 84.8%,use larger resolution:86.5%
- good transfer ability on downstream tasks
- linear probe
- few-shot learning
- object detection:COCO AP 50.2%
overview
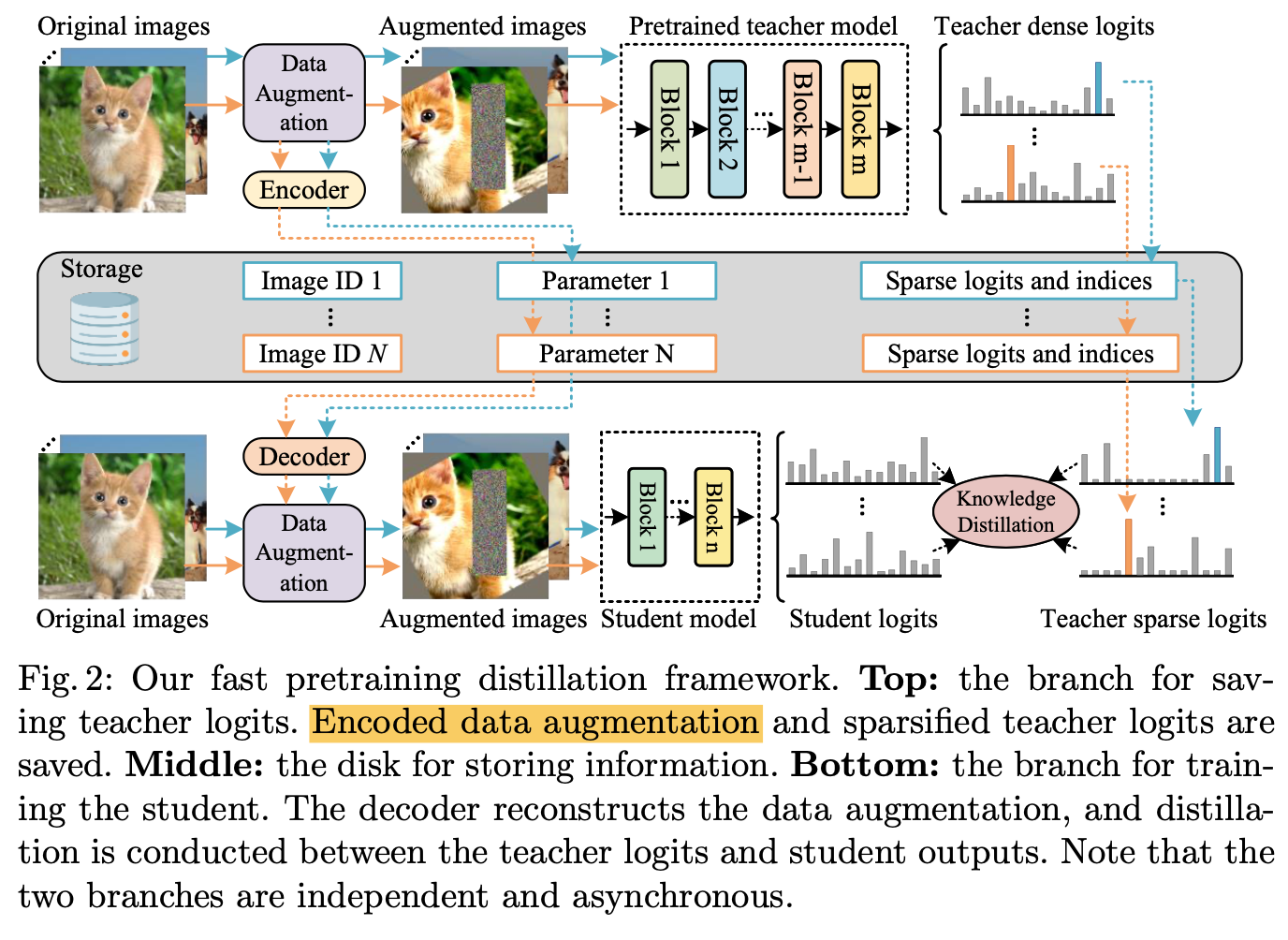
- 离线蒸馏
- 保存数据增强的参数和teacher logits
方法
- Fast Pretraining Distillation
- direct pretraining small models on massive data does not bring much gains,especially when transferring to downstream tasks,但是蒸馏的boost就十分显著了
- 一些方法在finetuning阶段进行蒸馏,本文focus on pretraining distillation:inefficient and costly
- given image x
- save strong data augmentation A (RandAugment & CutMix)
- save teacher prediction $\hat y=T(A(x))$
- 因为RandAugment内置随机性,同样的增强方式每次结果也不同,因为每个iteration的A都要存下来
- 用ground truth的one-hot label去蒸馏的效果反而不如unlabeled logits,因为one-hot太overfit了
- Sparse soft labels:imagnet21k的logits有21, 841个,为了节约只保存topK logits and indices,其余的用label smoothing
- Data augmentation encoding:
- 将一系列data aug params encode成一个scalar d
- 然后通过decoder将其还原:PCG输入single parameter,输出a sequence of parameters
- 实际实现的时候,就是存下一个d0,然后用PCG对T&S解码增强参数
- Model Architectures
- adopt hierarchical vision transformer,从大模型开始,定义一系列contraction factors,开始scaling down
- patch embedding:2个3x3 convs,stride2,pad1
- stage1:MBConvs & down sampling blocks
- stage2/3/4:transformer blocks with window attention
- attention biases
- a 3 × 3 depthwise convolution between attention and MLP
- 常规的residuals、LayerNorm依旧保留,conv的norm是BN,所有activation都是GELU
- Contraction factors
- embeded dimension:21M-[96,192,384,576],11M-[64,128,256,448],5M-[64,128,160,320]
- number of blocks:[2,2,6,2]
- window size:[7,14,7]
- channel expansion ratio of the MBConv block:4
- expansion ratio of MLP:4
- head dimension:32
- adopt hierarchical vision transformer,从大模型开始,定义一系列contraction factors,开始scaling down
- Fast Pretraining Distillation