cityscape leaderboard:
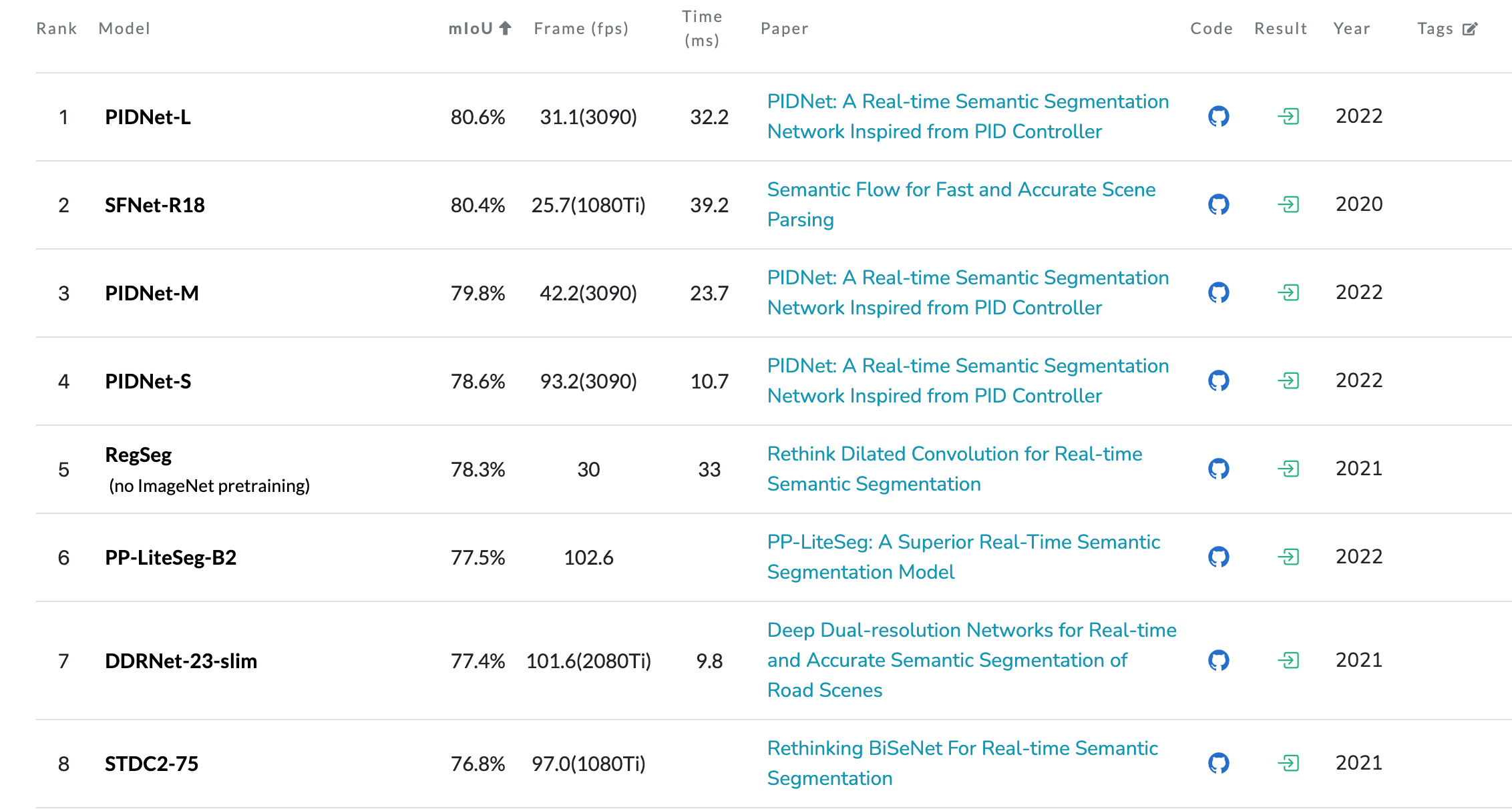
- [PIDNet 2022] PIDNet: A Real-time Semantic Segmentation Network Inspired from PID Controller
- [SFNet v1 2020] Semantic Flow for Fast and Accurate Scene Parsing
- [SFNet v2 2022] SFNet: Faster, Accurate, and Domain Agnostic Semantic Segmentation via Semantic Flow
- [PP-LiteSeg 2022] PP-LiteSeg: A Superior Real-Time Semantic Segmentation Model
- [DDRNet 2021] Deep Dual-resolution Networks for Real-time and Accurate Semantic Segmentation of Road Scenes
- [STDC-Seg 2021CVPR] Rethinking BiSeNet For Real-time Semantic Segmentation
PP-LiteSeg: A Superior Real-Time Semantic Segmentation Model
main contributions
- propose a Flexible and Lightweight Decoder (FLD):主要就是FPN的通道数
- propose a Unified Attention Fusion Module (UAFM):强化特征表达
- propose a Simple Pyramid Pooling Module (SPPM):简化PPM,low computation cost
real-time networks设计思路
- Strengthening feature representations:decoder中low-level和high-level特征的融合方式
- Contextual aggregation:花式PPM
overview
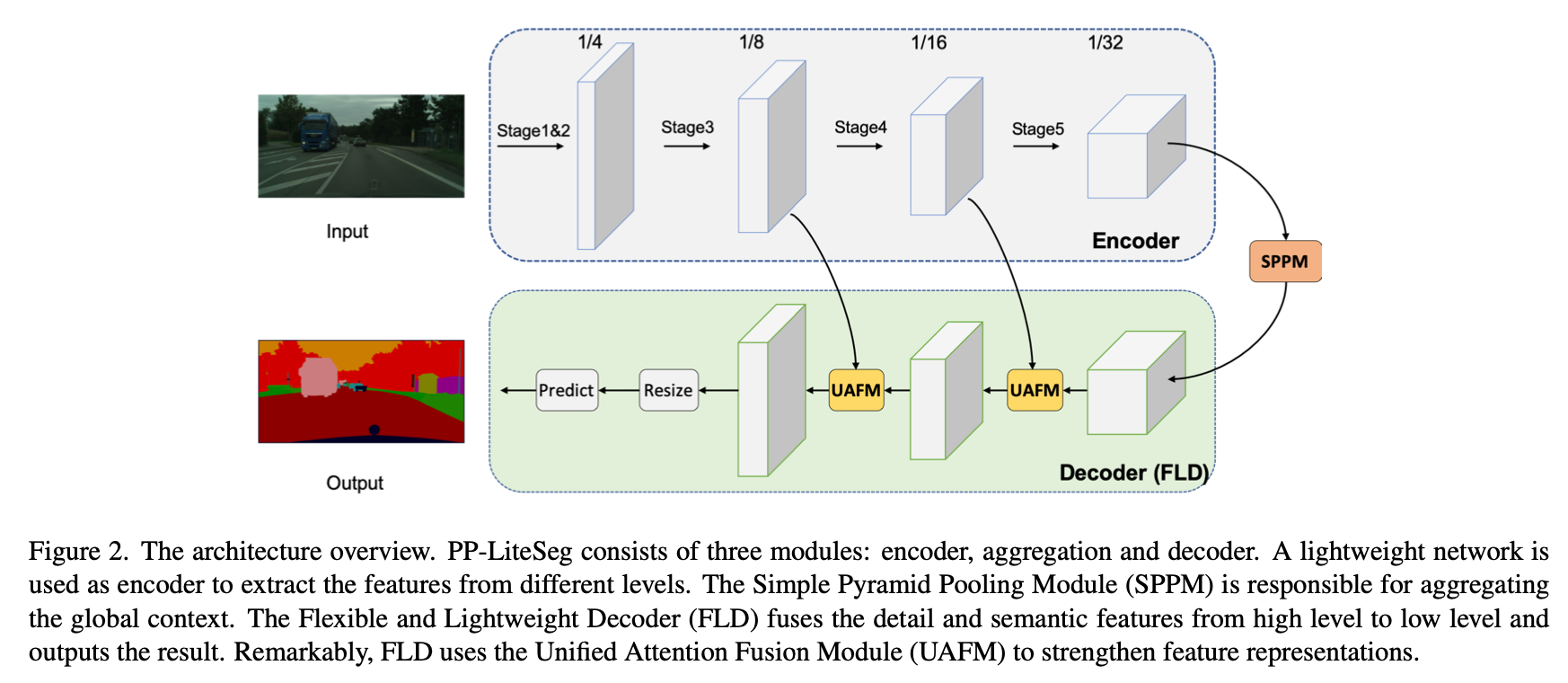
方法
Flexible and Lightweight Decoder
- recent lightweight models中的decoder在恢复resolution的过程中通道数保持不变:cause computation redundancy
- FLD从high-level到low-level逐渐减少通道数
Unified Attention Fusion Module
- 用一个attention module来产生weight map
然后对不同尺度的特征做加权和
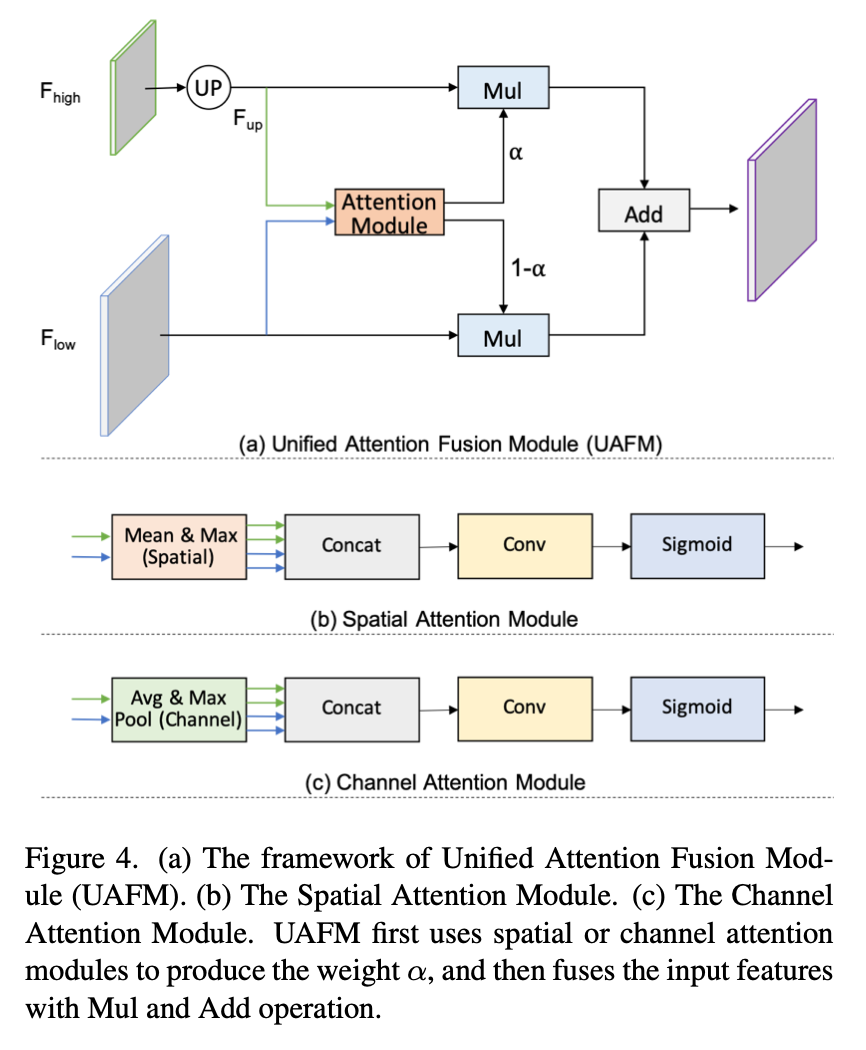
Spatial Attention Module
- 实际代码中用的这个
- 在channel维度上做mean & max,两个feature共得到4个[1,h,w]的map,concat在一起[4,h,w]
- 然后做conv+sigmoid得到weight map [1,h,w]
- 然后做element-wise的mul&add
- Channel Attention Module
- 在spacial map上做avg pooling和max pooling,两个feature共得到4个[c,1,1]的vector,concat在一起[4c,1,1]
- 然后做conv+sigmoid得到channel importance vec [c,1,1]
- 然后做channel-wise的mul&add
Simple Pyramid Pooling Module
- 主要改动
- reduce intermediate and output channels
- remove the short-cut
- replace concat with add
- 就3个global average pooling,得到1x1、2x2、4x4的map,然后分别conv-bn-relu,然后resize回原来的尺度
然后add & conv
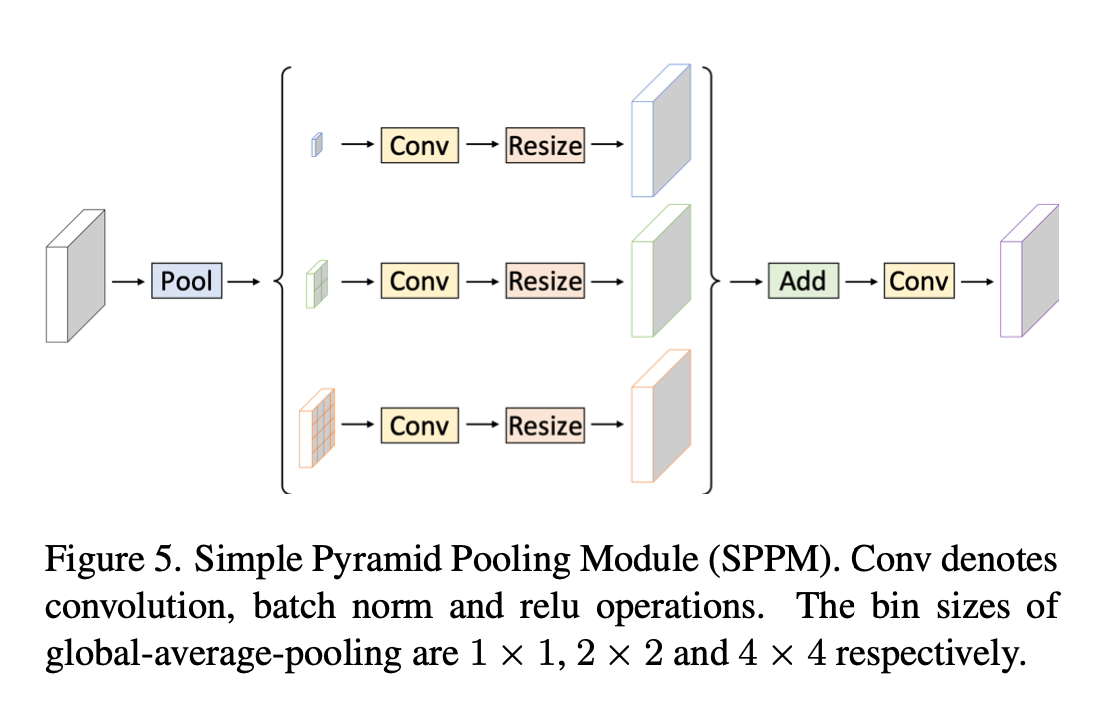
- 主要改动
实验
- datasets
- Cityscapes:1+18,5,000(2975/500/1525),原始尺寸是2048x1024
- CamVid:11类,701(367/101/233),原始尺寸是960x720
- training settings
- SGD:momentum=0.9
- lr:warmup,poly,
- Cityscapes训练160k,batchsize=16,baselr=0.005,weight decay=5e-4
- CamVid训练1k,batchsize=24,baselr=0.01,weight decay=1e-4
- dataaug
- random scale:scale range [0.125, 1.5] / [0.5, 2.5] for Cityscapes/CamVid
- random crop:crop size=[1024,512] / [960,720]
- random horizontal flipping / color jitting / normalization
- datasets
SFNet: Faster, Accurate, and Domain Agnostic Semantic Segmentation via Semantic Flow
动机
- widely used atrous convolution & feaature pyramid: computation intensive or ineffective
- we propose SFNet & SFNet-Lite
- Flow Alignment Module (FAM) to learn sematic flow
- Gated Dual Flow Alignment Module (GD-FAM): directly align the highest & lowest resolution feature maps
- speed & accuracy
- verified on 4 driving datasets (Cityscapes, Mapillary, IDD and BDD)
- SFNet-Lite-R18 back: 80.1 mIoU / 60 FPS
- SFNet-Lite-STDC back: 78.8 mIoU / 120 FPS
方法
previous methods
- FCN
- 开创性的工作
- lack of detailed object boundary information due to down-sampling
- deeplab
- atrous convolutions (last 4/5 stage)
- multiscale feature representation (ASPP)
- vision transformer
- 建模成query-based per-segment prediction
- strong performance but real time inference speed不理想
- FCN
trade-off
- maintain detailed resolution:空洞卷积,resolution大计算量就大,很难实时
- get features that exhibit strong semantic representation:biFPN style feature merge,有一定提升,但还是不如those hold large feature maps
- 本文的推测是:ineffective propagation of semantics from deep layers to shallow layers,across level的semantics are not well aligned,粗暴的downsample再upsample,无法恢复细节边缘信息
this paper
- propose FAM & SFNet
- 不同stage的feature之间,先做alignment,warp low level feature之后再merge
- R18-back: 79.8% mIoU / 33 FPS on cityscape
- DF2-back:77.8% mIoU / 103 FPS
propose GD-FAM & SFNet-Lite
- 为了更快,把密集的FAM换成只做一次的GD-FAM
- 只merge this highest & lowest尺度的features
- ResNet-18 back:80.1% mIoU / 49 FPS on cityscape
- STDCv1-back: 78.7 mIoU / 120 FPS
- propose FAM & SFNet
方法
出发点: the misalignment between feature maps caused by residual connection, repeated downsampling and up- sampling operations
inspiration:dynamic upsampling interpolation
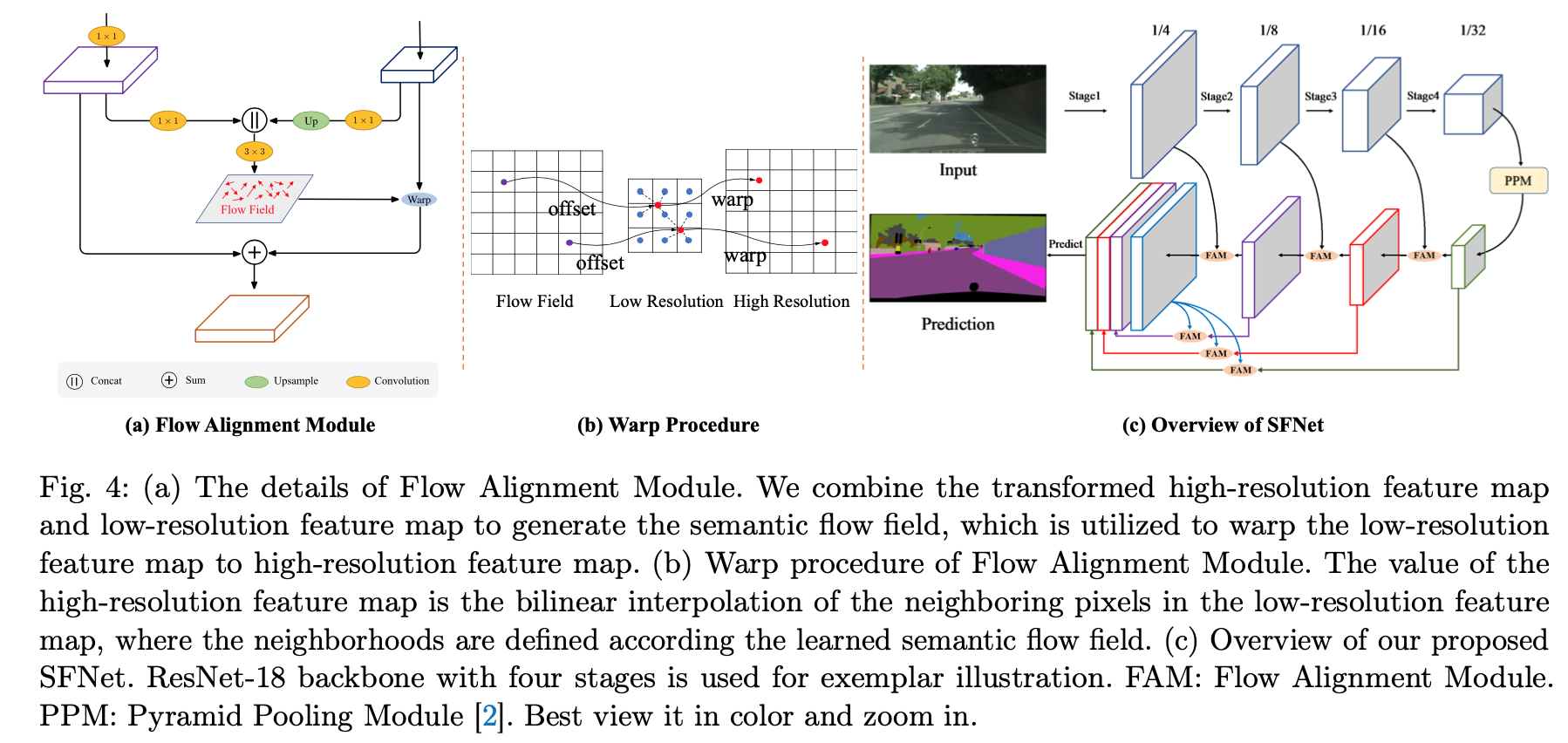
FAM
build in the FPN framework
define Semantic Flow:between different levels in a feature pyramid
pipeline
- 首先通道对齐
- 然后上采样,尺度对齐,$F \in R^{H\times W \times C}$
- 然后concat两个level的特征,(但是没有像真正的光流对齐FlowNet一样再concat上grid coordinates)
- 然后用两层3x3的卷积做semantic flow field的预测,$\Delta_{low-level} \in R^{H\times W\times 2}$
- 然后warp low-level feature
然后add & halve

和deformable conv的区别
- 首先这个offset是通过融合两个尺度特征得到的,DCN是特征自己预测的
- 其次DCN是为了得到更大的/更自由的reception field,more like attention,本文是为了align feature
可以看到warp & add以后的feature map相比较于直接上采样然后add,更加structurally neat,目标可以有更consistent的representation
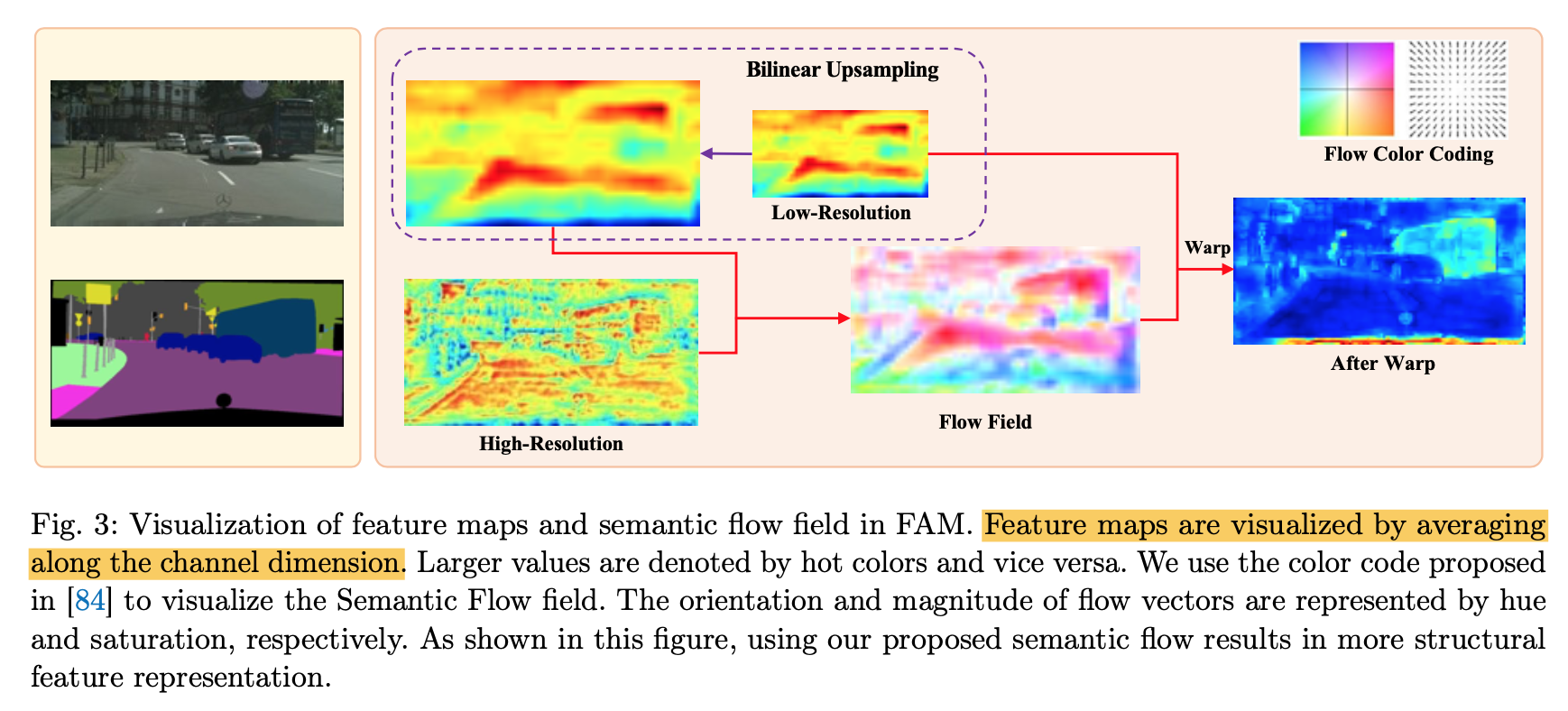
the whole network
- backbone
- ImageNet pretrained ResNet / DF series
- 4 stages
- stride2 in the first place per stage
- Pyramid Pooling Module (PPM),ASPP/NL is also experimented,后面实验部分说精度不如PPM
- Aligned FPN decoder
- encoder那边过来的stage2/3/4的low-level feature,被FAM aligned,然后fused into their bottom levels
- 最终的x4的prediction feature,concat来自所有尺度的特征,考虑到也存在mis-alignment,本文也实验性的添加了PPM,但是在real-time application中没加
- backbone
Gated Dual Flow Alignment Module and SFNet-Lite
上述版本的SFNet,在speed上是比BiSegNet慢的,thus we explore more compact decoder
takes F1 & F4 as inputs
outputs a refined high-resolution map
pipeline
- 首先将F4上采样的F1的resolution
- 然后concat,然后3x3convs,预测offsets,$\Delta \in R^{H\times W\times 4}$
然后split成$\Delta_{F1}$和$\Delta_{F4}$,分别给到F1和F4做align
再用F1和F4生成一个gate map,attention-style的结构,用pooling,1x1 conv和sigmoid,给两个warped feature做gated sum,思路是make full use of high level semantic feature and let the low level feature as a supplement of high level feature
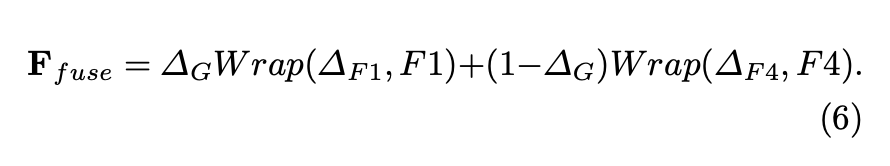
SFNet-Lite structure
实验
STDC-Seg: Rethinking BiSeNet For Real-time Semantic Segmentation
动机
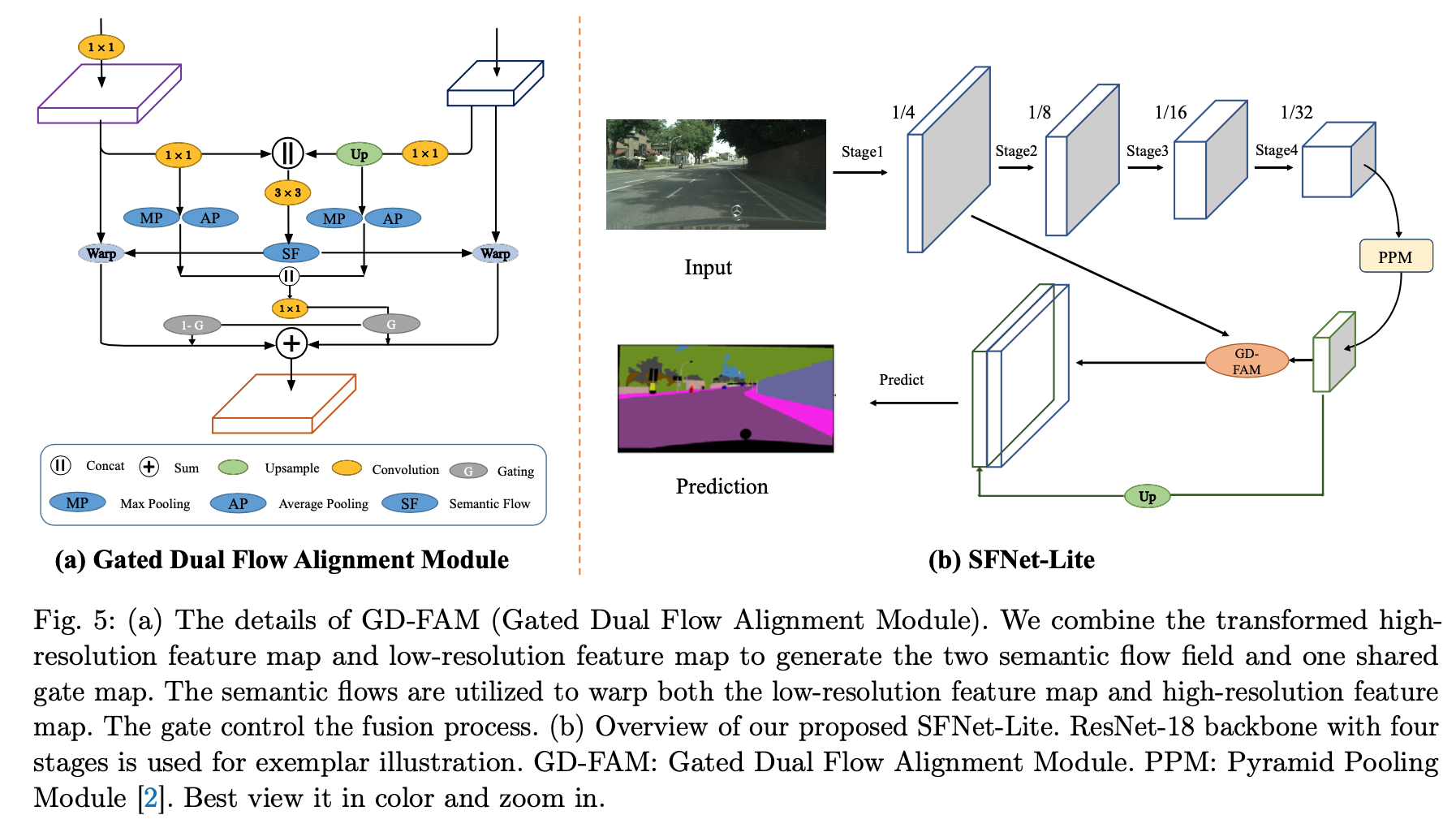
- BiSeNet
- use extra path to encode spatial information (low-level)
- time consuming
- not convenient to use pretrained backbones
- the auxiliary path is always lack of low-level information guidance
- this paper
- 回归test-time singe-stream manner
- 用一个Detail guidance module来促进backbone的low-level stage学习spatial feature,有直接监督,且test-time free cost
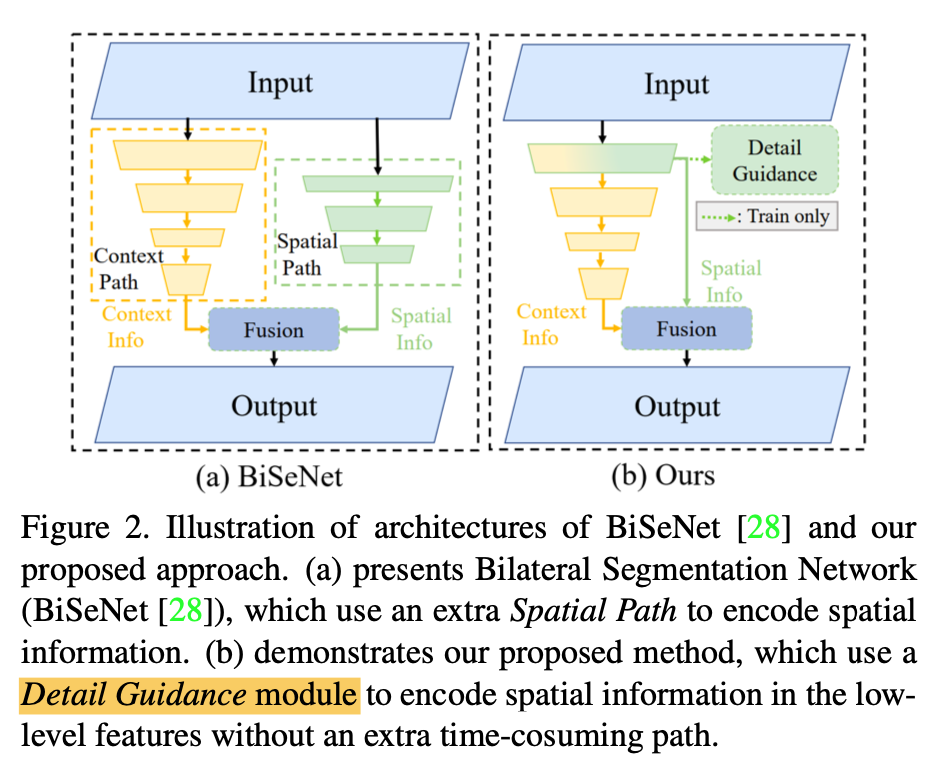
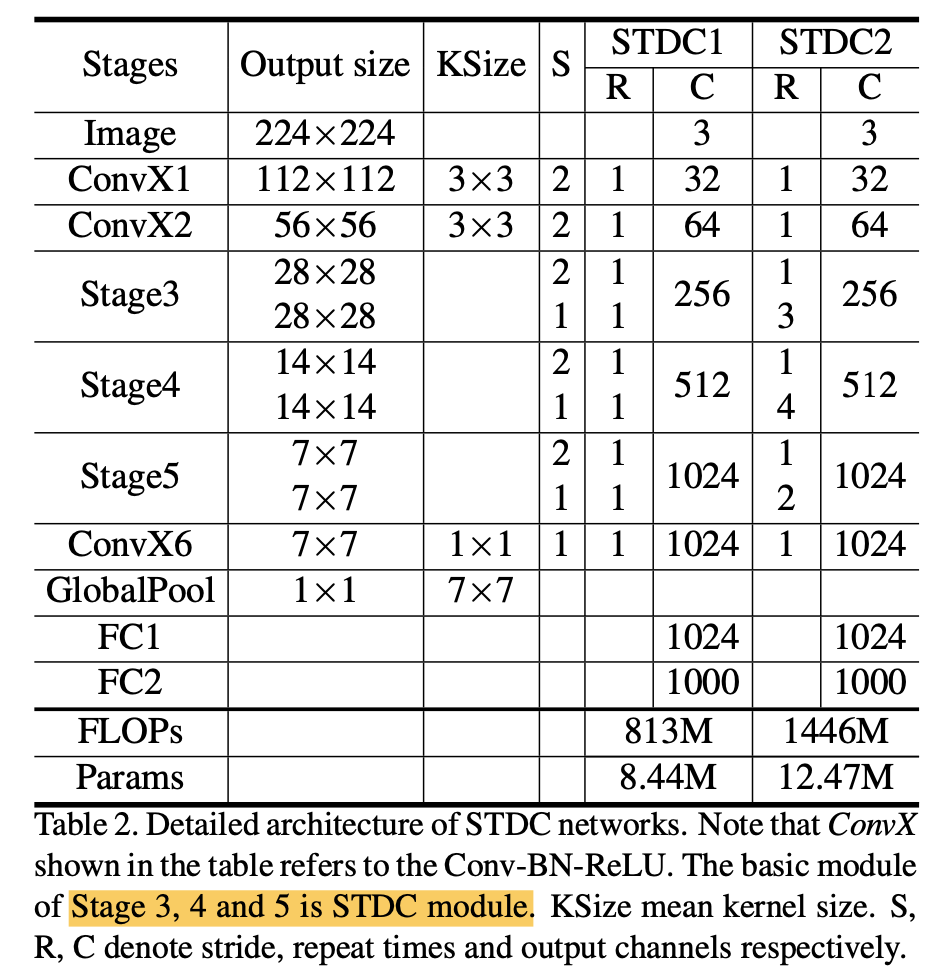
- 设计了STDC backbone,主要包含STDC module (Short-Term Dense Concatentae Network),有点类似denseNet的block
- verified on
- ImageNet
- Cityscapes: STDC1-Seg50 / 71.9% mIoU / 250.4 FPS, STDC2-Seg75 / 76.8% mIoU / 97.0 FPS
- CamVid
- BiSeNet
overview
single-stream
STDC backbone
方法
Short-Term Dense Concatenate Module
- each module is separated into several blocks:block1永远是1x1,block2/3/4是3x3
- the output gathers multi-scale information
一种是stride1的一种是stride2的,reception field如下

Classification Architecture
- stage1/2分别是一个conv-bn-relu
stage3/4/5是STDC Module,每个stage的第一个module用stride2
Segmentation Architecture
- STDC back:用stage3/4/5的feature map(x8/16/32)
- stage3的feature作为low-level feature
- stage4/5以及global pooling的stage5的feature作为high-level context feature,做FPN:stage4/5通过Attention Refine Module(类似SE),然后和前一个feature level做add,然后上采样,然后conv
- 以上的feature通过Feature Fusion Module(也类似SE block)融合
- SegHead:3x3conv-1x1conv
stage3的feature上还接了一个DetailHead
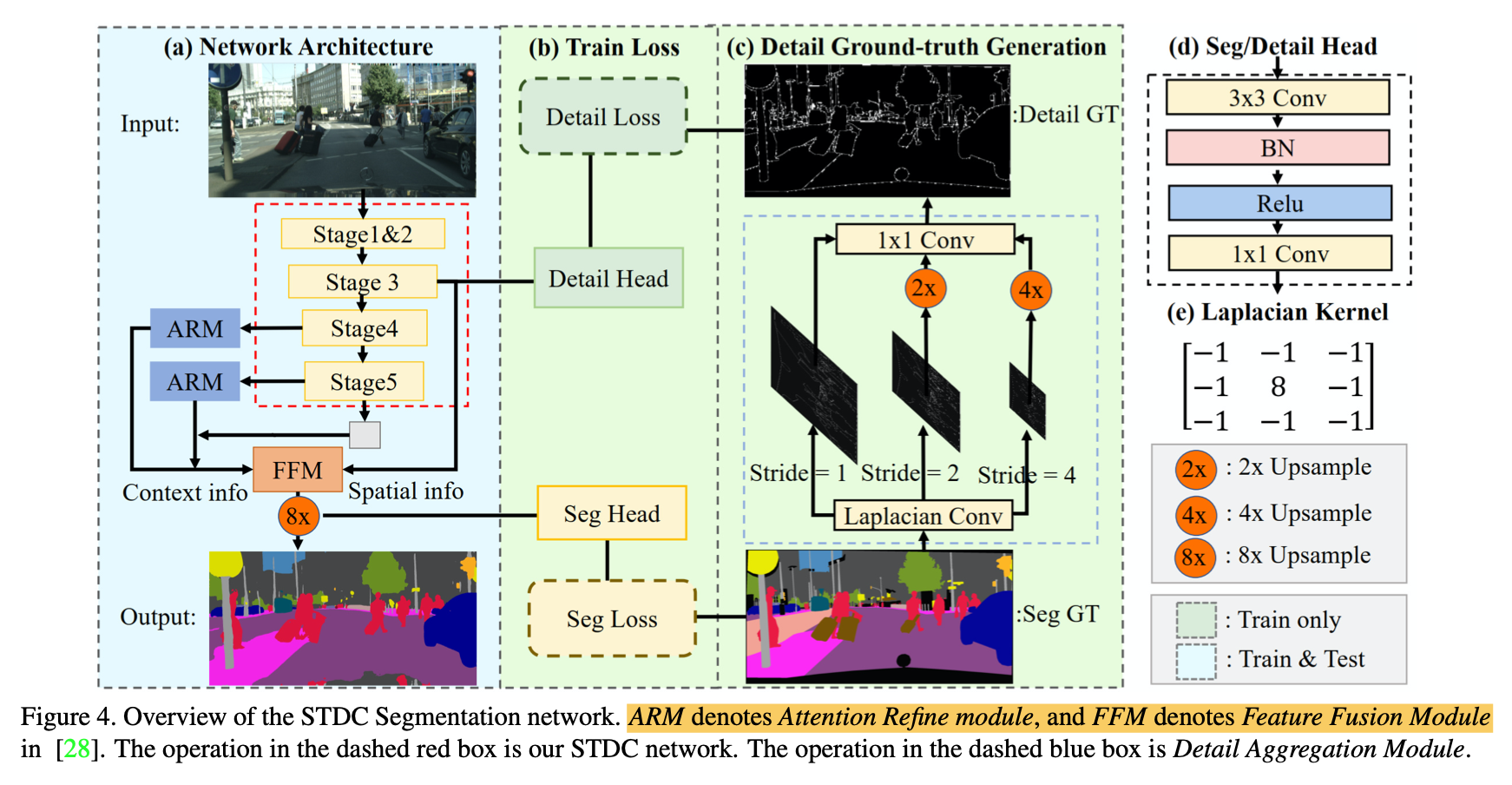
Detail Guidance of Low-level Features
- detail path是用来encode spatial detail(boundary/corner)
- 建模成binary segmentation task
- 首先将ground truth map通过Detail Aggregation module得到detail map
- 一个stride1/2/4的Laplacian operator(conv kernel)
- 然后是upsampling
- 然后fuse and 1x1 conv
- 最后用thresh 0.1转换成binary detail mask
- detail loss:dice + bce
有了detail guidance以后能够force backbone的stage3 feature保留更加detail的low-level feature

实验
backbone实验
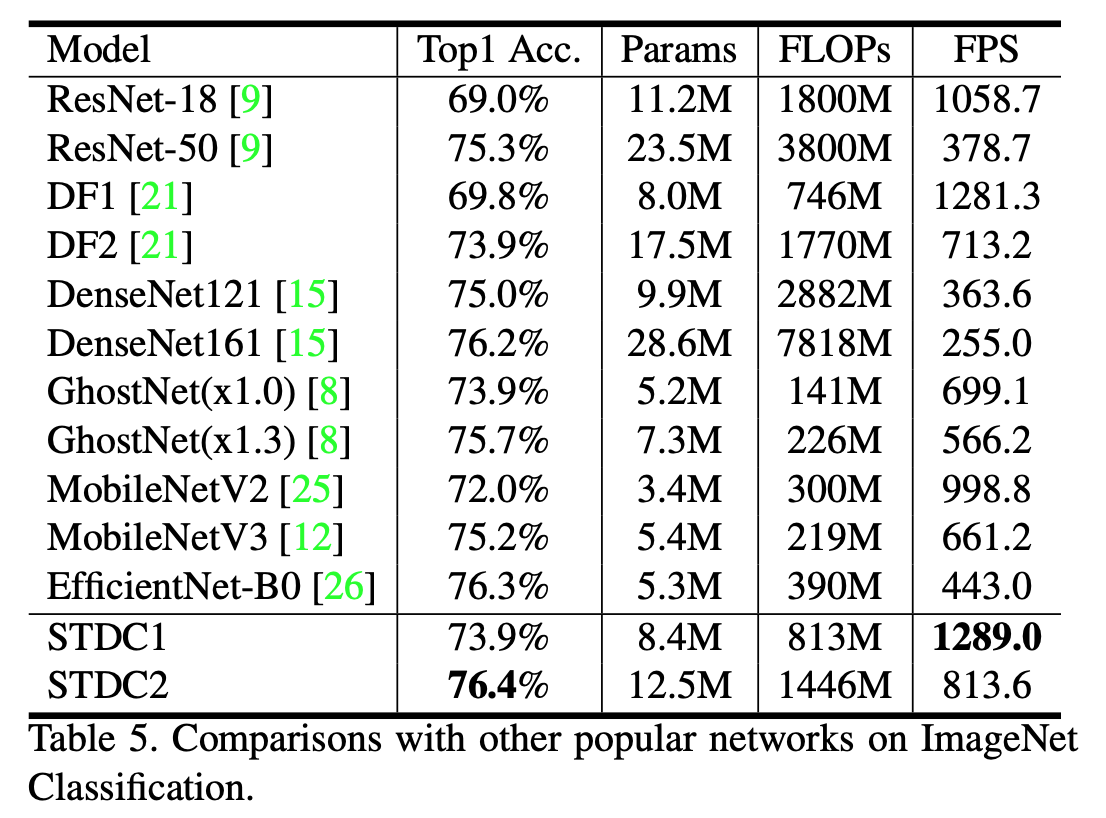
对标MobileNetV3和EfficientNet-B0,精度和速度都是更好的
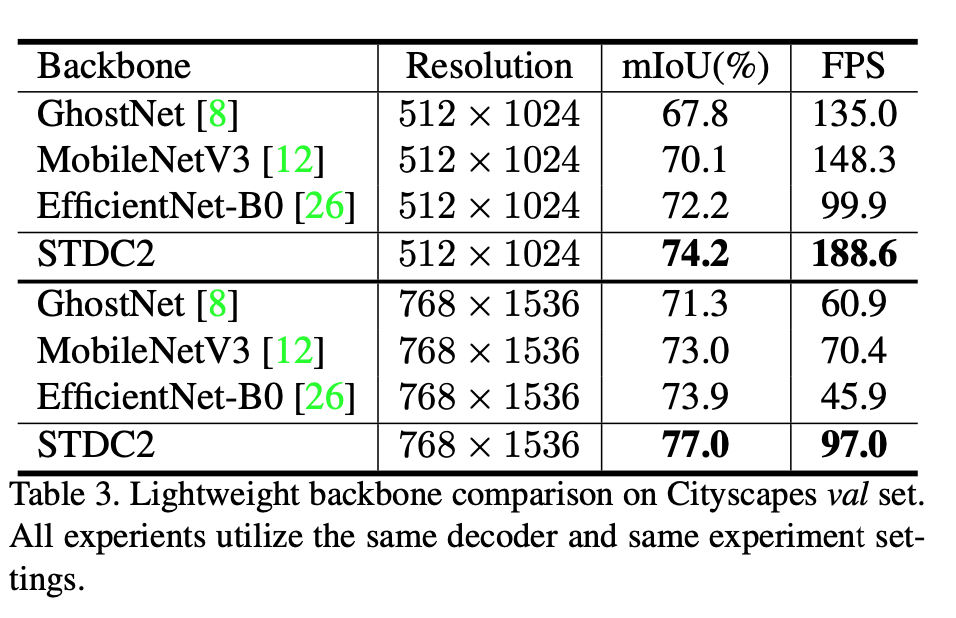
ImageNet精度&Flops,Flops比较大,但都是3x3卷积,推理速度更快