自监督papers
MoCo系列:contrastive-based
[2019 MoCo v1] Momentum Contrast for Unsupervised Visual Representation Learning,kaiming
[2020 SimCLR] A Simple Framework for Contrastive Learning of Visual Representations,Google Brain,混进来是因为它improve based on MoCo v1,而MoCo v2/v3又都是基于它改进
[2020 MoCo v2] Improved Baselines with Momentum Contrastive Learning,kaiming
[2021 MoCo v3] An Empirical Study of Training Self-Supervised Visual Transformers,kaiming
MAE:reconstruct-based
[2021 MAE] Masked Autoencoders Are Scalable Vision Learners:恺明,将BERT的掩码自监督模式搬到图像领域,设计基于masked patches的图像重建任务
MIM:reconstruct-based
[2021 SimMIM] SimMIM: A Simple Framework for Masked Image Modeling:微软,swin v2的scale up模型用了这个自监督方法来缓解data hungary issue
[2022 MIM] Revealing the Dark Secrets of Masked Image Modeling:微软,类似上一篇的展开实验part,
SimMIM: a Simple Framework for Masked Image Modeling
动机
- propose a simple framework of MIM
- without the need of special designs
- simple designs revealed strong learning performance
- major components
- 使用较大patch size:random masking of the input image with a moderately large masked patch size (e.g., 32) makes a powerful pre-text task
- 进行pixel-level的regression预测:predicting RGB values of raw pixels by direct regression performs no worse than the patch classification approaches with complex designs
- 轻量的预测头:the prediction head can be as light as a linear layer, with no worse performance than heavier ones
- proved on ImageNet
- 普通模型ViT-B:pretraing+finetuning,ImageNet-1k,83.8% top-1
- 大模型SwinV2-H:87.1% top-1
- 超大模型SwinV2-G:MIM能够leverage the data-hungry issue,使用更少量的数据训练超大模型至SOTA
- propose a simple framework of MIM
论点
自监督里面的numerous pretext tasks
- gray-scale image colorization:图像上色
- jigsaw puzzle solving:打乱的patches重新排序
- split-brain auto-encoding:图像分成两部分,两条分支,交叉预测对方
- rotation prediction:given变换前后的图像X&Y,预测变换参数
- learning to cluster:「特征聚类,将簇心标签赋给其成员,训练一个task,特征聚类」,迭代这个过程
Masked signal modeling
- 图像和NLP的主要区别
- images exhibit stronger locality:neighbor pixels就是high related的,language的词序则不存在必然的距离相关性
- visual signals are raw and low-level:因此预测pixel-level的重建任务是否对high-level recognition task有增益?
- the visual signal is continuous, and the text token is discrete
- bridge the modality gaps through several special designs
- converting continuous signals into color clusters
- patch tokenization using an additional network
- block-wise masking strategy to break short-range connections
- 图像和NLP的主要区别
this paper
propose a simple framework,无需上述复杂设计
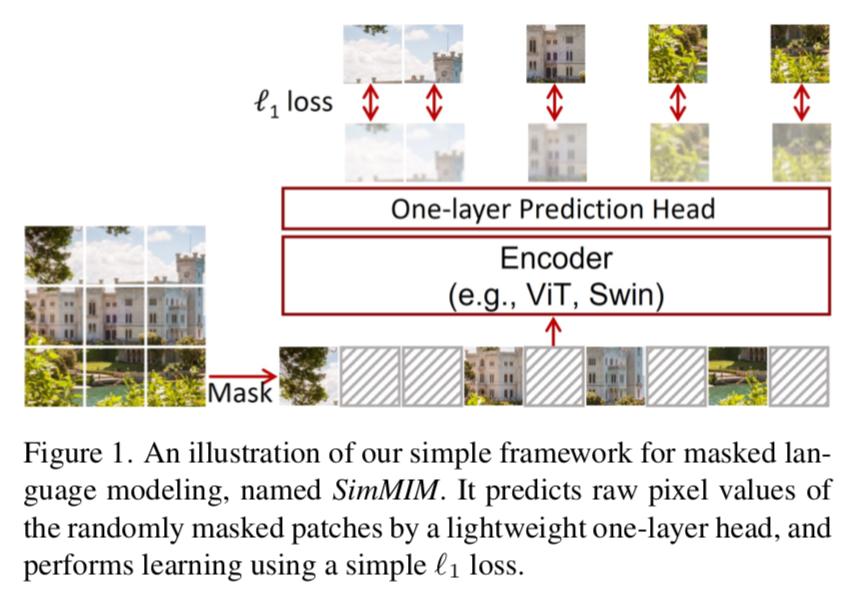
Random masking:
- patch-level的随机masking,适配vision transformer
- 大一点的patch size(32) works for a wide range of masking ratio
- 小的patch size(8) 需要masking ratio as high as 80% to perform well
- NLP里面的masking ratio通常比较小,如0.15,我们认为是因为info-level不一致
- 1-layer prediction head
- extremely lightweight
- 同时target resolution也不建议太大(12-96都可以好于192x192)
- achieves sligtly better transferring performance than heavy heads
- 这个自监督的头预训练完了要丢弃的,所以越小越好,不要过多承担模型能力
- pixel-level reconstruction use simple L1 loss
- regression比较适配continuous signal
- performs no worse than classification approaches
- 【QUESTION】分类任务一般怎么设计:后面实验里面,把RGB灰度值分解成8/256个bin,然后分类
方法
A Masked Image Modeling Framework:4 major components
- masking strategy
- encoder architecture:ViT & Swin
- prediction head
- prediction target:either the raw pixels or a transformation
Masking Strategy
- mask token
- use a learnable mask token vector to replace each masked patch
- token dimension 和 visible那部分patch embedding一致
- Patch-aligned random masking
- 就是以patch为单位随机masking
- swin的patch size是随阶段增长的,从4到32,we adopt 32
- for ViT we adopt 32
Other masking strategies:用了16/32
- square:随机放置的大方框
- block-wise:复杂设计的

- mask token
Prediction Head
- as light as a linear layer
- 实验也尝试过2-layer MLP、an inverse Swin-T、an inverse Swin-B 这种逐渐heavy的
- 上采样 if required:
- ViT编码得到x16的feature maps
- Swin编码得到x32的feature maps
- 用一个1x1 conv / linear,将feature dim扩展到patch size patch size 3,如swin-RGB就是32*32*3=3072
Prediction Targets
regression
- 也可以考虑将grouth-truth降采样到feature size
- L1 loss:计算masked区域RGB像素的L1 loss,然后mean on pixels
- 实验也尝试了L2 / smoothL1
Other prediction targets
- previous approaches大多数将masked signals转化成clusters or classes,然后perform a classification task
- Color clustering(iGPT):将巨型dataset的RGB values聚类成512个cluster,每个预测pixel is assigned to最邻近的cluster
- Vision tokenization(BEiT):用一个pretrained discrete VAE network将image patches转化成token,并作为classification target
- Channel-wise bin color discretization:每个颜色通道独立分类,灰度值离散化为8/256 bins
Evaluation protocols
- 首先将模型在imagenet1k上finetuning,然后看分类精度
- 或者其他down-stream tasks的指标来评估
实验
pre-training settings
- swinB:input 192x192,window size=6
- dataset:ImageNet-1K,a light data augmentation (random resize cropping/random flipping /color normalization)
- AdamW:weight decay=0.05,beta=[0.9,0.999]
- cosine LR scheduler:100 epochs (warmup 10 ep),baseLR=8e-4
- batch size:2048
- random masking:mask ratio=0.6,mask patch size=32
fine-tuning settings
- AdamW、batch size、masking 参数一致
- cosine LR:baseLR=5e-3
- a stochastic depth rate:0.1
- a layer-wise learning rate decay:0.9
- strong data augmentation:RandAug,Mixup,Cutmix,label smoothing,random erasing
AvgDist
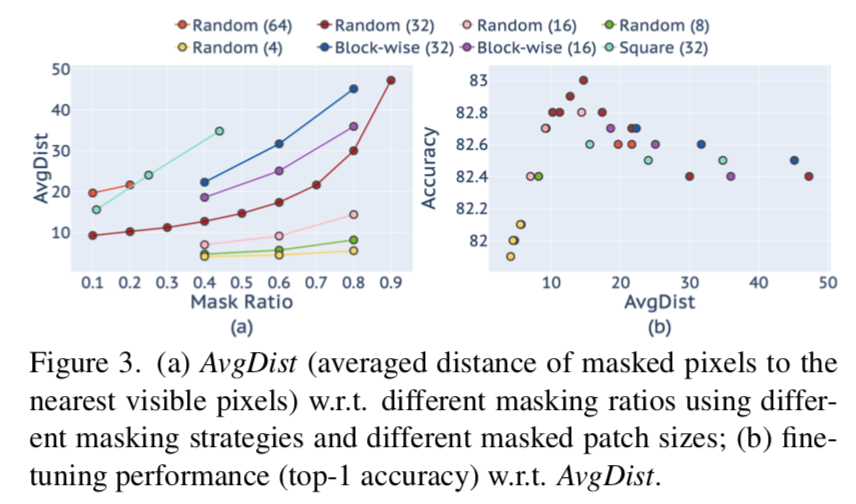
- measures the averaged Euclidean distance of masked pixels to the nearest visible ones:被遮挡的patch embedding与其最近的visible patch的embedding欧几里得距离
- mask ratio越大,AvgDist越大
- mask patch size越大,AvgDist越大
- AvgDist的值在[10,20]区间时,模型的精度最高
一些精度记录
- SwinV2-H achieves 87.1% top-1 accuracy,在只使用ImageNet-1K数据集里面精度最佳
- SwinV2-G借助了外部数据,但比google用的少,40× smaller,achieves strong performance
- 84.0% top-1 on ImageNet-V2
- 63.1/54.4 box/mask mAP on COCO object detection
- 59.9 mIoU on ADE20K semantic segmentation
- 86.8% top-1 acc on Kinetics-400 action recognition
Visualization
- 【20220614】目前初步实验下来,预训练的生成模型,生成的图片会呈现明显的棋盘格,因为每个x32的feature pixel代表了一个32x32的RGB patch,官方论文里面的图也很棋盘格,不知道该训练到啥程度算结束
What capability is learned?
- random masking:the shape and texture of masked parts can be well recovered,以及unmasked区域会观察到显著棋盘格效应,因为这部分区域在训练过程中是不回传梯度的
- masking most parts of a major object:can still predict an existence of object by the negligible clues
- masking the full major object:the masked area will be inpainted with background textures
Prediction v.s. reconstruction
- 比较了masked region recover和全图recover两个任务
- 从重建结果上看,后者视觉效果更好一点(棋盘格没那么明显,因为是全局预测),但是精度则低了一个点:probably the model capacity is wasted at the recovery of the unmasked area which may not be that useful for fine-tuning
auto-encoders and masked image modeling两个方法都是重建任务,but they are built on different philosophies:
- 前者是visible signal reconstruction
- 后者是prediction of invisible signals
MIM也可以设计成全图重建,但这相当于融合了两个任务
- prediction & reconstruction
- 从finetuning精度上看two tasks are fundamentally different in their internal mechanisms,两个任务的内部机制不同,合起来做不会促进
- the task to predict might be a more promising representation:看起来prediction任务学到的representation对下游任务更有用一些
【个人理解重建任务更local一点,所以细节更好看,prediction任务更long-range一些,但是为什么有说对low-level/fine-grained downstream task更好呢?】
Revealing the Dark Secrets of Masked Image Modeling
动机
- Masked image modeling (MIM) as pre-training
- proved effective
- but how it works remains unclear
- we compare MIM with mainstream supervised models
- through visualizations & experiments
- to cover the key representational differents
- visualizations
- 发现MIM brings locality inductive bias to all layers:信息流更不丢东西?
- 相比之下supervised models在lower layers更关注局部信息,在higher layers则更关注全局信息
- supervised models在last layers的attention head基本没啥差别(都是global semantic info),但是MIM在last layers仍旧能够keep diversity on attention heads
- less diversity harms the fine-tuning performance
- experiments
- 发现MIM相比较于supervised models更胜任tasks with weak semantics / fine-grained tasks
- 【猜测】image-level label 驱动 pixel-level study的效果更好?
- Masked image modeling (MIM) as pre-training
论点
masked signal modeling
- mask a portion of input signals and tries to predict them
- 属于比较经典的recover-based自监督任务设计
- language, vision, and speech场景都有在用
masked image modeling (MIM)
- achieve very high fine-tuning accuracy
- thus this paper wants a deeper understanding
we use SimMIM framework:就是基于ViT/swin-back+light-weight head重建pixel-level图像的任务
- random masking with large patch size
- a-linear-layer prediction head
- predict raw RGB pixels use L1 loss
Visualizations
attention weights have a clear meaning:每个token比重多大
从三个方面来分析
- averaged attention distance to measure whether it is local attention or global attention
- entropy of attention distribution to measure whether it is focused attention or broad attention:这跟上面不一个意思吗
- KL divergence of different attention heads to investigate that attention heads are attending different tokens or similar ones
Local Attention or Global Attention
图像信息带有strong locality:neighbor pixels天然地highly correlated,所以才会有conv这样的带有local priors的设计,但是transformer结构有没有这种inductive bias就值得讨论了
computing averaged attention distance in each attention head of each layer
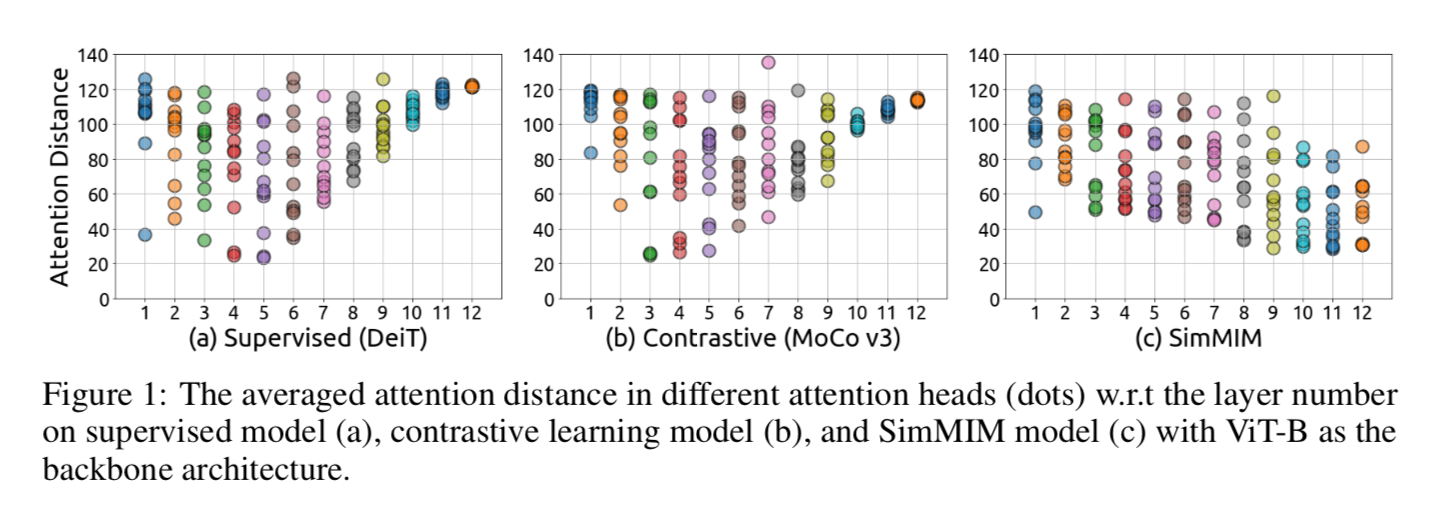
- constastive模型与supervised模型表现类似,lower layer focus locally,higher layers focus more globally
- MIM模型每层的attention heads则表现的充满diversity,始终保有local & global pixels
- 说明MIM brings locality inductive bias【不太理解】
Focused Attention or Broad Attention
averaging the entropy of each head’s attention distribution
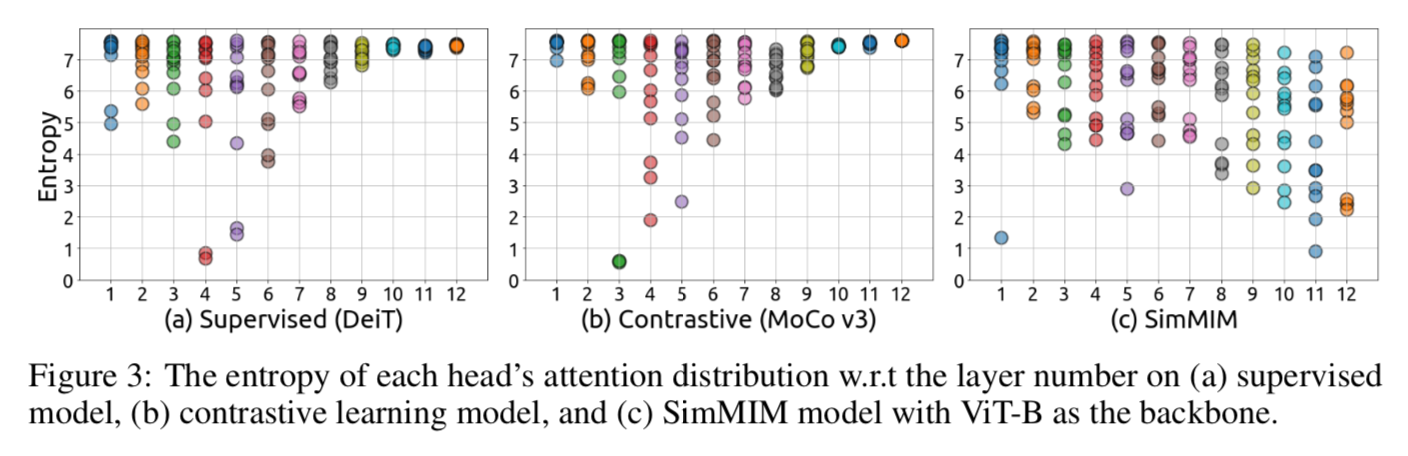
- constastive模型与supervised模型表现类似,lower layer的一些attention heads有非常focused attention,大部分higher layers的attention heads则focus very broadly
- MIM模型每层都很diverse,每层都兼顾了focused attention & broad attention
Diversity on Attention Heads
看每个attention head关注的token是否相似
computing the KL divergence between different heads
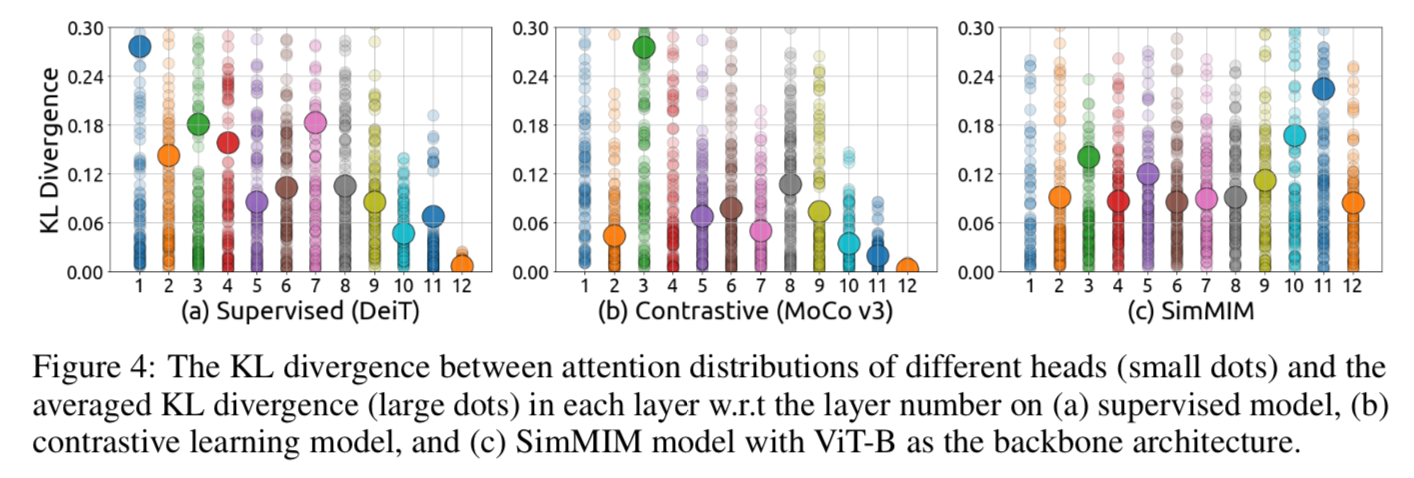
- constastive模型与supervised模型表现类似,diversity逐渐变小,最后几层甚至都没了
- losing diversity limits the capacity of the model:损害了模型表达能力
- 去掉supervised模型的后面几层去进行下游任务精度会保持甚至提升,说明supervised pretrained model后面几层确实对下游任务有负面影响
Investigating the Representation Structures via CKA similarity
前面都是在看同层不同attention heads,这里观察不同层的feature maps
via the CKA similarity between feature representations of different layers
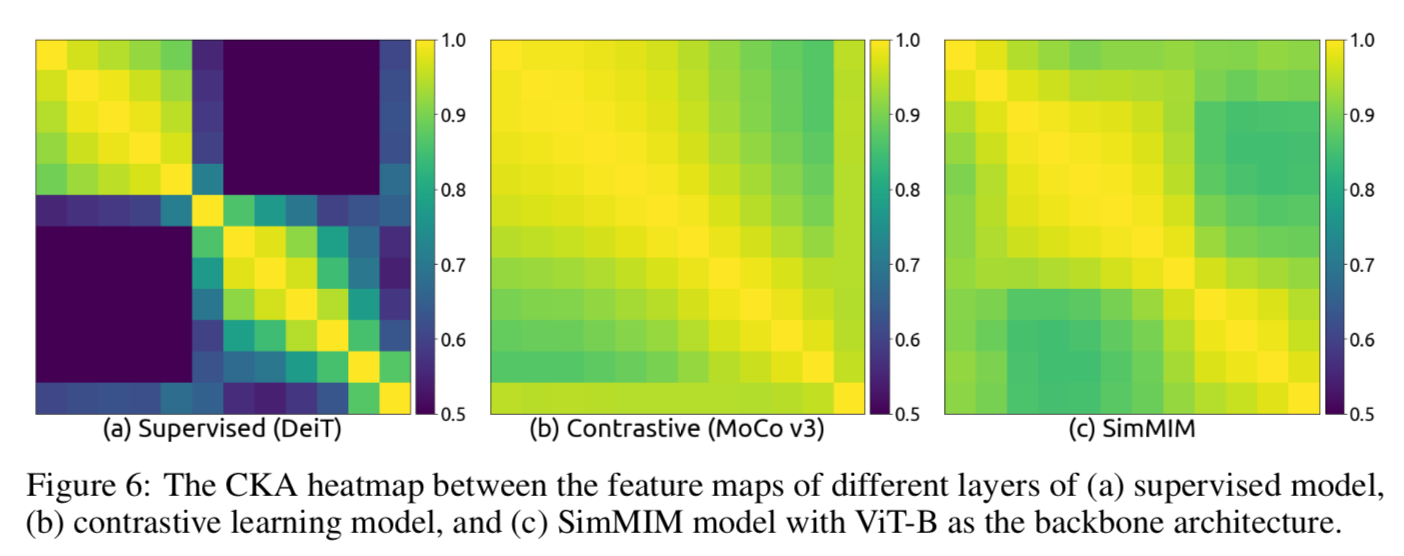
- MIM和constastive模型表现类似,每层的feature representation structures高度相似
- supervised模型则每层差异比较大
- 给这些预训练模型加载权重的时候随机调换一些层进行下游任务,MIM只有轻微掉点,但是supervised会受影响更大
Experiments
on 3 types of downstream tasks
- semantic understanding tasks:classification,Concept Generalization (CoG) & 12-dataset (K12) & iNaturalist-18 (iNat18)
- geometric and motion tasks:pose/depth estimation/video tracking,COCO & CrowdPose & NYUv2
- combined tasks:object detection,COCO
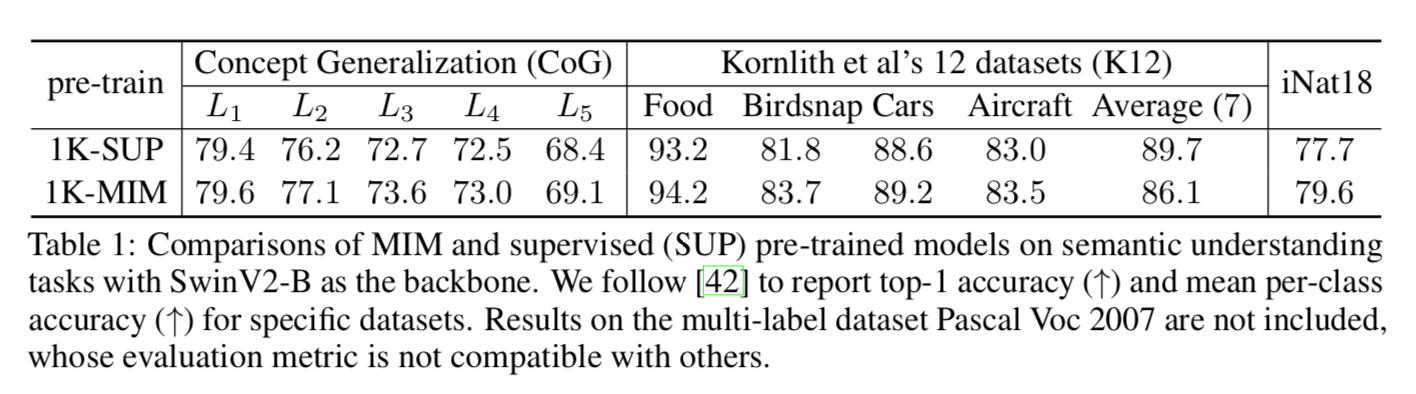
Semantic Understanding Tasks
- 用了三个数据集,从ImageNet pretrained去transfer
- settings
- AdamW
- cosine learning rate schedule
- 100 epochs with 20 warm-up
- input 224x224
- DropPath
- 发现ImageNet cover的类别supervised模型会好于MIM模型,没cover的类/fine-grained的类都是MIM精度更高,说明MIM的 representation power的transfer能力更强
Geometric and Motion Tasks
- 主要测试目标定位能力,不太关注高级语义信息
- 全面超越
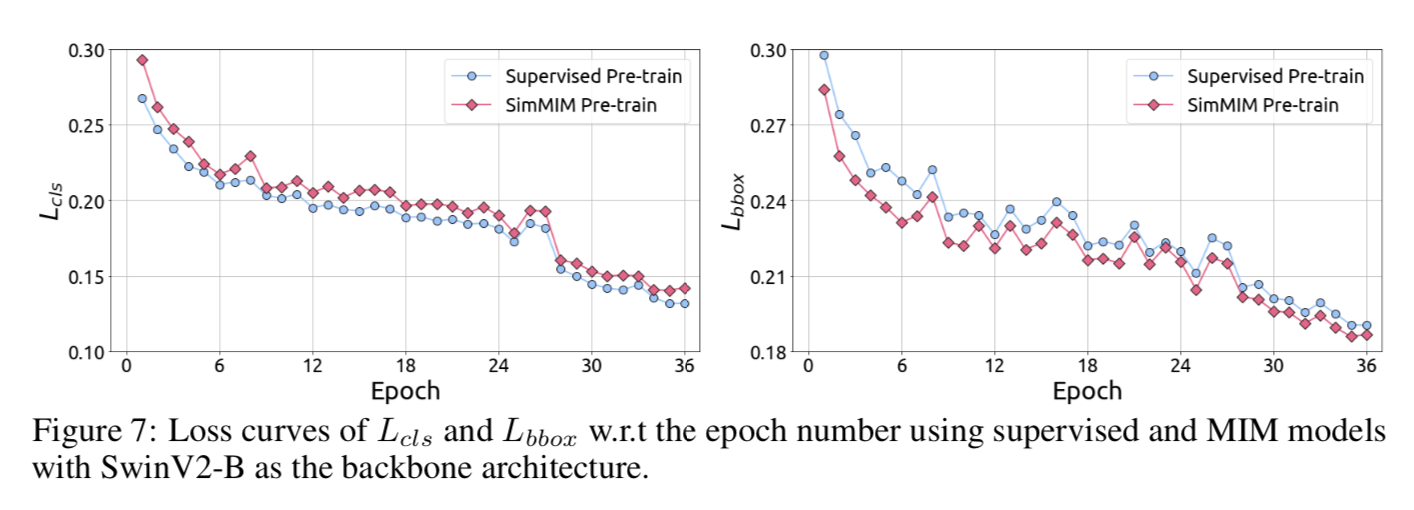
Combined Task of Object Detection
- COCO目标检测
- Mask-RCNN framework
- 也是clearly outperform
- 然后观察到MIM模型的定位task收敛的faster and better,supervised模型则对分类能力更有用,也说明了MIM更专注geometric and motion tasks