recollect:
[ViT 2020] AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE,Google,开启了vision transformer的固定范式,都是切割patches作为tokens,这也对应了文本的词/字符切割,但是一个patch和一个词向量的信息量是不一样的(像素信息更低级)
[TokenLearner 2022] TokenLearner: What Can 8 Learned Tokens Do for Images and Videos? Google,使用更少数量的、能够挖掘重要信息的learnable tokens,
repo:https://github.com/google-research/scenic/tree/main/scenic/projects/token_learner
unofficial keras repo:https://github.com/ariG23498/TokenLearner
TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?
动机
- tokens
- previous:densely sampled patches
- ours:a handful of adpatively learned tokens
- learn to mine important tokens in visual data
- find a few import visual tokens
- enable long range pair-wise attention
- applicable to both image & video tasks
- strong performance
- computationally more efficient
- comparable results are verified on classifications tasks
- 与state-of-the-arts on ImageNet对比
- video datasets, including Kinetics-400, Kinetics-600, Charades, and AViD
- tokens
论点
- the main challenge of ViTs
- require too many tokens:按照16x16的切割方式,512x512的图像也对应着1024个tokens
- transformer block的computation和memory是基于token length平方型增长的
- 因此限制了larger image/longer video
- thus we propose TokenLearner
- a learnable module
- take image as input
- generates a small set of tokens
- idea很直接:找到图像的重点区域regions-of-importance,然后用重点区域生成token
- 实验发现保留8-16个(之前transformer block通常保留200-500通道数)就能够保持甚至提升精度,同时降低flops
- the main challenge of ViTs
方法
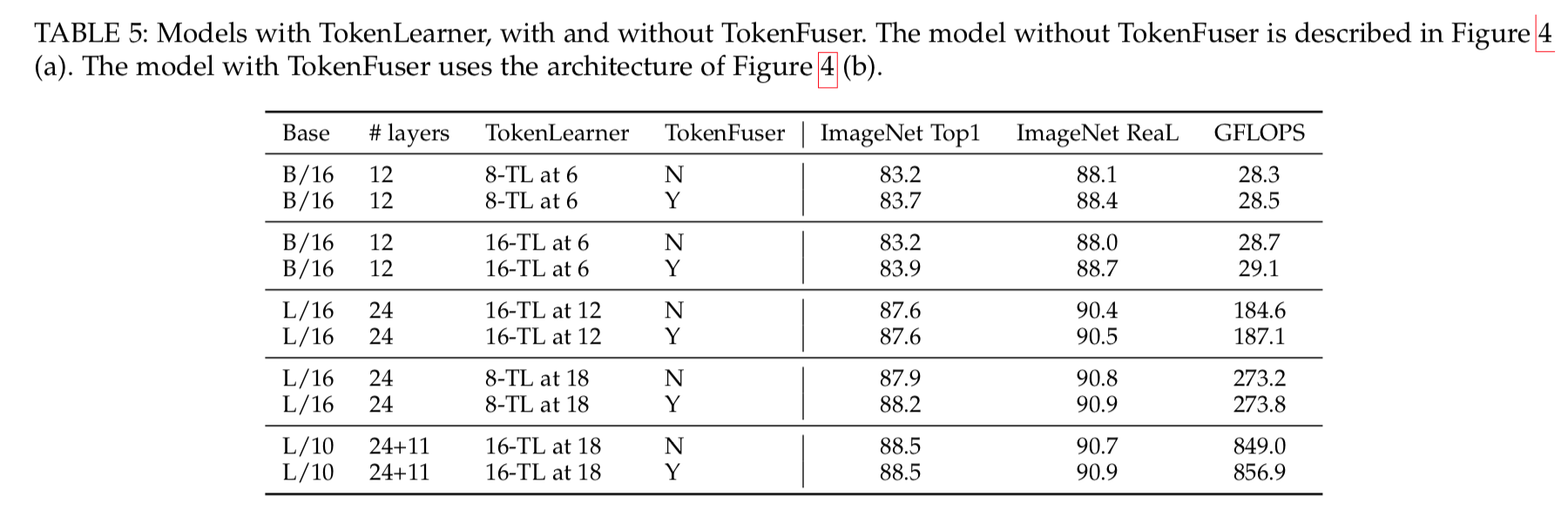
TokenLearner
formulation
- a space-time tensor input $X$:$X \in R^{T \times H \times W \times C}$
- a temporal slice $X_t$:$X_t \in R^{H \times W \times C}$
- T是时间维度,如果是image的话T=1,HWC是常规的长/宽/通道数
- for every time frame t,we learn to generate a series of tokens $Z_t$ from the input frame $X_t$:$Z_t=[z_i]_{i=1}^S$
- thus we use a tokenizer function $A_i$:$z_i=A_i(X_t)$,adaptively selects important combination of pixels
- 这样的function我们有S个,而且S远远小于HW,通常S=8
tokenizer function
- implemented with a spatial attention mechanism
- 首先生成一个spatial weight map (size HW1)
- 然后乘在$X_t$上,得到an intermediate weighted tensor (size HWC)
- 最后进行spatial维度的global averge pooling,将weighted maps转化成vector (size C)
- 所有的resulting tokens are gathered to form the output $Z_t =[z_i]_{i=1}^S\in R^{S \times C}$
- spatial attention的实现有两种
- 本文v1.0使用了一层/多层卷积(channel=S)+sigmoid
- 本文v1.1使用了一个MLP(dense-gelu-dense)
- (这两个版本的参数量差距巨大啊)
图:将$R^{HWC}$的input image稀疏映射到$R^{SC}$
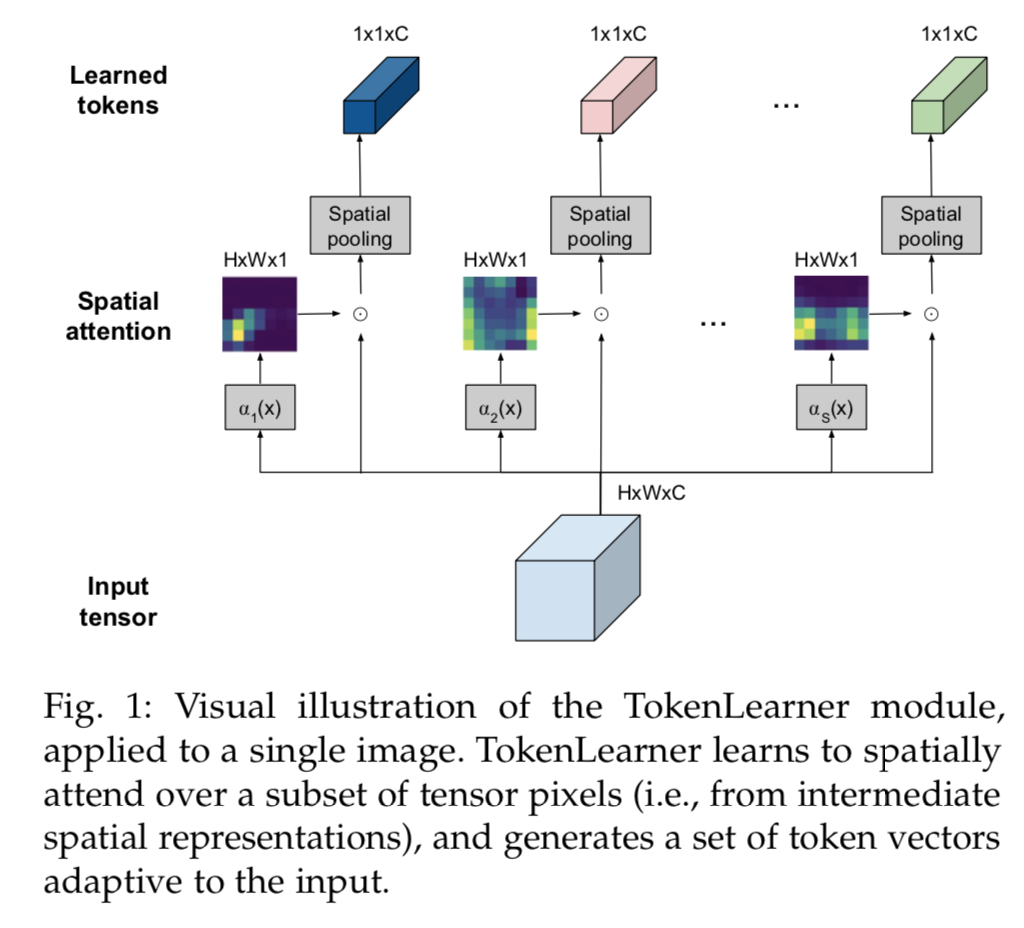
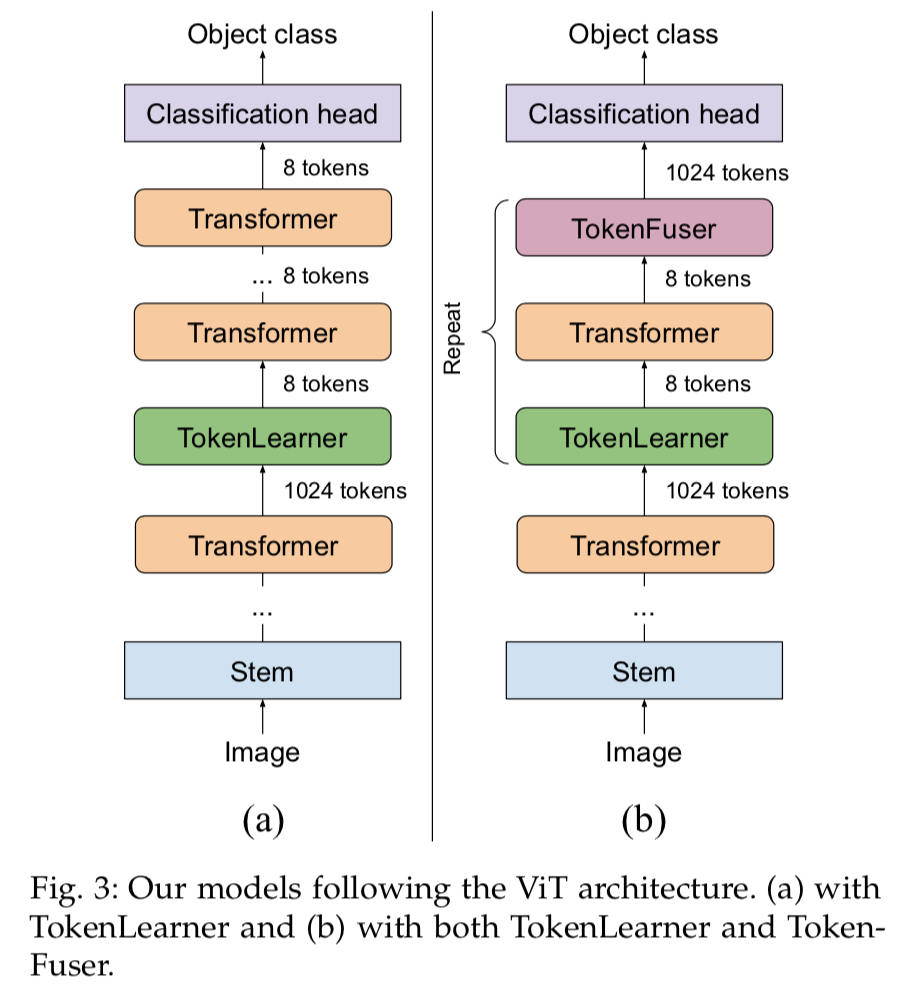
TokenFuser
after the Transformer layers,此时的tensor flow还是$R^{SC}$
引入TokenFuser
- fuse information across tokens,融合所有token
- remap the representation back to origin resolution,重映射
首先做fuse:give tokens $Y\in R^{ST \times C}$,乘以一个learnable weight $M (ST \times ST)$,得到tensor $\in R^{ST \times C}$,可以理解为空间(或时空)关联
然后做remap,对每个temporal slice $Y_t \in R^{SC}$:
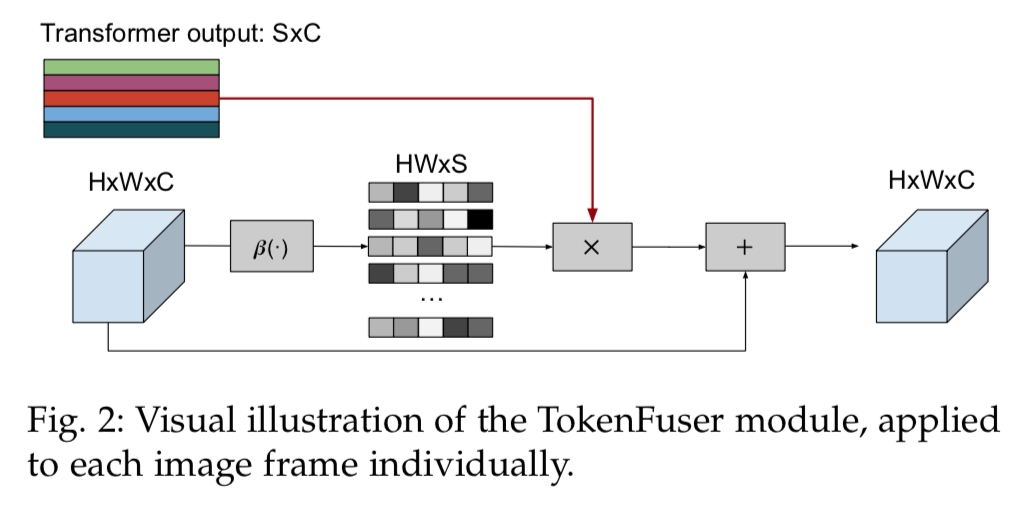
- $X_t^{j+1} = B(Y_t, X_t^j) = B_w Y_t + X_t^j = \beta_i(X_t^j)Y_t+X_t^j$
- $X_t^j$是TokenLinear的残差输入,也就是原图HWC,等待被reweight的分支
- $X_t^{j+1}$是模块输出
- $Y_t^j$是TokenFuser的fuse这步的结果,对应图上transformer output SC
- $\beta_i()$是个dense+sigmoid,作用在原图上,得到HWS的weight tensor $B_w$
- 然后乘上Y得到HWC
- 再加上这个残差
- $X_t^{j+1} = B(Y_t, X_t^j) = B_w Y_t + X_t^j = \beta_i(X_t^j)Y_t+X_t^j$
整体架构
整体计算流程
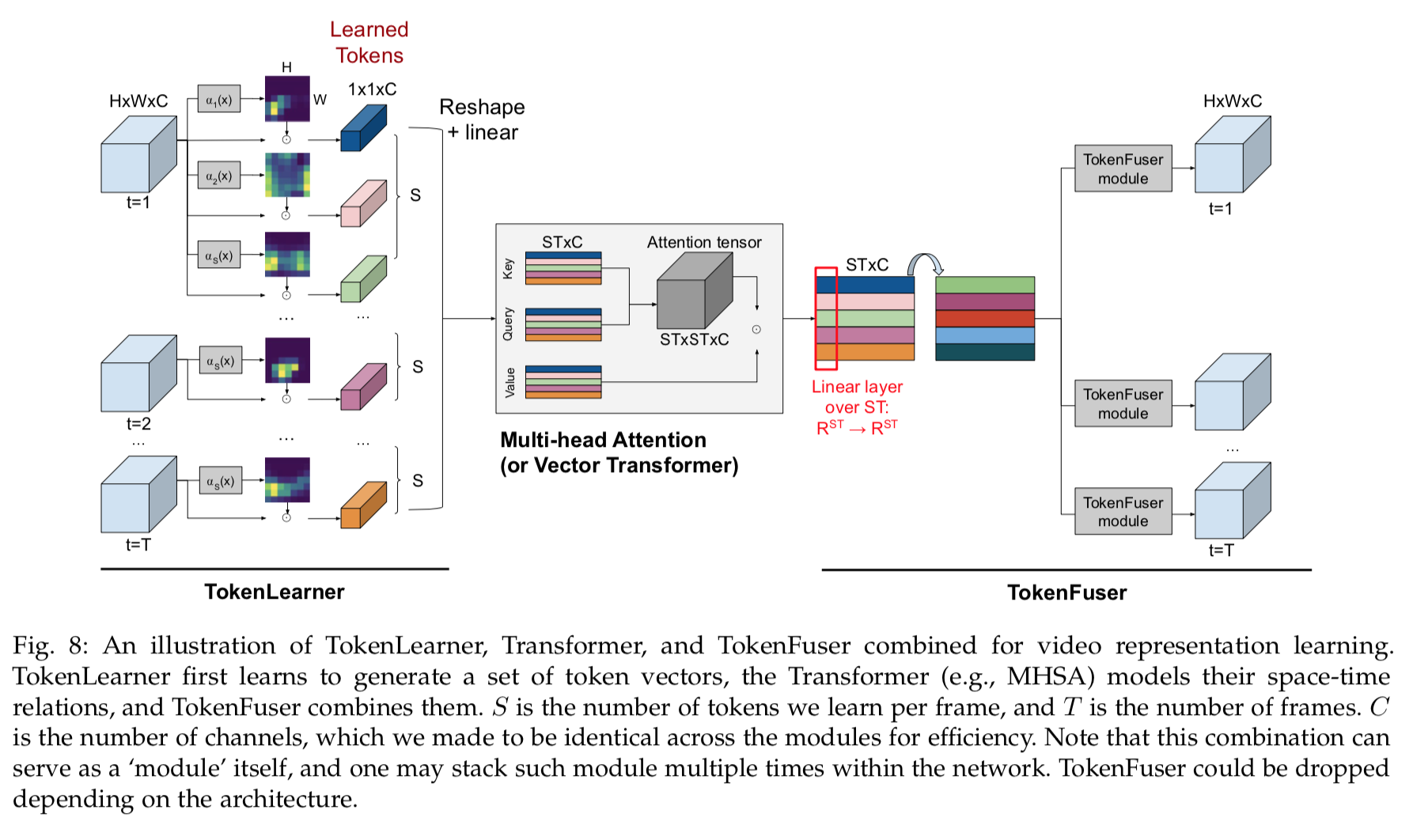
两种模型结构(有/没有TokenFuser)
实验
settings
- tobeadded
TokenFuser的ablation实验:整体有提升,模型越大提升越不明显