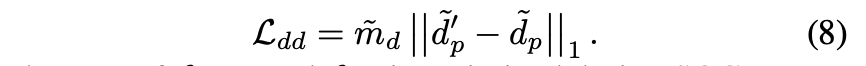papers:
[DIM-Matting 2017] Deep Image Matting,Matting网络始祖,trimap-based
[BGMv2 2021] Real-time high-resolution background matting,实现高分辨率图像的实时预测
[MODNet 2020] Is a Green Screen Really Necessary for Real-Time Portrait Matting,商汤,摒弃了辅助信息,直接实现Alpha预测
[PP-Matting 2022] High-Accuracy Natural Image Matting,百度,在MODNet基础上改进
[BiSeNet v2 2020] Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation,双encoder结构,一个用来显式地guide local feature,本身不是针对matting任务,但是其他matting paper引用了它
[GCA Matting 2020] Natural Image Matting via Guided Contextual Attention,introduce GCA block来做local guidance
[animal matting 2022] Bridging Composite and Real: Towards End-to-end Deep Image Matting,毛发抠图
Bridging Composite and Real: Towards End-to-end Deep Image Matting
introduction
毛发的分割通常需要trimap引导
思路还是常规的decompose,into two parallel sub-tasks:
- high-level semantic segmentation
- low-level details matting
propose GFM
Glance and Focus Matting network (GFM)
a shared encoder and two separate decoders
learn both tasks in a collaborative manner
分析了composed image和real-world image的差异
- a carefully designed composition route RSSN
- 提供了2000张high-resolution的动物图和10,000张portrait图
related work
methods
- 串行:先global segmentation生成trimap,然后做local matting,串行时间效率差,而且错误的语义不会被修正,两个网络通常分别训练,存在mismatch
- 并行:添加了一个global guidance做辅助分支,通常用coarse matte做学习目标,但是用一个网络去学全图fg/transition/bg区域的matte是一个比较困难的事,因为不同区域的表征、语义差异太大了
this paper 并行且多任务:并行执行segmentation和matting两个任务
- global rough segmentation
- details matting
datasets
- ORI-Track:之前的数据只提供前景和matte/low-resolution portraits和不太准确的matte
- COMP-Track:
- 之前是通过在公开数据集如COCO上叠加前景数据构造数据集的
- 这种合成图像存在composition artifacts
- 因为和前景存在resolution,sharpness,noise,illumination差异
- 可能存在salient object
this paper 提出了一个large-scale high-resolution clean background dataset (BG-20k)

method
overview
- a segmentation stage:先识别salient rough foreground / background
- a matting stage:focus on the transition areas to distinguish details from the background
collaboration
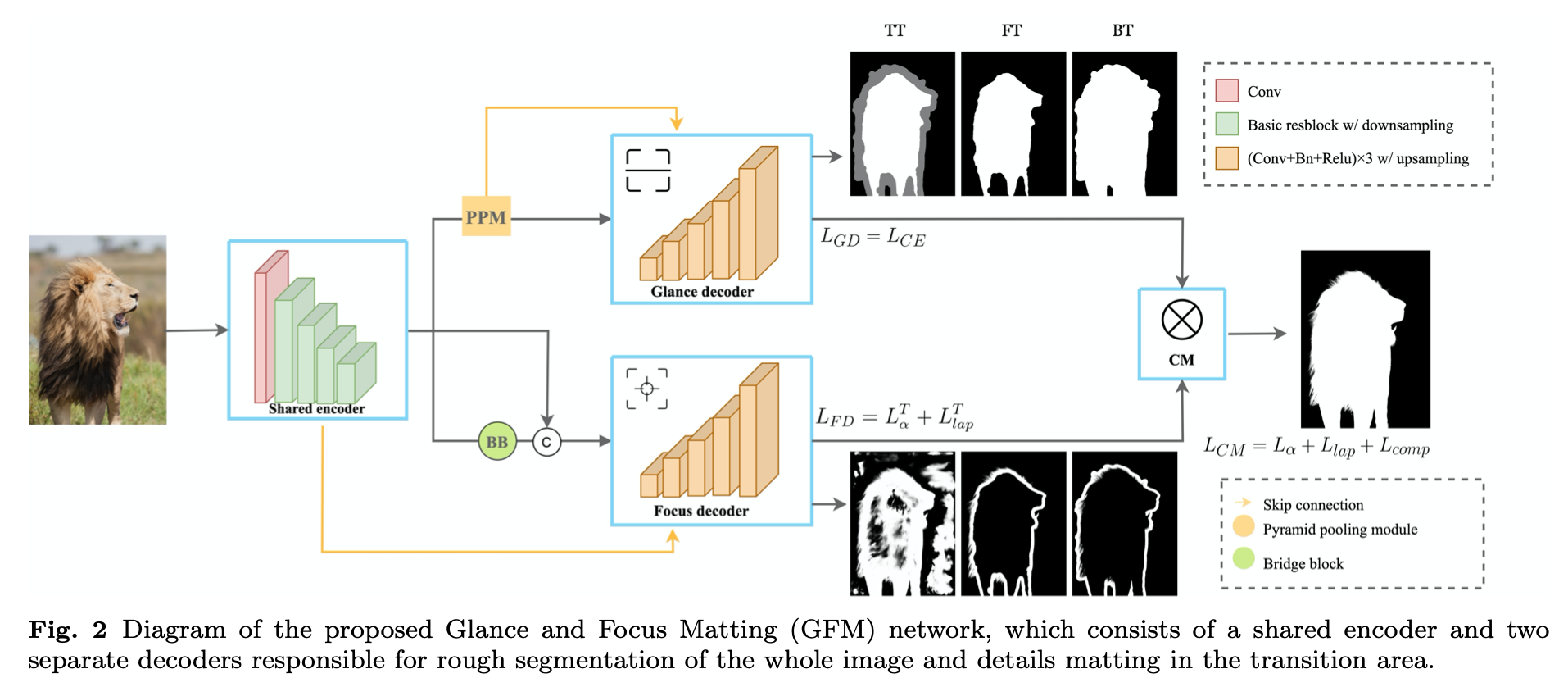
shared encoder
- 输入是single image
- 5 blocks:E0-E4,s2-s32
- DenseNet-121/ResNet-34/ResNet-101
Glance Decoder (GD)
- a large receptive field to learn high-level semantics
- PPM
- 镜像地stack 5 blocks:D4-D0
- each of which consists of three sequential 3 × 3 convolutional layers and an upsampling layer
- 每个stage的decoder block还接受一个ele-wise sum的PPM输入
- loss:2/3-channel的CE
Focus Decoder (FD)
aims at low-level structural features in transition areas
bridge block (BB)
- three dilated convolutional layers
- leverage local context in different receptive fields
- E4和BB的feature concat起来作为stage5 feature
镜像地stack 5 blocks:D4-D0
- UNet style
- 额外的来自encoder的shortcut,保留fine details
loss
alpha prediction loss:absolute difference
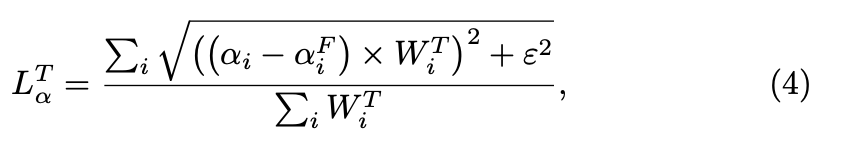
Laplacian loss:L1 loss
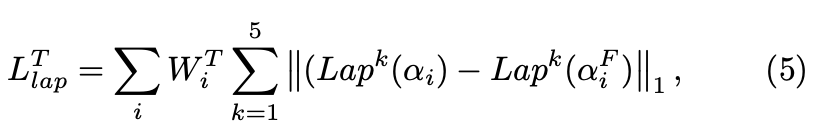
仅关注the unknown transition areas
Representation of Semantic and Transition Areas
- 模式1:GFM-TT
- 3-class trimap T:segmentation gt将ground truth alpha dilation and erosion with a kernel size of 25
- use the ground truth alpha matte来定义the transition area
- 模式2:GFM-FT
- 2-class foreground F:将ground truth alpha erode with a kernel size of 50做F
- 用(gt alpha>0) - F 作为transition area
- 模式3:GFM-BT
- 2-class foreground G:将ground truth alpha dilate with a kernel size of 50做G
- 用G-(gt alpha>0) 作为transition area
- 模式1:GFM-TT
Collaborative Matting (CM)
to generate the final alpha prediction
CM的不同模式
- GFM-TT模式下:CM把GD在transition area的预测换成FD的预测
- GFM-FT模式下:CM把GD和FD的结果相加
- GFM-BT模式下:CM用GD-FD的结果作为最终结果
loss
- alpha-prediction loss:absolute diff
- Laplacian loss:L1
composition loss:absolute diff
RSSN
BiSeNet V2: Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation
introduction
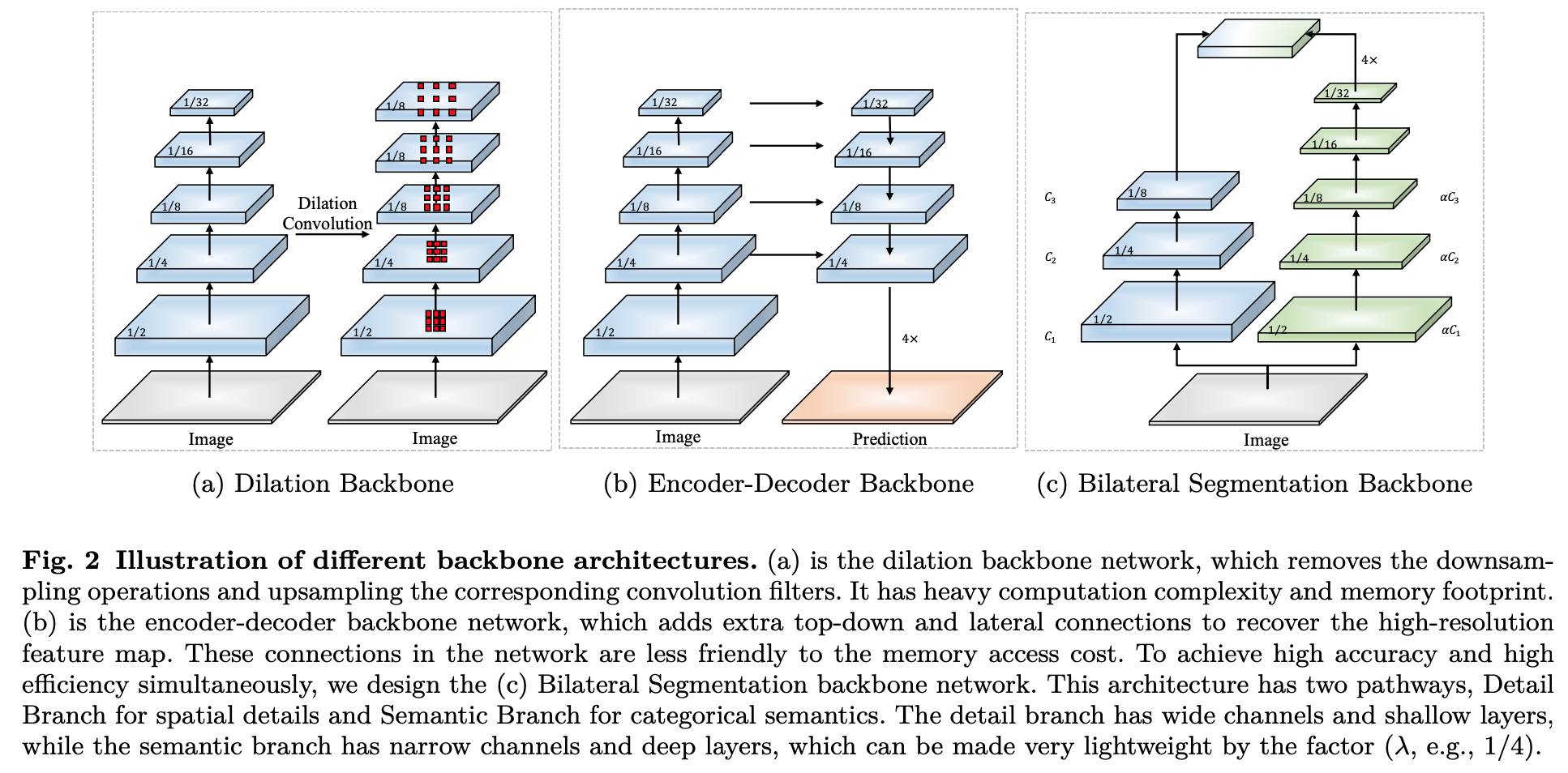
- propose Bilateral Segmentation Network (BiSeNet V2)
- treat spatial details and categorical semantics separately
- a Detail Branch:wide channels and shallow layers
- a Semantic Branch:narrow channels and deep layers
- design a Guided Aggregation Layer
- enhance mutual connections
- 得到fused feature
- treat spatial details and categorical semantics separately
performance
- on Cityscapes test:with 2048x1024 input,72.6% miou,156 FPS,on NVIDIA GeForce GTX 1080 Ti
different backbone
- dilation backbone如deeplab,用空洞卷积扩大reception field,同时保留high resolution,计算量大
- encoder-decoder backbone如unet,skip connection这部分会引入memory access cost,影响latency
本文的Bilateral Segmentation backbone,两个pathway,achieve high accuracy and high efficiency simultaneously
- propose Bilateral Segmentation Network (BiSeNet V2)
method
overview
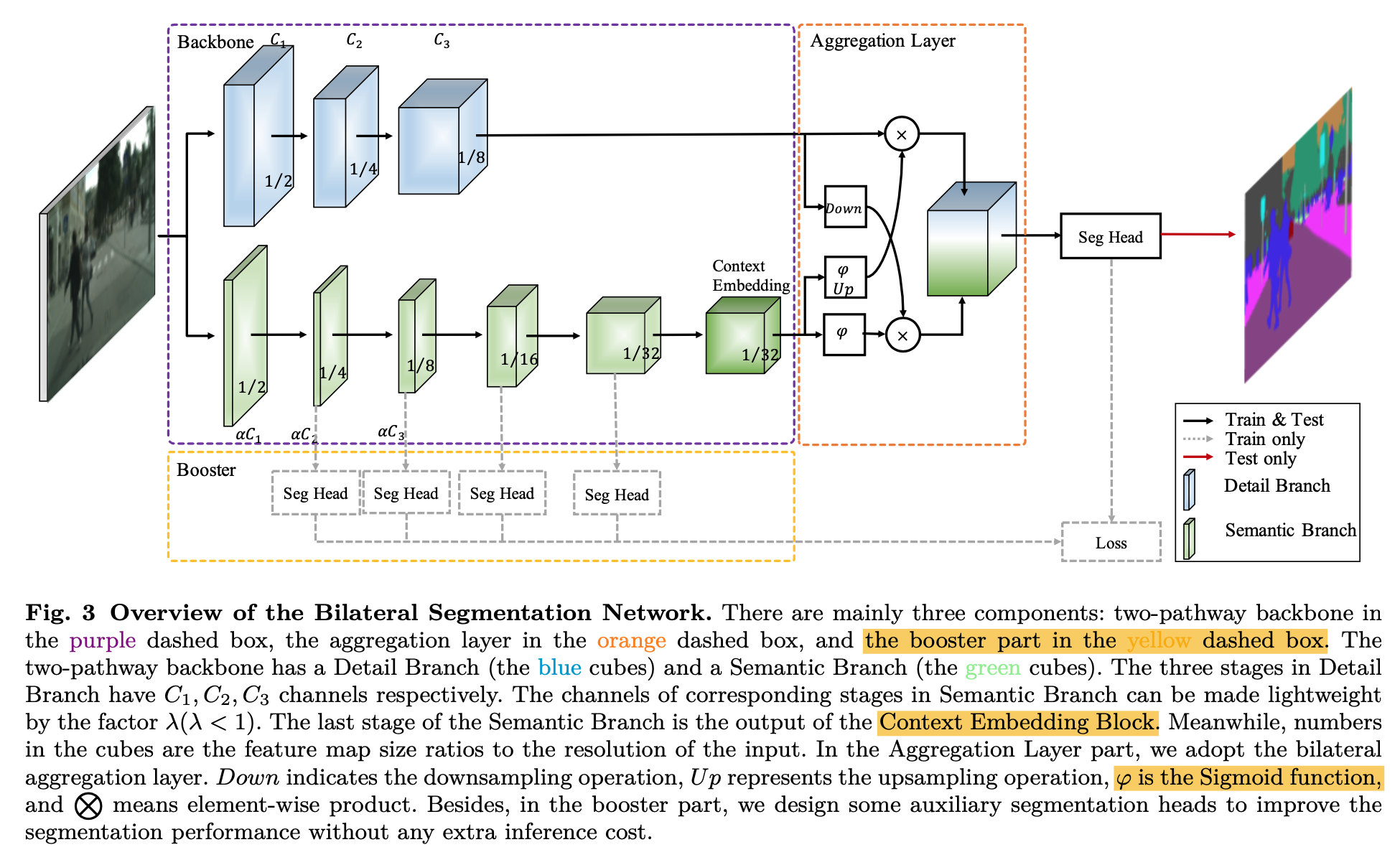
Detail Branch
- 负责学spatial details
- wide channels,shallow layers,small strides
- 没有residual path,避免memory access cost
- three stages,基本类似VGG
- 每个stage有两层conv-bn-relu
- 每个stage的第一个conv的stride是2
- 输出x8的feature map
Semantic Branch
负责学high-level semantics
channel数和Detail Branch的channel数有一个比例factor(<1)
可以用任何的lightweight convolutional model
large strides,large reception field
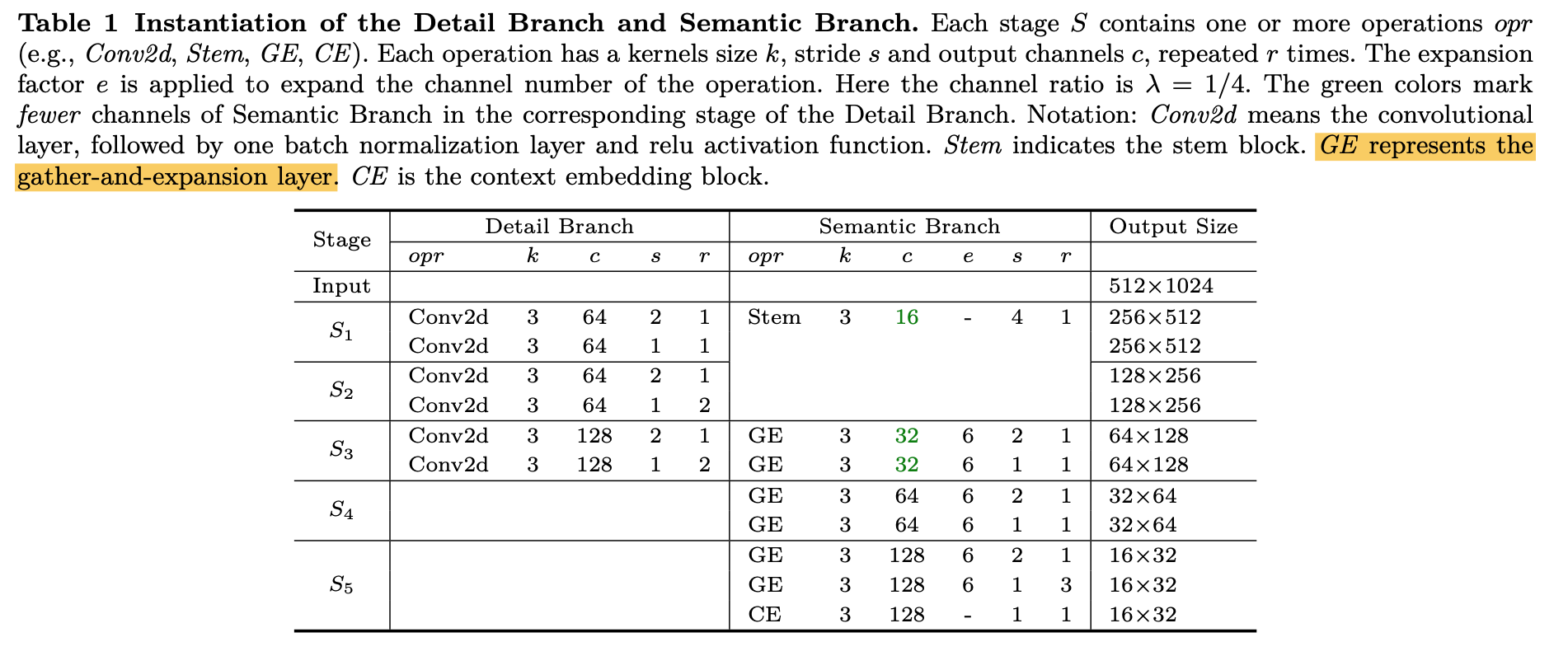
stem block
- 迅速下采样到x4尺度,用了两种下采样manner
然后concat + fuse conv
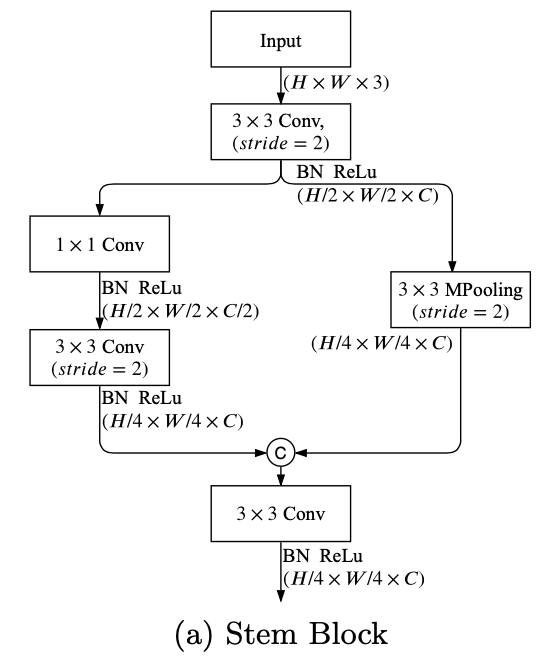
GE block
- 基本就是MobileNet V2的block
- 但是在resolution/channel变化时,identity path加入dwconv-conv来做align,而不是去掉id path
- 2个stride2的DWconv
- 1一个separable conv
同时在residual path中,expand layer的1x1conv换成了3x3conv,因为cudnn里面3x3conv更友好,expand操作放在了DWconv里面

最后的CE block用global average pooling to embed the global contextual response
GAP的1x1xC的context vector直接broadcast add到x32 feature上

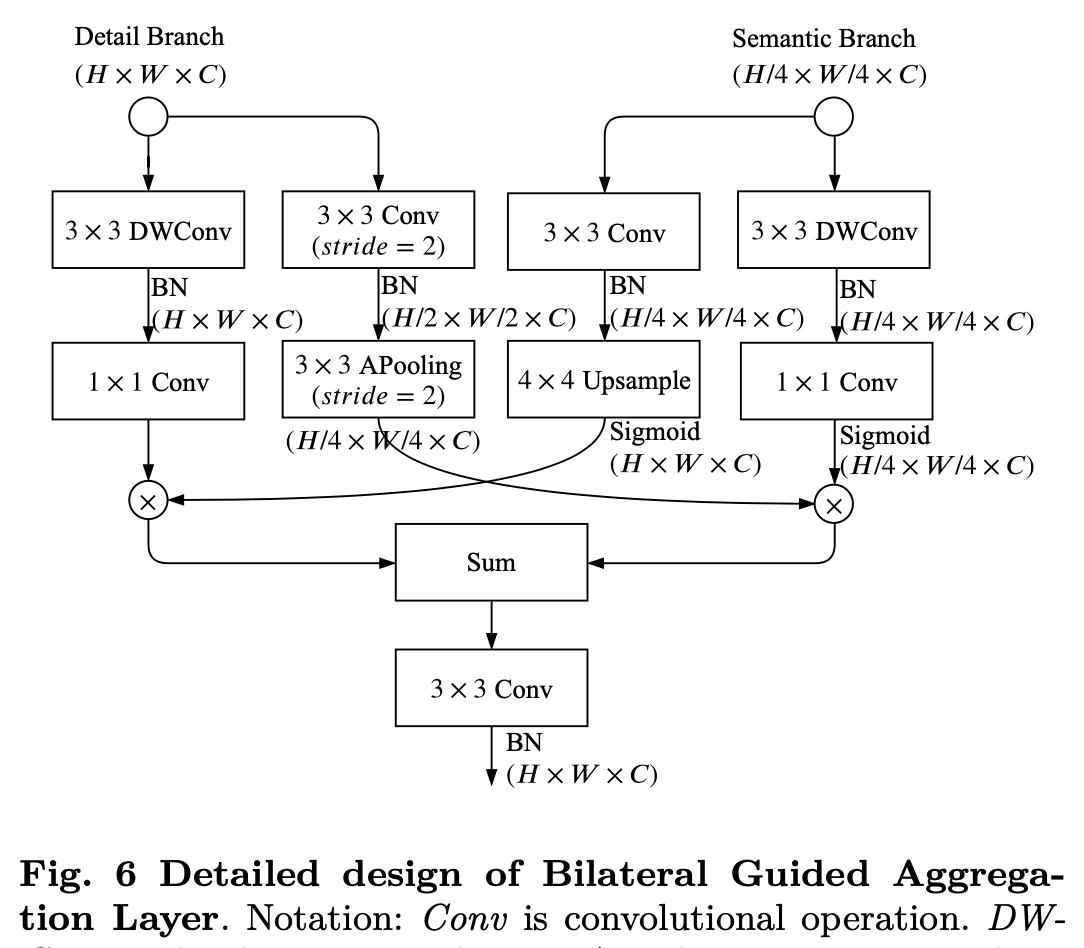
Bilateral Guided Aggregation
fuse manners
- simple sum/concat
- well designed operations,本文用了bidirectional aggregation method
BGA
用semantic branch的响应值来guide Detail Branch
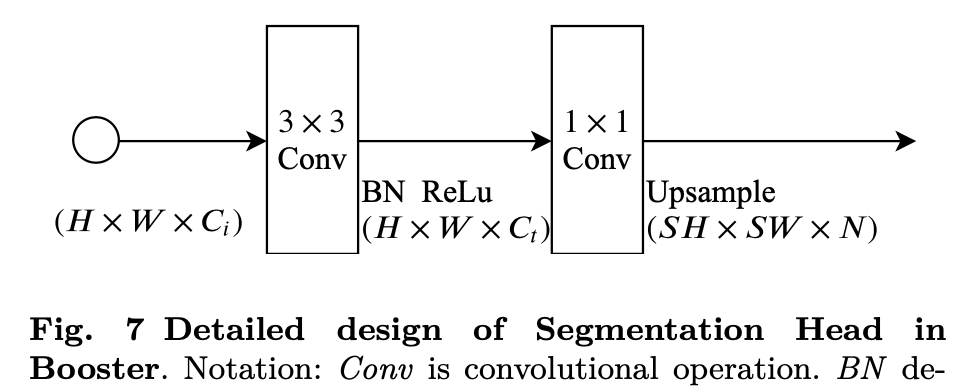
Booster Training Strategy
- 每个semantic stage的feature上加了auxiliary segmentation head
每个seg head都是3x3conv-bn-relu + 1x1 conv,然后上采样到原始尺度
PP-Matting: High-Accuracy Natural Image Matting
动机
- 抠图:aka. 抠前景,与segmentation的区别是在细节上更精准
- 现有技术的缺陷:
- trimap-based methods:需要提供trimap辅助信息
- trimap-free methods:与trimap-based方法在抠图质量上有较大差距
- 本文方法
- trimap-free architecture(a two-branch architecture)
- applies a high-resolution detail branch (HRDB):high-resolution保留local细节信息
- a semantic context branch (SCB):分割分支负责全局语义分割
- high-accuracy
- natural image matting
- trimap-free architecture(a two-branch architecture)
- test datasets
- Composition-1k
- Distinctions-646
论点
- task formulation
- an image $I \in R^{H\times W\times 3}$ 可以看作前景和背景的linear combination
- foreground image $F \in R^{H\times W\times 3}$
- background image $B \in R^{H\times W\times 3}$
- $I^i = \alpha^i F^i + (1-\alpha^i)B^i$
- $\alpha_i$:foreground opacity
- 可以看作是alpha mattes estimation problem
- 【没理解】The image matting problem is highly ill-posed with 7 values to be solved, but only 3 values are known for each pixel in a given RGB image.
- ill-posed problem:不适定问题,
- well-posed problem:适定问题,需满足三个条件,否则为不适定问题
- a solution exists 解必须存在
- the solution is unique 解必须唯一
- the solution’s behavior changes continuously with the initial conditions 解连续变化,不会发生跳变,即必须稳定
- GAN、图像超分辨率等任务,都不满足‘解唯一’(感觉生成系都不满足)—— In most cases, there are several possible output images corresponding to a given input image and the problem can be seen as a task of selecting the most proper one from all the possible outputs.
- an image $I \in R^{H\times W\times 3}$ 可以看作前景和背景的linear combination
- methods
- trimap-based
- trimap:a rough segmentation of the image into three parts: foreground, background and transition (regions with unknown opacity)
- 作为image的辅助信息,并行输入
- not feasible in video
- trimap-free
- multi-stage approaches:将trimap作为中间结果,串起两个任务,会有累积误差
- end-to-end approaches:一个网络直接出结果
- trimap-based
- our method
- high-resolution detail branch (HRDB):keep high resolution instead of encoder-decoder,fine-grained details
- semantic context branch (SCB) :segmentation subtask, foreground-background ambiguity
- fuse:give the final alpha matte
- task formulation
方法
overview of network architecture
- two branches:SCB & HRDB
- shared encoder
- PPM to strengthen semantic context
guidance flow to merge
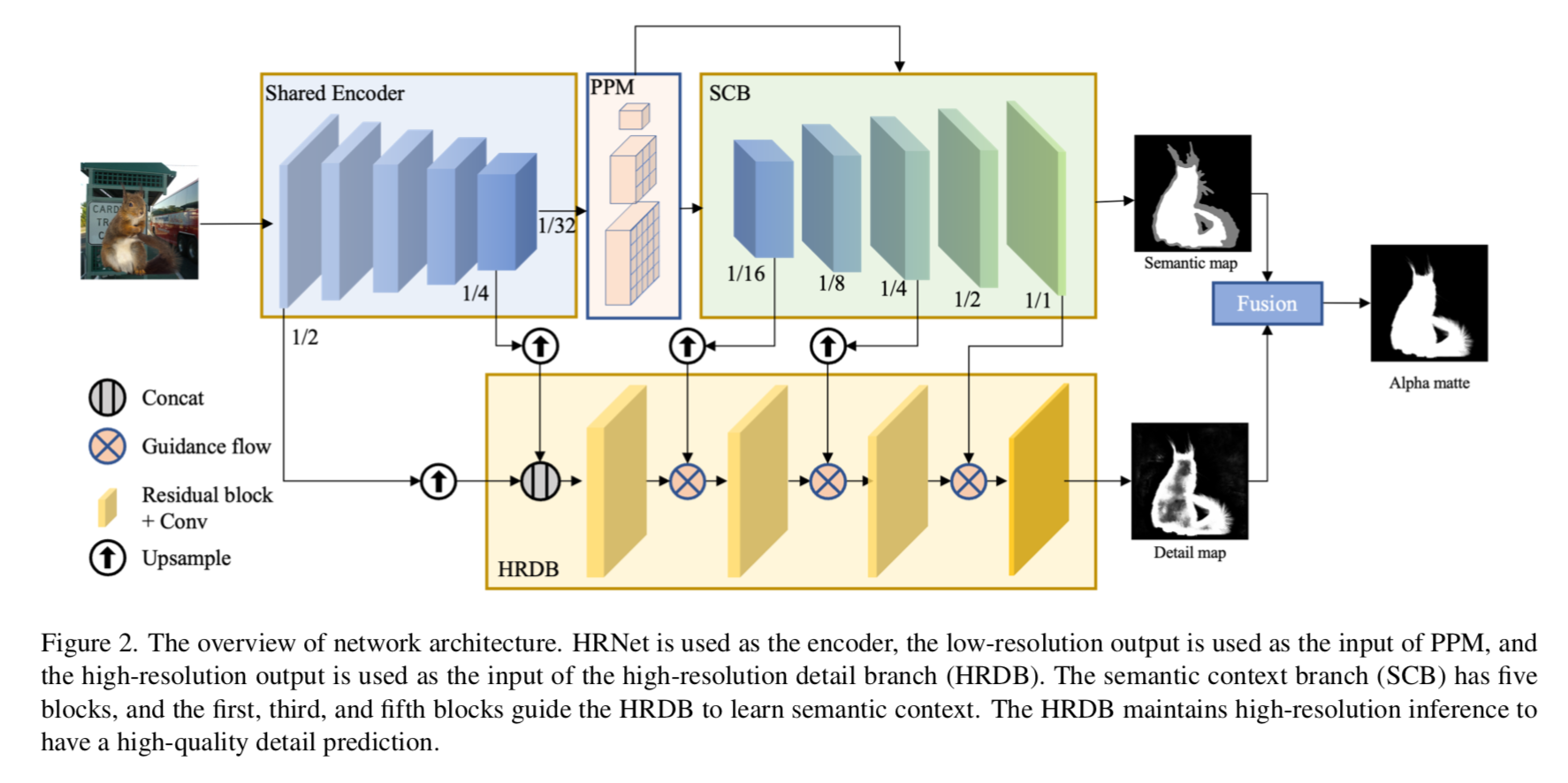
shared encoder
- need both high-resolution details and high-level abstract semantics
- HRNet48 pre-trained on ImageNet
Semantic Context Branch(SCB)
- 用来生成trimap(fg/bg/transition)
- 5 blocks
- each block:3xConvBNReLU+bilinear upsample
- 32x 下采样的特征图作为分割分支的输入,加一个PPM,
- 输出是semantic map,分割目标是3分类的segmentation mask,也就是trimap
High-Resolution Detail Branch(HRDB)
- 3 residual blocks + 1 conv
- 2x和4x 的特征图上采样到原始resolution,然后combine,作为分支输入
- SCB的中间结果作为guidance flow,也融合进HRD分支, to obtain semantic context
- 输出是detail map,focuses on details representation in the transition region
Guidance Flow
- Gate Convolutional Layers (GCL) 用来生成guidance map $g \in R^{H \times W}$
- $g = \sigma (C_{1 \times 1} (s||d))$
- semanic map和detail map先concat,然后conv-bn-relu & conv-sigmoid
- merge guidance flow和 original flow 得到最终的merged flow $\hat d$
- $\hat d = (d \odot g + d)^T w $
- detail map和guidance map先做element-wise的点乘,作为辅助信息
- 然后叠加detail map
- 最后进行channel-wise的re-weight
- 用semantic map的1、3、5 block的输出进行guidance
- Gate Convolutional Layers (GCL) 用来生成guidance map $g \in R^{H \times W}$
Loss Function
3个losses
[1] semantic loss $L_s$:pixel-level的3分类CE
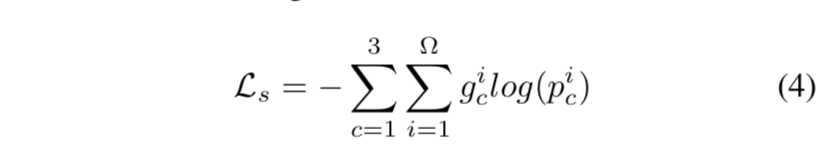
[2] detail loss $L_d$:是alpha loss $L_{\alpha}$和gradient loss $L_{grad}$的sum,而且只计算transition region
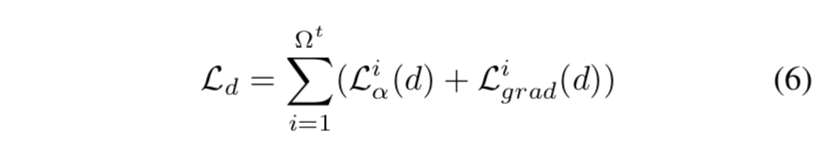
- the alpha-prediction loss:是 groud truth alpha(下标g)和 predict alpha(下标d)的absolute difference
- the gradient loss:是像素gradient magnitude的差值
$\epsilon=1e-6$
[3] fusion loss $L_f$:包含alpha loss $L_{\alpha}$、gradient loss $L_{grad}$、composition loss $L_{comp}$ based on the final alpha matte
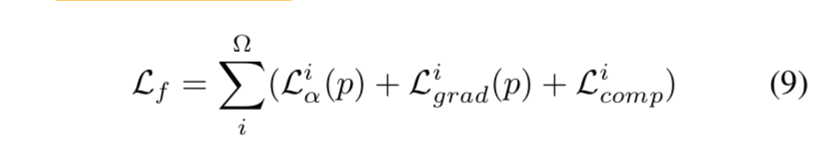
- the composition loss:是ground truth RGB value与predict RGB value的差值
- predict Image $I_p$是用predicted alpha matte对ground truth foreground & background的加权得到
alpha loss和gradient loss的算法与上面保持一致,但是alpha matte的值是不同的,一个是detail map的结果,一个是fusion map的结果
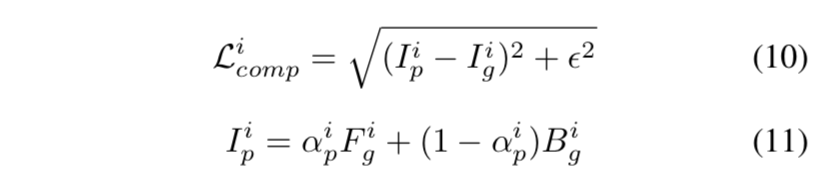
the final weighted loss:$\lambda_1=\lambda_2=\lambda_3=1.0$
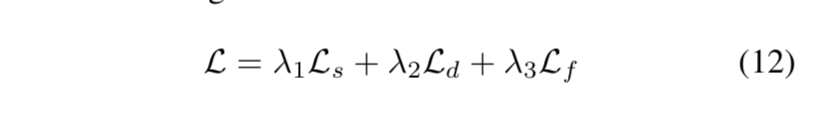
实验
- Datasets
- Distinctions-646:训练集包含596个前景目标及ground truth alpha mattes,测试集包含50个
- Adobe Composition-1k:431/50
- 在训练中每个前景会被添加进100张背景中,测试是20张
- Implementation Details
- input images:random crop into [512,640,800] /pad into [512,],augmented by random [distortion, blurring, horizontal flipping]
- SGD:momentum=0.9,weight decay=4e-5
- lr:初始0.01,300k iteration的时候pow by 0.9
- batchsize = 4
- conduct on a single Tesla V100 GPU
- Evaluation metrics:the lower,the better
- the sum of absolute differences (SAD)
- mean squared error (MSE)
- gradient (Grad)
- connectivity (Conn)
- Datasets
MODNet: Real-Time Trimap-Free Portrait Matting via Objective Decomposition
动机
- existing methods
- either require auxiliary inputs
- or involve multiple stages
- thus we propose MODNet (matting objective decomposition network)
- light-weight
- real-time
- end-to-end
- single-input
- portrait matting
- two novel techniques
- an Efficient Atrous Spatial Pyramid Pooling (e-ASPP) module:fuse multi-scale
- a self-supervised sub-objectives consistency (SOC) strategy:domain shift problem
- test device:under 512x512, 67 FPS, GTX 1080Ti GPU
- dataset:a carefully designed photographic portrait matting (PPM-100) benchmark & Adobe Matting Dataset
- existing methods
论点
Portrait Matting Approaches
- trimap-based:有一个pre-defined trimap作为先验
- multi-stage:先用一个semantic network生成一个pseudo trimap,然后refine成alpha matte,数据集有限,suffer from the domain shift problem,对real-world data的泛化性不好
- 本文方法能够同时自动化完成matting task的子任务:背景提取 & 前景语义,同时用子任务之间的consistency做自监督,提升模型泛化性
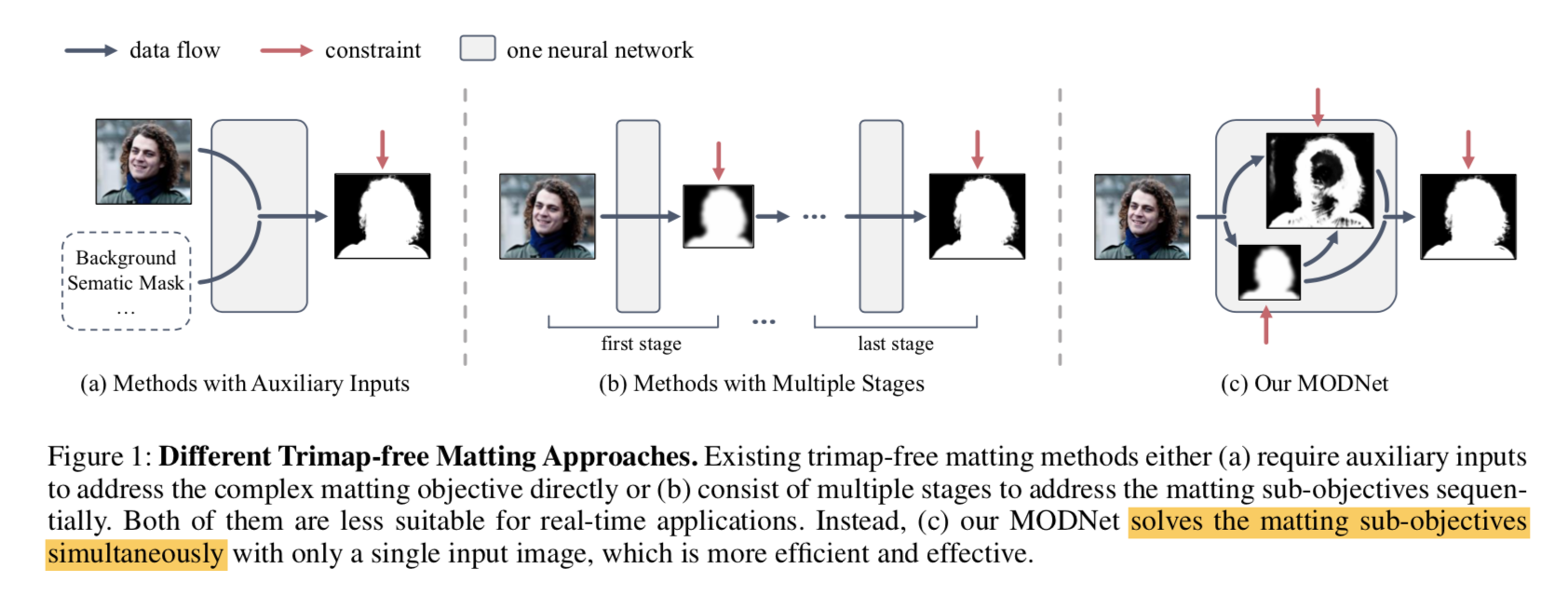
Image Matting Formulation
- an alpha matte predicting task:$I^i = \alpha^i F^i + (1-\alpha^i)B^i$
- ill-posed explanation:上面这个公式,等式右边的参数全是未知的,3通道像素值也就是3+3+1=7个未知数per pixel
- 所以通常才需要trimap辅助信息
- 提供0/0.5/1三种alpha构成的mask
- absolute foreground (α = 1),
- absolute background (α = 0)
- unknown area (α = 0.5)
- 这样任务就简化为,基于known 0/1 region的像素信息,需要预测unknown region的alpha probability
- matting任务heavily rely on low-level features
- trimap-free matting
- a semantic estimation step will then be needed to locate the foreground
- ASPP
- proved to boost the performance notably in segmentation-based tasks
- 本文改进了an efficient variant of ASPP
- Consistency Constraint
- Consistency supervision用于semi-/self-supervised
- MODNet imposes consistency among various sub-objectives within a model
方法
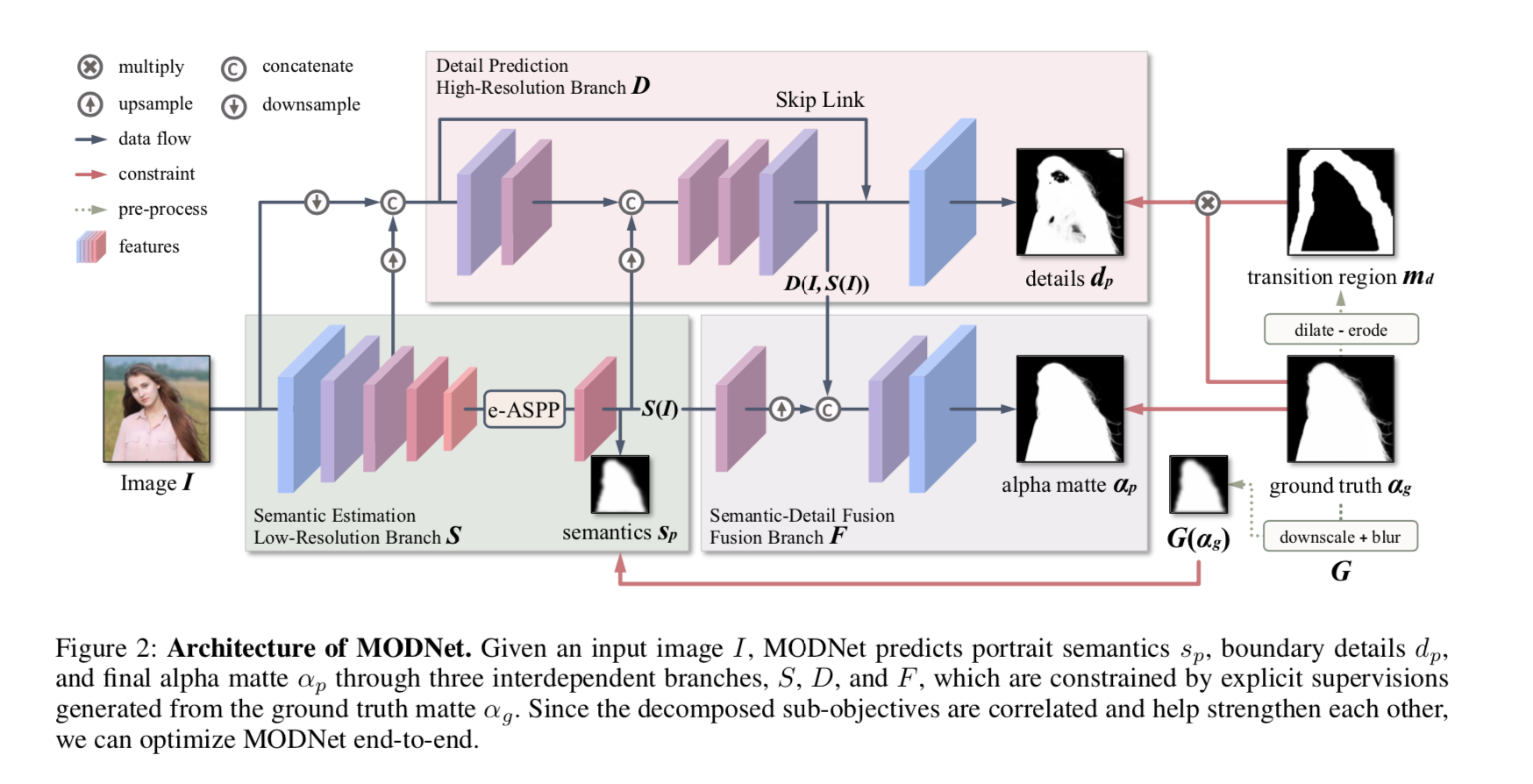
overview
- divide into three parts
- semantic estimation:前背景,x16 seg map,用coarse alpha监督
- detail prediction:边界细节,x4 boundary map,用boundary region的alpha监督
- semantic-detail fusion:信息融合,得到最终的alpha matte prediction
Architecture
- divide into three parts
Semantic Estimation
the low-resolution branch S
use an encoder MobileNetV2 to predict a coarse mask:16x downsamp
seg head:1x1conv + sigmoid
ground truth也是粗糙版:ground truth matte也做16x下采样+blur,去除了一些类似发丝的fine feature,专心提取前景整体
Efficient ASPP (e-ASPP):
- 标准的ASPP能解决分割前景有洞的情况,但是huge computation
- 空洞卷积多尺度提取+常规卷积融合——modify it in three steps:
- 空洞卷积分解成depth-wise conv和point-wise conv
- 调换point-wise和fuse conv的顺序
- fuse conv也替换为更cheaper的depth-wise conv
L2 loss
- $s_p$:predict alpha
$G(\alpha_g)$:粗糙化以后的ground truth alpha matte
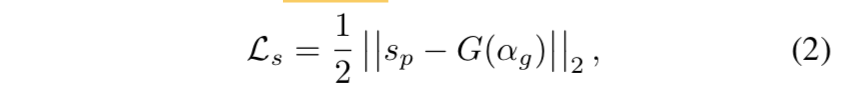
Detail Prediction
the high-resolution branch D
用原始图像I、Semantic Branch的输出S(I)、以及Semantic Branch的中间结果(low-level features) 作为输入
Branch D 超级轻量
- 层数少:12个conv
- 通道数少:64 maximum
- 没有保留原始解析率:第一层就下采样到4x,最后两层再复原,impact is negligible owing to skip link
L1 loss:focus on transition region only
- $m_d$:boundary mask,对$\alpha_g$先膨胀再腐蚀,提取transition area作为boundary mask
- $d_p$:D(I, S(I)),branch输出
$\alpha_g$:ground truth alpha matte
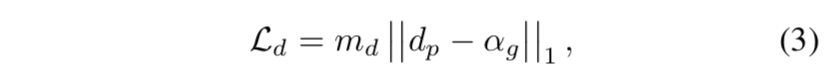
Semantic-Detail Fusion
the fusion branch F
combine semantics and details
- upsample S(I)
- then concat S(I) & D(I, S(I))
- 然后是convs+sigmoid,得到final predict matte
L1 loss + compositional loss
- L1 loss:全图的alpha matte的L1 loss
$L_c$: the absolute difference between input image I and the composited image,跟PP-matting公式10一样,用均方根~
- the composited image $I_p$ 用gt的fg和bg以及预测的alpha计算
- loss是L2 loss
$\alpha_p$:final prediction
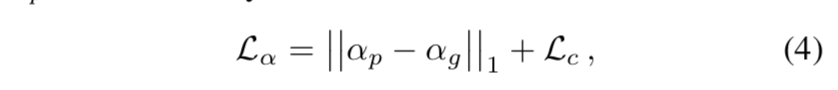
train end-to-end through the sum of losses above
- $\lambda_s = \lambda_a = 1$
$\lambda_d = 10$
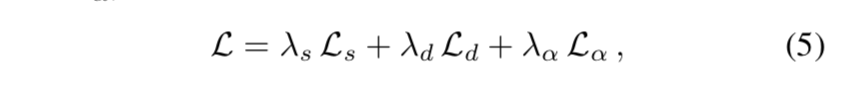
SOC for Real-World Data
portrait matting requires excellent labeling in the hair area,通常在摄影网站上找虚化背景的图标注的
常规的data aug是用背景替换的方式,但是和real-world data还是存在domain gap,模型通常过拟合训练集
utilize sub-objectives consistency (SOC) to adapt MODNet to unseen data distributions
MODNet的3个子任务在无标签数据上should have consistent outputs
given unlabeled Image I,预测$s, d, \alpha$
enforce the semantics in $\alpha$ to be consistent with $s$
- 还是用supervised training里面的L2 loss
- gt alpha替换成pred alpha
enforce the details in $\alpha$ to be consistent with $d$
- 还是用supervised training里面的L1 loss in transition region
- gt alpha替换成pred alpha
两项consistency loss加起来
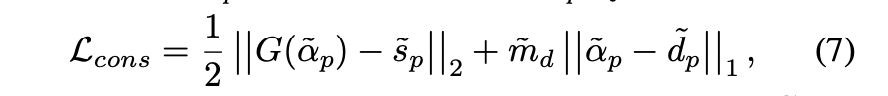
extra regularization term防止alpha虚化使得detail loss丧失细节信息