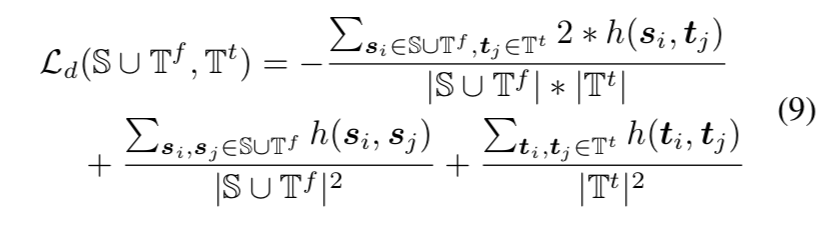Weakly Supervised Object Localization as Domain Adaption
动机
- Weakly supervised object localization (WSOL)
- localizing objects only with the supervision of image-level classification label
- previous method use classification structure and CAM to generate the localization score:CAM通常不完全focus在目标上,定位能力weak
- our method
- 将任务建模成域迁移任务,domain-adaption(DA) task
- score estimiator用image-level信息来训练,用像素级信息来测试
- a DA-WSOL pipeline
- a target sampling strategy
- domain adaption localization (DAL) loss
- Weakly supervised object localization (WSOL)
论点
CAM的表现不佳
- 核心在于domain shift:用分类架构,训练一个分类任务,是对image-level feature的优化,但是目标却是 localization score,这是pixel-level feature,两者之间没有建立联系
- 最终estimator会get overfitting on source domain(也就是image-level target)
- 一个直观的想法:引入DA,align the distribution of these two domains,avoid overfitting——activating the discriminative parts of objects
mechanisms
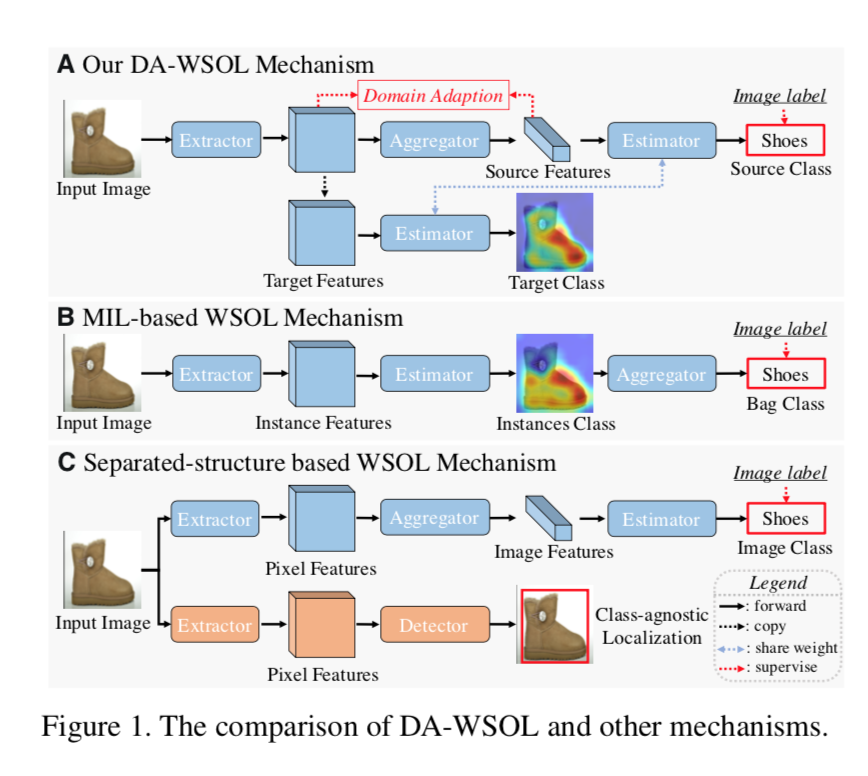
- B: Multi-instance learning(MIL) based WSOL
- 分类架构
- 类别目标驱动
- 通过各种data augmentation/cut mix来strengthen
- 印象里原论文是先训一个纯分类网络(CNN+fc),然后去掉头,改成CNN+GAP+fc,做finetuning,得到能产生CAM的网络(提取对应类别权重对特征图加权),因为需要两步训练,后面如果要看cam一半都是用grad-cam(用梯度的平均作为权重,无需重新训练),performance据说等价
- C: Separated-structure based WSOL
- 一个目标分类任务
- 一个目标定位任务:伪标签、多阶段
- A: Domain Adaption
- 引入DA to better assist WSOL task:align feature distribution between src/tgt domain
- end-to-end
- a target sampling strategy
- target domain features has a much larger scale than source domain features:显然image-level task下,训练出的特征提取器更多的保留前景特征,但是pixel-level下还包含背景之类的
- sampling旨在选取source-related target samples & source unseen target samples
- domain adaption localization (DAL) loss
- 上述的两类samples fed into这个loss
- source-related target samples:to solve the sample imbal- ance between two domains
- source unseen target samples:viewed as the Universum to perceive target cues
- B: Multi-instance learning(MIL) based WSOL
方法
Revisiting the WOSL
- task description:给定$image X\in R^{3 \times N} $,3通道N个pixel,需要分辨任意像素$X_{:,i}$是否属于a certain class 0-k
- a feature extractor f(~):用来提取pixel-level features $Z = f(X) \in R^{C \times N}$
- a score estimator e(~):用来估计pixel的localization score $Y=e(Z) \in R^{K \times N}$
- 在有监督场景下,pixel-level target Y是直接给定的,但是在无监督场景下,我们只有image-level mask,即$y=(max(Y_{0:}), max(Y_{1:}), …, max(Y_{k:})) \in R^{K \times 1}$,即每个feature map的global max/avg value构成的feature vector
- an additional aggregator g (~):用来聚合feature map,将pixel-level feature转换成image-level $z=g(Z) \in R^{C\times 1}$,如GAP
- 然后再fed into the score estimator above:$y^* = e(z) \in R^{K \times 1}$
- 用classification loss来监督$y$和$y^*$,这就是一个分类任务
- but at test time:the estimator is projected back onto the pixel-level feature Z to predict the localization scores,这就是获取CAM
Modeling WSOL as Domain Adaption
- 对每个sample X,建立两个feature sets S & T
- source domain:$s = z = (gf)(X)$
- target domain:$\{t_1,t_2,…,t_N\} =\{Z_{1,:},Z{2,:},…,Z{N,:}\}=f(X)$
- aim at minimizing the target risk without accessing the target label set (pixel-level mask),可以转化为:
- minimizing source risk
- minimizing domain discrepancy
- $L(S,Y^S,T) = L_{cls}(S,Y^S) + L_a(S,T)$
- loss
- L_cls就是常规的分类loss,在image-level上train
- L_a是proposed adaption loss,用来最小化S和T的discrepancy,会force f(~)和g (~)去学习domain-invariant features
- 使得 e(~)在S和在T上的performance相似
properties to notice
- some samples在set T中存在,而在set S中不存在,如background,不能强行align两个set
- 两个分布的scale比例十分imbalance,1:N——the S set in some degree insufficient
- 两个分布的差异是已知的,就是aggregator g (~),这是个先验知识
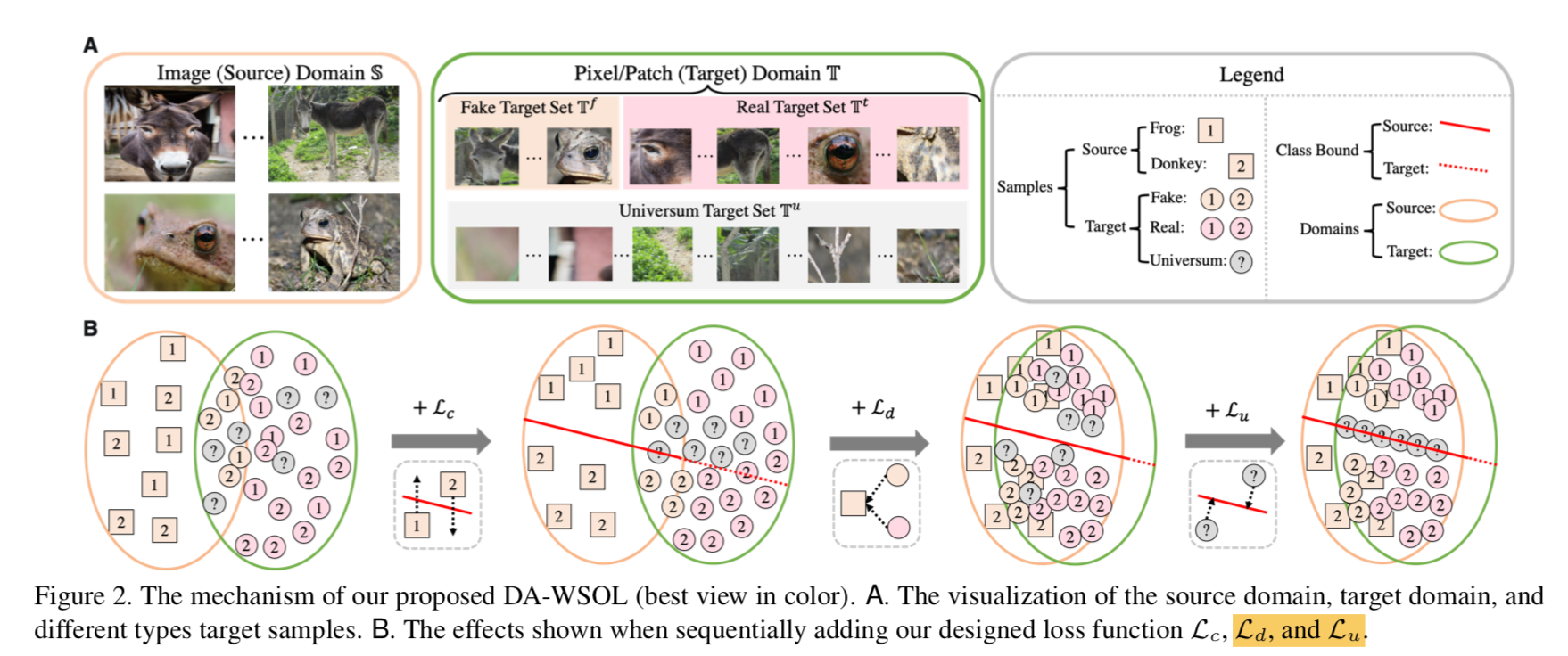
mechanism as in figure
- 起初两个分布并不一致,方框1/2是image level feature,圆圈1/2是pixel level feature,圆圈问号类是pixel map上的bg patches
- 用class loss去监督如CAM method,能够区分方框1/2,在一定程度上也能够区分圆圈1/2,但是不能精准定位目标,因为S和T存在discrepancy——bg patches
- 引入domain adaption loss,能够tighten两个set,使得两个分布更加align,这样class bound在方框1/2和圆圈1/2上的效果都一样好
引入Universum regularization,推动decision boundary into Universum samples,使得分类边界也有意义
- 对每个sample X,建立两个feature sets S & T
Domain Adaption Localization Loss $L_a$(~)
- 首先进一步切分target set T
- Universum $T^u$:不包含前景类别/bg样本
- the fake $T^f$:和source domain的sample highly correlated的样本(在GAP时候被保留下来的样本)
- the real $T^t$:aside from above two的样本
- recall the properties
- the fake之所以会highly correlated source domain,就是因为先验知识GAP (property3),我们知道他就是在GAP阶段被留下来的target sample
- 我们可以将其作为source domain的补充样本,以弥补insufficient issue (property2)
- 关于unmatched data space (property1),T-Universum就与S保持same label space了
- based on these subsets,overall的DAL loss包含两个部分
- domain adaption loss $L_d$:UDA,unsupervised,align the distribution
- Universum regularization $L_u$:feature-based L1 regularization,所有bg像素的绝对值之和,如果他们都在分类边界上,不属于任何一个前景类,localization score的响应值就都是0,那么loss就是0
- $L_a(S,T) = \lambda_1L_d(S \cup T^f, T^t) + \lambda_2 L_u(T^u)$
- 首先进一步切分target set T
Target Sampling Strategy (这个有点不太理解)
- a target sample assigner(TSA)
- a cache matrix $M \in R^{C \times (K+1)}$
- column 0:represents the anchor of $T^u$
- the rest column:represents the anchor of certain class of $T^t$
- 感觉就是记录了每类column vec的簇心
init
- column 0:zero-init
- the rest:当遇到第一个这一类的样本的时候,用src vec $z+\epsilon$初始化
update
- 首先基于image-level label得到类别id:$k = argmax(y)$,注意使用ground truth,不是prediction vec
- 然后拿到cache matrix中对应的anchor:$a^u = M_{:,0}, \ \ a^t = M_{:,k+1}$
- 然后再加上image-level predict作为初始的cluster:$C_{init} = \{a^u, a^t, z\} \in R^{C \times 3}$
- 对当前target samples做K-means,得到三类样本,进而计算adaption loss
用聚类得到的新center C,加权平均更新cache matrix,权重$r_k$是对应类images的数目的倒数
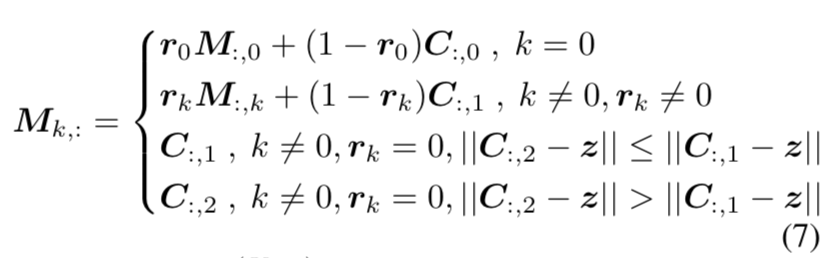
overall
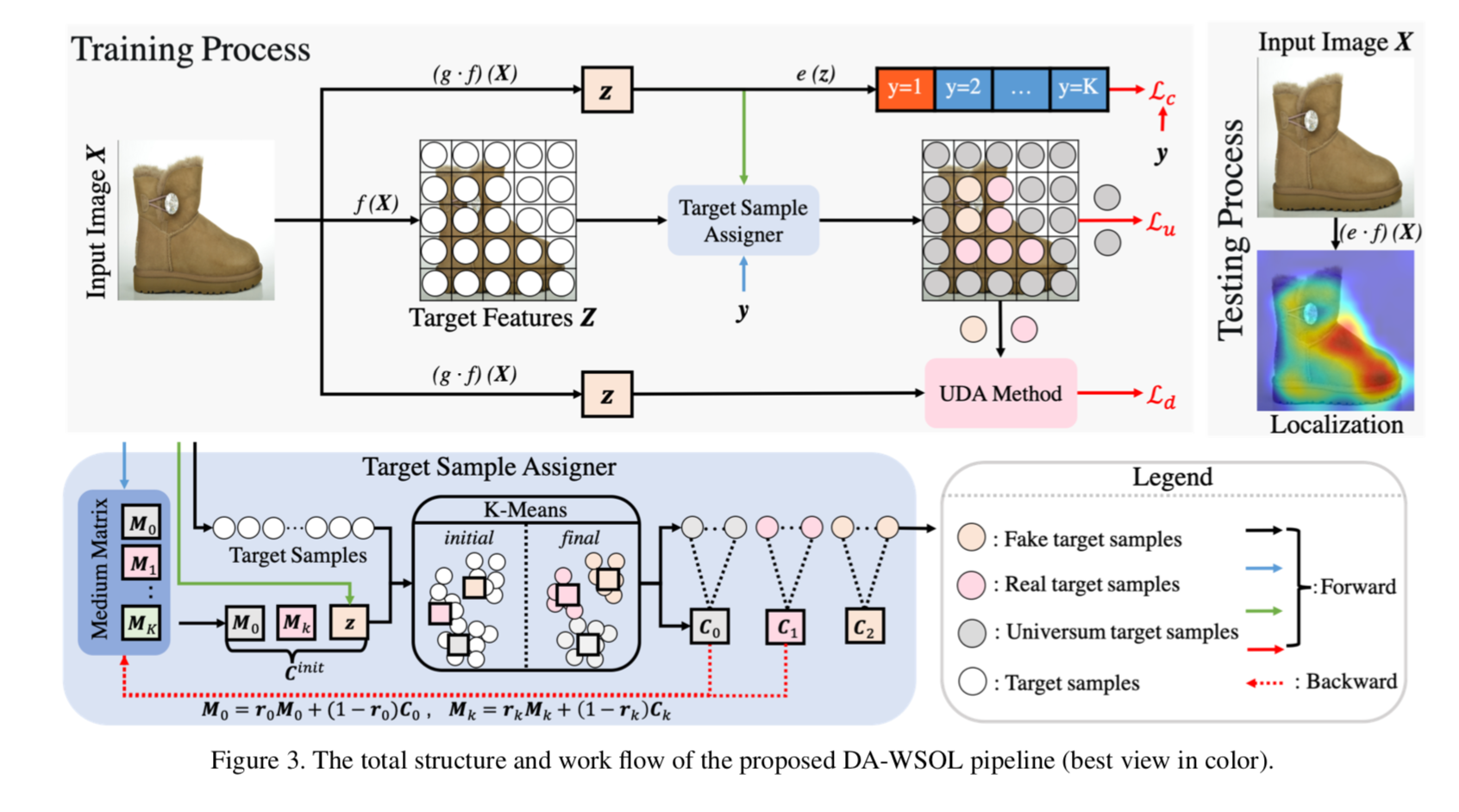
pipeline summary
首先获得S和T,f(~)是classification backbone(resnet/inception),g(~)是 global average pooling,e(~)是作用在source domain feature vector的 fully-connected layer ,generate the image-level classification score,supervised with cross-entropy
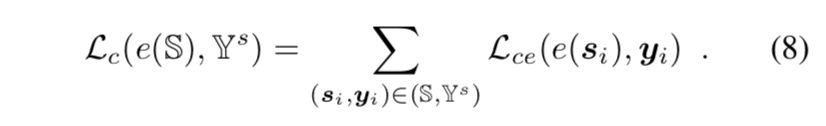
然后通过S、T以及ground truth label id得到3个target subsets
$T^u$用来计算$L_u$
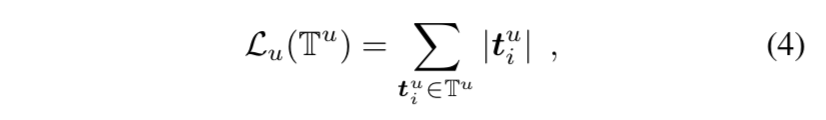
$S$和$T^f$和$T^t$用来计算$L_d$:MMD (Maximum Mean Discrepancy),h(~)是高斯kernel