facebook,2022,https://github.com/facebookresearch/ConvNeXt
inductive biases(归纳偏置)
- 卷积具有较强的归纳偏置:即strong man-made settings,如local kernel和shared weights,只有spatial neighbor之间有关联,且在不同位置提取特征的卷积核共享——视觉边角特征与空间位置无关
- 相比之下,transformer结构就没有这种很人为的先验的设定,就是global的优化目标,所以收敛也慢
A ConvNet for the 2020s
动机
- reexamine the design spaces and test the limits of what a pure ConvNet can achieve
- 精度
- achieving 87.8% ImageNet top-1 acc
- outperforming Swin Transformers on COCO detection and ADE20K segmentation
论点
- conv
- a sliding window strategy is intrinsic
- built-in inductive biases:卷积的归纳偏置是locality和spatial invariance
- 即空间相近的grid elements有联系而远的没有:translation equivariance is a desirable property
- 空间不变性:shared weights,inherently efficient
- ViT
- 除了第一层的patchify layer引入卷积,其余结构introduces no image-specific inductive bias
- global attention这个设定的主要问题是平方型增长的计算量
- 使得这个结构在classification任务上比较work,但是在其他任务场景里面(需要high resolution,需要hierarchical features)使用受限
- Hierarchical Transformers
- hybrid approach:重新引入local attention这个理念
- 能够用于各类任务
- 揭露了卷积/locality的重要性
- this paper brings back convolutions
- propose a family of pure ConvNets called ConvNeXt
- a Roadmap:from ResNet to ConvNet
- conv
方法
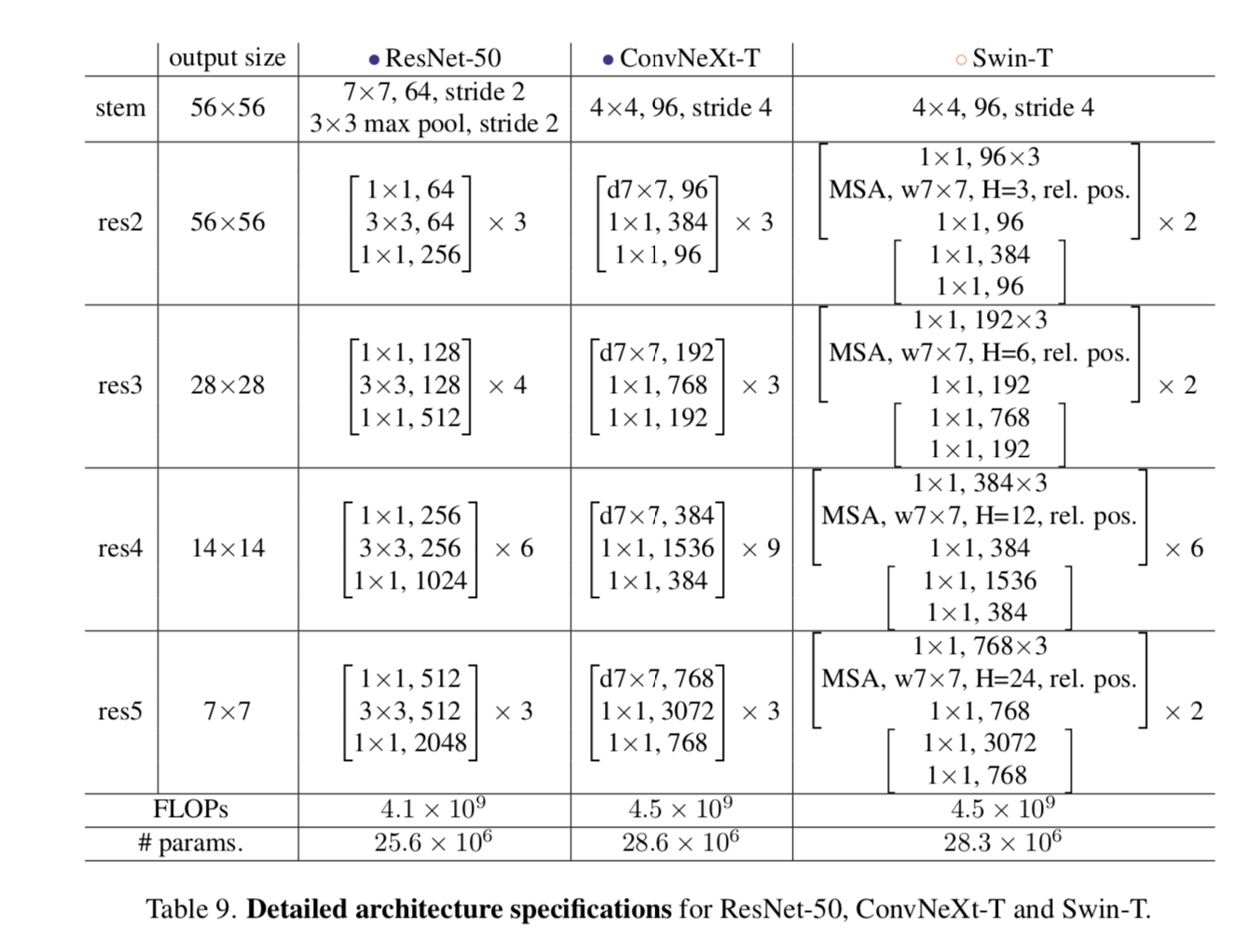
from ResNet to ConvNet
- ResNet-50 / Swin-T:FLOPs around 4.5e9
- ResNet-200 / Swin-B around 15e9
首先用transformer的训练技巧训练初始的resnet,作为baseline,然后逐步改进结构
- macro design
- ResNeXt
- inverted bottleneck
- large kernel size
- various layer-wise micro designs
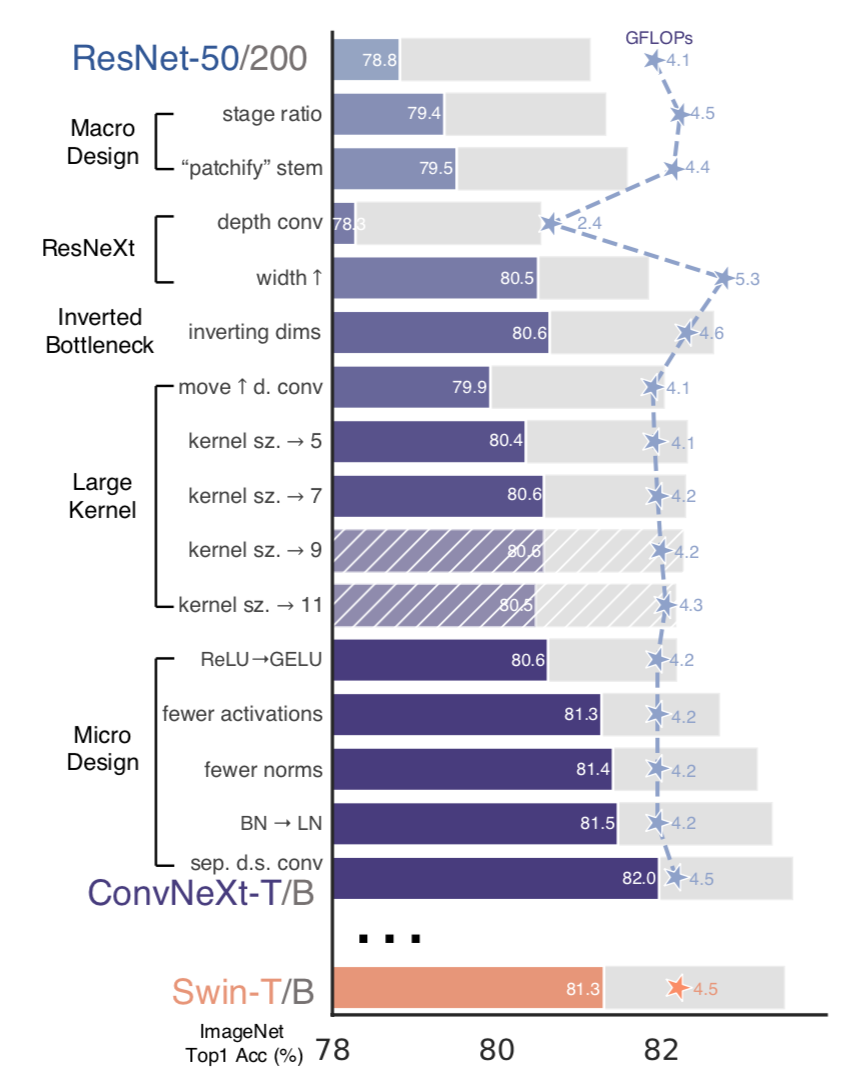
Training Techniques
- 300 epochs
- AdamW
- aug:Mixup,CutMix,RandAugment,Random Erasing
- reg:Stochastic Depth,Label Smoothing
这就使得resnet的精度从76.1%提升到78.8%
Macro Design
- 宏观结构就是multi-stage,每个stage的resolution不同,涉及的结构设计有
- stage compute ratio
- stem cell
- swin的stage比是1:1:3:1,larger model是1:1:9:1,因此将resnet50的3:4:6:3调整成3:3:9:3,acc从 78.8% 提升至 79.4%
- 将stem替换成更加aggressive的patchify,4x4conv,s4,non-overlapping,acc从 79.4% 提升至 79.5%
- 宏观结构就是multi-stage,每个stage的resolution不同,涉及的结构设计有
ResNeXt-ify
- 用分组卷积来实现更好的FLOPs/acc的trade-off
- 分组卷积带来的model capacity loss用增加网络宽度来实现
- 使用depthwise convolution,同时width从64提升到96
- groups=channels
- similar to the weighted sum of self-attention:在spatial-dim上mix information
- acc提升至80.5%,FLOPs增加5.3G
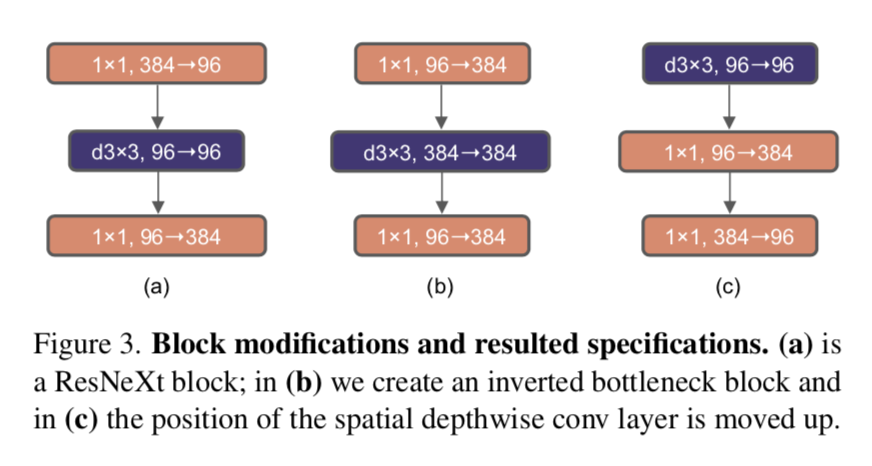
Inverted Bottleneck
transformer block的ffn中,hidden layer的宽度是输入宽度的4倍
MobileNet & EfficientNet里面也有类似的结构:中间大,头尾小
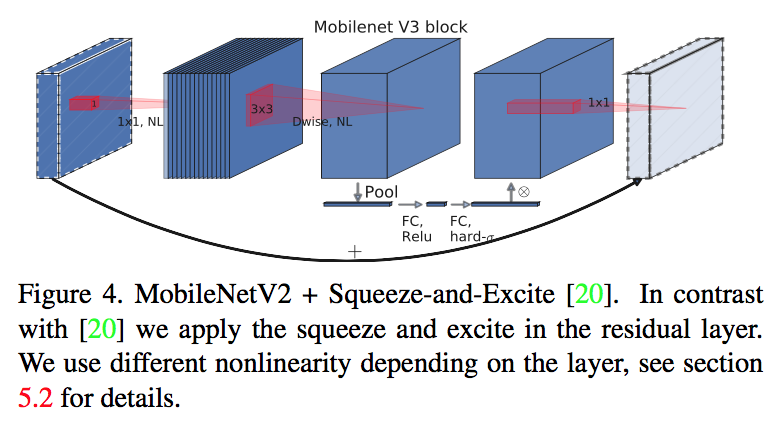
而原始的resne(X)t是bottleneck结构:中间小,两头大,为了节约计算量
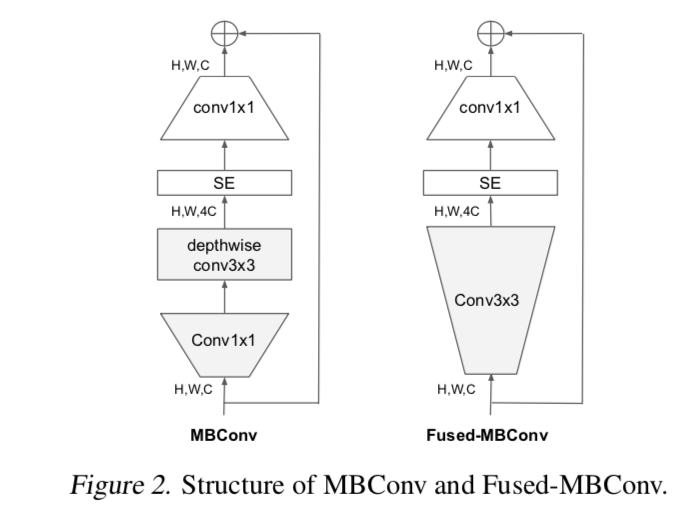
- reduce FLOPs:因为shortcut上面的1x1计算量小了
- 精度稍有提升:80.5% to 80.6%,R200/Swin-B上则更显著一点,81.9% to 82.6%
Large Kernel Sizes
- 首先将conv layer提前,类比transformer的MSA+FFN
- reduce FLOPs,同时精度下降至79.9%
- 然后增大kernel size,尝试[3,5,7,9,11],发现在7的时候精度饱和
- acc:from 79.9% (3×3) to 80.6% (7×7)
Micro Design:layer-level的一些尝试
- Replacing ReLU with GELU:原始的transformer paper里面也是用的ReLU,但是后面的先进transformer里面大量用了GeLU,实验发现可以替换,但是精度不变
- Fewer activation functions:transformer block里面有QKV dense,有proj dense,还有FFN里的两个fc层,其中只有FFN的hidden layer接了个GeLU,而原始的resnet每个conv后面都加了relu,我们将resnet也改成只有类似线性层的两个1x1 conv之间有激活函数,acc提升至81.3%,nearly match Swin
Fewer normalization layers:我们比transformer还少用一个norm(因为实验发现加上入口那个LN没提升),acc提升至81.4%,already surpass Swin
Substituting BN with LN:BN对于convNet,能够加快收敛抑制过拟合,直接给resnet替换LN会导致精度下降,但是在逐步改进的block上面替换则会slightly提升,81.5%
- Separate downsampling layers:学Swin,不再将stride2嵌入resnet conv,而是使用独立的2x2 s2conv,同时发现在resolution改变的时候加入norm layer能够stabilize training——每个downsamp layer/stem/final GAP之后都加一个LN,acc提升至82%,significantly exceeding Swin
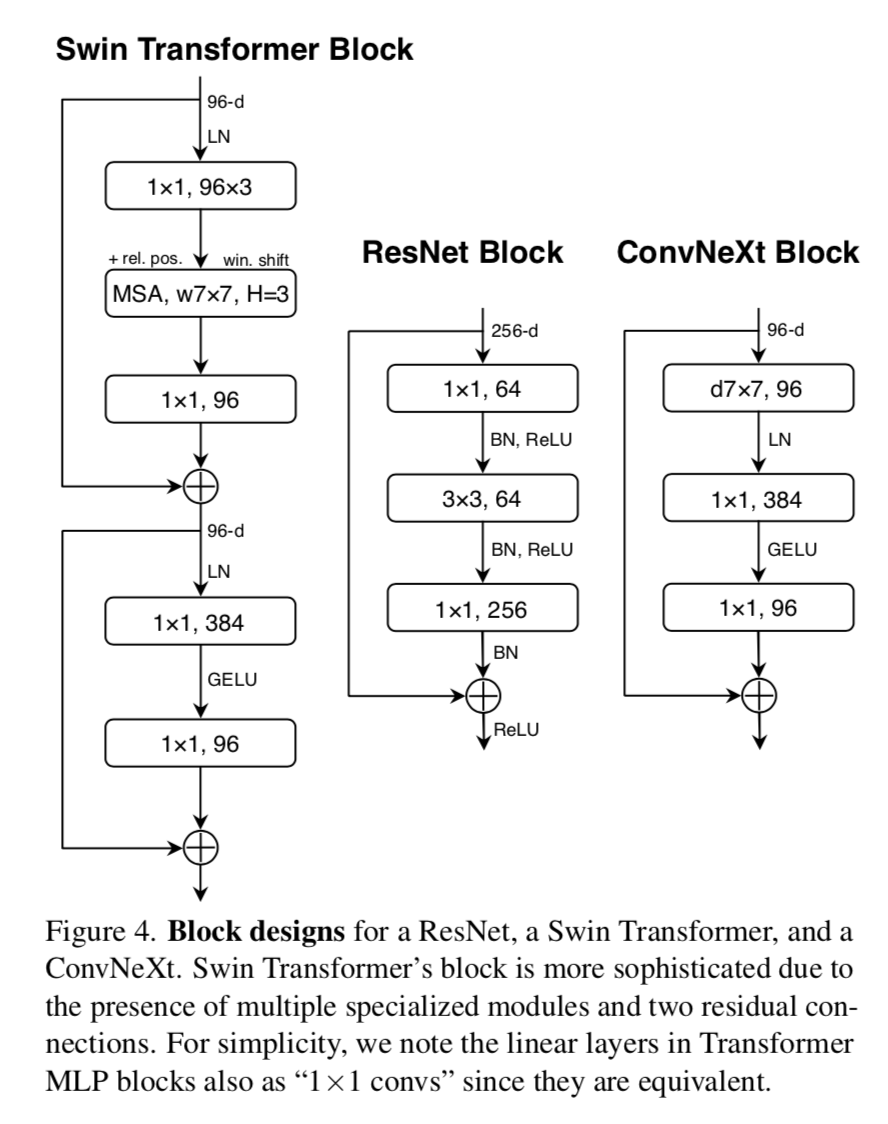
overall structural params