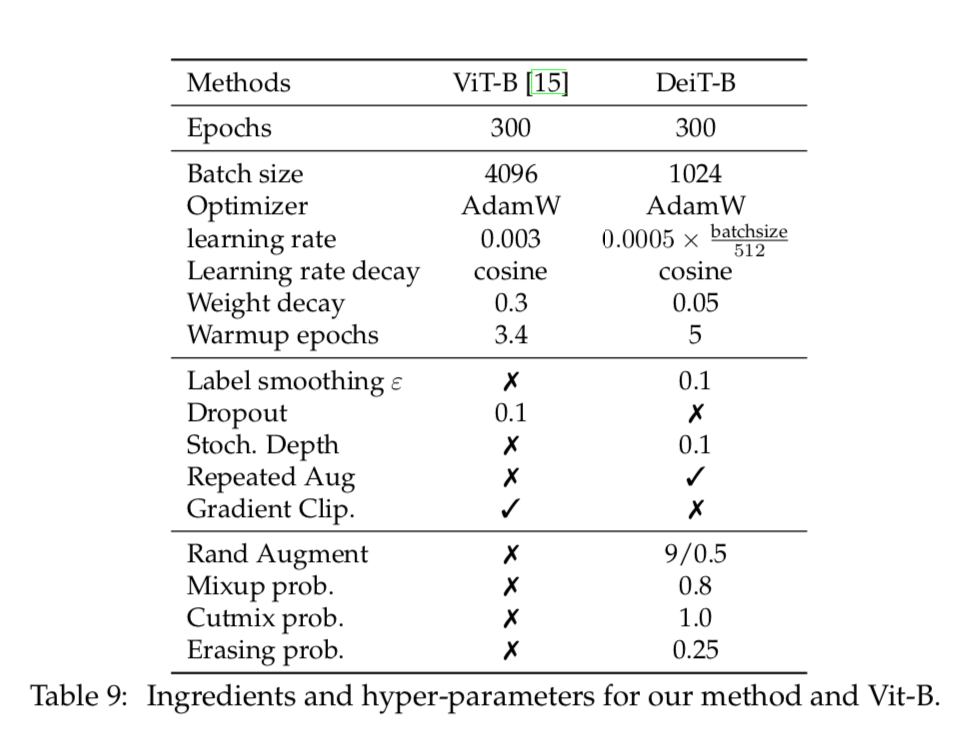
炼丹大法:
[Google 2021] How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers,Google,rwightman,这些个点其实原论文都提到过了,相当于补充实验了
[Google 2022] Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time,多个模型权重做平均
[Facebook DeiT 2021] Training data-efficient image transformers & distillation through attention,常规技巧大全
How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers
动机
- ViT vs. CNN
- 没有了平移不变形
- requires large dataset and strong AugReg
- 这篇paper的contribution是用大量实验说明,carefully selected regularization and augmentation比憨憨增加10倍数据量有用,简单讲就是在超参方面给一些insight
- ViT vs. CNN
方法
basic setup
pre-training + transfer-learning:是在google research的原版代码上,TPU上跑的
inference是在timm的torch ViT,用V100跑的
data
- pretraining:imagenet
- transfer:cifar
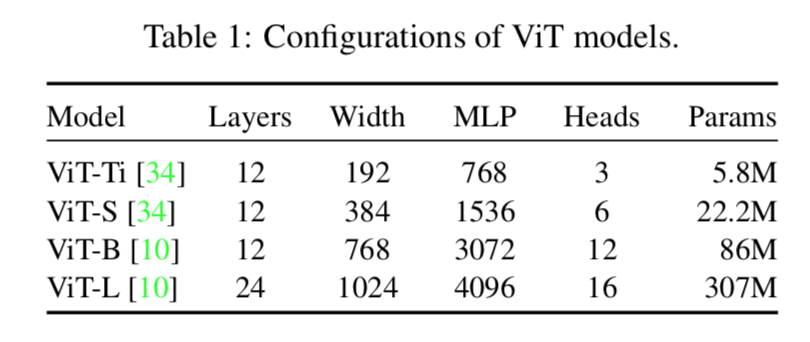
models
- [ViT-Ti, ViT-S, ViT-B and ViT-L][https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py]
- 决定模型scale的几个要素:
- depth:12,24,32,40,48
- embed_dim:192,384,768,1024,1280,1408
- mlp_ratio:4,48/11,64/13
- num_heads:3,6,12,16
- 还有影响计算量的变量:
- resolution:224,384
- patch_size:8,16,32
和原版唯一的不同点是去掉了MLP head里面的hidden layer——那个fc-tanh,据说没有performance提升,还会引发optimization instabilities
Regularization and data augmentations
- dropout after each dense-act except the Dense_QKV:0.1
- stochastic depth:线性增长dbr,till 0.1
- Mixup:beta分布的alpha
- RandAugment:randLayers L & randMagnitude M
- weight decay:0.1 / 0.03,注意这个weight decay是裸的,实际计算是new_p = new_p - p*weight_decay*lr,这个WD*lr可以看作实际的weight decay,也就1e-4/-5量级
Pre-training
- Adam:[0.9,0.999]
- batch size:4096
- cosine lr schedule with linear warmup(10k steps)
- gradients clip at global norm 1
- crop & random horizontal flipping
- epochs:ImageNet-1k 300 epochs,ImageNet-21k [30,300] epochs
Fine-tuning
- SGD:0.9
- batch size:512
- cosine lr schedule with linear warmup
- gradients clip at global norm 1
- resolution:[224,384]
结论
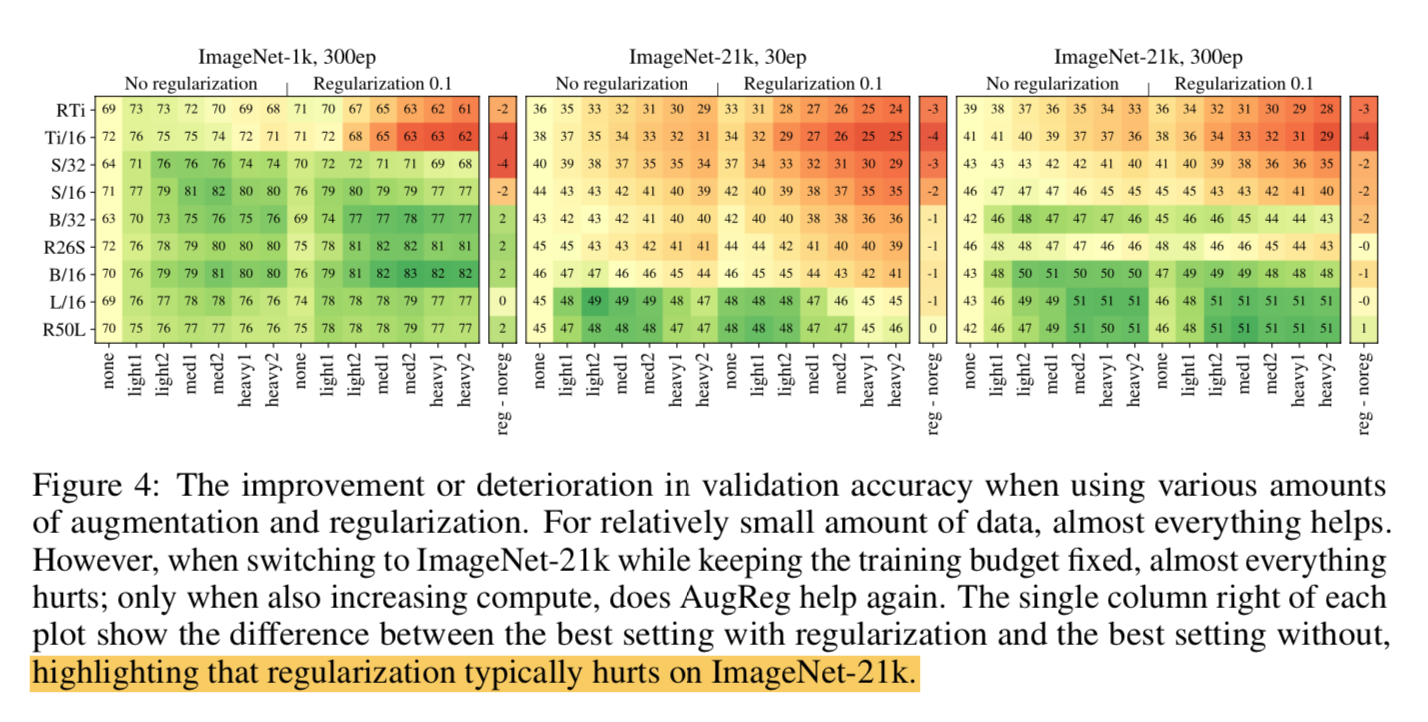
Scaling datasets with AugReg and compute:加大数据量,加强aug®
proper的AugReg和10x的数据量都能引导模型精度提升,而且是差不多的水平
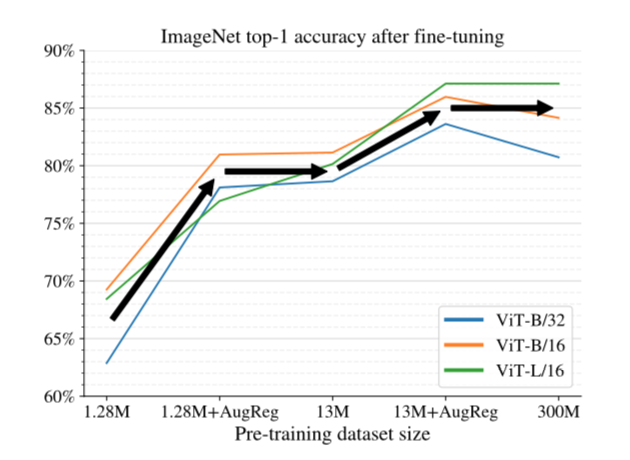
Transfer is the better option:永远用预权重去transfer,尤其大模型
- 在数据量有限的情况下,train from scratch基本上不能追上transfer learning的精度
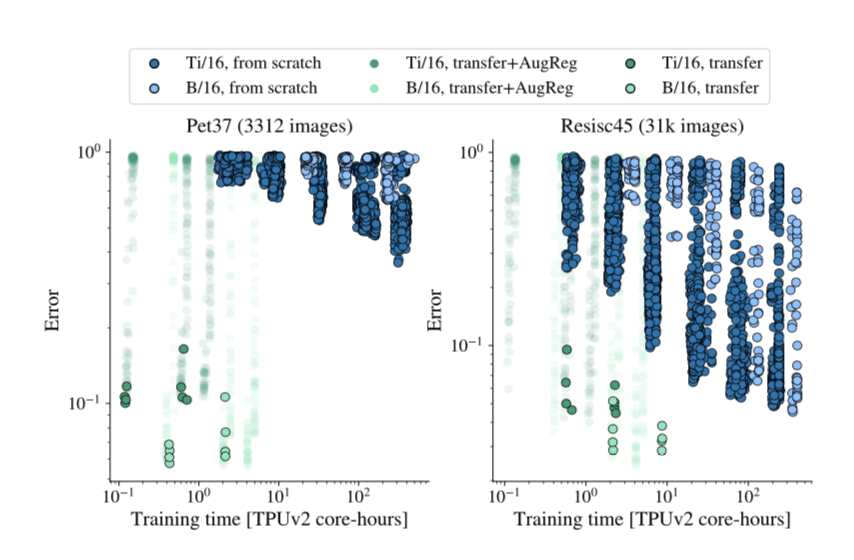
More data yields more generic models:加大数据,越大范化性越好
Prefer augmentation to regularization:非要比的话aug > reg,成年人两个都要
- for mid-size dataset like ImageNet-1k any kind of AugReg helps
- for a larger dataset like ImageNet-21k regularization almost hurts,但是aug始终有用
Choosing which pre-trained model to transfer
- Prefer increasing patch-size to shrinking model-size:显存有限情况下优先加大patch size
- 相似的计算时间,Ti-16要比S-32差
- 因为patch-size只影响计算量,而model-size影响了参数量,直接影响模型性能
Training data-efficient image transformers & distillation through attention
动机
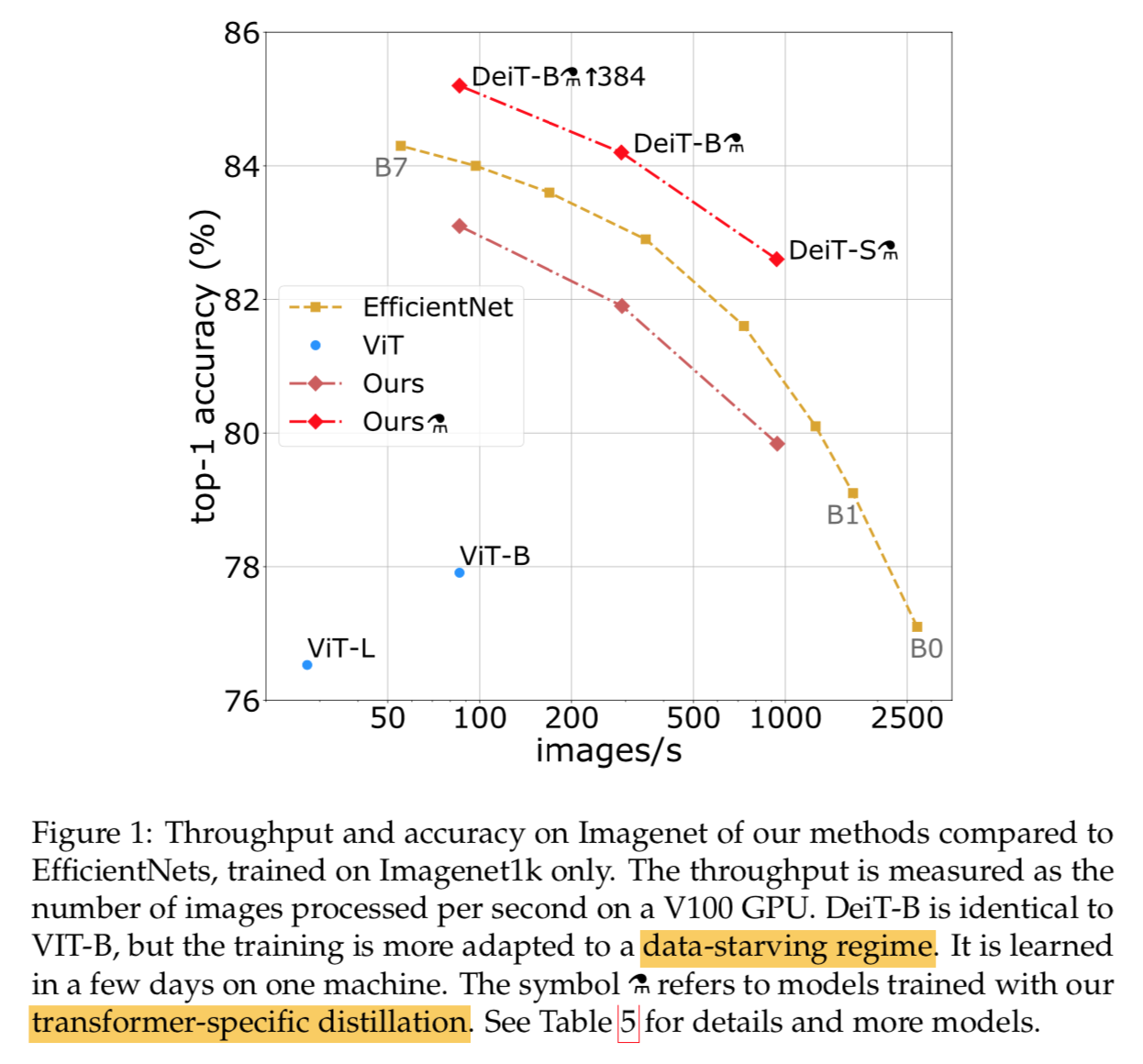
- 大数据+大模型的高精度模型不是谁都负担得起的
- we produce competitive model
- use Imagenet only
- on single computer,8-gpu
- less than 3 days,53 hours pretraining + 20 hours finetuning
- 模型:86M,top-1 83.1%
- 脸厂接地气!!!
- we also propose a tranformer-specific teacher-student strategy
- token-based distillation
- use a convnet as teacher
论点
本文就是在探索训练transformer的hyper-parameters、各种训练技巧
Knowledge Distillation (KD)
- 本文主要关注teacher-student
- 用teacher生成的softmax结果(soft label)去训练学生,相当于用student蒸馏teacher
- the class token
- a trainable vector
- 和patch token接在一起
- 然后接transformer layers
- 然后 projected with a linear layer to predict the class
- 这种结构force self-attention在patch token和class token之间进行信息交换
- 因为class token是唯一的监督信息,而patch token是唯一的输入变量
- contributions
- scaling down models:DeiT-S和DeiT-Ti,向下挑战resnet50和resnet18
- introduce a new distillation procedure based on a distillation token,类似class token的角色
- 特殊的distillation机制使得transformer相比较于从同类结构更能从convnet上学到更多
- well transfer
方法
首先假设我们有了一个strong teacher,我们的任务是通过exploiting the teacher来训练一个高质量的transformer
Soft distillation
- teacher的softmax logits不直接做标签,而是计算两个KL divergence
CE + KL loss
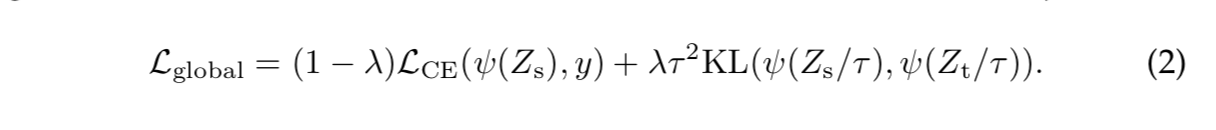
Hard-label distillation
- 就直接用作label
CE + CE
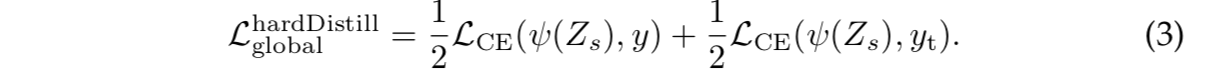
实验发现hard比soft结果好
Distillation token
- 在token list上再添加一个new token
- 跟class token的工作任务一样
- distillation token的优化目标是上述loss的distillation component
- 与class token相辅相成
作为对比,也尝试了用原本的CE loss训练两个独立的class token,发现这样最终两个class token的cosine similarity高度接近1,说明额外的class token没有带来有用的东西,但是class token和distillation token的相似度最多也就0.93,说明distillation branch给模型add something,【难道不是因为target不同所以才不同吗???】

Fine-tuning with distillation
- finetuning阶段用teacher label还是ground truth label?
- 实验结果是teacher label好一点
Joint classifiers
- 两个softmax head相加
- 然后make the prediction
Training details & ablation
Initialization
- Transformers are highly sensitive to initialization,可能会导致不收敛
- 推荐是weights用truncated normal distribution
Data-Augmentation
- Auto-Augment, Rand-Augment, random erasing, Mixup等等
- transformers require a strong data augmentation:几乎都有用
除了Dropout:所以我们把Dropout置零了
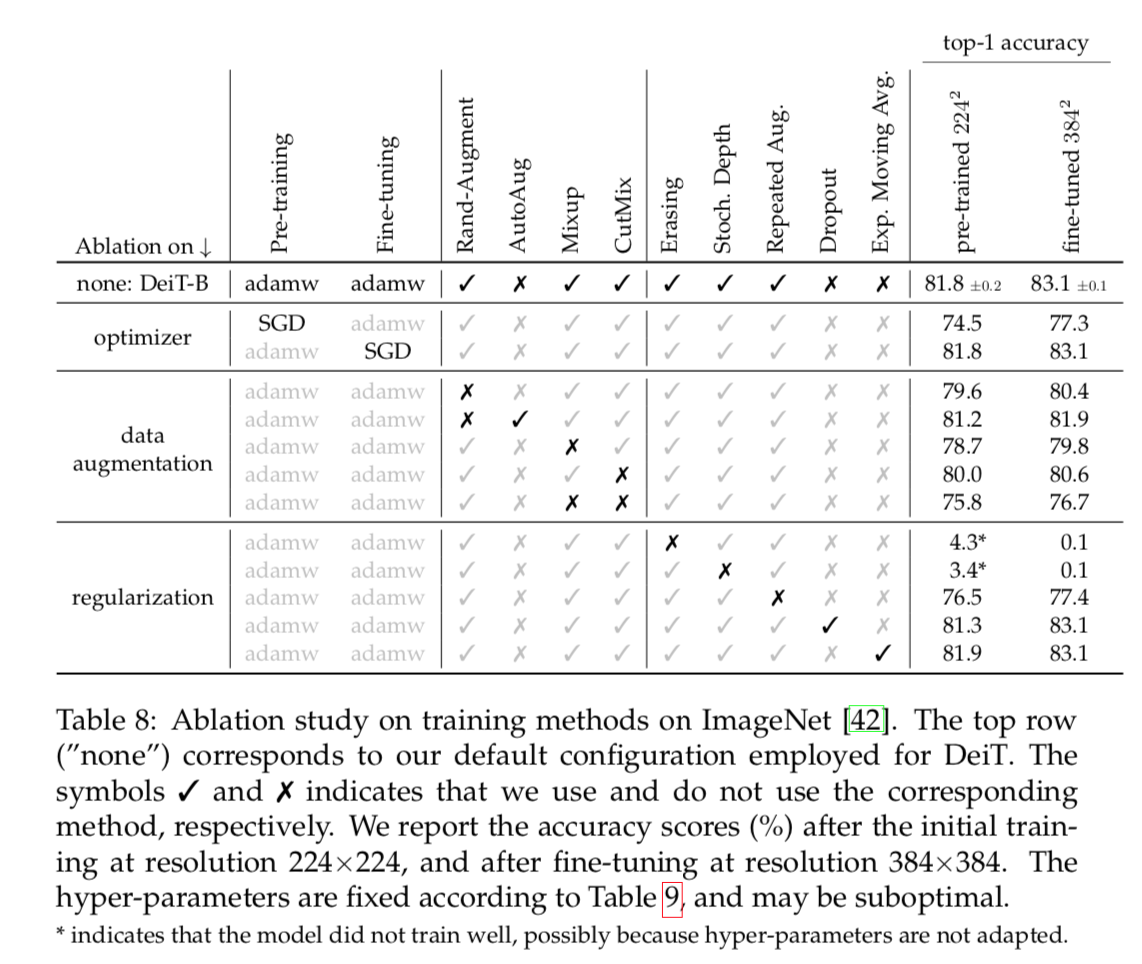
Optimizers & Regularization
- AdamW
- 和ViT一样的learning rate
但是much smaller weight decay:发现weight decay会hurt convergence