papers
[MAE] Masked Autoencoders Are Scalable Vision Learners:恺明,将BERT的掩码自监督模式搬到图像领域,设计基于masked patches的图像重建任务
[VideoMAE] VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training:腾讯AI Lab,进一步搬运到video领域
Masked Autoencoders Are Scalable Vision Learners
动机
- 一种自监督训练(pretraining)方式,用来提升模型泛化性能
- 技术方案:
- mask & reconstruct
- encoder-decoder architecture
- encoder operates only on visible patches:首先对input patches做random sampling,只选取少量patches给到encoder
- lightweight decoder run reconstruction on (masked) tokens:将encoded patches和mask tokens组合,给到decoder,用于重建原始图像
- 精度
- with MAE pretraining,ViT-Huge on ImageNet-1k:87.8%
论点
自监督路线能给到模型更大体量的数据,like NLP,masked autoencoding也是经典的BERT训练方式,but现实是autoencoding methods in vision lags behind NLP
- information density:NLP是通过提取高级语义信息去推断空缺的,而图像如果有充足的邻里低级空间信息,就能重建出来不错的效果,导致模型没学到啥高级语义信息就收敛了,本文的解决方案是random mask极大比例的patches,largely reduce redundancy
- decoder plays a different role be- tween reconstructing text and images:和上一条呼应,visual decoder重建的是像素,低级信息,NLP decoder重建的是词向量,是高级表征,因此BERT用了个贼微小的结构来建模decoder——一个MLP,但是图像这边decoder的设计就重要的多——plays a key role in determining the semantic level of the learned latent representations
our MAE
- 不对称encoder-decoder
- high portion masking:既提升acc又减少计算量,easy to scale-up
workflow
- MAE pretraing:encode random sampled patches,decode encoded&masked tokens
- down stream task:save encoder for recognition tasks
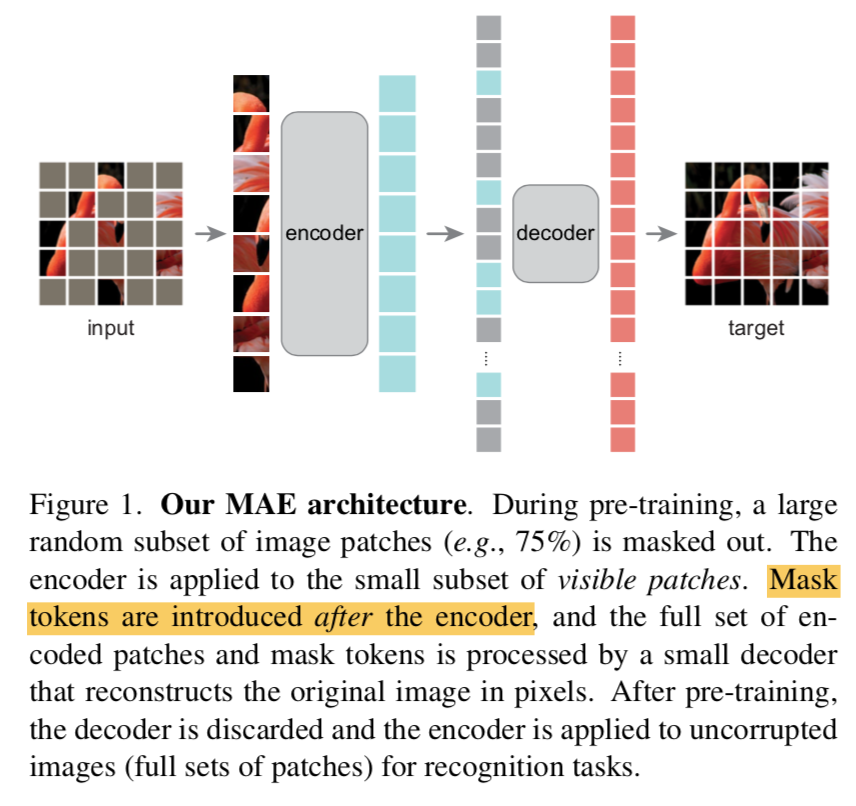
方法
- masking
- 切分图像:non-overlapping patches
- 随机采样:random sample the patches following a uniform distribution
- high masking ratio:一定要构建这样的task,不能简单通过邻里低级信息恢复出来,必须要深入挖掘高级语义信息,才能推断出空缺是啥
- MAE encoder
- ViT
- given patches:linear proj + PE
- operates on a small visible subset(25%) of the full set
- 负责recognition任务
- MAE decoder
- a series of Transformer blocks:远小于encoder,narrower and shallower,单个token的计算量是encoder的<10%
- given full set tokens
- mask tokens:a shared & learned vector 用来表征missing patches
- add PE:从而区别不同的mask token
- 负责reconstruction任务
- Reconstruction target
- decoder gives the full set reconstructed tokens:[b,N,D]
- N:patch sequence length
- D:patch pixel values
- reshape:[b,H,W,C]
- 重建loss,per-pixel MSE:compute only on masked patches
- 【QUESTION,这个还没理解】还有一个变体,官方代码里叫norm_pix_loss,声称是for better representation learning,以每个patch的norm作为target:
- 对每个masked patch,计算mean&std,
- 然后normalize,
- 这个normed patch作为reconstruction target
- decoder gives the full set reconstructed tokens:[b,N,D]
- masking