- 目标检测leaderboard: https://paperswithcode.com/sota/object-detection-on-coco
- boxAP
- swin开启了霸榜时代:家族第一名63.1
- 接着是YOLO家族:家族第一名57.3,YOLOv4是55.8
- DETR:论文里是44.9(没在榜单上),只有一个deformable DETR是52.3
- 时代的眼泪Cascade Mask R-CNN:42.8
- anchor-free系列:FCOS是44.7,centerNet是43.5
- 目前检测架构的几个霸榜算法
- DETR系列end-to-end
- Swin放在传统二阶段架构里面
- YOLO
- tricks加持:multi-scale、TTA、self-training、cascade、GIoU
papers
[DETR 2020] End-to-End Object Detection with Transformers:Facebook,首个端到端检测架构,无需nms等后处理,难优化,MSA的显存/计算量
[Swin 2021] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows:微软,主要是swin-back的建模能力强,放在啥框架里都很行
[deformable DETR 2021] DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION:商汤,将MSA卷积话,解决transformer的high-resolution困境
[anchor DETR 2022] Anchor DETR: Query Design for Transformer-Based Object Detection:旷视,new query design,也是针对attention结构的变种(cross-attention),精度更高,显存更少,速度更快,收敛更快
[DDQ 2022] What Are Expected Queries in End-to-End Object Detection? 商汤,基于DETR,讨论新的dense queries
repo
https://github.com/facebookresearch/detr
https://github.com/facebookresearch/3detr,3D版本
https://github.com/fundamentalvision/Deformable-DETR
Swin details for object detection
integrate Swin backbone into 4 frameworks in mmdetection
- Cascade Mask R-CNN
- ATSS
- RepPoints v2
- Sparse RCNN
basic setttings
- multi-scale training:resize输入使得shorter side is between 480 and 800
- AdamW:lr=0.0001,weight decay=0.05
- batch size=16
- stochastic depth=0.2
- 3x schedule (36 epochs with the learn- ing rate decayed by 10× at epochs 27 and 33)
- pretrained:use a ImageNet-22K pre-trained model as initialization
compare to ResNe(X)t
R50 vs. Swin-T:Swin-T普遍优于R50,4个框架Cascade Mask R-CNN > RepPoints V2 > Sparse R-CNN > ATSS
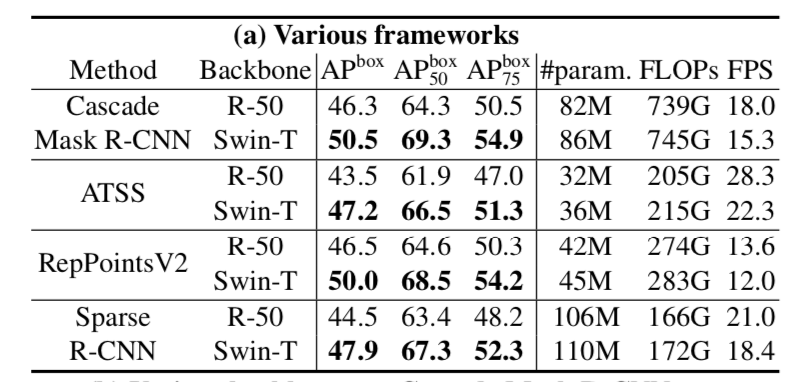
X101 vs. Swin-S & X101-64 vs. Swin-B:Swin普遍优于RX
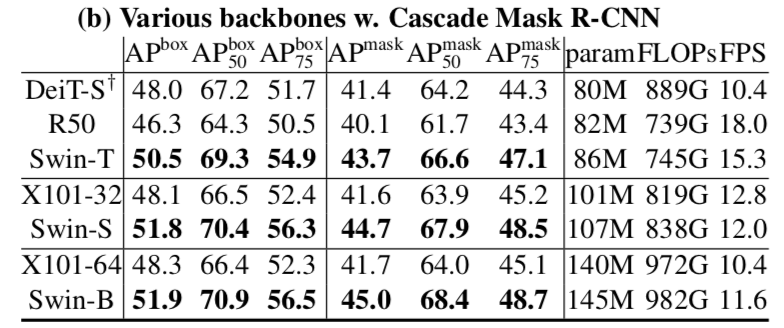
System-level Comparison:进一步加强Swin-L
- HTC++
- stonger multi-scale input(400-1400)
- 6x schedule (72 epochs)
- soft- NMS
ImageNet-22K pre-trained
DETR: End-to-End Object Detection with Transformers
第一次看时有些技术细节不太理解,重新梳理一下:
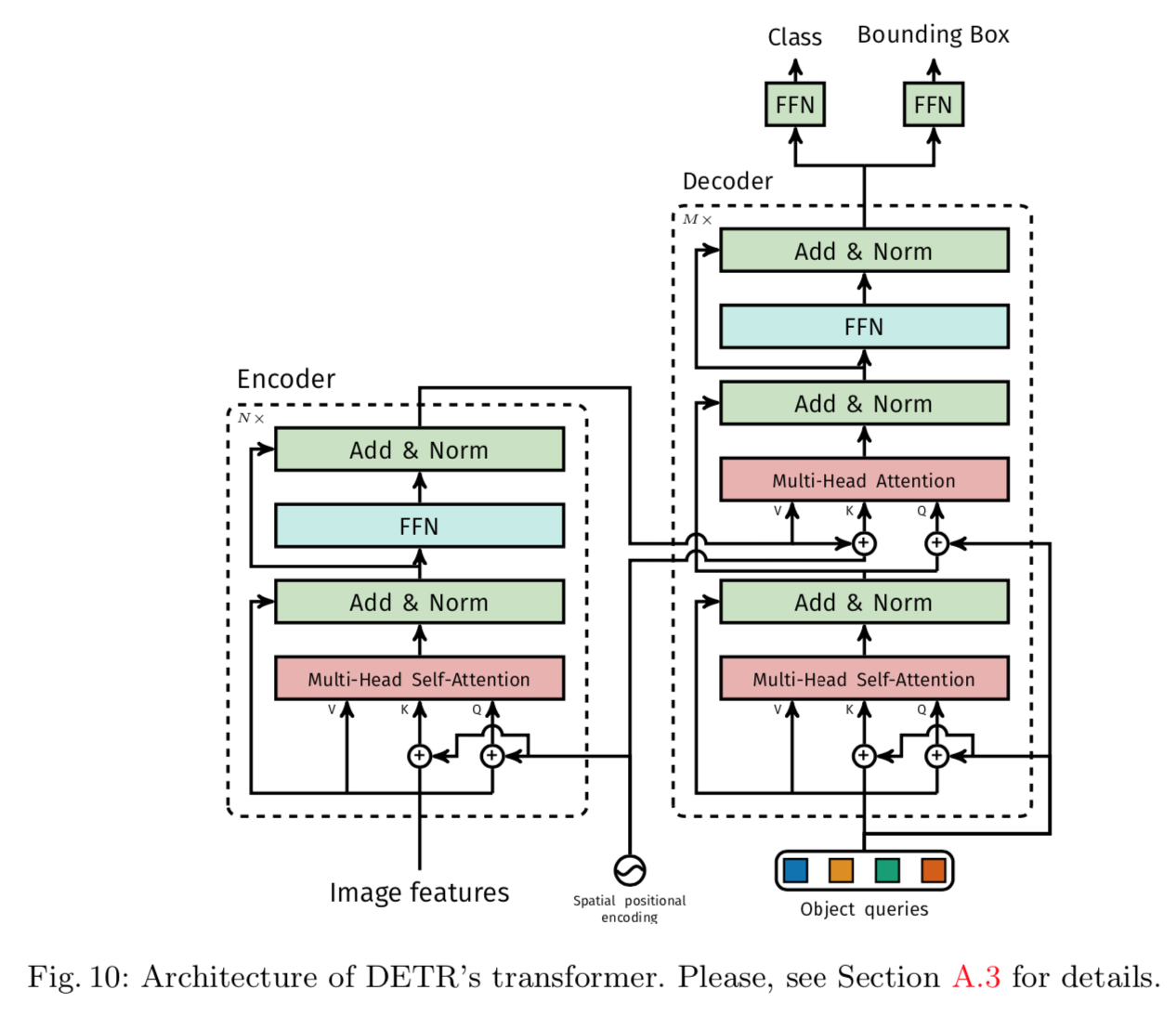
encoder
- feature inputs:
- 用了resnet最后一个阶段的输出,(H0/32,W0/32,C),C=2048
- 然后用1x1 conv降维,(H,W,d),作为attention layer的输入
- 没有batch dim,one image per GPU,外加DDP
- DC:distillation conv
- fixed PE:
- 给每一层attention layer的输入query和key都加了fixed PE
- 注意是QK不是QKV
- 论文的示例代码为了简洁用了learnt PE,而且只加在input层
- feature inputs:
decoder
- object queries:全0初始化,100是建议长度,补充材料里面有个实验,图像包含40以下目标时候基本不会漏检,再往上就开始漏检了
- learnt PE
prediction heads
首先做bipartite matching
将pred box和gt box一一对应,没配上的pred box与no object对齐
matching loss:寻找到最优的pred box排列,使得matching cost最小,优化算法是Hungarian algorithm,matching cost也可以理解为匹配质量
第一项是匹配上的某个box,它的预测概率,越大说明越confident,匹配质量越好
第二项是匹配上的某个box,它与gtbox的box loss,越大匹配质量越不好
然后计算detection loss
- cls loss:CE
- box loss:L1 + GIoU
DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION
动机
- DETR的痛点
- slow convergence
- limited feature spatial resolution:小目标往往需要放大输入resolution才能检出,但是transformer负担不起high-resolution计算
- 处理attention module的计算限制
- only attend to a small set of key sampling points
- 那应该类似两阶段?先选格子,再fine-regress
- performace
- better than DETR
- 10x less training epochs
- 两阶段架构上,用作RPN,performance有进一步提升
- DETR的痛点
论点
Modern object detectors:not fully end-to-end
- anchor
- training target assignment
NMS
都是hand-crafted components,引入了超参的
DETR:fully end-to-end
- 直接回归box,结构极简
- 但是有痛点
- high-resolution
- slow convergence:attention weights需要很久才能focus到sparse object上
deformable convolution
- a powerful and efficient mech- anism to attend to sparse spatial locations
- while lacks the element relation modeling mechanism
we propose Deformable DETR
combines the best of deformable conv and Transformers
- deformable conv:sparse spatial sampling
- Transformers:relation modeling capability
deformable attention module
- 替换原始的Transformer attention modules
- 不是在all featuremap pixels上做计算,而是先pre-filter一部分locations
- 可以extended to multi-scale:naturally aggregate,无需特征金字塔
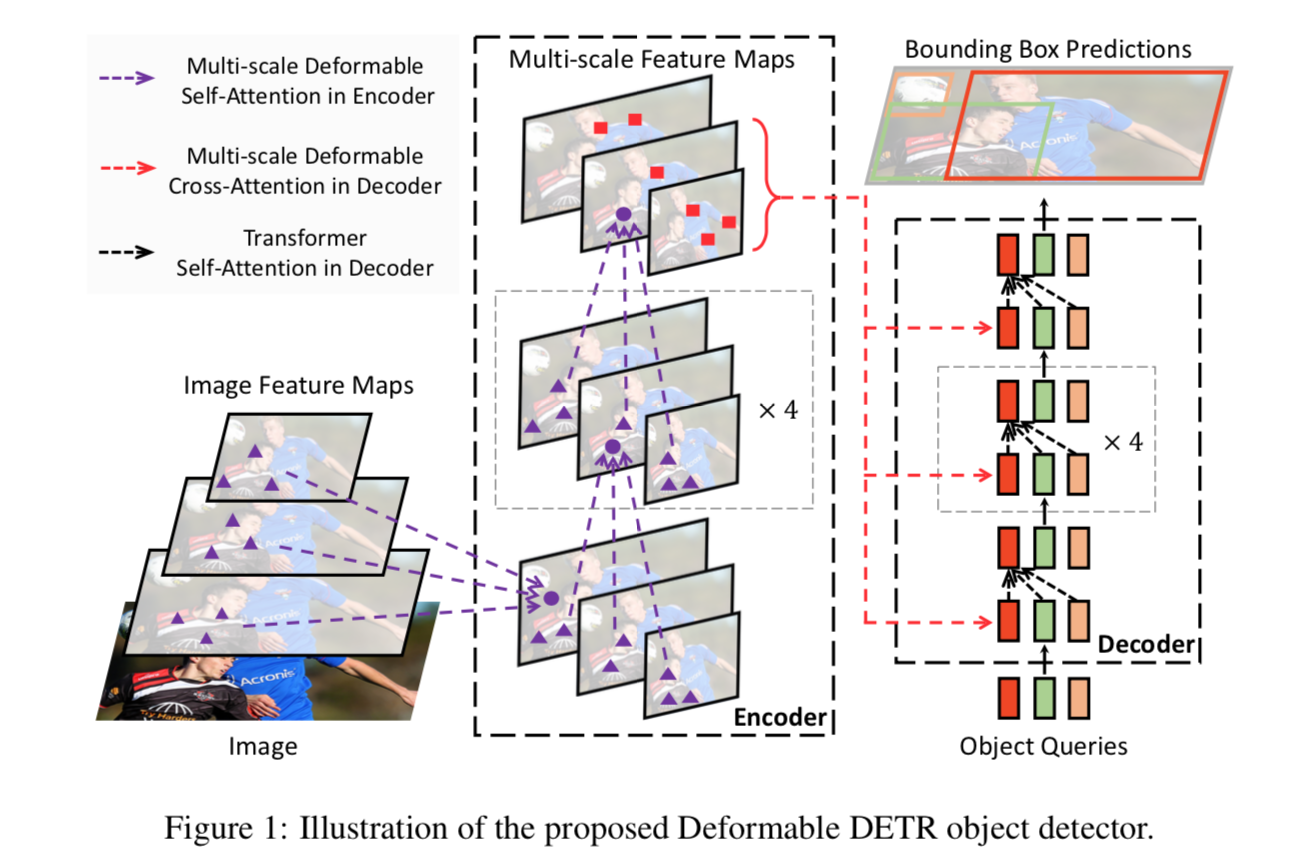
核心技术回顾
Multi-Head Attention in Transformers
- given Q,K,V
- attention values:$Softmax(\frac{QK^T}{\sqrt d}) V$
- multi-head:concat + dense
- 计算量随着feature map的size的二次方增长
DETR
- given CNN feature maps
- 用一个encoer-decoder的结构,将feature maps转化成a set of object queries
- encoder是self-attention:Q和K都是feature map pixels
decoder是cross-attention + self-attention:
- cross的query来自decoder的额外输入——N object queries represented by learnable positional embeddings,key来自encoder
- self的query和key都是decoder的额外输入——object queries
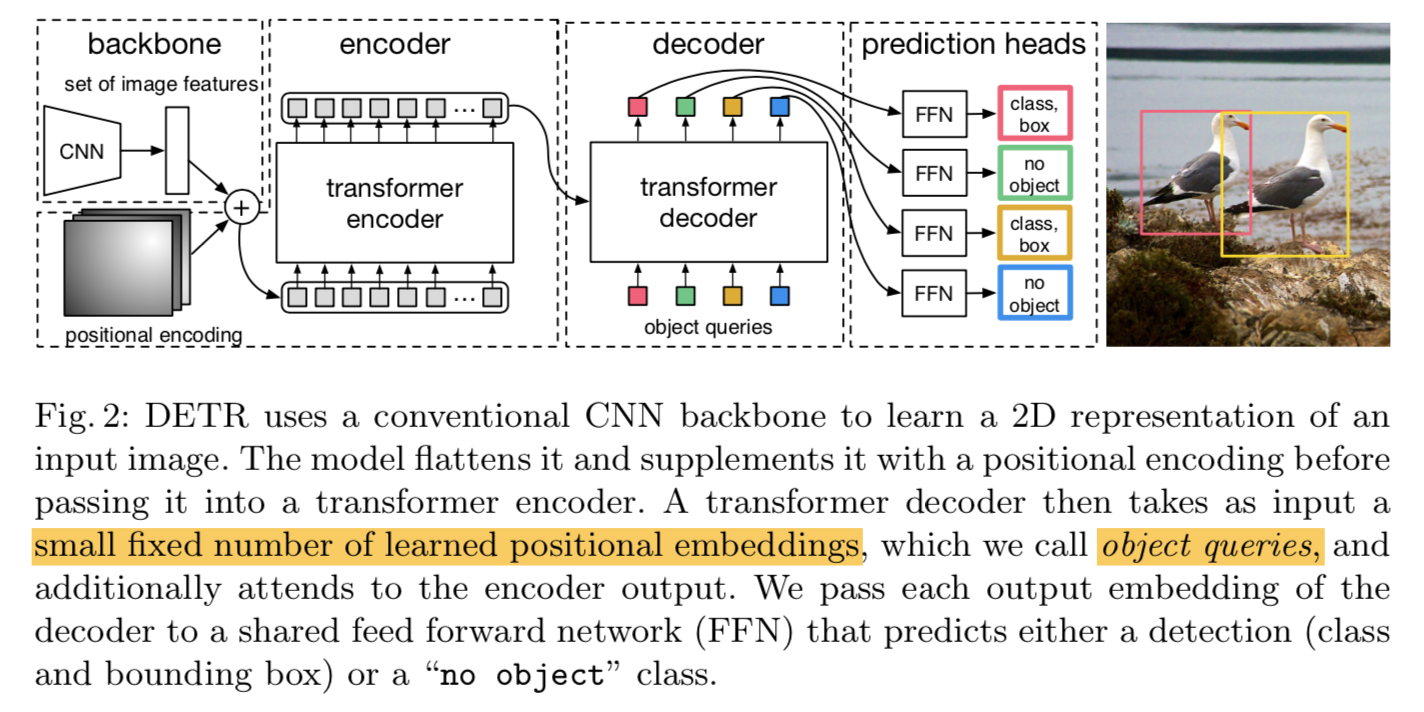
方法
Deformable Attention Module
Transformer的attention layer的计算量和feature map的size正相关
Deformable attention的一个点,只和周围一个固定pattern上的点计算relationship,控制了计算量
assign only a small fixed number of keys for each query
公式
- given:input $x\in R^{C\times H\times W}$,2d point $p_q$,query feature $z_q$
- $m$ indexes the attention head
- $k$ indexes the sampled keys
- $K$ is the total sampled key number:远小于HW
- $A_{mqk}$和$\Delta p_{mqk}$是每个head的attention weights & sampling offsets,是从输入feature经过一个线性层得到的
- 前者还加了一个softmax,normed into [0,1]
- 后者是feature level的绝对距离,范围无界
- $W_m^{‘}x_q$是query values
- $x(p_q + \Delta_p{mqk})$用了bilinear interpolation
Multi-scale Deformable Attention Module
将坐标$p_q$转换成normalized形式$\hat p_q$,输入一组不同scale的inputs feature map,将不同scale上这个点的weighted query加在一起就好了
公式
- $A_{mlqk}$ is normalized by $\sum_{l=1}^L \sum_{k=1}^K A_{mlqk}=1$:attention weights的softmax是在所有level feature的sampled points上的,也就是LK个points
- $\phi(\hat p_q)$将normed coords转换到对应feature level

Deformable Transformer Encoder
C3-C6,L=4,channel=256
- 用Resnet stage3到stage5的featuremap接一个1x1conv,作为multi-scale feature maps
C5的output再接一下3x3 s2 conv得到C6
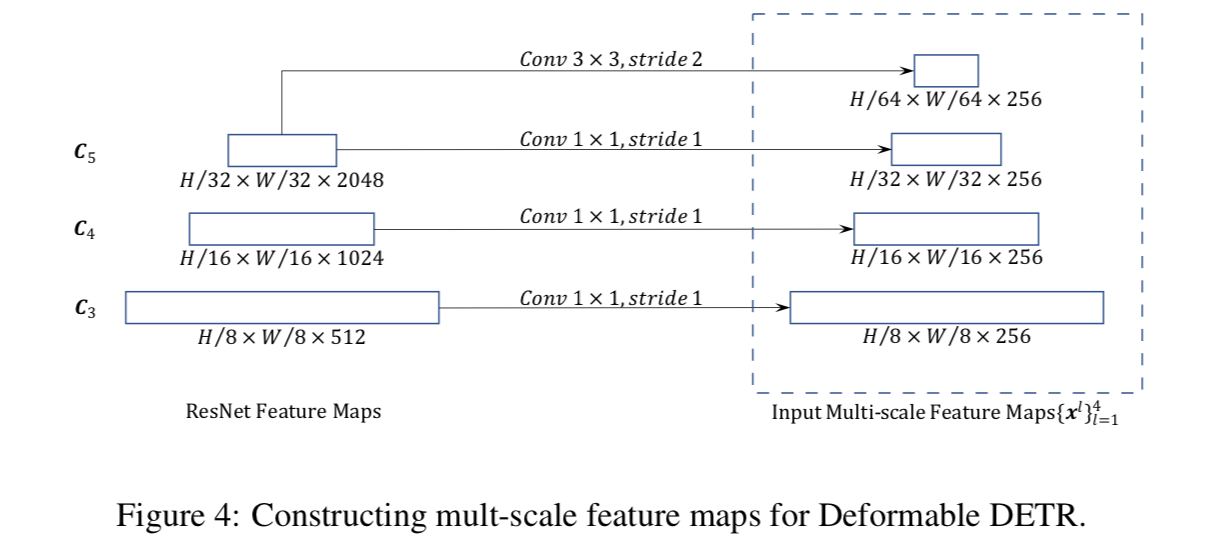
堆叠Multi-scale Deformable Attention Module
- module的输入和输出都是same resolution的feature maps
- add a scale-level embedding $e_l$:用来指示输入的query pixel来自哪个scale level,但是它是随机初始化的,然后随着网络训练【???】
- query是pixels,reference points就是它自身:代码里是query embed + fc来实现
Deformable Transformer Decoder
- cross-attention
- query是object queries
- key是encoder的输出
- object queries are extracting features from the feature maps
- self-attention
- query和key都是object queries
- object queries interact with each other
- 这里仅给cross-attention module用了Multi-scale Deformable Attention Module,因为decoder的self-att的key不是feature maps了
- cross-attention
query的reference points is predicted from its object query embedding:fc + sigmoid,也作为box center的initial guess
detection head预测的是reference point的偏移量
Anchor DETR: Query Design for Transformer-Based Object Detection
动机
- previous DETRs
- decoder输入的object queries是一系列learned embeddings
- do not have explicit physical meanings
- difficult to optimize
- we propose Anchor DETR
- a novel query design based on anchors:enable ‘one region multiple objects’
- an attention variant:reduce memory
- better performance and fewer training epochs
- verified on
- MSCOCO
- ResNet50-DC5 feature,44.2 AP with 19 FPS
- previous DETRs
论点
Visualization of the prediction slots
a图是DETR的prediction boxes的中心点,绿-红-蓝表示box由小到大,可以看到绿box分布在全图,红蓝则集中在中心,其实类似枚举,没有什么物理意义
b图是Anchor DETR的prediction slots,黑点是anchor points,可以看到box的中心点都分布在anchor附近
- 说明本文方法are more related to a specific position than DETR

回看CNN
- anchors are highly related to position
- contain interpretable physical meanings
we propose this novel query design
- 首先用anchor coordinates去编码query
- 其次针对一个位置多个目标的情况:adding multiple patterns to each anchor point
- CNN是highly anchor-driven,位置和尺寸都包含了,DETR是完全放飞,随意初始化,本文方法在中间,用了anchor position,但是没有scale
- 这样还是保证网络预测的格子都在anchor附近:easier to optimize
we also propose an attention variant that we call Row-Column Decouple Attention (RCDA)
- 行列解耦:2D key feature decouple into 1D row and 1D column
- 串行执行row attention & column attention
reduce memory cost
similar or better performance
- 这个其实可以理解的,MSA的global attention太dense computation了,所以才会出现Swin那种WMSA去分块,deformable DETR那种先filter出attention区域,包括本文的解耦,都是在尝试稀疏化
方法
anchor points
CNN detector里面anchor points永远对应着feature grids
但是在transformer里面,这个点可以更flexible,可以是learned points sequence
本文两种都尝试了
- fixed anchor points就是grid coordinates
learned anchors就是random uniform初始化,然后加入learned layers,最后输出的learned coordinates
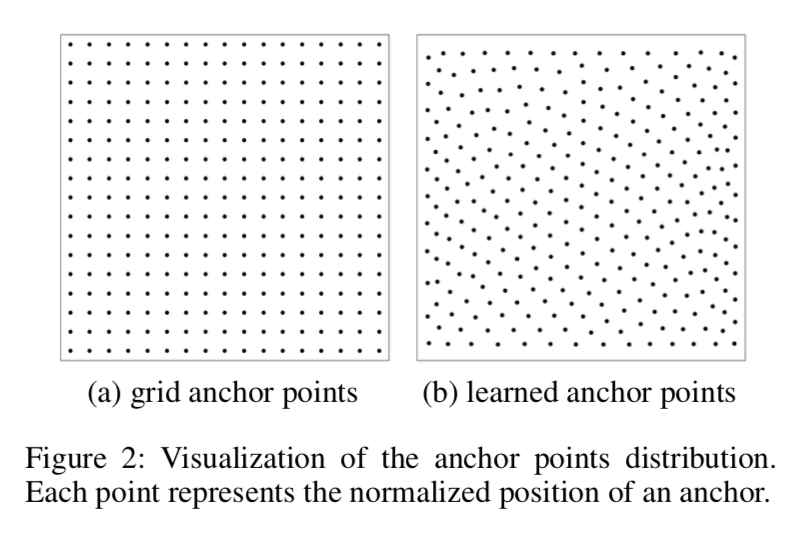
最终的网络预测都加在这个anchor coordinates上,也就是网络又变成预测偏移量了
attention formulation:the DETR-like attention
也就是最原始的transformer里面的MSA,QKV首先各自过一层linear layer,然后如下计算:
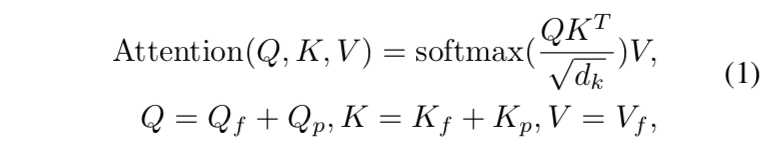
下标f是feature,下标p是position
- decoder里面有两种attention:self-attention和cross-attention
- self-attention里面$Q_f,K_f, V_f$是一样的,来自前面的输出,$Q_p, K_p$是一样的,来自learned positional embedding
- decoder的第一个query输入$Q^{init}_f \in R^{N_q \times D}$可以是一个常量/一个learned embedding
- cross-attention里面Q的来源不变,但是KV变成了encoder的输出,$K_p$是sine-cosine positional embedding,是个常量
anchor points to object query
- 原始的DETR用learned positional embedding作为object query,用来distinguishing different objects,缺少可解释性
- we use anchor points $Pos_q \in R^{N_A \times 2}$
- $N_A$个点坐标
- 2是xy-dim,range 0-1
- encode as the object queries $Q_p$
- we use a small MLP with 2 linear layers
- $Q_p = Encode(Pos_q) \in R^{N_A \times D}$
multiple objects issue
- one position may have multiple objects
- 回想原始的object query,是用embedding生成的$Q_f^{init}$,每个$Q_f^i \in R^D$相当于一个pattern,用来代表当前位置/index
- 如果给到多个pattern给一个object query:
- use a small set pattern embedding $Q_f^i \in R^{N_p \times D}$
- 用embedding来生成:$Q_f^i = Embedding(N_p, D)$
- 相当于to detect objects with different patterns at each position
- $N_p=3$,类似scale
- overall的object queries就是$Q_f \in R^{N_pN_A \times D}$
- positional embeddings则是$Q_p \in R^{N_pN_A \times D}$,它的Np是复制过来的(3个pattern的PE相同)
Row-Column Decoupled Attention (RCDA)
- memory issue,限制了resolution
- decouple the key feature $K_f \in R^{H \times W \times D}$ to the row feature $K_{fx} \in R^{ W \times D}$ and column feature $K_{fy} \in R^{H \times D}$:通过1D global average pooling
then perform row attention and column attention successively
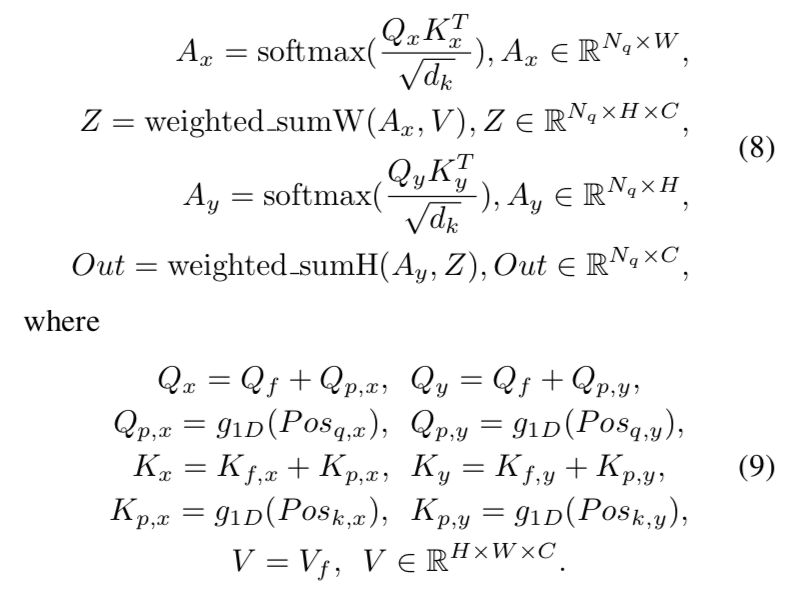
$g_{1D}$是1D的position encoding function:learned MLP for Q & sin-cos for K
之前的计算量:(Nq)*(HW)
- 现在的计算量:(Nq)*(H+W)
overall pipeline
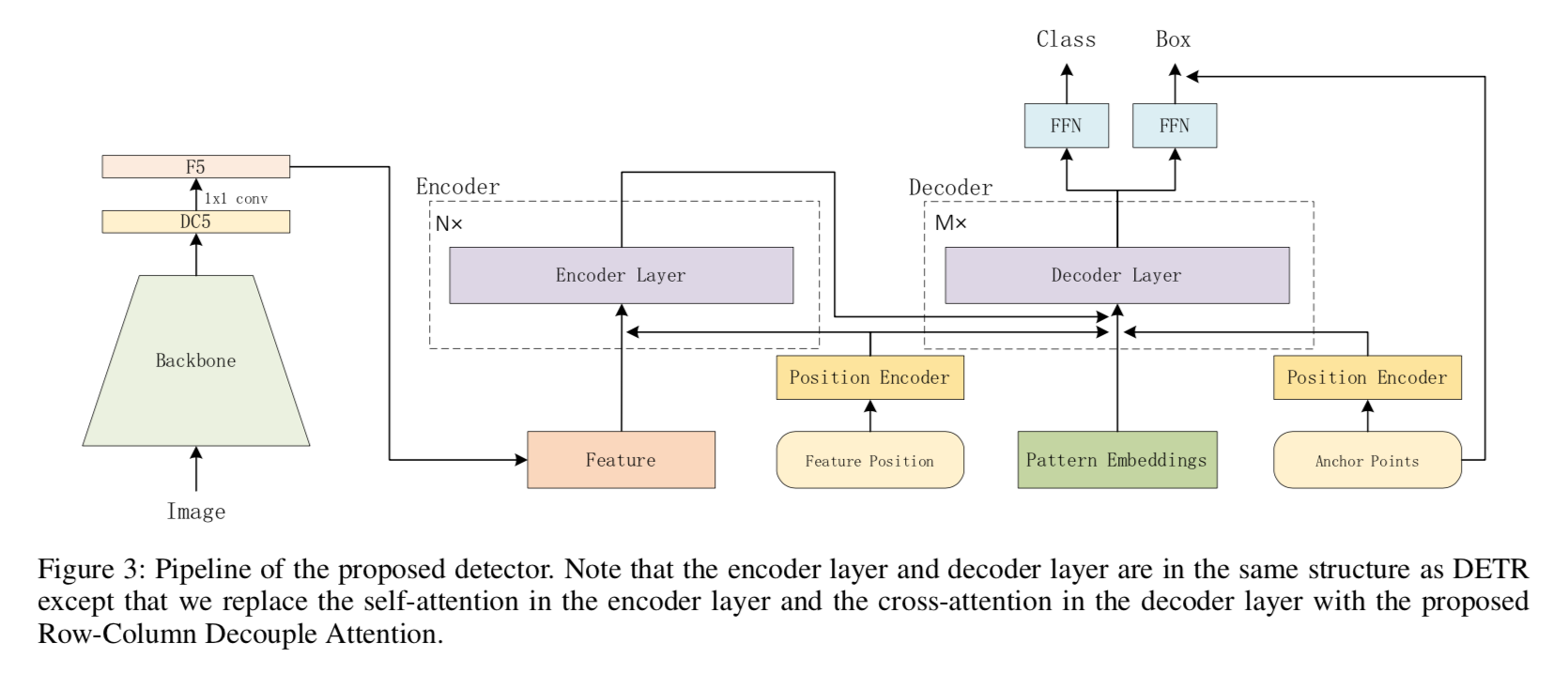
- 宏观结构跟DETR一毛一样
- 但就是encoder/decoder内部的attention module变成了RCDA
- 然后就是pattern embeddings从Embedding(100,256)变成了Embedding(Np,D),用(Na,D)的anchor grids一广播就变成了(NpNa,D)的query inputs
实验
- settings