- papers
[swin] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows:微软,multi-level features,window-based
[swin V2] Swin Transformer V2: Scaling Up Capacity and Resolution:卷死了卷死了,同年就上V2,
[PVT 2021] Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions,商汤,也是金字塔形结构,引入reduction ratio来降低computation cost
[Twins 2021] Twins: Revisiting the Design of Spatial Attention in Vision Transformers,美团
[MiT 2021] SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers,是一篇语义分割的paper里面,提出了a family of Mix Transformer encoders (MiT),based on PVT,引入reduction ratio对K降维,起到计算量线性增长的效果
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
- swin V1的paper note在:https://amberzzzz.github.io/2021/01/18/transformers/,我们简单look back:
- input embedding:absolute PE 替换成 relative PE
- basic stage
- basic swin block:W-MSA & SW-MSA
- patch merging
- classification head
a quick look back on MSA layer:
- scaled dot-Product attention
- dot:计算每个query和所有keys的similarity,$QK^T$
- scaled:归一化dot-product的结果,用$\sqrt {d_k}$做分母,$\frac{QK^T}{\sqrt {d_k}}$
- weighted sum
- softmax:计算query和所有keys的weights,$softmax(\frac{QK^T}{\sqrt {d_k}})$
- sum:计算query在所有values上的加权和,作为其全局representation,$softmax(\frac{QK^T}{\sqrt {d_k}})V$
- multi-head attention
- linear project:将输入QKV投影成h个D/h-dim的sub-QKV-pairs
- attention in parallel:并行对每组sub-QKV计算sub-Q的global attention
- concat:concat这些heads的输出,也就是所有query的global attention
- linear project:增加表征复杂度
- masking
- used in decoder inputs
- decoder inputs query只计算它之前出现的keys的attention:将其之后的similarity value置为-inf,这样weights就无限接近0了
- 3类regularization:
- Residual dropout:在每个residual path上面都增加了residual dropout
- PE dropout:在输入的PE embedding之后添加dropout
- adds dropout:在每个residual block的sums之后添加dropout
- $P_{drop}=0.1$
- scaled dot-Product attention
training details
pretraning:
- AdamW:weight decay=0.01
- learning rate:linear decay,5-epoch warm-up,initial=0.001
- batch size:4096
- epochs:60
- an increasing degree of stochastic depth:0.2、0.3、0.5 for Swin-T, Swin-S, and Swin-B
finetuning:
- on larger resolution
- batch size:1024
- epochs:30
- a constant learning rate of 1e−5
- a weight decay of 1e−8
- the stochastic depth ratio to 0.1
weights transfer
- different resolution:swin是window-based的,resolution的改变不直接影响权重
- different window size:relative position bias需要插值到对应的window size,bi-cubic
Swin Transformer V2: Scaling Up Capacity and Resolution
动机
- scaling up:
- capacity and resolution
- generally applicable for vision models
- facing issues
- instability
- low resolution pre-trained models到high-resolution downstream task的有效transfer
- GPU memory consumption
- we present techniques
- a post normalization technique:instability
- a scaled cosine attention approach:instability
- a log-spaced continuous position bias:transfer
- implementation details that lead to significant GPU savings
- scaling up:
论点
大模型有用这个事在NLP领域已经被充分证实了:Bert/GPT都是pretrained huge model + downsteam few-shot finetuning、
CV领域的scaling up稍微lagging behind一点:而且existing model只是用于image classification tasks
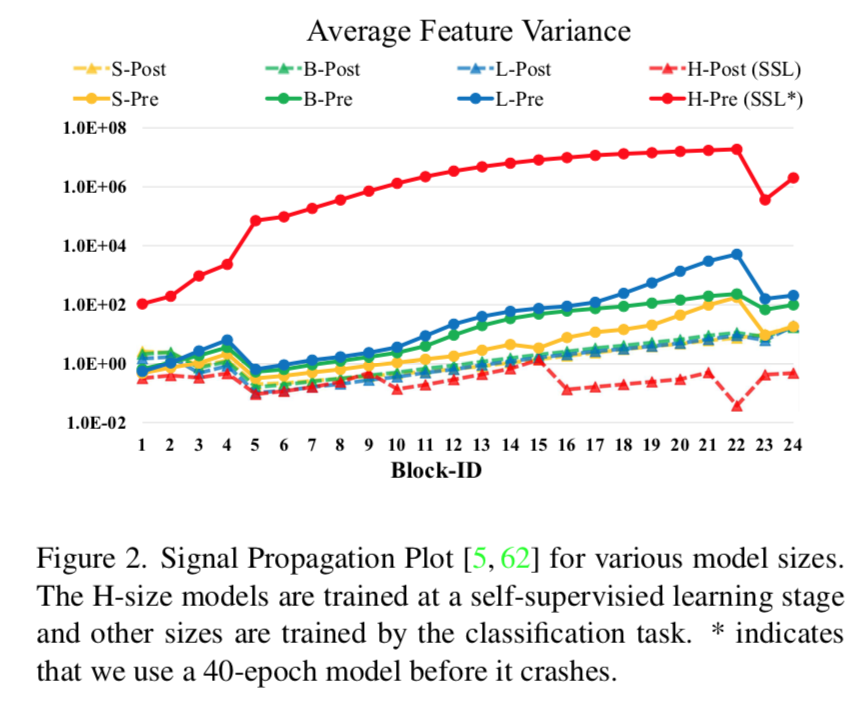
instability
- 大模型不稳定的主要原因是residual path上面的value直接add to the main branch,the amplitudes accumulate
- 提出post-norm,将LN移动到residual unit后面,限幅
- 提出scaled cosine attention,替换原来的dot product attention,好处是cosine product是与amplitude无关的
看图:三角是norm后置,圆形是norm前置
transfer
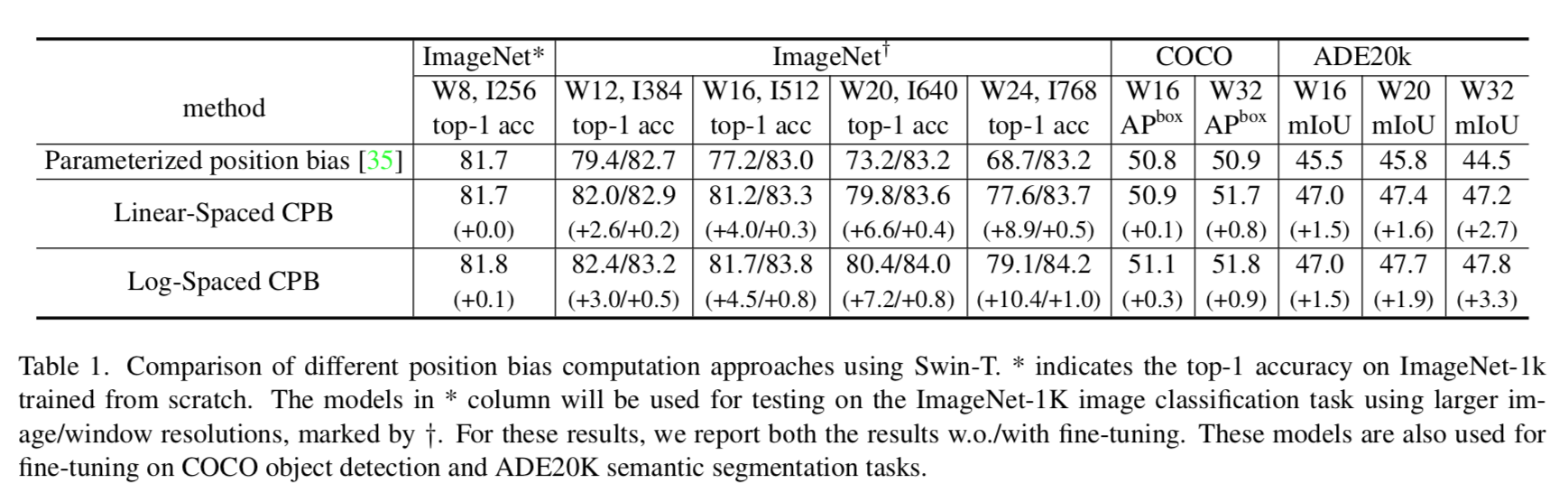
- 提出log-spaced continous position bias (Log-CPB)
- 之前是bi-cubic interpolation of the position bias maps
看图:第一行是swin V1的差值,transfer到别的window size会显著drop,下面两个CPB一个维持,一个enhance
GPU usage
- zero optimizer
- activation check pointing
- a novel implementation of sequential self-attention computation
our model
- 3 billion params
- 1536x1536 resolution
- Nvidia A100-40G GPUs
- 用更少的数据finetuning就能在downstream task上获得更好的表现
方法
overview
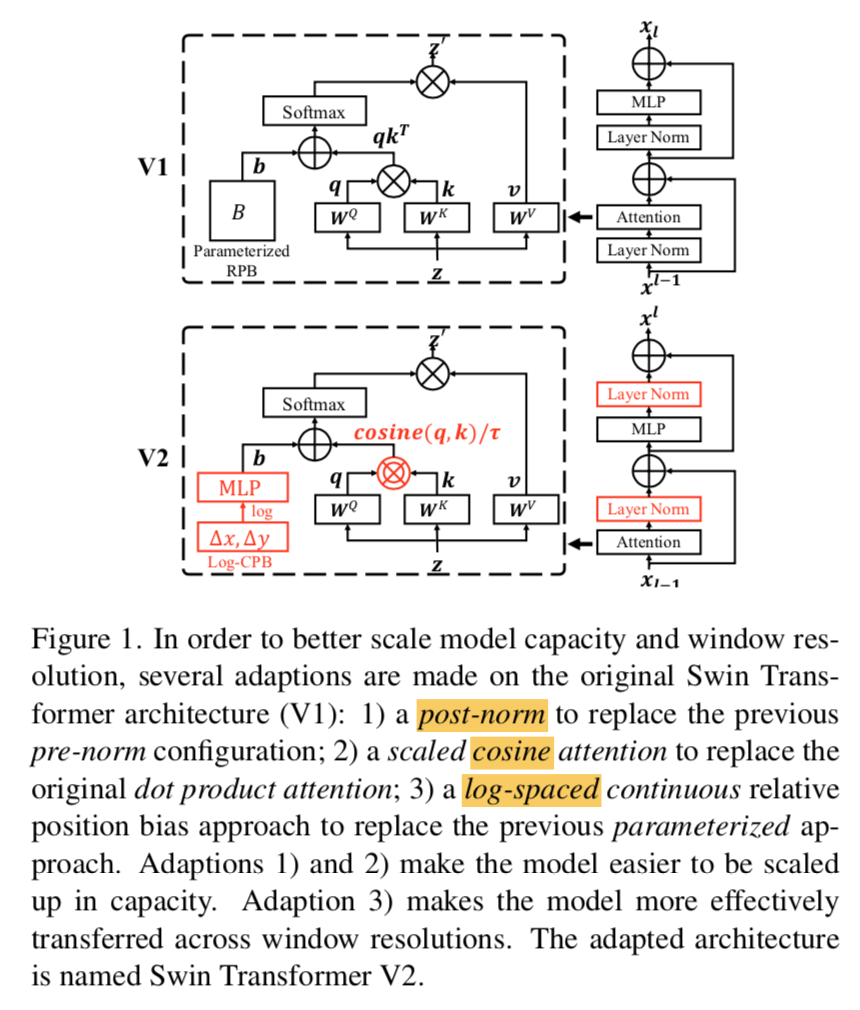
normalization configuration
- common language Transformers和vanilla ViT都是前置norm layer
- 所以swin V1就inherit这个设置了
- 但是swin V2重新安排了
relative position bias
- key component in V1
- 没有用PE,而是在MSA里面引入了bias term:$Attention(Q,K,V)=Softmax(QK^T/\sqrt d + B)V$
- 记一个window里面patches的个数是$M^2$,那么$B \in R^{M^2}$,两个轴上的相对位置范围都是[-M+1,M-1),有bias matrix $\hat B \in R^{(2M-1)\times(2M-1)}$,然后从中得到$B$,源代码实现的时候用了一个truncated_normal来随机生成$\hat B$,然后在$\hat B$里面取$B$
- windows size发生变化的时候,bias matrix就进行bi-cubic插值变换
Scaling Up Model Capacity
在 pre-normalization的设置下
- the output activation values of each residual block are directly merged back to the main branch
- main branch在deeper layer的amplitude就越来越大
- 导致训练不稳定
Post normalization
- 就是MSA、MLP和layerNorm的顺序调换
- 在largest model training的时候,在main branch也引入了layerNorm,每6个Transformer block就引入一个norm unit
Scaled cosine attention
- 原始的similarity term是Q.dot(K)
- 但是在post-norm下,发现the learnt attention map容易被个别几对pixel pairs主导
- 所以改成cosine:$Sim(q_i,k_i)=cos(q_i,k_i)/\tau + B_{ij}$
- $\tau$ 是learnable scalar
- larger than 0.01
- non-shared across heads & layers
Scaling Up Window Resolution
Continuous relative position bias
- 用一个小网络来生成relative bias,输入是relative coordinates
2-layer MLP + ReLU in between
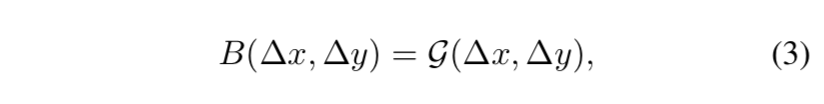
Log-spaced coordinates
将坐标值压缩到log空间之后,插值的时候,插值空间要小得多
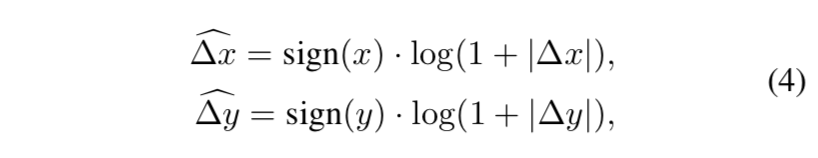
Implementation to save GPU memory
- Zero-Redundancy Optimizer (ZeRO):通常并行情况下,优化器的states是复制多份在每个GPU上的,对大模型极其不友好,解决方案是divided and distributed to multiple GPUs
- Activation check-pointing:没展开说,就说high resolution下,feature map的存储也占了很大memory,用这个可以提高train speed 30%
- Sequential self-attention computation:串行计算self-attention,不是batch computation,这个底层矩阵效率优化不理解
Joining with a self-supervised approach
- 大模型需要海量数据驱动
- 一个是扩充imageNet数据集到五倍大,using noisy labels
- 还进行了自监督学习:additionally employ a self-supervised learning approach to better exploit this data:《Simmim: A simple framework for masked image modeling》,这个还没看过