之前那篇《transformers》太长了,新开一个分割方向的专题,papers:
——————————previous—————————-
[SETR] Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers,复旦,水,感觉就是把FCN的back换成transformer
[UNETR 2021] UNETR: Transformers for 3D Medical Image Segmentation,英伟达,直接使用transformer encoder做unet encoder
[TransUNet 2021] TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation,encoder stream里面加transformer block
[TransFuse 2021] TransFuse: Fusing Transformers and CNNs for Medical Image Segmentation,大学,CNN feature和Transformer feature进行bifusion
———————————-new———————————-
- [Swin-Unet 2021] Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation,TUM,2D的Unet-like pure transformer,用swin做encoder,和与其对称的decoder
- [nnFormer 2021] nnFormer: Interleaved Transformer for Volumetric Segmentation,港大,对标nn-Unet,3D版本的Swin-Unet,完全就是照着上一篇写的
- [UPerNet 2018] Unified Perceptual Parsing for Scene Understanding,PKU&字节,Swin Segmentaion的补充材料,Swin的down-stream task选择用UperNet as base framework
- [SegFormer 2021] SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers,港大&英伟达,参照FCN范式的(CNN+FPN+seg head),设计了swin+MLP decoder的全linear网络,用于分割
Swin Transformer for Semantic Segmentaion
补充Swin paper附录里面关于分割的描述:
- dataset:
- ADE20K:semantic segmentation
- 150 categories
- 25K/20K/2K/3K for total/train/val/test
- UperNet as base framework
- benchmark:https://paperswithcode.com/sota/semantic-segmentation-on-ade20k?p=swin-transformer-hierarchical-vision
nnFormer: Interleaved Transformer for Volumetric Segmentation
动机
- 用transformer的ability to exploit long-term dependencies,去弥补卷积神经网络先天的spatial inductive bias
- recently transformer-based approaches
- 将transformer作为一个辅助模块,用于编码global context
- 没有将transformer最核心的,self-attention,有效的整合进CNN
- nnFormer:not-another transFormer
- volume-based self-attention,极大降低计算量
- 打败了Swin-Unet和nnUnet
论点
Transformers
- self-attention
- capture long-range dependencies
- give predictions more consisitent with humans
previous approaches
- TransUNet:Unet结构类似,CNN提取特征,再接一个transformer辅助编码全局信息,但是一两层的transformer layer并不足以提取到这种长距离约束
- Swin-UNet:有了appropriate的下采样方法,transformer能够学习hierarchical object concepts at different scales,但它是一个纯transformer的结构,用hierarchical的transformer block构造encoder和decoder,整体也是Unet结构,没有探索如何将卷积和self-attention有机结合
nnFormer contributions
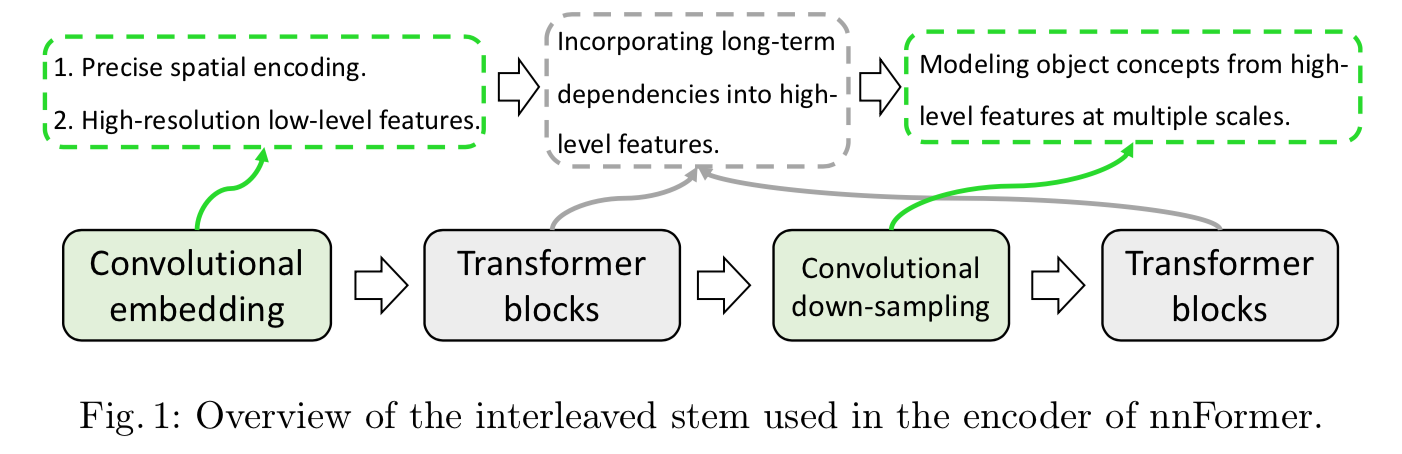
hybrid stem:卷积和self-attention都用上了,并且都能充分发挥能力,他的encoder:
- 首先是一个轻量的conv embedding layer,好处是卷积能够提供更precise的spatial information,
然后是交替的transformer blocks和convolutional down-sampling blocks,capture long-term dependencies at various scales
V-MSA:volume-based multi-head self-attention
- a computational-efficient way to capture inter-slice dependencies
- 计算复杂度降低90%以上
- 应该就是类似于swin那种inter-patch & inter-patch吧?
方法
overview
U-net结构:
- embedding block + encoder + decoder + patch expanding block
- 三次下采样 & 三次上采样
- long residual connections
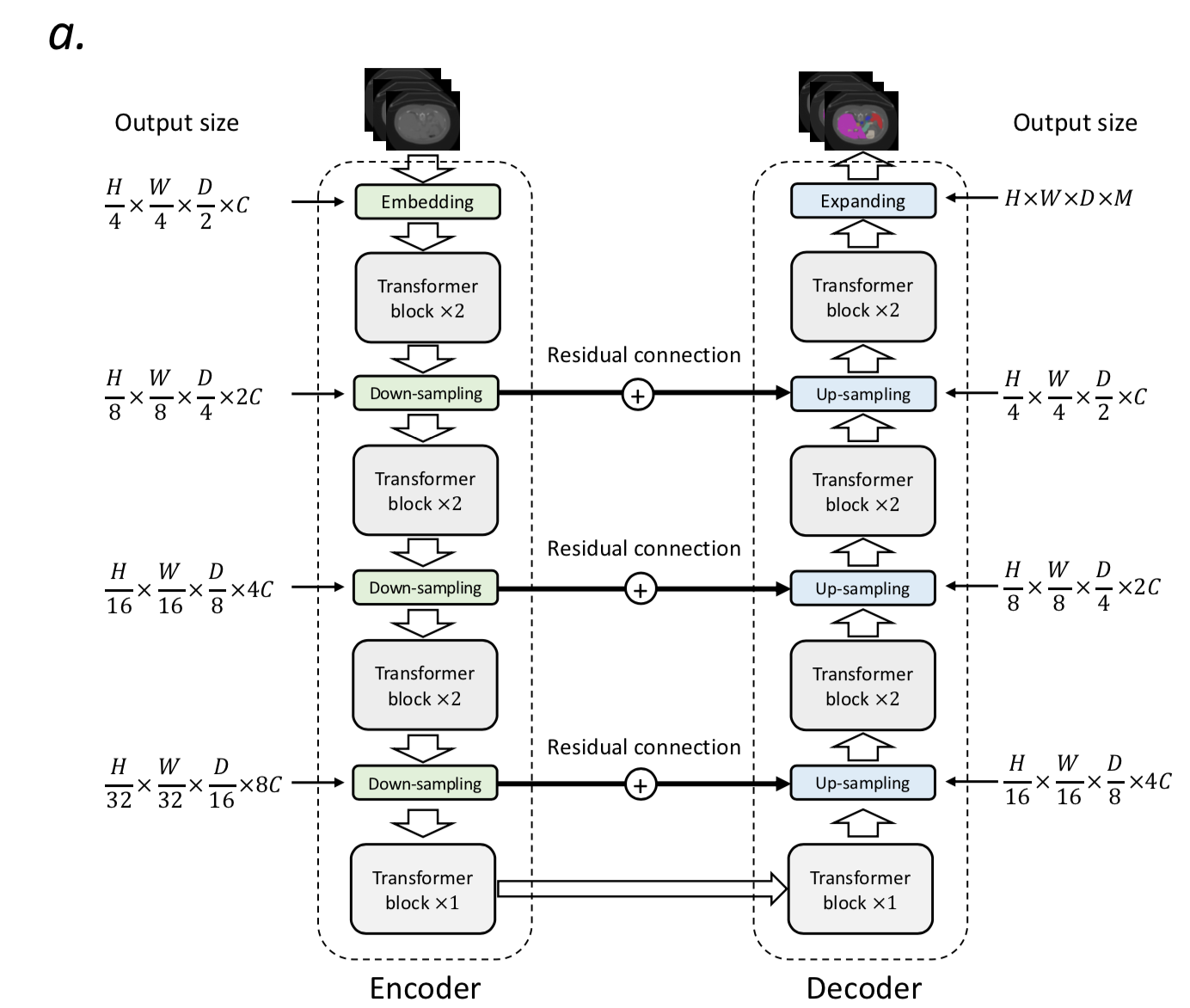
encoder
input:3D patch $X \in R^{H \times W \times D}$
embedding block
- 将3D patch转化成patch tokens,$X_e \in R^{\frac{H}{4}\frac{W}{4}\frac{D}{2}C}$,代表的是high-resolution spatial information
- $\frac{H}{4}\frac{W}{4}\frac{D}{2}$是token个数
- C是tensor channel,192/96
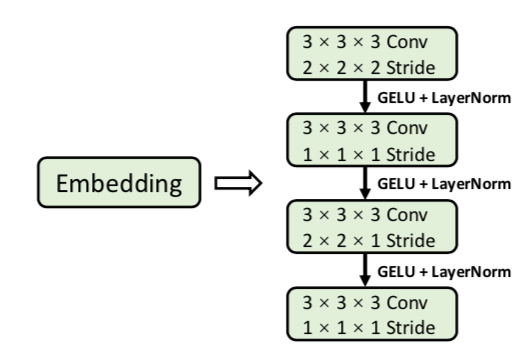
- 4个连续的kernel3x3的卷积层替代Swin里面的big kernel:小卷积核给出的解释是计算量&感受野,没什么特别的,用卷积embedding给出的解释是pixel-level编码局部spatial信息,more precisely
前三层卷积后面+GELU+LN,stride在1、3层,如图
transformer block
hierarchical
compute self-attention within 3D local volumes (instead of 2D local windows)
input:tokens representation of 3D patch, $X_t \in R^{L \times C}$
首先reshape:对token sequence,再次划分local volume,$\tilde X_t \in R^{N_V \times N_T \times C}$
- local volume里面包含一组空间相邻的tokens
- $N_V$是volume的数目(类似Swin里面window的数目)
- $N_T=S_H \times S_W \times S_D$ 是每个local volumes里面token的个数,{4,4,4}/{5,5,3}
然后跟Swin一样,两个连续的transformer blocks,3D windows instead of 2D
- V-MSA:volume-based multi-head self-attention
SV-MSA:shifted version

反正就是3D版的swin,回去看swin更清晰
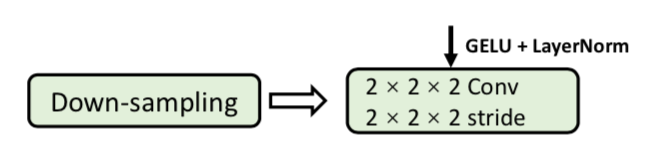
down-sampling block
就是strided conv,说是相比较于neighboring concatenation,能产生更hierarchical的representation,有助于learn at multi scales
decoder
- 和encoder高度对称
- down-samp对标替换成strided deconvolution
- 然后和encoder之间还有long-range connection,融合semantic和fine-grained information
最后的expanding block也是用了deconv
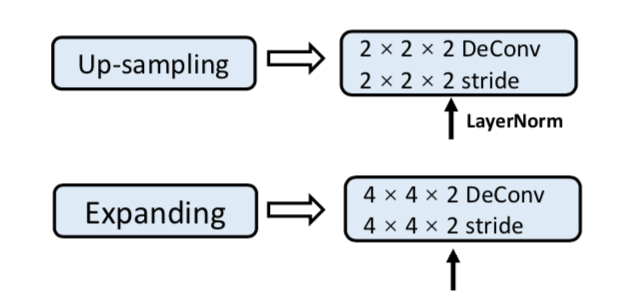
实验
Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
- 动机
- Unet-like pure Transformer
- 用Swin transformer做encoder
- 对称的decoder,用patch expanding layer做上采样
- outperforms full-convolution / combined methods
- Unet-like pure Transformer
论点
- CNN的局限性
- 提取explicit global & long-range information
- meanwhile Swin在各项任务上SOTA了
- Swin-Unet
- the first pure Transformer-based Unet-shaped architecture
- consists of encoder, bottleneck, decoder and skip connections
- token:non-overlapping patches split from the input image
- fed into encoder:得到context features
- fed into decoder:将global features再upsample回input resolution
- patch expanding layer:不用conv/interpolation,实现spatial和feature-dim的increase
- skip connection:对Transformer-based的Unet结构仍旧有效
- CNN的局限性
方法
overview
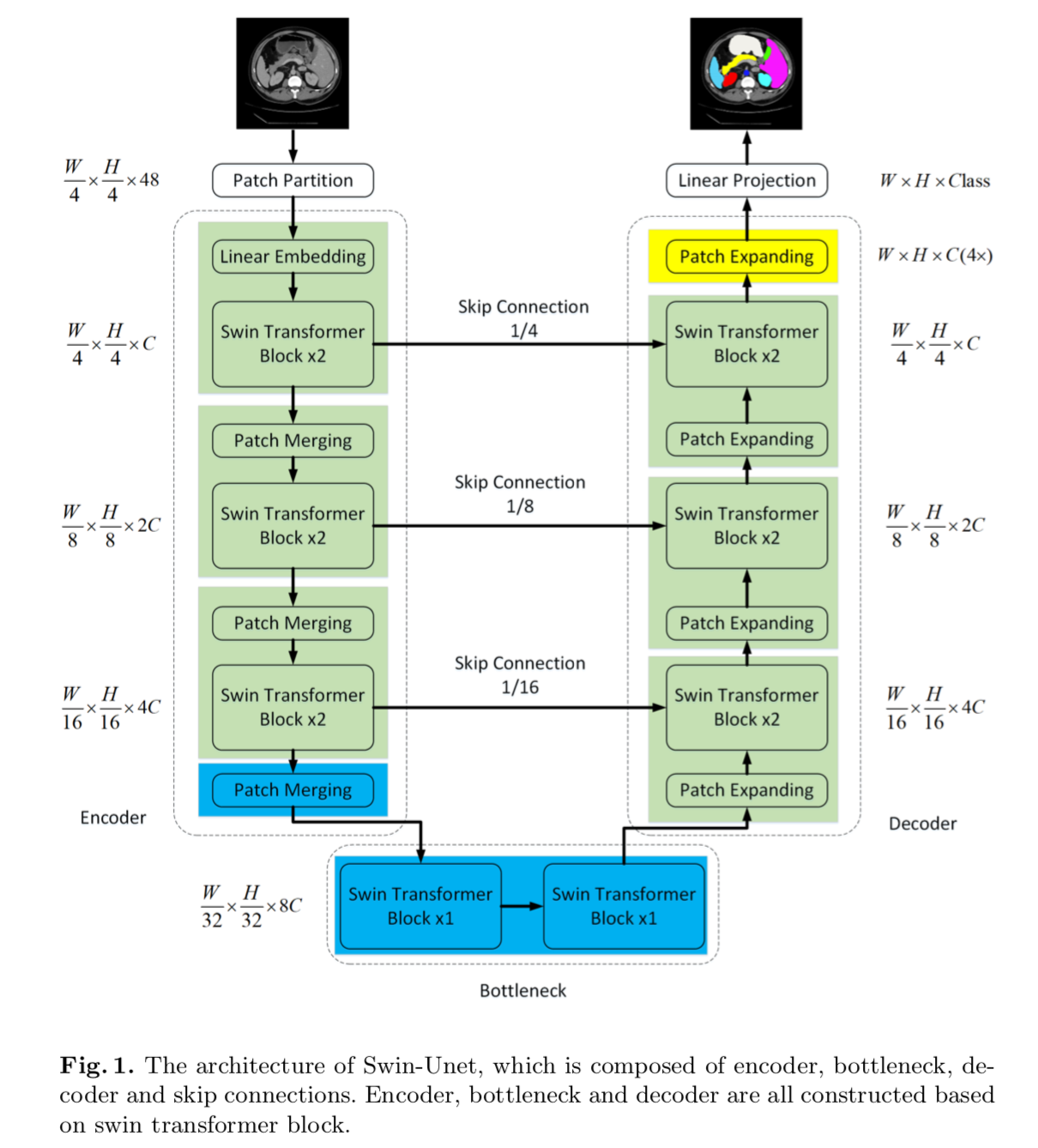
- patch partition
- 将图像切分成不重叠的patches,patch size是4x4
- 每个patch的feature dimension就是4x4x3=48,也就是48-dim vec
- linear embedding
- 将固定的patch dimension映射到任意给定维度C
- 交替的Swin Transformer blocks和Patch Merging
- generate hierarchical feature representations
- Swin Transformer block 是负责学feature representation的
- Patch Merging是负责维度变换(下采样/上采样)的
- 对称的decoder:交替的Swin Transformer blocks和Patch Expanding
- Patch Expanding将相邻特征图拼接起来,组成2x大的特征图,同时减少特征维度
- 最后一个Patch Expanding layer则执行4倍上采样
- patch partition
Swin Transformer block
- based on shifted windows
- 两个连续的Transformer block为一组
- 每个block内部都是LN-MSA-LN-MLP,residual,GELU
- 第一个block的MSA是W-MSA
第二个block的MSA是SW-MSA
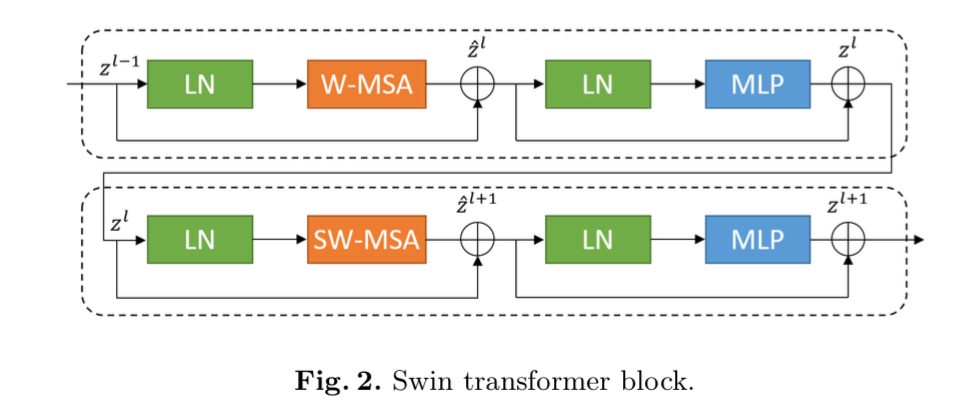
encoder
- input:C-dim tokens,$\frac{H}{4} \times \frac{W}{4}$个tokens
- patch merging layer
- 将patches切分成2x2的4个parts
- 然后将4个part在特征维度上concat
- 然后接一个linear layer,将特征维度的dim转换为2C
- 这样spatial resolution就downsampled by 2x
- 特征维度加倍了2x
bottleneck
- encoder和decoder中间那个部分
- 用了两个连续的Swin transformer block
- 【QUESTION】也是shifited windows的吗?
- 这个part特征维度不变
decoder
- patch expanding layer
- given input features:$(\frac{W}{32} \times \frac{H}{32}\times 8C)$
- 先是一个linear layer,加倍feature dim:$(\frac{W}{32} \times \frac{H}{32}\times 16C)$
- 然后合并相邻4个patch tokens:$(\frac{W}{16} \times \frac{H}{16}\times 4C)$
- patch expanding layer
skip connection
- concat以后接一个linear layer,保持特征维度不变
实验
UPerNet: Unified Perceptual Parsing for Scene Understanding
动机
- 人类对于图像的识别是存在多个层次的
- scenes
- objects inside
- compositional parts
- textures and surfaces
- our work
- study a new task caled Unified Perceptual Parsing(UPP):建立了一个“统一感知解析”的任务
- 要求模型recognize as many visual concepts as possible
- propose a multi-task framework UPerNet & a training strategy
- repo:https://github.com/CSAILVision/unifiedparsing
- semantic segmentation
- multi-task
- 人类对于图像的识别是存在多个层次的
论点
- various visual recognition tasks are mostly studied independently
- 过去的task总是将不同level的视觉信息分开研究
- is it possible for a neural network to solve several visual recognition tasks simultaneously?
- thus we propose Unified Perceptual Parsing(UPP)task
- 有两个data issue
- no single dataset annotated with all levels of visual information
- 不同perceptual levels的标注形式也不统一
- thus we propose UPerNet
- overcome the heterogeneity of different datasets
- learns to detect various visual concepts jointly
- 主要实现方式是每个iteration只选取一种数据集,同时只更新相关网络层
- we further propose a training method
- enable the network to predict pixel-wise texture labels using only image-level annotations
- various visual recognition tasks are mostly studied independently
方法
Defining Unified Perceptual Parsing
统一感知解析:从一张图中获取各种维度的视觉信息
- scene labels
- objects
- parts of objects
- materials and textures of objects
datasets
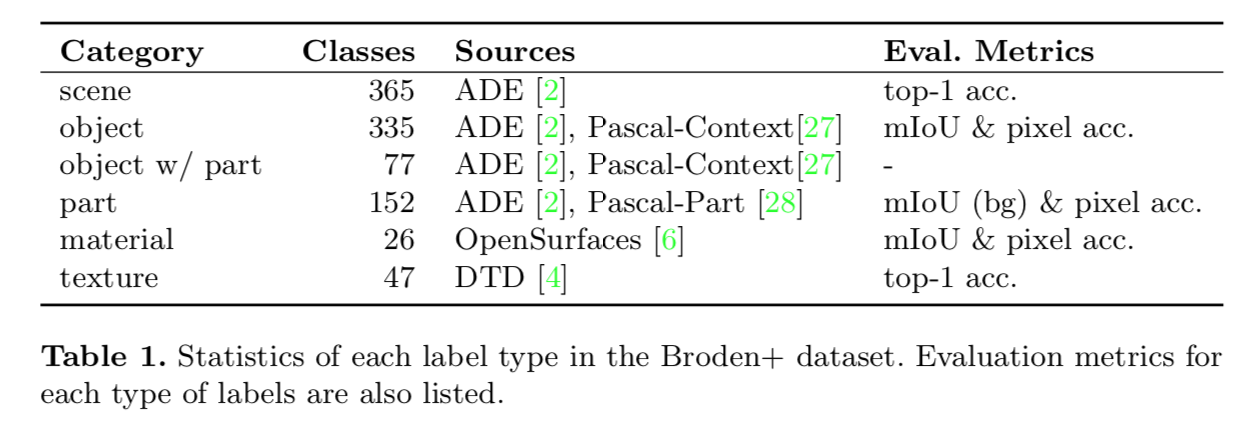
使用了Broadly and Densely Labeled Dataset:整合了好几个数据集,contains various visual concepts
Objects, object parts and materials are segmented down to pixel level while textures and scenes are annotated
at image level:目标、组成成分、材质是像素级标注,纹理和场景是图像级标注

standardize调整
- data imabalance issue:丢掉一部分尾部数据
- merge across dataset:合并不同数据集的同类数据
- merge under-sampled labels:合并子类
our Broden+
- 57, 095 images in total:51,617 training /5, 478 validation
22, 210 images from ADE20K, 10, 103 images from Pascal-Context and Pascal-Part, 19, 142 images from Open- Surfaces and 5, 640 images from DTD
metrics
- Pixel Accuracy (P.A.):the proportion of correctly classified pixels
- mean IoU (mIoU):目标前景的平均IoU,会影响bg分割的表现
- mIoU-bg:前景占比很小的时候,再加上bg IoU,object parts
- top-1 acc:图像级标注使用top1 acc,scene and texture classification
Designing Networks for Unified Perceptual Parsing
overview
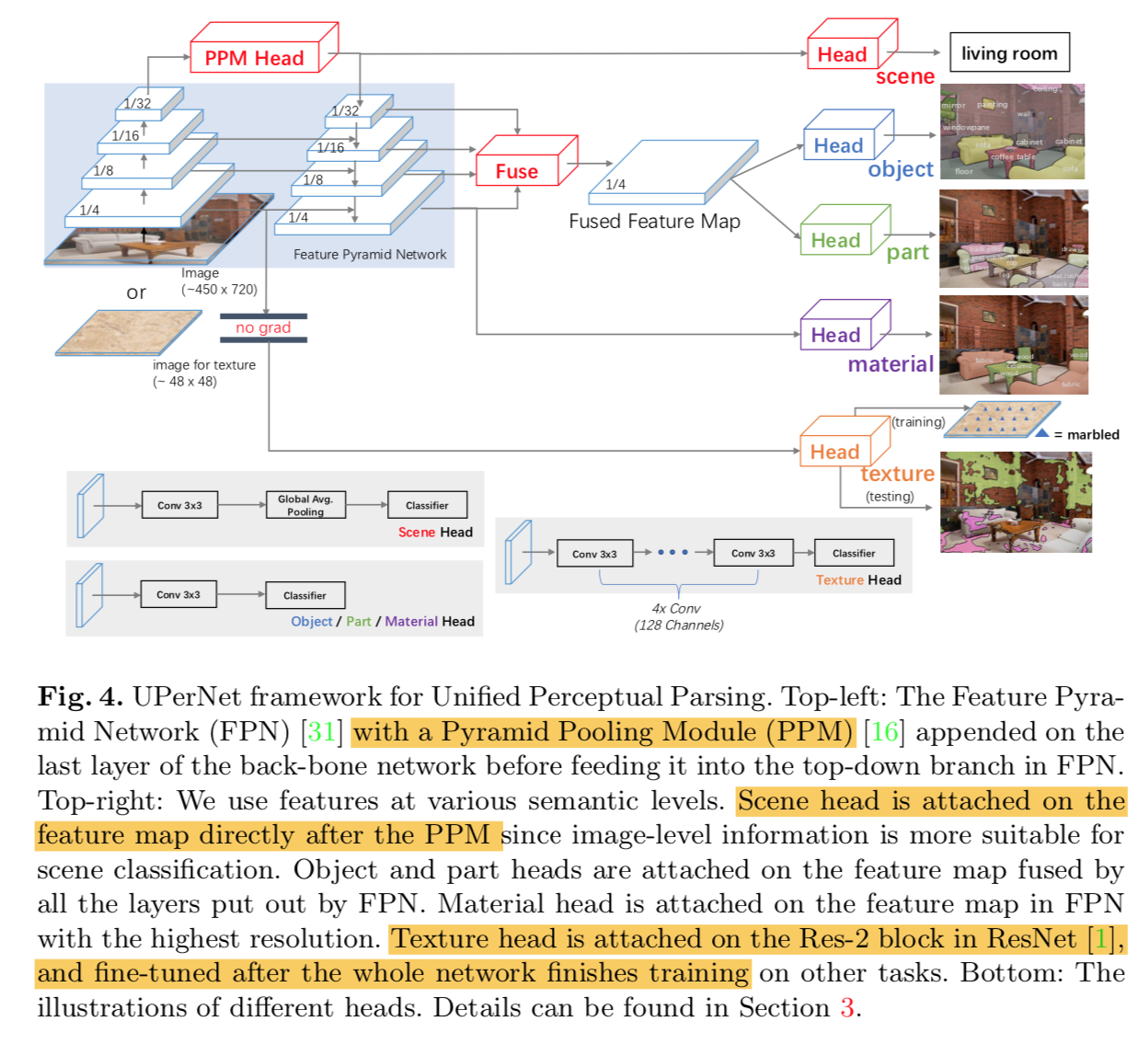
- 因为包含high/low level visual tasks,所以网络也是multi-level的:FPN with a PPM
- scene head是image-level classification label,直接接PPM的输出
- object and part heads是多尺度的,使用FPN fusion的输出
- material head是细粒度任务,使用FPN的highest resolution featuremap的输出
- texture head是更加细粒度任务,接在backobne的Res-2 block后面,而且是在网络训练完其他任务以后再fine-tuning的
FPN
- multi-level feature
- use [top-down path + lateral connections] to fuse high-level semantic information into middle & low
- conv-BN-ReLU,channel = 512
PPM
- from PSPNet
- 用来解决CNN理论上感受野足够大,但实际上相当小这个问题
- 相比较于用dilated methods去扩大感受野的方式,好处是down-sampling rate更大(还是x32),能够提取high-level semantics
ResNet
- 使用每个stage的输出作为level feature map,{C2, C3,C4,C5},x4-x32
- FPN的输出feature map,{P2, P3,P4,P5},P5是PPM的输出
heads
- scene head:分类器,接PPM输出,global average pooling + linear layer
- object/parts head:实验发现使用fusion map表现好于P2,fusion map通过bilinear interpolating & concat & conv
- materials head:on top of P2 rather than fused features
- texture head:
- texture label是图像级的,而且来自non-natural images
- directly fusing these images with other natural images is harmful to other tasks
- 同时我们希望预测是pixel-level
- 我们把它接在C2上,append several convolutional layers,感受野small enough,而且backbone layers不回传梯度,只更新head layers
- training images使用64x64的,确保模型只focus在local detail上
- only fine-tune a few epochs
training settings
- poly learning rate,initial=0.2,power=0.9
- weight decay=1e-4,momentum=0.9
- training inputs:常用的目标检测rescale方法,随机将shorter side变成{300, 375, 450, 525, 600}
- inference inputs:使用fixed shorter side 450
- longer side < 1200
- 为了防止noisy gradient,每个mini-batch随机选一种data source,按照数据集大小采样,只梯度更新相关path的参数
- object and material segmentation计算前景loss
- part segmentation计算前景+背景
- on each GPU a mini-batch involves 2 images
- sync-SGD & sync BN across 8 GPUs
- training iterations of ADE20k (20k images) is 100k,其他数据集对应rescale
Design discussion
- previous segmentation networks主要是FCN,用pretrained backbones搭配dilated convs,扩大感受野的同时维持比较大的resolution
- 但是原始的backobne,通常在stage4/5的时候有比较多的层,如resnet101的res4&res5就占了78层
- 改用dilated convs一是计算量memory飙升
- 二是有违最初的设计逻辑,未必还能发挥出原始的效能
- 第三就是不好兼顾本文任务的classification task
实验
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
动机
- propose a semantic segmentation framework SegFormer
- simple, lightweight, efficient, powerful
- hierarchical transformer + MLP decoder
特点
- does not need positional encoding:在inference阶段切换图像分辨率不会引起性能变化
- avoids complex decoders:MLP decoder主要就是merge multi levels
scale up to obtain a family of models:SegFormer-B0 to SegFormer-B5
verified on
- SegFormer-B4:50.3% mIoU on ADE20K,SOTA
SegFormer-B5:84.0% mIoU on Cityscapes
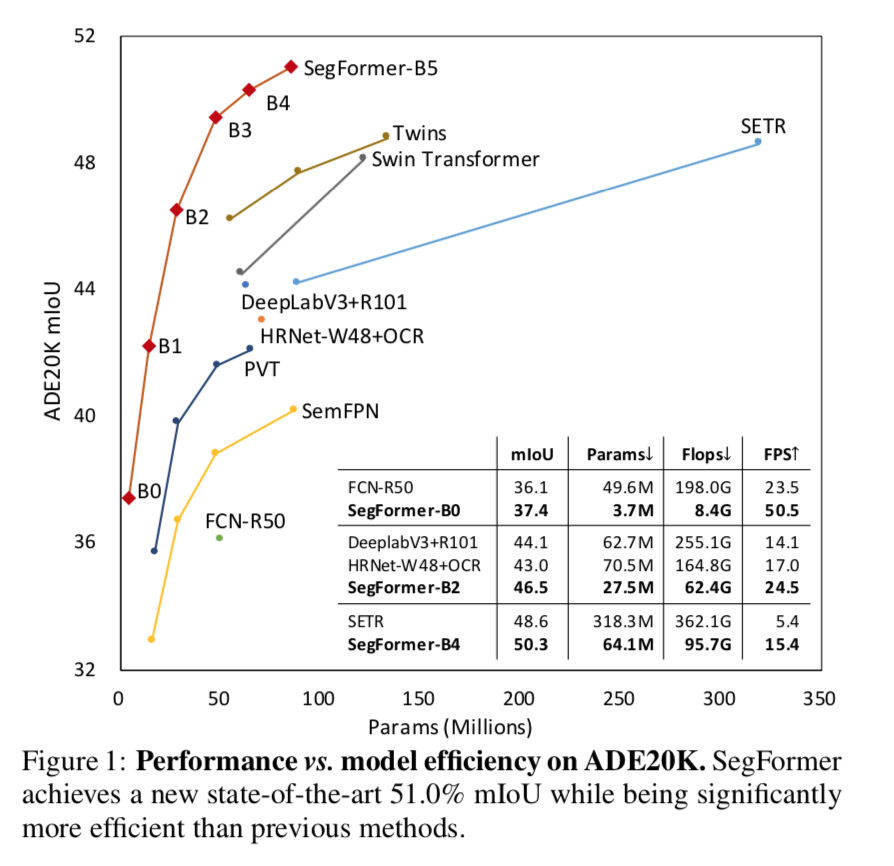
- propose a semantic segmentation framework SegFormer
论点
- SETR
- ViT-back + several CNN decoders
- ViT主要是计算量 & single-scale issue
- 后续methods提出PVT、Swin、Twins等,主要focus在优化multi-scale的backbone,忽略了decoder的设计
- this paper (SegFormer)
- redesigns both the encoder and the decoder
- 改进的Transformer encoder:hierarchical & positional-encoding-free
- 设计的all-MLP decoder:lightweight but powerful,设计的核心思想是 to take advantage of the Transformer-induced features where the attentions of lower layers tend to stay local, whereas the ones of the highest layers are highly non-local
- SETR
方法
overview

- encoder:
- 使用了4x4的patch size,相比较于16x16的ViT,fine-grained patches is more preferred by semantic segmentation
- multi-level features:x4,x8,x16,x32
- decoder
- 输入上述的multi-level features
- 输出x4的segmentation mask
- encoder:
Hierarchical Transformer Encoder
- We design a series of Mix Transformer encoders (MiT):MiT-B0 to MiT-B5
- 基于PVT的efficient self-attention module
- 针对原始attention block的平方时间复杂度
- use a reduction ratio R to reduce the length of sequence K:注意是改变K的长度,而不是Q
- given原始序列长度$N=HW$,feature dimensions $C$
- 先reshape:$\hat K = Reshape(\frac{N}{R},CR)(K)$
- 再降维:$K=Linear(CR,C)(\hat K)$
- 计算量从O(N^2)下降到O(N^2/R)
- set R to [64, 16, 4, 1] from stage-1 to stage-4
- 同时提出了several novel designs
- overlapped patch merging
- 本文的一个论点是ViT用non-overlapping patches去做patch merging,相邻patch之间没有保留local continuity,所以需要positional encoding
- 所以use an overlapping patch merging process
- notations
- patch size K=7/3
- stride S=4/2
- padding size P=3/1 (valid padding)
- patch merging操作仍旧通过卷积来实现
- positional-encoding-free design
- ViT修改resolution要同步interpolatePE,还是会引起掉点
- we introduce Mix-FFN
- 在FFN中夹了一个conv3x3
- sufficient to provide positional information
- 甚至可以用depth-wise convolutions节省参数量
- we argure that adding PE is not necessary in semantic segmentation
- overlapped patch merging
Lightweight All-MLP Decoder
idea是transformer有着远大于传统CNN的有效感受野,所以decoder可以轻量一点,不用再堆block

4 main steps
- unify:multi-level的feature maps各自通过MLP layer to unify the channel dimension
- upsample:所有的features上采样到x4,biliear interp
- fuse:concat + MLP(实际代码里用了1x1conv-bn-relu)
seg head:MLP,预测mask仍在x4尺度上

实验
- training settings
- AdamW:lr=2e-4,weight decay=1e-4
- poly LR:power=0.9,by iteration
- training settings