official repo: https://github.com/PetarV-/GAT
reference: https://zhuanlan.zhihu.com/p/34232818
- 归纳学习(Inductive Learning):先从训练样本中学习到一定的模式,然后利用其对测试样本进行预测(即首先从特殊到一般,然后再从一般到特殊),这类模型如常见的贝叶斯模型。
- 转导学习(Transductive Learning):先观察特定的训练样本,然后对特定的测试样本做出预测(从特殊到特殊),这类模型如k近邻、SVM等。
GRAPH ATTENTION NETWORKS
动机
- task:node classification
- 在GCN基础上引入 masked self-attentional layers
- specify different weights to different nodes in a neighborhood,感觉是用attention矩阵替换邻接矩阵?
论点
- the attention architecture properties
- parallelizable,计算高效
- can be applied to graph nodes having different degrees,这个邻接矩阵也可以啊
- directly applicable to inductive learning problems,是说原始GCN那种semi-supervised场景吗
- 感觉后面两点有点牵强
- GCN
- 可以避免复杂的矩阵运算
- 但是依赖固定图结构,不能直接用于其他图
- the attention architecture properties
methods
graph attentional layer
input:node features
- N个节点,F-dim representation
- $h=\{\overrightarrow {h_1},\overrightarrow {h_2},…,\overrightarrow {h_N} \}$,$\overrightarrow {h_i} \in R^F$
output:a new set of node features
- $h=\{\overrightarrow {h_1^{‘}},\overrightarrow {h_2^{‘}},…,\overrightarrow {h_N^{‘}} \}$,$\overrightarrow {h_i} \in R^{F^{‘}}$
a weight matrix
- $W \in R^{F \times F^{‘}}$
- applied to every node
then self-attention
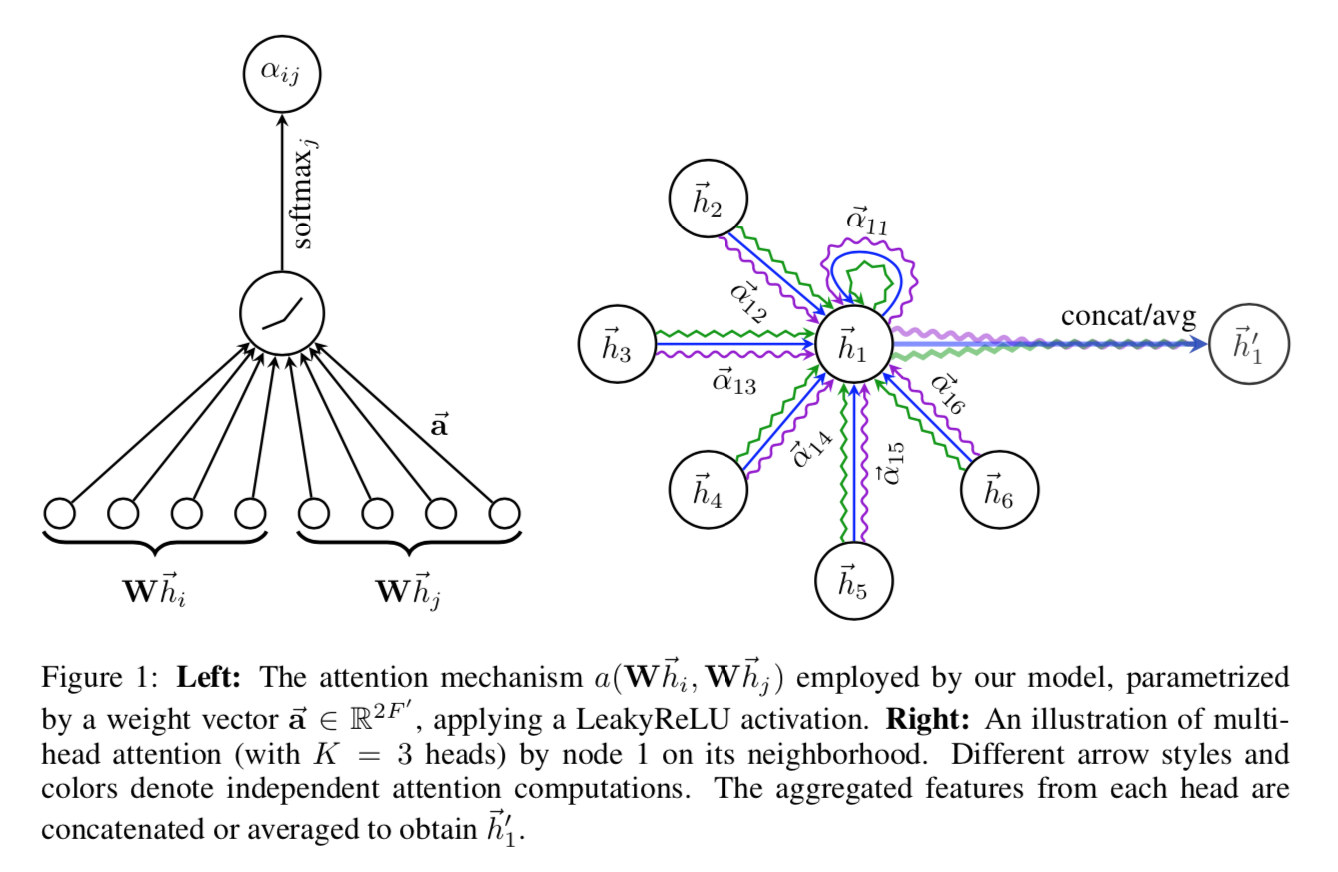
compute attention coefficients:$e_{ij} = a(W\overrightarrow {h_i},W\overrightarrow {h_j})$
- attention mechanism a:是一个single-layer feedforward neural network + LeakyReLU(0.2)
- weight vector $\in R^{2F^{‘}}$
softmax norm
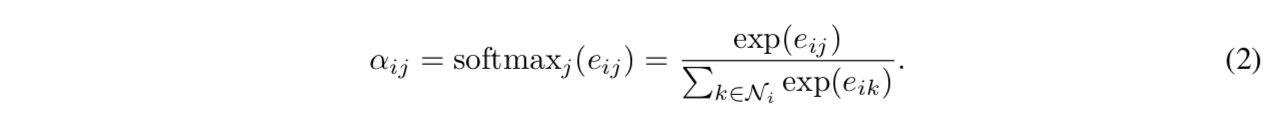
overall expression
- 两个feature vector concat到一起
- 然后全连接层+LeakyReLU
然后softmax
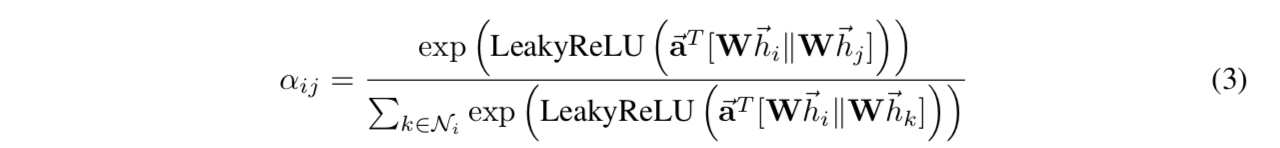
表达的是节点j对节点i的重要性
masked attention:inject graph structure,只计算节点i的neighborhood的importance
neighborhood:the first-order neighbors
加权和 + nonlinearity
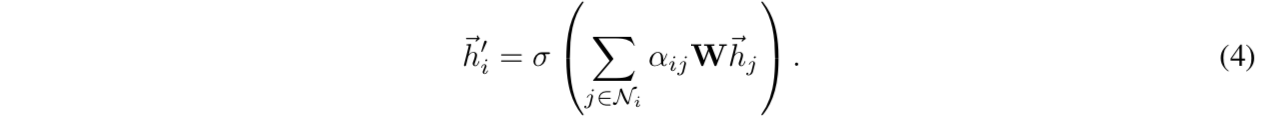
multi-head attention:
- trainable weights有多组,一个节点与其neighborhood的attention coefficients有多组
- 最后每组weights计算出那个new node feature(加权平均+nonlinear unit),可以选择concat/avg,作为最终输出
concat
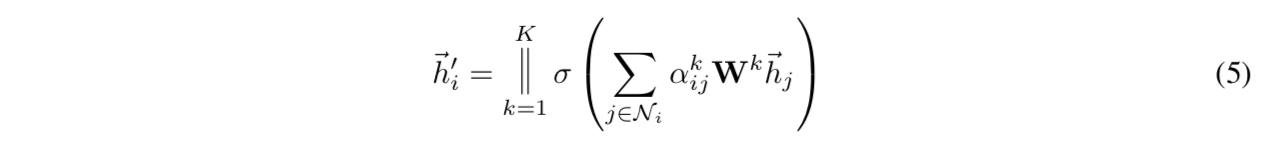
如果是网络最后一层的MHA layer,先avg,再非线性激活函数:
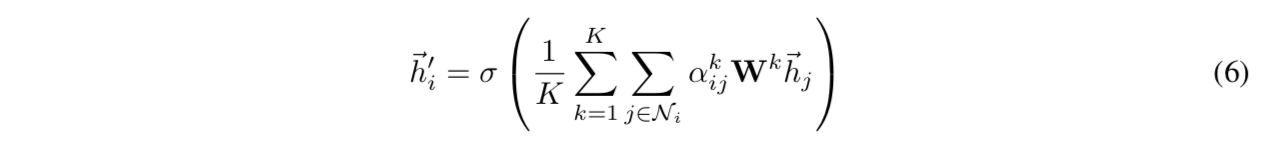
overall
comparisons to related work
our proposed GAT layer directly address several issues that were present in prior approaches
- computationally efficient,说是比矩阵操作高效,这个不懂
- assign different importance to nodes of a neighborhood,这个GCN with tranable adjacent matrix不也是一样性质的吗,不懂
- enable 有向图
- enable inductive learning,可以被直接用于解决归纳学习问题,即可以对从未见过的图结构进行处理,为啥可以不懂
数学表达上看,attention和adjacent matrix本质上都是用来建模graph edges的
- adj-trainable GCN:dag paper里面那种,adjacent matrix本身就是一个可训练变量(N,N),随着训练更新参数
GAT:attention的更新引入了新的线性层权重 $ W \in R^{2F^{‘}}$
