- 美研院的论文,检测,用于腰椎/髋关节关键点提取
- preparations
- hrnet
- pspModule
Structured Landmark Detection via Topology-Adapting Deep Graph Learning
动机
- landmark detection
- 特征点检测
- identify the locations of predefined fiducial points
- capture relationships among 解剖学特征点
- 一个难点:遮挡/复杂前景状态下,landmark的准确检测和定位——structual information
- the proposed method
- 用于facial and medical landmark detection
- topology-adapting:learnable connectivity
- learn end-to-end with two GCNs
- landmark detection
论点
- heatmap regression based methods
- 将landmarks建模成heatmaps,然后回归
- lacking a global representation
- 核心要素有bottom-up/top-down paths & multi-scale fusions & high resolution heatmap outputs
- coordinate regression based methods
- potentially incorporate structural knowledge but a lot yet to be explored
- falls behind heatmap-based ones
- 核心要素是cascaded & global & local
- 好处是结构化,不丢点,不多点,但是不一定准
- graph methods
- 基于landmark locations和landmark-to-landmark-relationships构建图结构
- most methods relies on heatmap detection results
- we would directly regress landmark locations from raw input image
- we propose
- DAG:deep adaptive graph
- 将landmarks建模成graph图
- employ global-to-local cascaded Graph Convolution Networks逐渐将landmark聚焦在目标位置
- graph signals combines
- local image features
- graph shape features
- cascade
- two GCNs
- 第一个预测一个global transform
- 第二个预测local offsets to further adjust
- contributions
- effectively exploit the structural knowledge
- allow rich exchange among landmarks
- narrow the gap between coordinate & heatmap based methods
- heatmap regression based methods
方法
the cascaded-regression framework
input
- image
- initial landmarks from the mean shape
outputs
- predicted landmark coordinates in multiple steps
feature
- use graph representation
- G = (V,E,F)
- V是节点,代表landmarks,也就是特征点,表示为(x,y)的坐标
- E是边,代表connectivity between landmarks,表示为(id_i, id_k)的无向/有向映射,整体的E matrix是个稀疏矩阵
- F是graph signals,capturing appearance and shape information,表示为高维向量,如256-dim vec,与节点V一一对应,用于储存节点信息,在GCN中实际进行计算交互
overview
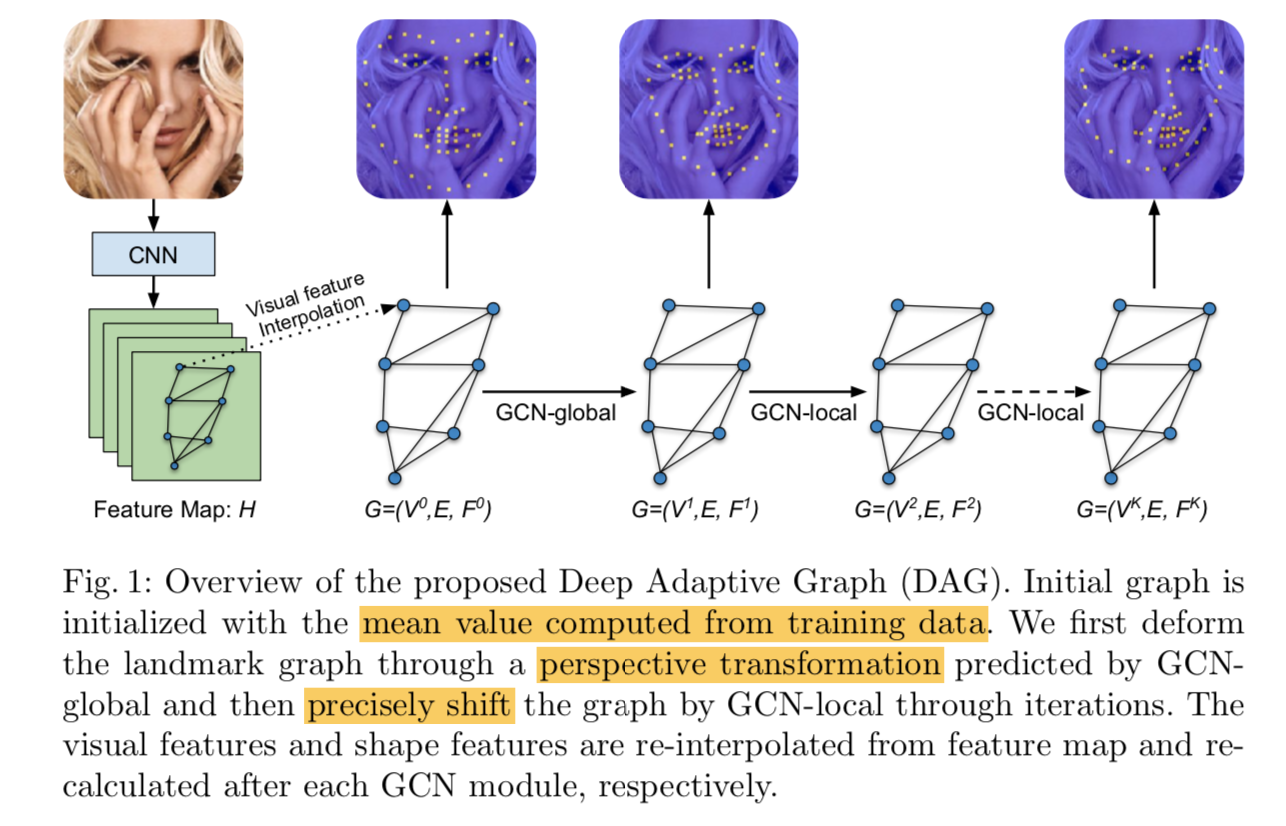
- summary
- cascade:一个GCN-global做粗定位,迭代多个GCN-local做precise定位
- interpolation:feature map到feature nodes的转换,通过interpolation,【是global interp吗,是基于initial mean coords吗】
- regression:【targets的具体坐标表示???】
- inital graph:训练集的平均值
- graph signal:visual feature和shape feature
- summary
Cascaded GCNs
GCN-global:global transformation
GCN-local:coordinate offsets
share the same GCN architecture
graph convolution
核心思想就是:给定一个图结构(with connectivity E),每一次堆叠graph convolution,就是在对每个图节点,基于其自身$f_k^i$和邻居节点$f_k^j$的当前graph feature,weighted aggregating,结果作为这个节点这次图卷积的输出$f_{k+1}^i$
learnable weight matrices $W_1$ 和 $W_2$
可以看作是邻居节点间信息交互的一种方式
Global Transformation GCN
这个model的作用是将initial landmarks变换到coarse targets
参照STN,
recall STN
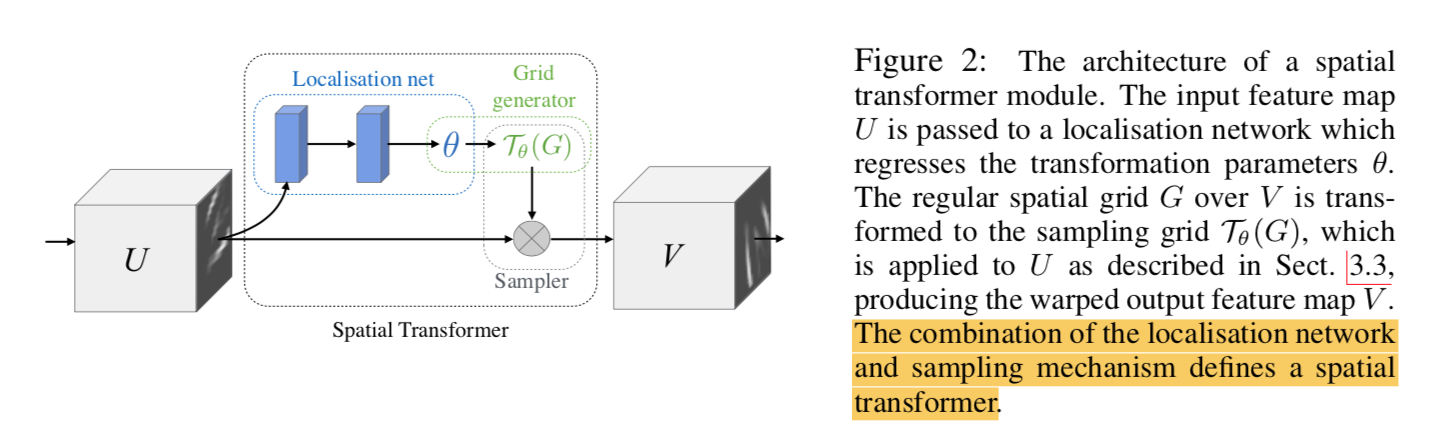
使用perspective transformation透视变换,引入9个scalars,进行图形变
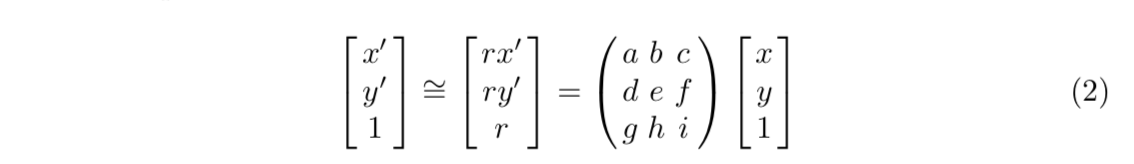
workflow
- given a target image
- initialize landmark locations $V^0$ using trainingset mean
- GCN-global + GIN 预测perspective transformation
- 进而得到变换后的节点位置
graph isomorphism network (GIN)
图的线性层
输入是GCN-global的graph features $\{f_k^i\}$
输出是9-dim vector
计算方式
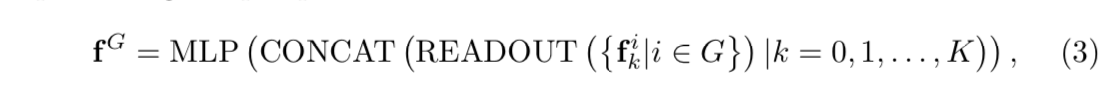
- READOUT:sum the features from all nodes
- CONCAT:得到一个高维向量
- MLP:9-dim fc
- 最后得到9-dim的perspective transformation scalar
coordinate update
- 将9-dim $f^G$ reshape成3x3 transformation matrix M
然后在当前的landmark locations $V^0$上施加变换——矩阵左乘
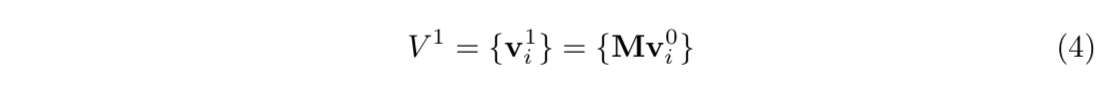
Local Refinement GCN
GCN结构与global的一致,但是不share权重
最后的GIN头变了
- 输出改成2-dim vector
- represents coordinate offsets
coordinate update
加法,分别在x/y轴坐标上
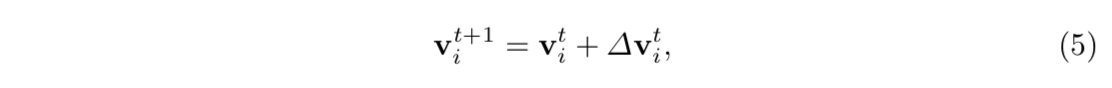
we perform T=3 iterations
Graph signal with appearance and shape information
- Visual Feature
- denote CNN输出的feature map H with D channels
- encoding整个feature map:bi-linear interpolation at the landmark location $v_i$,记作$p_i$,是个D-dim vector
- Shape Feature
- visual feature对节点间关系的建模,基于global map全局信息提取,比较隐式、间接
- 事实上图结构能够直接对global landmarks shape进行encoding
- 本文用displacement vectors,就是距离,每个节点的displacement vector记作$q_i=\{v_j-v_i\}_{j!=i}$,flatten成一维,对有N个节点的图,每个节点的q-vec维度为2*(N-1)
- shape feature保存了structural information,当人脸的嘴被遮住的情况下,基于眼睛和鼻子以及结构性信息,就能够推断嘴的位置,这是Visual Feature不能直接表达的
- graph signal
- concat
- result in a feature vector $f_i \in R^{D+2(N-1)}$
- Visual Feature
Landmark graph with learnable connectivity
- 大多数方法的图基于先验知识构建
- we learn task-specific graph connectivity during training phase
- 图的connectivity serves as a gate,用邻接矩阵表示,并将其作为learnable weights
training
GCN-global
margin loss
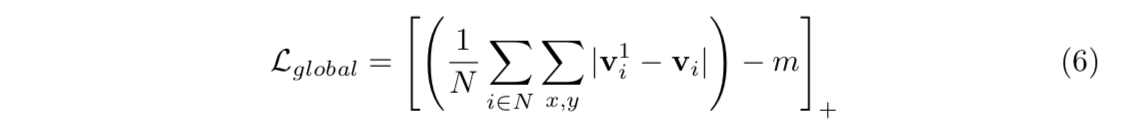
$v_i^1$是GCN-global的预测节点坐标
m是margin
$[u]_+$是$max(0,u)$
push节点坐标到比较接近ground truth就停止了,防止不稳定
GCN-local
L1 loss
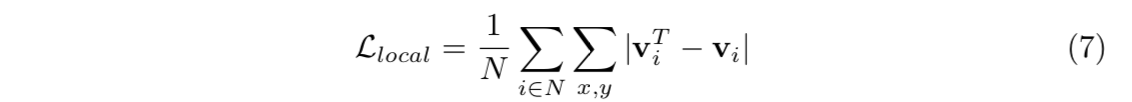
$v_i^T$是第T个iteration GCN-local的预测节点坐标
overall loss
- 加权和
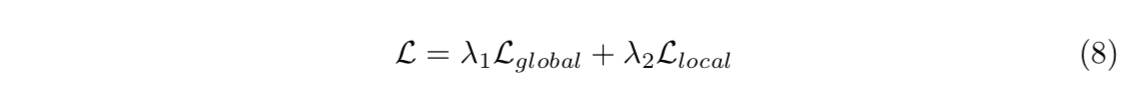
网络结构
- GCN-global
- 三层basic graph convolution layer with residual(id path)
- concat distance vector
- 一层basic graph convolution
- mean axis1(node axis)
- fc,输出9-dim scalar,(b,9)
- GCN-local
- 三层basic graph convolution layer with residual(id path)
- relu
- concat distance vector
- 一层basic graph convolution
- fc,输出2-dim coords for each node,(b,24,2)
- GCN-global