Refine Myself by Teaching Myself : Feature Refinement via Self-Knowledge Distillation
动机
- 传统的知识蒸馏
- by stage:先训练庞大的teacher
- self knowledge distillation
- without the pretrained network
- 分为data augmentation based approach 和 auxiliary network based approach
- data augmentation approach如UDA,通过监督原始图像和增强图像的一致性,但是会loose local information,对pixel-level tasks不友好,而且监督信息是从logits层,没有直接去refine feature maps
- our approach FRSKD
- auxiliary network based approach
- utilize both soft label and featuremap distillation
- 传统的知识蒸馏
论点
various distillation methods
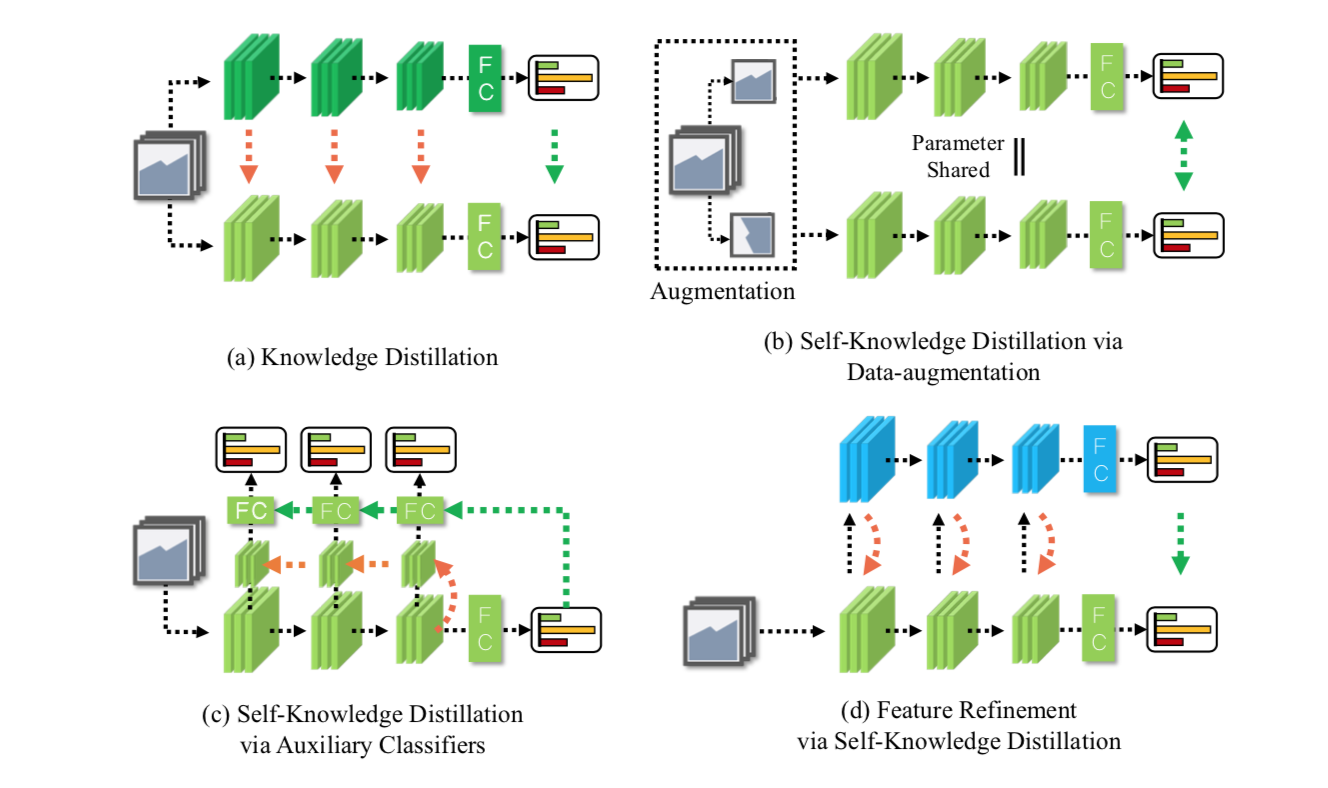
- a是传统知识蒸馏,深绿色是pretrained teacher,浅绿色是student,橙色箭头是feature蒸馏,绿色箭头是soft label蒸馏
- b是data augmentation based 自蒸馏,shared 网络,原图和增强后的图,用soft logits来蒸馏
- c是auxiliary classifier based 自蒸馏,cascaded分类头,每个分类器都接前一个的
- d是本文自蒸馏,和c最大的不同是bifpn结构使得两个分类器每个level的特征图之间都有连结,监督方式一样的
FPN
- PANet:上行+下行
- biFPN:上行+下行+同层级联
方法
overview
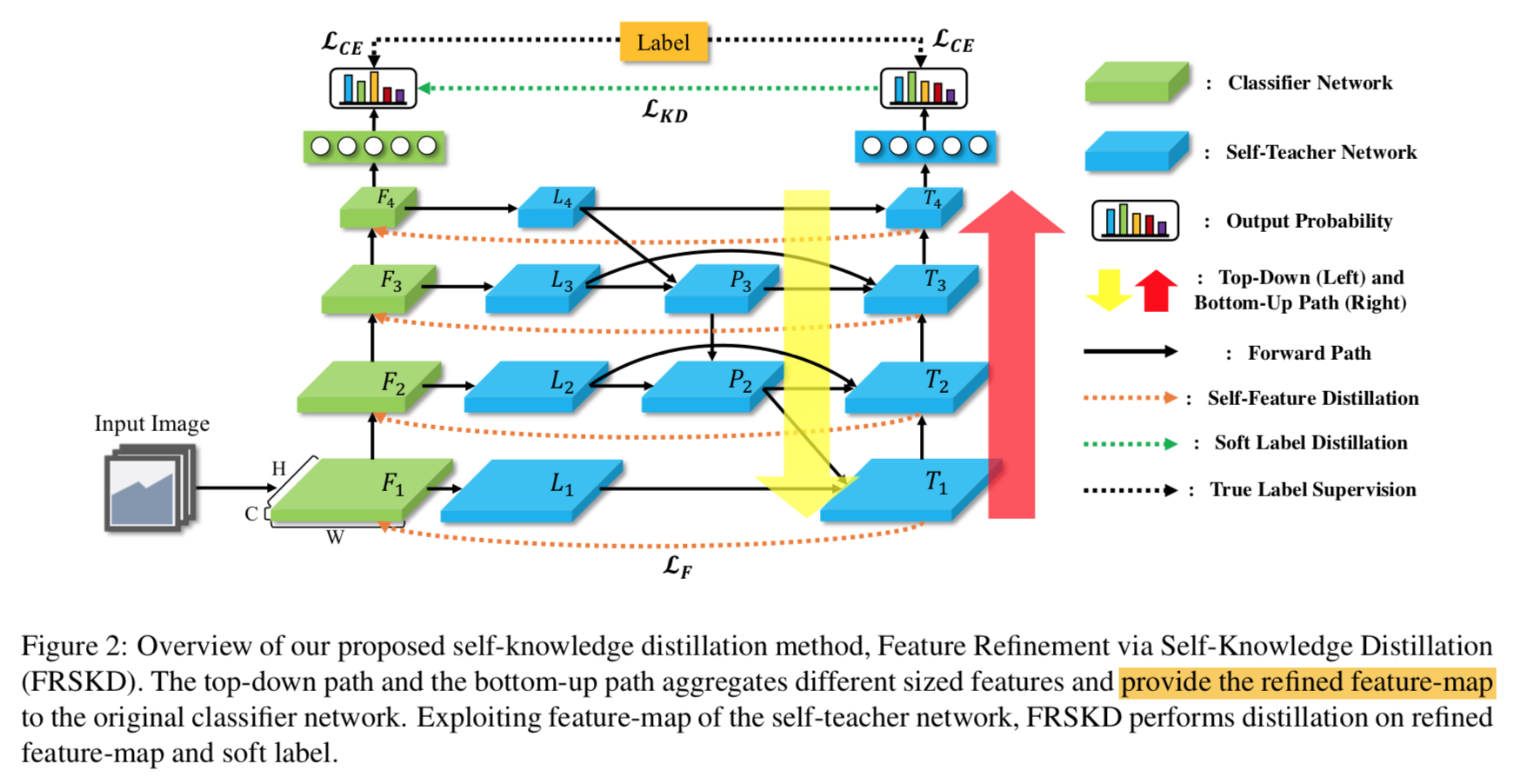
notations
- dataset $D=\{(x_1,y_1), (x_2,y_2),…, (x_N,y_N)\}$
- feature map $F_{i,j}$,i-th sample,j-th block
- channel dimension $c_j$,j-th block
self-teacher network
- self-teacher network的目的是提供refined feature map和soft labels作为监督信息
- inputs:feature maps $F_1, F_2, …, F_n$,也就是说teacher在进行梯度回传的时候到F就停止了,不会更新student model的参数
- modified biFPN
- 第一个不同:别的FPN都是在fuse之前先用一个fixed-dim 1x1 conv将所有level的feature map转换成相同通道数(如256),we design $d_i$ according to $c_i$,引入一个宽度系数width,$d_i=width*c_i$,
- 第二个不同:使用depth-wise convolution
- notations
- BiFPN:每层dim固定的版本
- BiFPNc:每层dim随输入变化的版本
self-feature distillation
- feature distillation
- adapt attention transfer
- 对feature map先进行channel-wise的pooling,然后L2 norm,提取spatial information
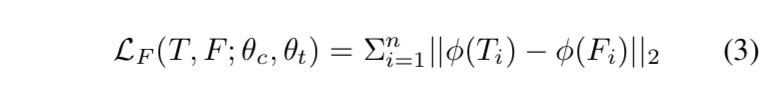
- soft label distillation
- 两个分类头的KL divergence
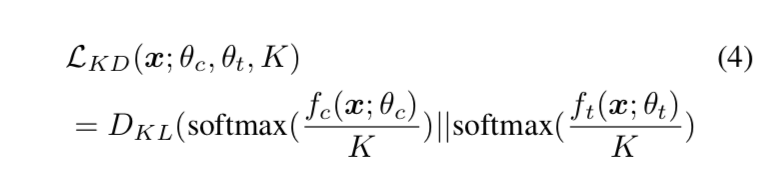
- CE with gt
- 两个分类头分别还有正常的CE loss
- overall
- 总的loss是4个loss相加:$L_{FRSKD}(x,y,\theta_c, \theta_t, K)=L_{CE}(x,y,\theta_c)+L_{CE}(x,y,\theta_t)+\alpha L_{KD}(x,\theta_c,\theta_t, K) + \beta L_{F}(T,F,\theta_c,\theta_T)$
- $\alpha \in [1,2,3]$
- $\beta \in [100,200]$
- 【QUESTION】FRSKD updates the parameters by the distillation loss,$L_{KD}$ and $L_F$,which is only applied to the student network,这个啥意思暂时没理解
- feature distillation
实验
- experiment settings
- FRSKD\F:只做soft label的监督,不做feature map的监督
- FRSKD:标准的本文方法
- FRSKD+SLA:本文方法的基础上attach data augmentation based distillation
- experiment settings