google brain,引用量51,但是ImageNet榜单/SOTA模型的对比实验里面经常能够看到这个SAM,出圈形式为分类模型+SAM
SAM:Sharpness-Aware Minimization,锐度感知最小化
official repo:https://github.com/google-research/sam
Sharpness-Aware Minimization for Efficiently Improving Generalization
动机
- heavily overparametered models:training loss能训到极小,但是generalization issue
- we propose
- Sharpness-Aware Minimization (SAM)
- 同时最小化loss和loss sharpness
- improve model generalization
- robustness to label noise
- verified on
- CIFAR 10&100
- ImageNet
- finetuning tasks
论点
typical loss & optimizer
- population loss:我们实际想得到的是在当前训练集所代表的分布下的最优解
training set loss:但事实上我们只能用所有的训练样本来代表这个分布
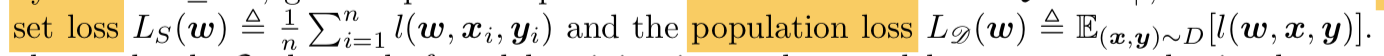
因为loss函数是non-convex的,所以可能存在多个local even global minima对应的loss value是一样的,但是generalization performance确是不同的
成熟的全套防止过拟合手段
- loss
- optimizer
- dropout
- batch normalization
- mixed sample augmentations
- our approach
- directly leverage the geometry of the loss landscape
- and its connection to generalization (generalization bound)
- proved additive to existing techniques
方法
motivation
- rather than 寻找一个weight value that have low loss,我们寻找的是那种连带他临近的value都能有low loss的value
- 也就是既有low loss又有low曲度
sharpness term
- $\max \limits_{||\epsilon||_p < \rho} L_s(w+\epsilon) - L_s(w)$
- 衡量模型在w处的sharpness
Sharpness-Aware Minimization (SAM) formulation
- sharpness term再加上train loss再加上regularization term
- $L_S^{SAM}(w)=\max\limits_{a} L_s(w+\epsilon)$
- $\min \limits_{w} L_S^{SAM}(w) + \lambda ||w||^2_2$
- prevent the model from converting to a sharp minimum
effective approximation
bound
- with $\frac{1}{p} + \frac{1}{q} = 1$

approximation
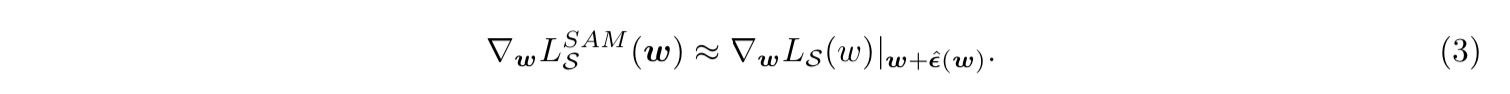
pseudo code

- given a min-batch
- 首先计算当前batch的training loss,和当前梯度,$w_t$ to $w_{t+1}$
- 然后计算近似为梯度norm的步长$\hat\epsilon(w)$,equation2,$w_t$ to $w_{adv}$,这里面的adv联动了另一篇论文《AdvProp: Adversarial Examples Improve Image Recognition》
- 然后计算近似的sharpness term,可以理解为training loss在w邻居处的梯度,equation3,应该是蓝色箭头的反方向,图上没标记出来
- 用w邻居的梯度来更新w的权重,用负梯度(蓝色箭头)
- overll就是:要向前走之前,先回退,缺点是两次梯度计算,时间double
实验结论
能优化到损失的最平坦的最小值的地方,增强泛化能力
