recollect
[SimCLR]
[MoCo]
Multi-Task Self-Training for Learning General Representations
动机
- learning general feature representations
- expect a single general model
- 相比较于training specialized models for various tasks
- harness from independent specialized teacher models
- with a multi-task pseudo dataset
- trained with multi-task learning
- evalutate on 6 vision tasks
- image recognition (classification, detection, segmentation)
- 3D geometry estimation
论点
pretraining & transfer learning
- transformer一般都是这个套路,BiT&ViT
- pretraining
- supervised / unsupervised
- learn feature representations
- transfer learning
- on downstream tasks
- the features may not necessarily be useful
- 最典型的就是ImageNet pre-training并不能improve COCO segmentation,但是Objects365能够大幅提升
- pretraining tasks必须要和downstream task align,learn specialized features,不然白费
learning general features
- a model simultaneously do well on multiple tasks
- NLP的bert是一个典型用多任务提升general ability的
- CV比较难这样做是因为标签variety,没有这样的大型multi-task dataset
multi-task learning
- shared backbone (如ResNet-FPN)
- small task-specific heads
self-training
- use a supervised model to generate pseudo labels on unlabeled data
- then a student model is trained on the pseudo labeled data
- 在各类任务上都proved涨点
- 但是迄今为止都是focused on a single task
in this work
lack of large scale multi-task dataset的issue,通过self-training to fix,用pseudo label
specialized/general issue,通过多任务,训练目标就是六边形战士,absorb the knowledge of different tasks in the shared backbone
three steps
- trains specialized teachers independently on labeled datasets (分类、分割、检测、深度估计)
- the specialized teachers are then used to label a larger unlabeled dataset(ImageNet) to create a multi- task pseudo labeled dataset
train a student model with multi-task learning
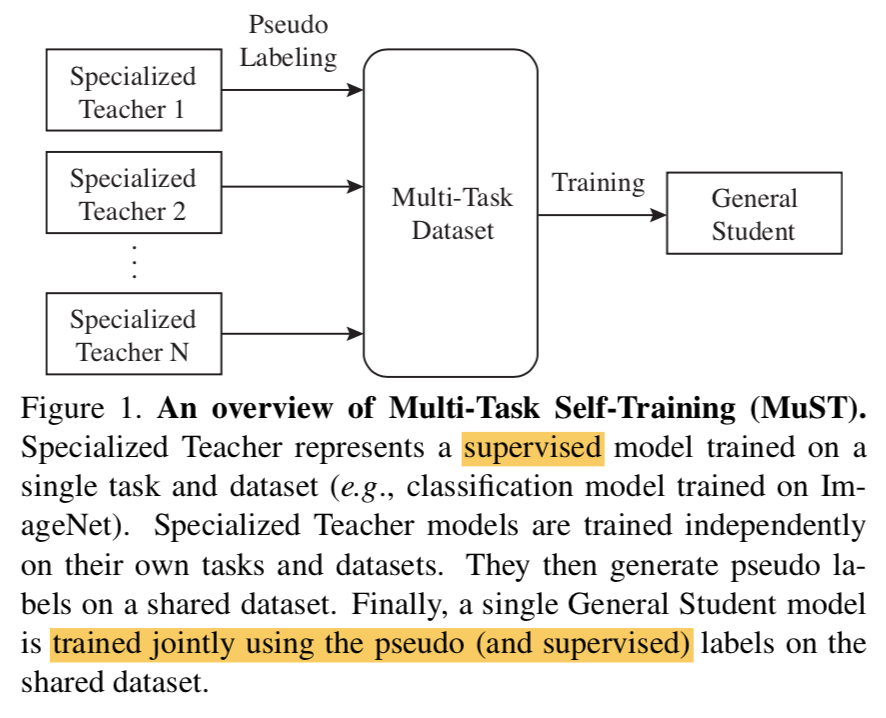
MuST的特质
- improve with more unlabeled data,数据越多general feature越好
- can improve upon already strong checkpoints,在海量监督高精度模型基础上fine-tune,仍旧能在downstream tasks涨点
方法
Specialized Teacher Models
- 4 teacher models
- classification:train from scratch,ImageNet
- detection:train from scratch,Object365
- segmentation:train from scratch,COCO
- depth estimation:fine-tuning from pre-trained checkpoint
- pseudo labeling
- unlabeled / partially labeled datasets
- for detection:hard score threshold of 0.5
- for segmentation:hard score threshold of 0.5
- for classification:soft labels——probs distribution
- for depth:直接用
- 4 teacher models
Multi-Task Student Model
模型结构
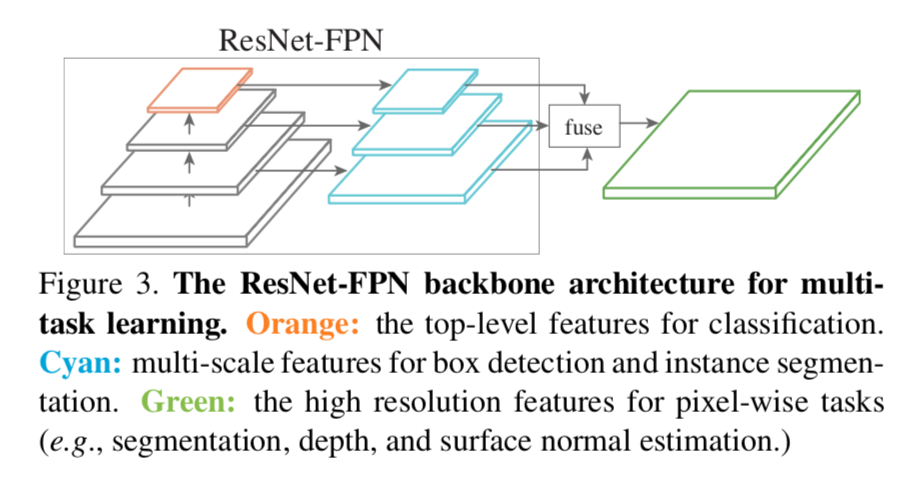
- shared back
- C5:for classification
- feature pyramids {P3,P4,P5,P6,P7}:for detection
- fused P2:for pixel-wise prediction,把feature pyramids rescale到level2然后sum
- heads
- classification head:ResNet design,GAP C5 + 线性层
- object detection task:Mask R-CNN design,RPN是2 hidden convs,Fast R-CNN是4 hidden convs + 1 fc
- pixel-wise prediction heads:3 hiddent convs + 1 linear conv head,分割和深度估计任务independent,不share heads
- shared back
Teacher-student training
- using the same architecture
- same data augmentation
- teacher和student的main difference就是dataset和labels
Learning From Multiple Teachers
- every image has supervision for all tasks
- labels may come from supervised or pseudo labels
- 如果使用ImageNet数据集,classification就是真标签,det/seg/depth supervision则是伪标签
- balance the loss contribution
- 加权和,task-specific weights
- for ImageNet,use $w_i = \frac{b_slr_{it}}{b_{it}lr_{s}}$
- follow the scaling rule:lr和batch size成正比
- except for depth loss
Cross Dataset Training
- training across ImageNet, object365 and COCO
- 有标签的就用原标签,没有的用伪标签,supervised labels and pseudo labels are treated equally,而不是分别采样和训练
- balance the datasets:合在一起然后均匀采样
Transfer Learning
- 得到general student model以后,fine-tune on 一系列downstream tasks
- 这些downstream datasets与MuST model的训练数据都是not align的
- 这个实验要证明的是supervised model(如teacher model)和self-supervised model(如用pseudo label训练出来的student model),在downstream tasks上迁移学习能performance是差不多的,【注意⚠️:如果迁移datasets前后align就不是这样了,pretrain显然会更好!!!】