papers
[MPL 2021] Meta Pseudo Labels
[UDA 2009] Unsupervised Data Augmentation for Consistency Training
[Entropy Minimization 2004] Semi-supervised Learning by Entropy Minimization
Meta Pseudo Labels
动机
- semi-supervised learning
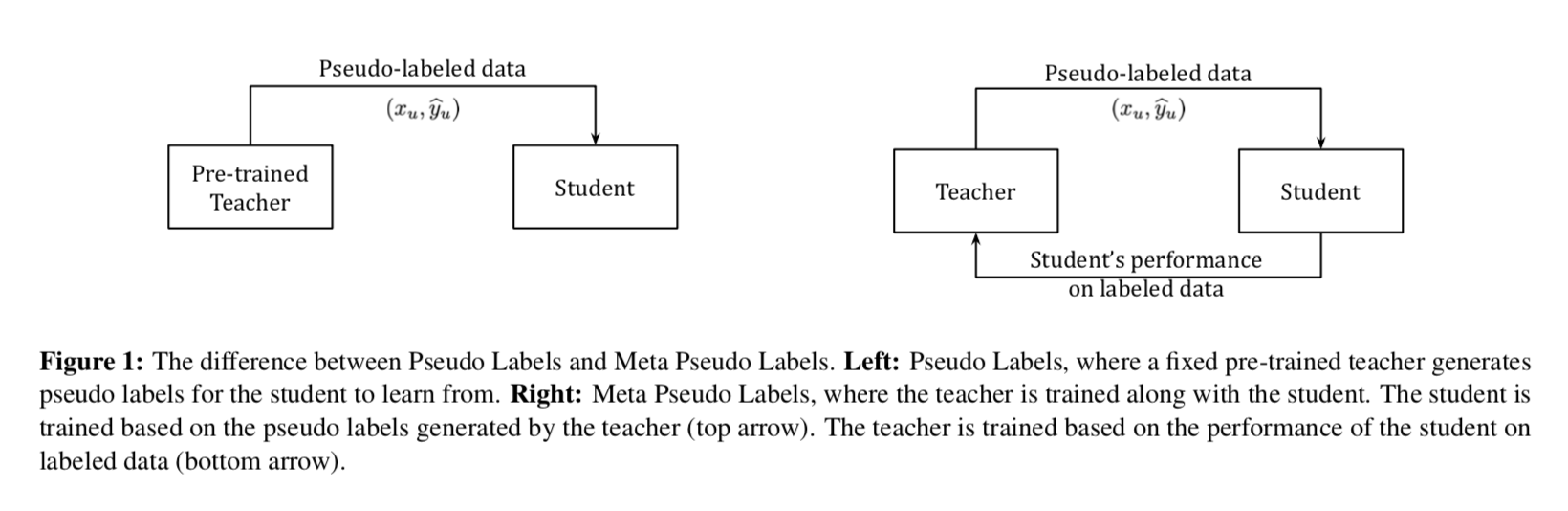
- Pseudo Labels:fixed teacher
- Meta Pseudo Labels:constantly adapted teacher by the feedback of the student
- SOTA on ImageNet:top-1 acc 90.2%
- semi-supervised learning
论点
Pseudo Labels methods
- teacher generates pseudo labels on unlabeled images
- pseudo labeled images are then combined with labeled images to train the student
- confirmation bias problem:student的精度取决于伪标签的质量
we propose Meta Pseudo Labels
- teacher observes how its pseudo labels affect the student
- then correct the bias
- the feedback signal is the performance of the student on the labeled dataset
- 总的来说,teacher和student是train in parallel的
- student learns from pseudo labels from the teacher
- teacher learns from reward signal from how well student perform on labeled set
- dataset
- ImageNet as labeled set
- JFT-300M as unlabeled set
- model
- teacher:EfficientNet-L2
- student:EfficientNet-L2
main difference
- Pseudo Labels方法中,teacher在单向的影响student
Meta Pseudo Labels方法中,teacher和student是交互作用的
方法
notations
- models
- teacher model T & $\theta_T$
- student model S & $\theta_S$
- data
- labeled set $(x_l, y_l)$
- unlabeled set $(x_u)$
- predictions
- soft predictions by teacher $T(x_u, \theta_T)$
- student $S(x_u, \theta_S)$ & $S(x_l, \theta_S)$
- loss
- $CE(q,p)$,其中$q$是one-hot label,e.g. $CE(y_l, S(x_l, \theta_S))$
- models
Pseudo Labels
- given a fixed teacher $\theta_T$
train the student model to minimize the cross-entropy loss on unlabeled data
$\theta_S^{PL}$ also achieve a low loss on labeled data
- $\theta_S^{PL}$ explicitly depends on $\theta_T$:$\theta_S^{PL}(\theta_T)$
- student loss on labeled data is also a function of $\theta_T$:$L_l(\theta_S^{PL}(\theta_T))$
Meta Pseudo Labels
intuition:minimize $L_l$ with respect to $\theta_T$
但是实际上dependency of $\theta_S^{PL}(\theta_T)$ on $\theta_T$ 非常复杂
因为我们用了teacher prediction的hard labels去训练student
an alternating optimization procedure

teacher’s auxiliary losses
- augment the teacher’s training with a supervised learning objective and a semi-supervise learning objective
- supervised objective
- train on labeled data
- CE
- semi-supervised objective
- train on unlabeled data
- UDA(Unsupervised Data Augmentation):将样本进行简单增强,通过衡量一致性损失,模型的泛化效果得到提升
- consistency training loss:KL散度
finetuning student
- 在meta pseudo labels训练过程中,student only learns from the unlabeled data
- 所以在训练过程结束后,可以finetune it on labeled data to improve accuracy
overall algorithm

* 这里面有一处下标写错了,就是teacher的UDA gradient,是在unlabeled data上面算的,那两个$x_l$得改成$x_u$ * UDA loss论文里使用两个predicted logits的散度,这里是CE
Unsupervised Data Augmentation for Consistency Training
动机
- data augmentation in previous works
- 能在一定程度上缓解需要大量标注数据的问题
- 多用在supervised model上
- achieved limited gains
- we propose UDA
- apply data augmentation in semi-supervised learning setting
- use harder and more realistic noise to generate the augmented samples
- encourage the prediction to be consistent between unlabeled & augmented unlabeled sample
- 在越小的数据集上提升越大
- verified on
- six language tasks
- three vision tasks
- ImageNet-10%::top1/top5 68.7/88.5%
- ImageNet-extra unlabeled:top1/top5 79.0/94.5%
- data augmentation in previous works
论点
- semi-supervised learning
- three categories
- graph-based label propagation via graph convolution and graph embeddings
- modeling prediction target as latent variables
- consistency / smoothness enforcing
- 最后这一类方法shown to work well,
- enforce the model predictions on the two examples to be similar
- 主要区别在于perturbation function的设计
- three categories
- we propose UDA
- use state-of-the-art data augmentation methods
- we show that better augmentation methods(AutoAugment) lead to greater improvements
- minimizes the KL divergence
- can be applied even the class distributions of labeled and unlabeled data mismatch
- we propose TSA
- a training technique
- prevent overfitting when much more unlabeled data is avaiable than labeled data
- semi-supervised learning
方法
formulation
given an input $x\in U$ and a small noise $\epsilon$
compute the output distribution $p_{\theta}(y|x)$ and $p_{\theta}(y|x,\epsilon)$
minimize the divergence between two predicted distributions $D(p_{\theta}(y|x)||p_{\theta}(y|x,\epsilon))$
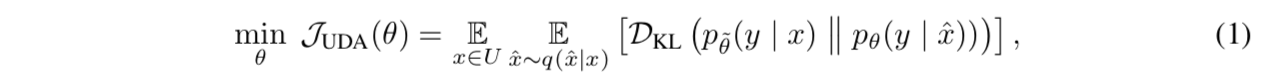
add a CE loss on labeled data
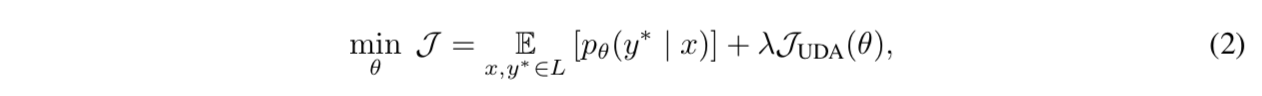
UDA的优化目标
- enforce the model to be insensitive to perturbation
- thus smoother to the changes in the input space
$\lambda=1$ for most experiments
use different batchsize for labeled & unlabeled
Augmentation Strategies for Different Tasks
- AutoAugment for Image Classification
- 通过RL搜出来的一组optimal combination of aug operations
- Back translation for Text Classification
- TF-IDF based word replacing for Text Classification
- AutoAugment for Image Classification
Trade-off Between Diversity and Validity for Data Augmentation
- 对原始sample做变换的时候,有一定概率导致gt label变化
- AutoAugment已经是optmial trade-off了,所以不用管
- text tasks需要调节temperature
Additional Training Techniques
TSA(Training Signal Annealing)
situation:unlabeled data远比labeled data多的情况,我们需要large enough model去充分利用大数据,但又容易对小trainset过拟合
for each training step
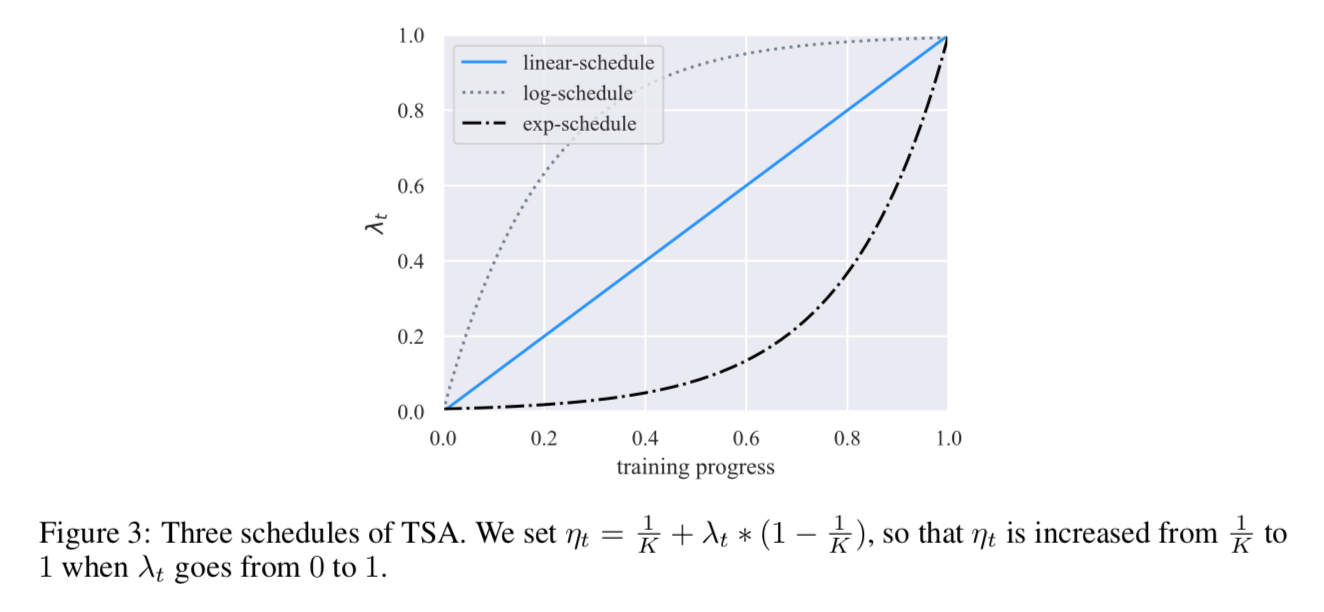
- set a threshold $\frac{1}{K}\leq \eta_t\leq 1$,K is the number of categories
- 如果样本在gt cls上的预测概率大于这个threshold,就把这个样本的loss去掉
$\eta_t$ serves as a ceiling to prevent the model from over-training on examples that the model is already confident about
gradually release the training signals of the labeled examples,缓解overfitting
schedules of $\eta_t$
- log-schedule:$\lambda_t = 1-exp(-\frac{t}{T}*5)$
- linear-schedule:$\lambda_t = \frac{t}{T}$
exp-schedule:$\lambda_t = exp((\frac{t}{T}-1)*5)$
如果模型非常容易过拟合,用exp-schedule,反过来(abundant labeled data/effective regularizations),用log-schedule
Sharpening Predictions
- situation:the predicted distributions on unlabeled examples tend to be over-flat across categories,task比较困难,训练数据比较少时,在unlabeled data上每类的预测概率都差不多低,没有倾向性
- 这时候KL divergence的监督信息就很弱
- thus we need to sharpen the predicted distribution on unlabeled examples
- Confidence-based masking:将current model not confident enough to predict的样本过滤掉,只保留最大预测概率大于0.6的样本计算consistency loss
- Entropy minimization:add an entropy term to the overall objective
- softmax temperature:在计算softmax时先对logits进行rescale,$Softmax(logits/\tau)$,a lower temperature corresponds to a sharper distribution
- in practice发现Confidence-based masking和softmax temperature更适用于小labeled set,Entropy minimization适用于相对大一点的labeled set
Domain-relevance Data Filtering
- 其实也是Confidence-based masking,先用labeled data训练一个base model,然后inference the out-of-domain dataset,挑出预测概率较大的样本