Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection
动机
- one-stage detectors
- dense prediction
- three fundamental elements
- class branch
- box localization branch
- an individual quality branch to estimate the quality of localization
- current problems
- the inconsistent usage of the quality estimation in train & test
- the inflexible Dirac delta distribution:将box regression的value建模成真值附近的脉冲分布,用来描述边界不清晰/遮挡的case可能不准确
- we design new representations for these three elements
- merge quality estimation into class prediction:将objectness/centerness整合进cls prediction,直接用作NMS score
- continout labels
- propose GFL(Generalized Focal Loss) that generalizes Focal Loss from discrete form into continous version
- test on COCO
- ResNet-101-?-GFL: 45.0% AP
- defeat ATSS
- one-stage detectors
论点
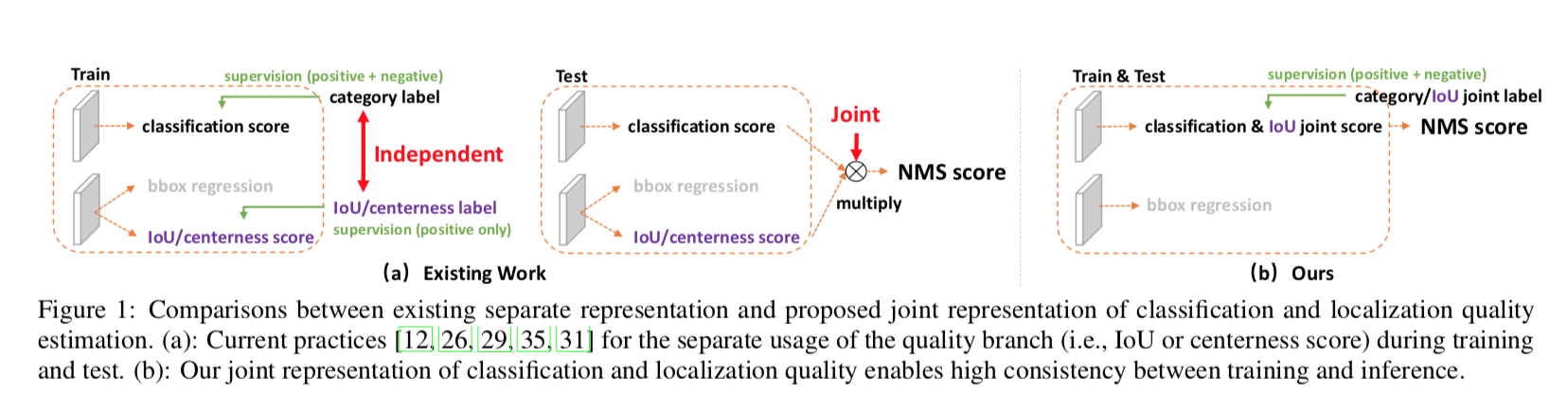
inconsistent usage of localization quality estimation and classification score
- 训练的时候quality和cls branch是independent branch
- box branch的supervision只作用在positive样本上:which is unreliable on predicting negatives
- 测试阶段将quality和cls score乘起来有可能拉高负样本的分数,以至于在NMS阶段把低分正样本挤掉
inflexible representation of bounding boxes
- most method建模成脉冲分布:只在IoU大于一定阈值的格子上有响应,别的格子都是0
- some recent work建模成高斯分布
- in fact the real distribution can be more arbitrary and flexible,连续且不严格镜像
thus we propose
merge the quality representation into the class branch:
- class vector的每个元素代表了格子的localization quality(如IoU score)
在inference阶段也是直接用作cls score
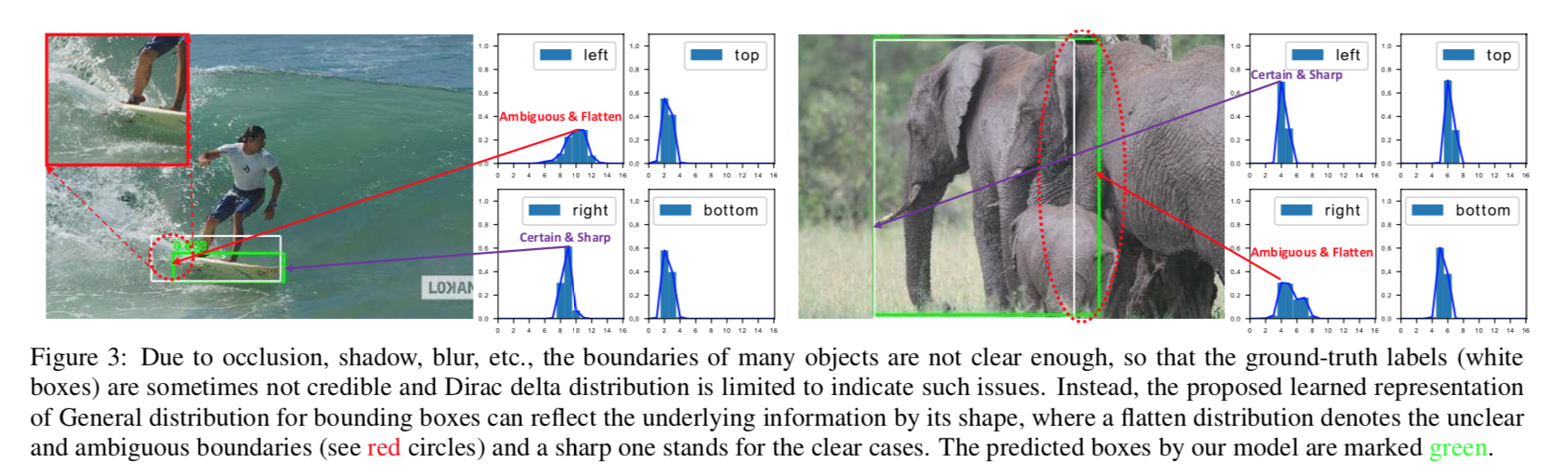
propose arbitrary/general distribution
- 有明确边界的目标的边的分布是比较sharp的
没有明显边界的边分布就是flatten一点
Generalized Focal Loss (GFL)
- joint class representation是continuous IoU label (0∼1)
- imbalance问题仍然存在,但是standart Focal Loss仅支持[0,1] sample
- 修改成continuous形式,同时specialized into Quality Focal Loss (QFL) and Distribution Focal Loss (DFL)
- QFL for cls branch:focuses on a sparse set of hard examples
- DFL for box branch: focus on learning the probabilities of values around the continuous target locations
方法
Focal Loss (FL)
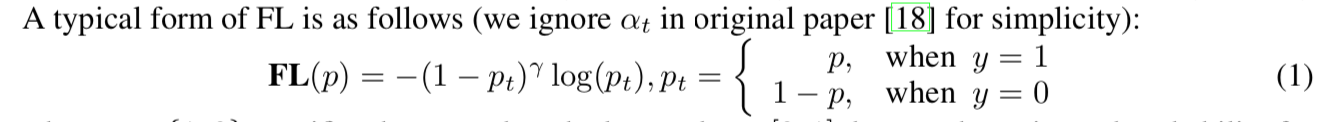
- standard CE part:$-log(p_t)$
- scaling factor:down-weights the easy examples,focus on hard examples
Quality Focal Loss (QFL)
soft one-hot label:正样本在对应类别上有个(0,1]的float score,负样本全0
float score定义为预测框和gt box的IoU score
we adopt multiple binary classification with sigmoid
modify FL
- CE part 改成complete form:$-ylog(\hat y)-(1-y)log(1-\hat y)$
- scaling part用vector distance替换减法:$|y-\hat y |^{\beta}$
$\beta$ controls the down-weighting rate smoothly & $\beta=2$ works best
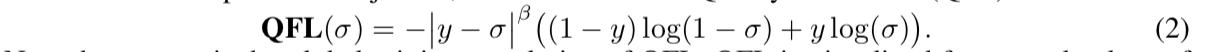
Distribution Focal Loss (DFL)
use relative offsets from the location to the four sides of a bounding box as the regression targets
回归问题formulation
- 连续:$\hat y = \int_{y_0}^{y_n}P(x)xdx$
- 离散化:$\hat y = \sum_{i=0}^n P(y_i)y_i$
- P(x) can be easily implemented through a softmax layer containing n+1 units:
DFL
- force predictions to focus values near label $y$:explicitly enlarge the probabilities of $y_i$和$y_{i+1}$,given $y_i \leq y \leq y_{i+1}$
- $log(S_i)$ force the probabilities
gap balance the 上下限,使得$\hat y$的global mininum solution无限逼近真值$y$,如果真值接近的是$\hat y_{i+1}$,可以看到$log(S_i)$那项被downscale了
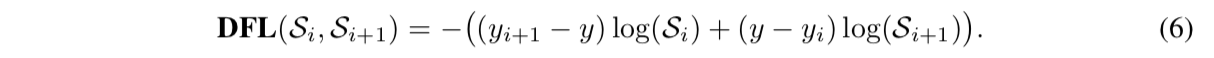
Generalized Focal Loss (GFL)
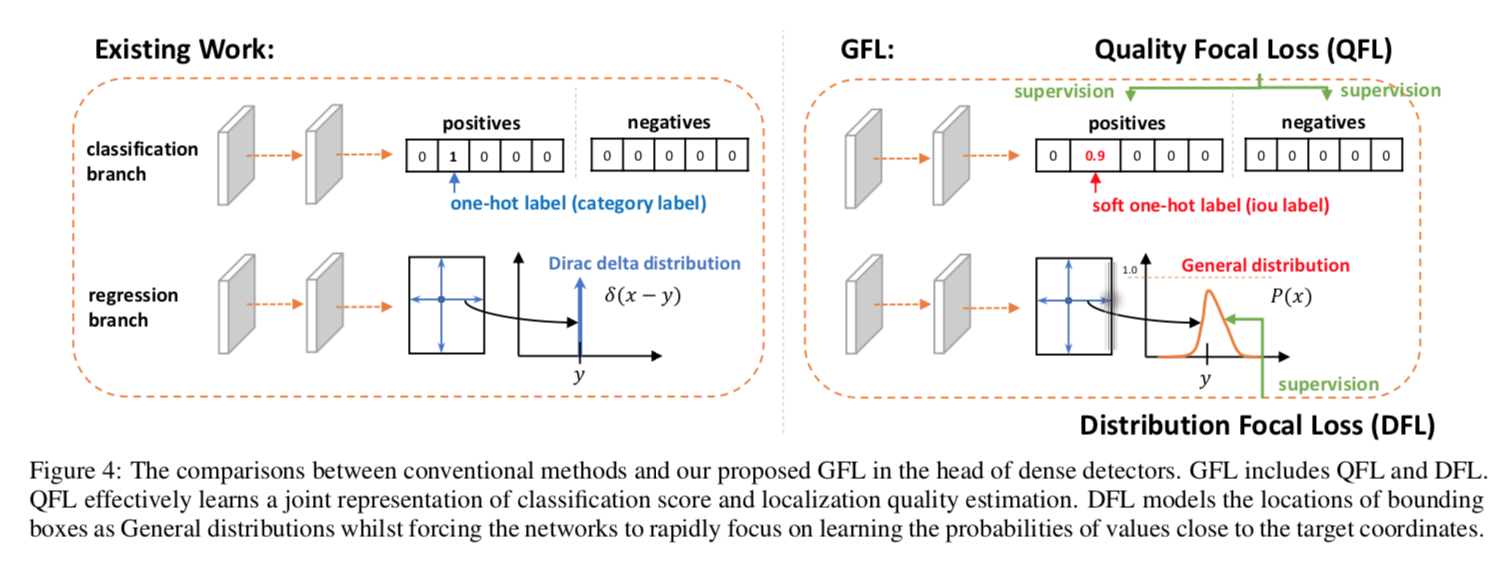
以前的cls preditions在测试阶段要结合quality predictions作为NMS score,现在直接就是
以前regression targets每个回归一个值,现在是n+1个值
overall
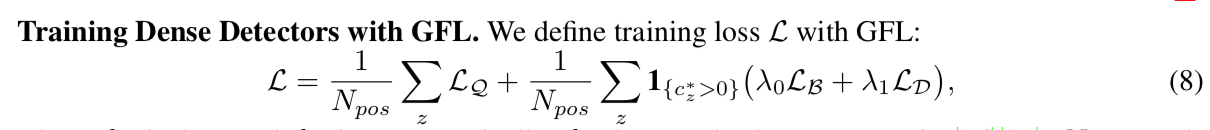
- 第一项cls loss,就是QFL,dense on 所有格子,用正样本数去norm
- 第二项box loss,GIoU loss + DFL,$\lambda_0$默认2,$\lambda_1$默认1/4,只计算有IoU的格子
- we also utilize the quality scores to weight $L_B$ and $L_D$ during training
彩蛋
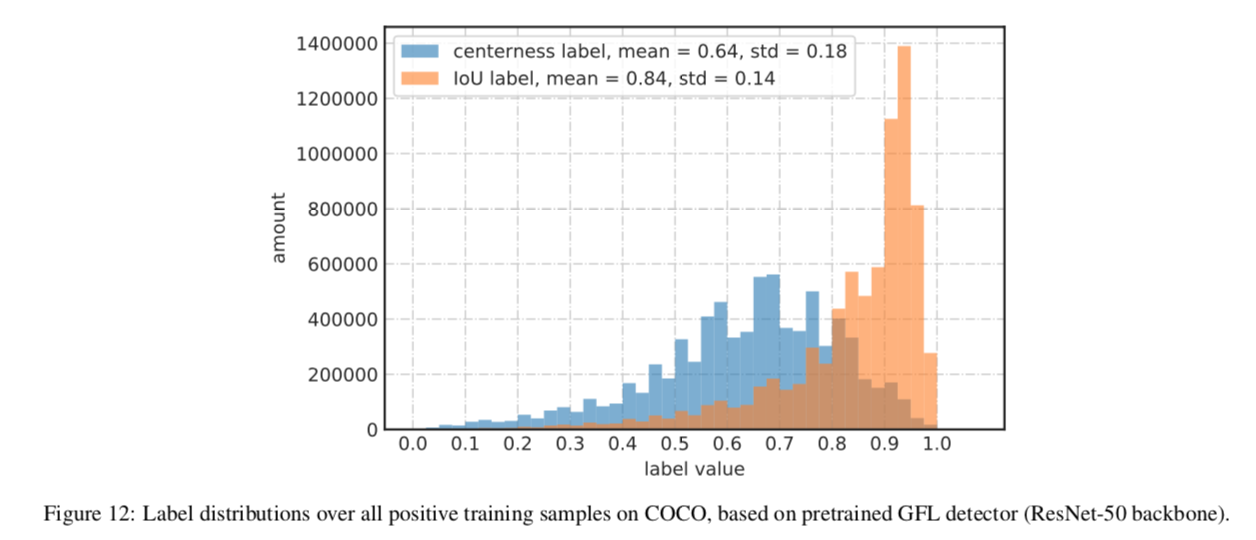
IoU branch always superior than centerness-branch
centerness天生值较小,影响召回,IoU的值较大