综述
few-shot
- few-shot learning:通过少量样本学习识别模型
- 问题:过拟合&泛化性,数据增强和正则能在一定程度上缓解但不解决,还是推荐从大数据上迁移学习
- 共识:
- 样本量有限的情况下,不依靠外部数据很难得到不错的结果,当下所有的解决方案都是借助外部数据作为先验知识,构造学习任务
- 迁移数据也不是随便找的,数据集的domain difference越大,迁移效果越差(e.g. 用miniImagenet做类间迁移,效果不错,但是用miniImagenet做base class用CUB做novel class,学习效果会明显下降)
- 数据集:
- miniImagenet:自然图像,600张,100类
- Omniglot:手写字符,1623张,50类
- CUB:鸟集,11788张,200类,可用于细粒度,可以用于zero-shot
methods
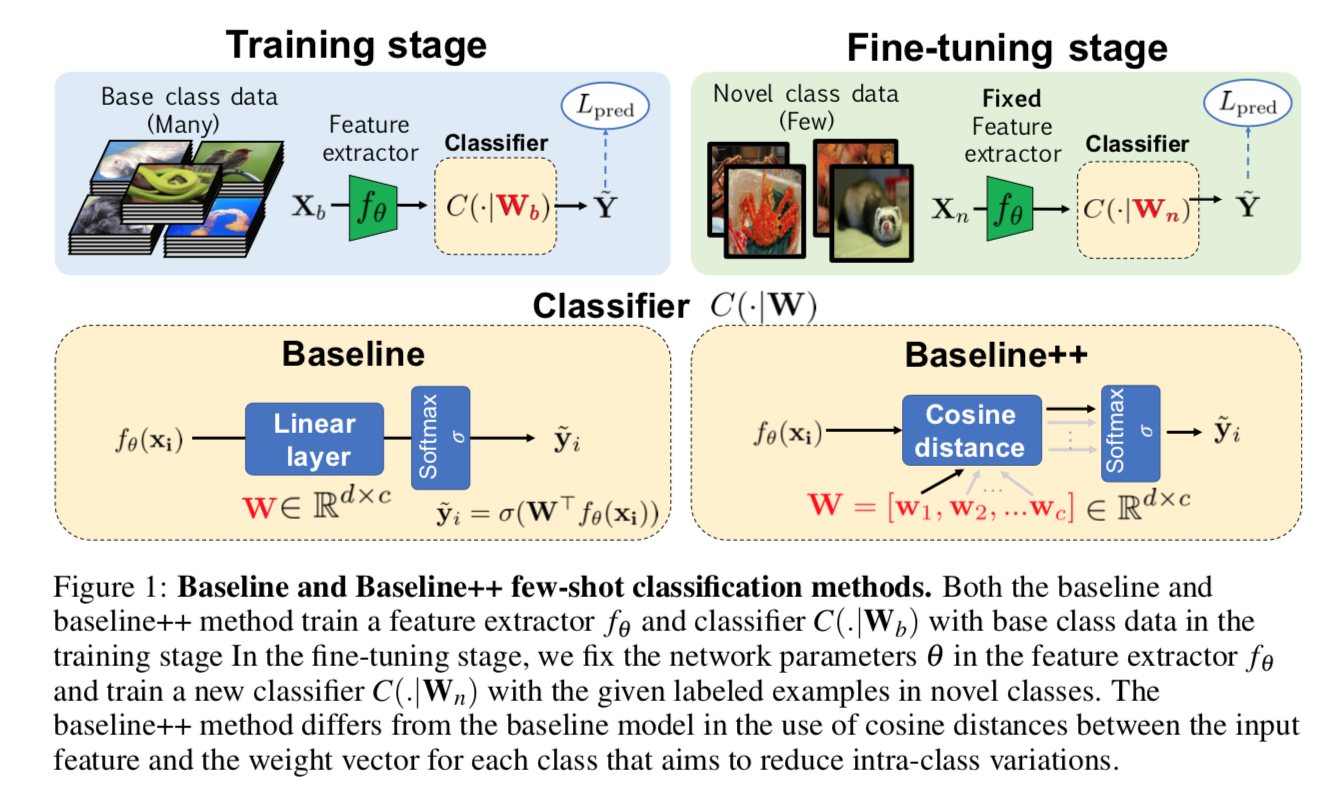
pretraining + finetuning
- pretraining阶段用base class训练一个feature extractor
finetuning阶段fix feature extractor重新训练一个classifier
基于度量学习
- 引入distance metric其实都算度量学习,所以上面(pretraining+finetuning)和下面(meta learning)的方法都有属于度量学习的方法
基于元学习
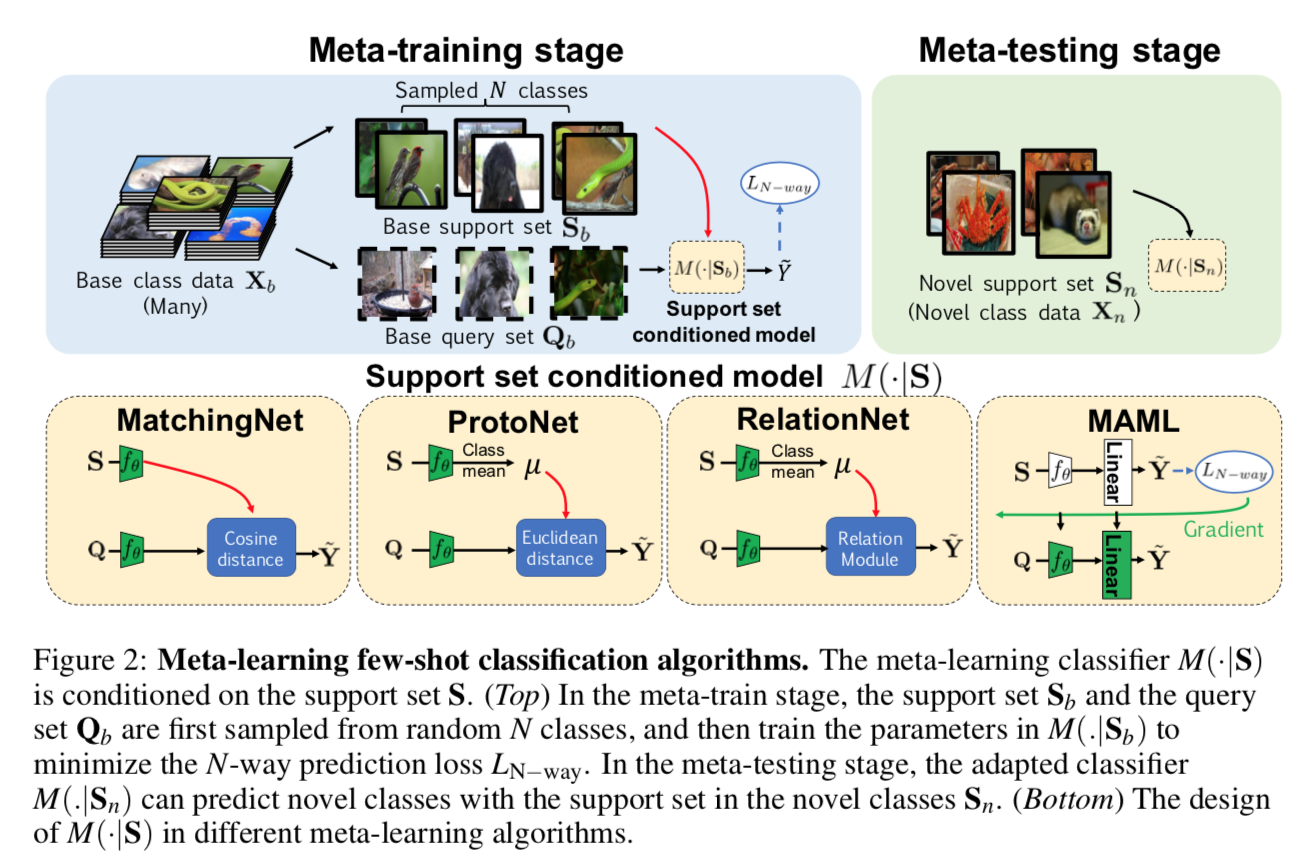
- base class&novel class:base class是已有的大数据集,多类别,大样本量,novel class是我们要解决的小数据集,类别少,每类样本也少
- N-way-K-shot:基于novel class先在base class上构建多个子任务,N-way就是构建随机N个类别的分类任务,K-shot就是每个类别对应样本量为K
supportset S & queryset Q:N-way-K-shot的训练集和测试集,来自base class中相同的类别,均用于training procedure
与传统分类任务对比:


leaderboard:https://few-shot.yyliu.net/miniimagenet.html
papers
- [2015 siamese]:Siamese Neural Networks for One-shot Image Recognition,核心思想就是基于孪生网络构建similarity任务,用一个大数据集构造的same/diff pairs去训练,然后直接用在novel set上,metric是reweighted L1
- [2016 MatchingNet]:Matching Networks for One Shot Learning,本质上也是孪生网络+metric learning,监督的是support set S和test set B的相似度——在S下训练的模型在B的预测结果误差最小,网络上的创新是用了memory&attention,train procedure的创新在于“test and train conditions must match N-way-K-shot”,
- [2017 ProtoNet]:Prototypical Networks for Few-shot Learning,
- [2019 few-shot综述]:A CLOSER LOOK AT FEW-SHOT CLASSIFICATION
Siamese Neural Networks for One-shot Image Recognition
动机
- learning good features is expensive
- when little data is available:一个典型任务one-shot learning
- we desire
- generalize to the new distribution without extensive retraining
- we propose
- train a siamese network to rank similarity between inputs
- capitalize on powerful discriminative features
- generalize the network to new data/new classes
- experiment on
- character recognition
方法
general strategy
- learn image representation:supervised metric-based approach,siamese neural network
reuse the feature extractor:on new data,without any retraining
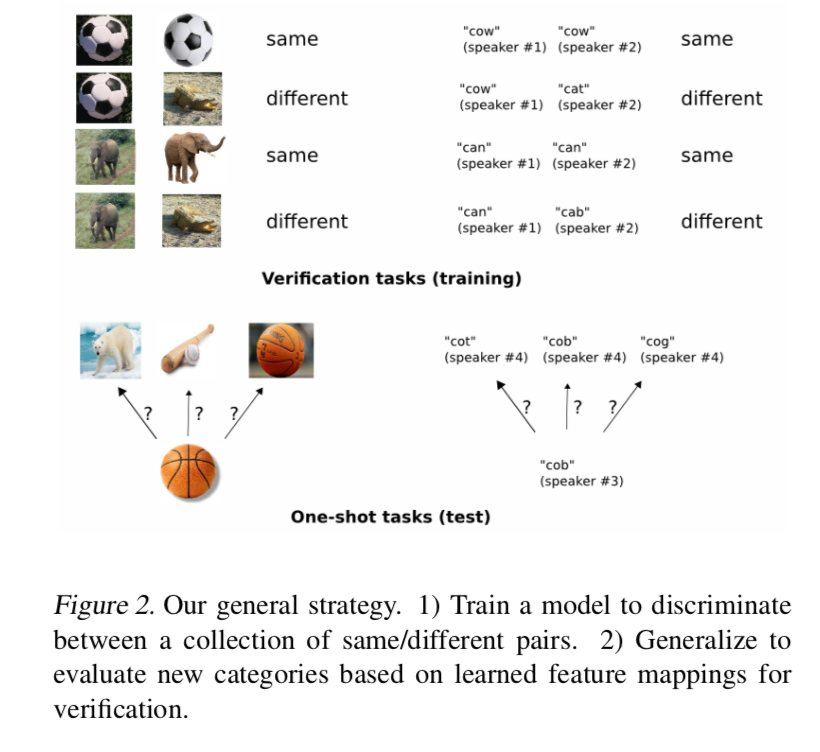
why siamese
- we hypothesize that networks which do well at verification tasks should generalize to one-shot classification
siamese nets
- twin networks accept distinct inputs that are joined by an energy function at the top
- twin back shares the weights:symmetric
- 原始论文用了contrastive energy function:contains dual terms to increase like-pairs energy & decrease unlike-pairs energy
- in this paper we use weighted L1 + sigmoid
model
conv-relu-maxpooling:conv of varying sizes
最后一个conv-relu完了接flatten-fc-sigmoid得到归一化的feature vector
然后是joined layer:计算两个feature vector的L1 distance后learnable reweighting
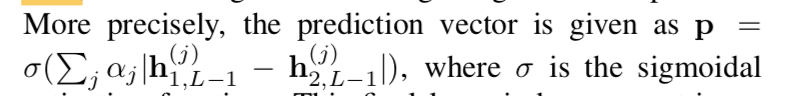
然后接sigmoid
loss
- binary classifier
- regularized CE
- loss function里面加了layer-wise-L2正则
- bp的时候两个孪生网络的bp gradient是additive的
weight initialization
- conv weights:mean 0 & std var 0.01
- conv bias:mean 0.5 & std var 0.01
- fc weights:mean 0 & std var 0.2
- fc bias:mean 0.5 & std var 0.01
learning schedule
- uniform lr decay 0.01
- individual lr rate & momentum
- annealing
augmentation
- individual affine distortions
- 每个affine param的probability 0.5
<img src="few-shot/affine.png" width="45%;" />
实验
- dataset
- Omniglot:50个字母(international/lesser known/fictitious)
- 训练用的子集:60% of the total data,12个drawer创建的30个字母,每类样本数一样多
- validation:4个drawer的10个字母
- test:4个drawer的10个字母
- 8个affine transforms:9倍样本量,same&different pairs
- 在不经过微调训练的条件下,模型直接应用在MNIST数据集,仍有70%的准确率:泛化能力
- dataset
评价
- 孪生网络对于两个图像之间的差异是非常敏感的
- 一只黄色的猫和黄色的老虎之间的差别要比一只黄色的猫和黑色的猫之间的差别更小
- 一个物体出现在图像的左上角和图像的右下角时其提取到的特征信息可能截然不同
- 尤其经过全连接层,空间位置信息被破坏
- 手写字符数据集相比较于ImageNet太简单了
- 优化网络结构:MatchingNet
- 更好的训练策略:meta learning
- 现在去复现已经没啥意义,算是metric learning在小样本学习上的一个startup吧
- 孪生网络对于两个图像之间的差异是非常敏感的
MatchingNet: Matching Networks for One Shot Learning
动机
- learning new concepts rapidly from little data
- employ ideas
- metric learning
- memory cell
- define one-shot learning problems
- Omniglot
- ImageNet
- language tasks
论点
- parametric models learns slow and require large datasets
- non-parametric models rapidly assimilate new examples
- we aim to incorporate both
- we propose Matching Nets
- uses recent advances in attention and memory that enable rapid learning
- test and train conditions must match:如果要测试一个n类的新分布,就要在m类大数据集上训类似的minibatch——抽n个类,每类show a few examples
方法
build one-shot learning within the set-to-set framework
训练以后的模型不需要进一步tuning就能produce sensible test labels for unobserved classes
given a small support set $S=\{(x_i,y_i)\}^k_{i=0}$
train a classifier $c_S$
given a test example $\hat x$:we get a probability distribution $\hat y=c_S(\hat x)$
define the mapping:$S \rightarrow c_S $ to be $P(\hat y| \hat x ,S)$
when given a new support set $S^{‘}=\{\hat x\}$:直接用模型P去预测$\hat y$就可以了
simplest form:
- a是attention mechanism:如果和测试样本$\hat x$最远的b个支持样本$x_i$的attention是0,其余为一个定值,这就等价于一个k-b-NN机制
- $y_i$ act as memories:可以把每个$y_i$看作是每个$x_i$提取到的信息保存成memory
workflow定义:given a input,我们基于attention锁定corresponding samples in the support set,并retrieve the label
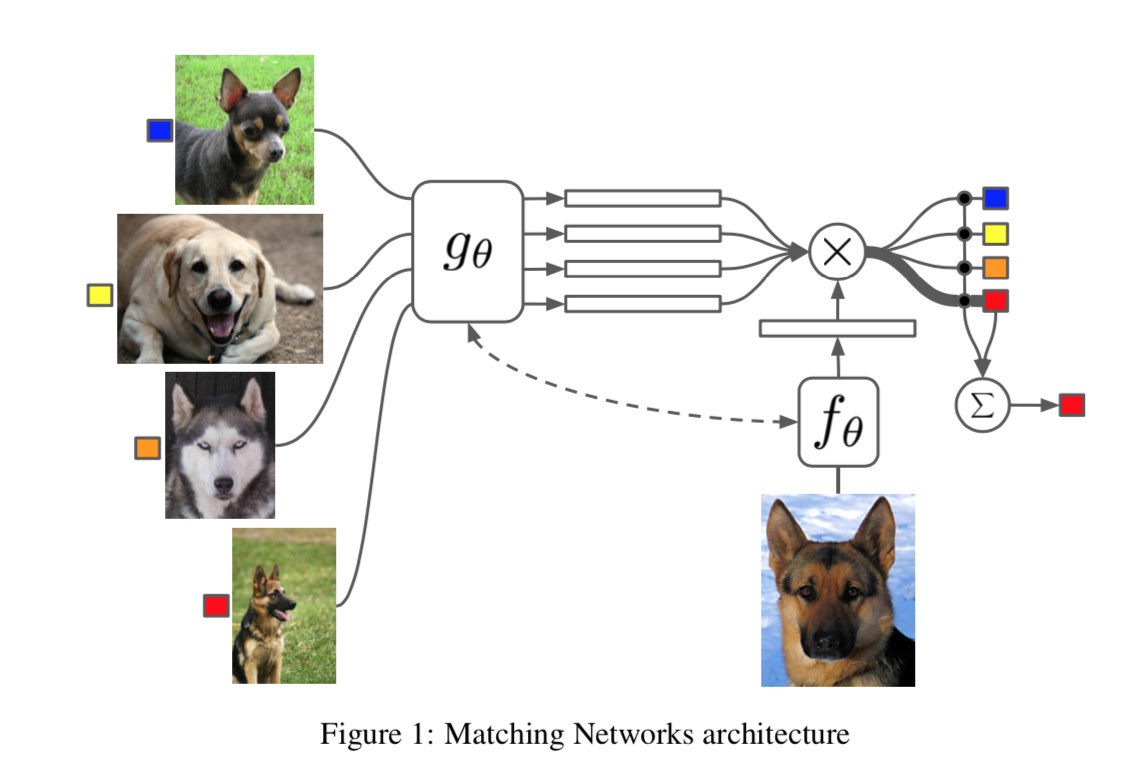
attention kernel
- 用一个embedding function先将$\hat x$和$x_i$转化成embeddings
- 然后计算和每个$x_i$ embedding的cosine distance
- 然后softmax,得到每个的attention value
- softmax之后的attention value,大部分是N选1,如果每个attention value都不高,说明query sample和训练集每类都不像,是个novel
Full Context Embeddings(FCE)
简单的模式下f和g就是两个shared weights的CNN feature extractor,FCE是接在常规feature vector后面精心设计的一个结构
设计思路
- g:support set don’t get embedded individually
- f:support set modify how we embed the test image
the first issue:
bidirectional Long-Short Term Memory
encoder the whole support set as contexts,each time step的输入是$g^{‘}(x_i)$
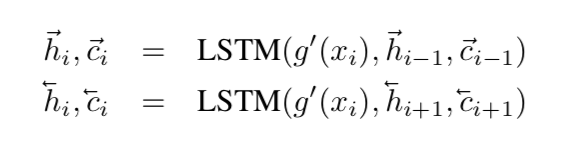
skip connection
the second issue
LSTM with read attention over the whole set S
$f(\hat x, S)=attLSTM(f^{‘}(\hat x), g(S), K)$
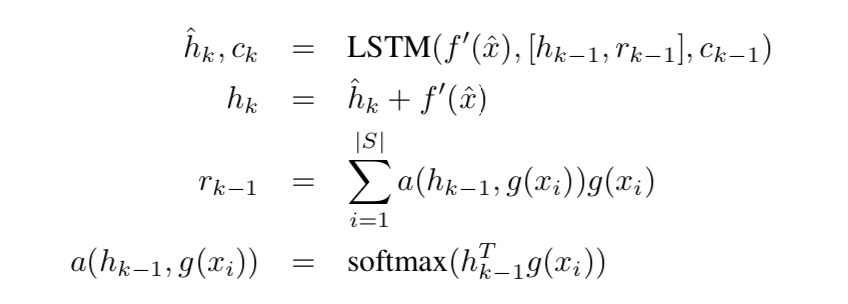
$f^{‘}(\hat x)$是query sample的feature vector,作为LSTM each time step的输入
$K$是fixed number of unrolling steps,限制LSTM计算的step,也就是feature vector参与LSTM循环计算的次数,最终的输出是$h_K$
skip connection as above
support set S的引入:
- content based attention + softmax
- $r_{k-1}$和$h_{k-1}$是concat到一起,作为hidden states:【QUESTION】这样lstm cell的hidden size就变了啊???
attention of K fixed unrolling steps
encode $x_i$ in the context of the support set S
training strategy
- the training procedure has to be chosen carefully so as to match the never seen
- task define:从全集中选取few unique classes(e.g. 5),每个类别选取few examples(e.g. 1-5),构成support set S,再从对应类别抽一个batch B,训练目标就是minimise the error predicting the labels in the batch B conditioned on the support set S
batch B的预测过程就是figure1:需要$g(S(x_i,y_i))$和$f(\hat x)$计算$P(\hat y|\hat x, S)$,然后和$gt(\hat y)$计算log loss
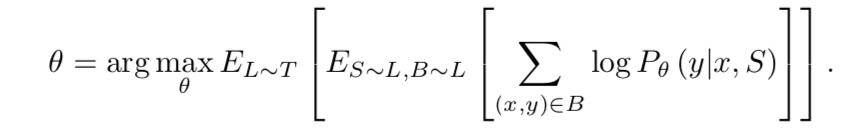
实验
模式
- N-way-K-shot train
- one-shot test:用唯一的one-shot novel sample生成对应类别的feature vector,然后对每个test sample计算cosine distance,选择最近的作为其类别
comparing methods
- baseline classifier + NN
- MANN
- Convolutional Siamese Net + NN
- further finetuning:one-shot
- 结论
- using more examples for k-shot classification helps all models
- 5-way is easier than 20-way
- siamese net在5-shot的时候跟our method差不多,但是one-shot degrades rapidly
- FCE在简单数据集(Omniglot)上没啥用,在harder task(miniImageNet)显著提升
A CLOSER LOOK AT FEW-SHOT CLASSIFICATION
动机
- 为主流方法提供一个consistent comparative analysis,并且发现:
- deeper backbones significantly reduce differences
- reducing intra-class variation is an important factor when shallow backbone
- propose a modified baseline method
- achieves com- petitive performance
- verified on miniImageNet & CUB
- in realistic cross-domain settings
- generalization analysis
- baseline method with standard fine-tuning win
- 为主流方法提供一个consistent comparative analysis,并且发现:
论点
three main categories of methods
- initialization based
- aims to learn good model initialization
- to achieve rapid adaption with a limited number of training samples
- have difficulty in handling domain shifts
- metric learning based
- 训练目标是learn to compare
- if a model can determine the similarity of two images, it can classify an unseen input image with the labeled instances:本质是similarity计算器,脱离label level
- 花式训练策略:meta learning/graph
- 花式距离metric:cosine/Euclidean
- turns out大可不必:
- a simple baseline method with a distance- based classifier is competitive to the sophisticated algorithms
- simply reducing intra-class variation in a baseline method leads to competitive performance
- hallucination based
- 用base class训练一个生成模型,然后用生成模型给novel class造假数据
- 通常和metric-based模型结合起来用,不单独分析
- initialization based
two main challenges 没法统一横向比较
- implementation details有差异,baseline approach被under-estimated:无法准确量化the relative performance gain
- lack of domain shift between base & novel datasets:makes the evaluation scenarios unrealistic
- our work
- 针对代表性方法conduct consistent comparative experiments on common ground
- discoveries on deeper backbones
- 轻微改动baseline method获得显著提升
- replace the linear classifier with distance-based classifier
- practical sceneries with domain shift
- 发现这种现实场景下,那些代表性的few-shot methods反而干不过baseline method
- open source code:https://github.com/wyharveychen/CloserLookFewShot
- 针对代表性方法conduct consistent comparative experiments on common ground
方法
- baseline
- standard transfer learning:pre-training + fine-tuning
- training stage
- train a feature extractor $f_{\theta}$ and a classifier $C_{W_b}$
- use abundant base class labeled data
- standard CE loss
- fine-tuning stage
- fix feature extractor $f_{\theta}$
- train a new classifier $C_{W_n}$
- use the few labeled novel samples
- standard CE loss
- baseline++
- variant of the baseline:唯一的不同就在于classifier design
- 显式地reduce intra-class varation among features during training,和center loss思路有点像,但是center loss的质心是滑动平均的,这里面的质心是learnable的
- training stage
- write the weight matrix $W_b$ as $[w_1, w_2, …, w_c]$,类似每类的簇心
- for an input feature,compute cosine similarity
- multiply a class-wise learnable scalar to adjust origin [-1,1] value to fit softmax
- 然后用softmax对similarity vector进行归一化,作为predict label
- the softmax function prevents the learned weight vectors collapsing to zeros:每类的预测distance都是0是网络比较容易陷入的局部最优解
- 【in fine-tuning stage??】
- meta-learning algorithms
- three distance metric based methods:MatchingNet,ProtoNet,RelationNet
- one initialization based method:MAML
- meta-training stage
- a collection of N-way-K-shot tasks
- 使得模型$M(*|S)$学会的是一种学习模式——在有限数据下做预测
- meta-testing stage
- 所有的novel data都作为对应类别的support set
- (class mean)
- 模型就用这个新的support set来进行预测
- Different meta-learning methods主要区别在于如何基于support set做预测,也就是classifier的设计
- MatchingNet计算的是query和support set的每个cosine distance,然后mean per class
- ProtoNet是先对support features求class mean,然后Euclidean distance
- RelationNet先对support features求class mean,然后将距离计算模块替换成learnable relation module
- baseline
实验
three scenarios
- generic object recognition:mini-ImageNet,100类,600张per class,【64-base,16-val,20-novel】
- fine-grained image classification:CUB-200-2011,200类,总共11,788张,【random 100-base,50-val,50-novel】
- cross-domain adaptation:mini-ImageNet —> CUB,【100-mini-ImageNet-base,50-CUB-val,50-CUB-test】
training details
- baseline和baseline++模型:train 400 epochs,batch size 16
- meta learning methods:
- train 60000 episodes for 5-way-1-shot tasks,train 40000 episodes for 5-way-5-shot tasks
- use validation set to select the training episodes with the best acc
- k-shot for support set,16 instances for query set
- Adam with 1e-3 initial lr
- standard data augmentation:crop,left-right flip,color jitter
testing stage
- average over 600 experiments
- each experiment randomly choose 5-way-k-shot support set + 16 instances query set
- meta learning methods直接基于support set给出对query set的预测结果
- baseline methods基于support set训练一个新的分类头,100 iterations,batch size 4
模型details
- baseline++的similarity乘上了class-wise learnable scalar
- MachingNet用了FCE classification layer without fine-tuning版本,也乘了class-wise learnable scalar
- RelationNet将L2 norm替换成softmax加速训练
- MAML使用了一阶梯度近似for efficiency
初步结果
4-layer conv backbone
input size 84x84
origin和re-implementation的精度对比
- 原始的baseline没加data augmentation,所以过拟合了精度差,被underestimated了
- MatchingNet加了那个scalar shift的改进以后精度有显著提升
ProtoNet原论文是20-shot&30-shot,本文主要比较1-shot和5-shot,精度都放出来了
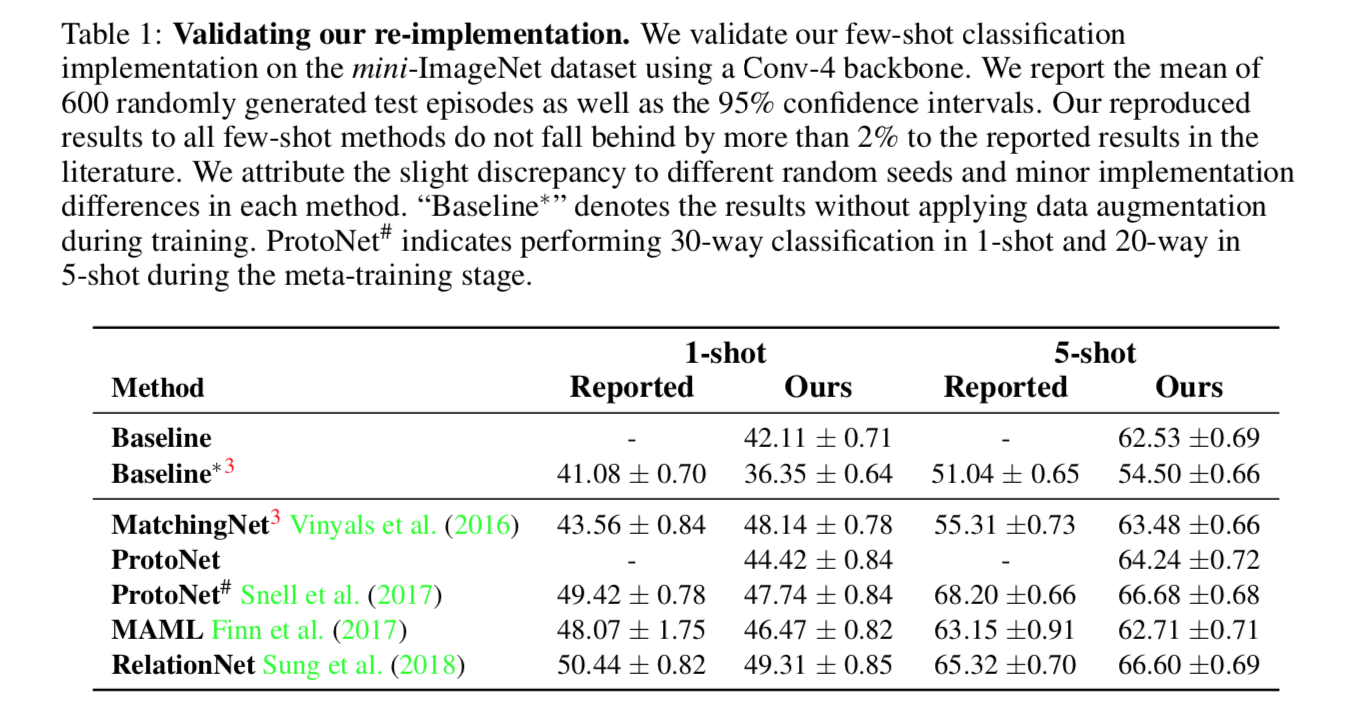
our experiment setting下各模型的精度对比
- baseline++大幅提升精度,已经跟meta learning methods差不多了
- 说明few-shot的key factor是reduce intra-class variation
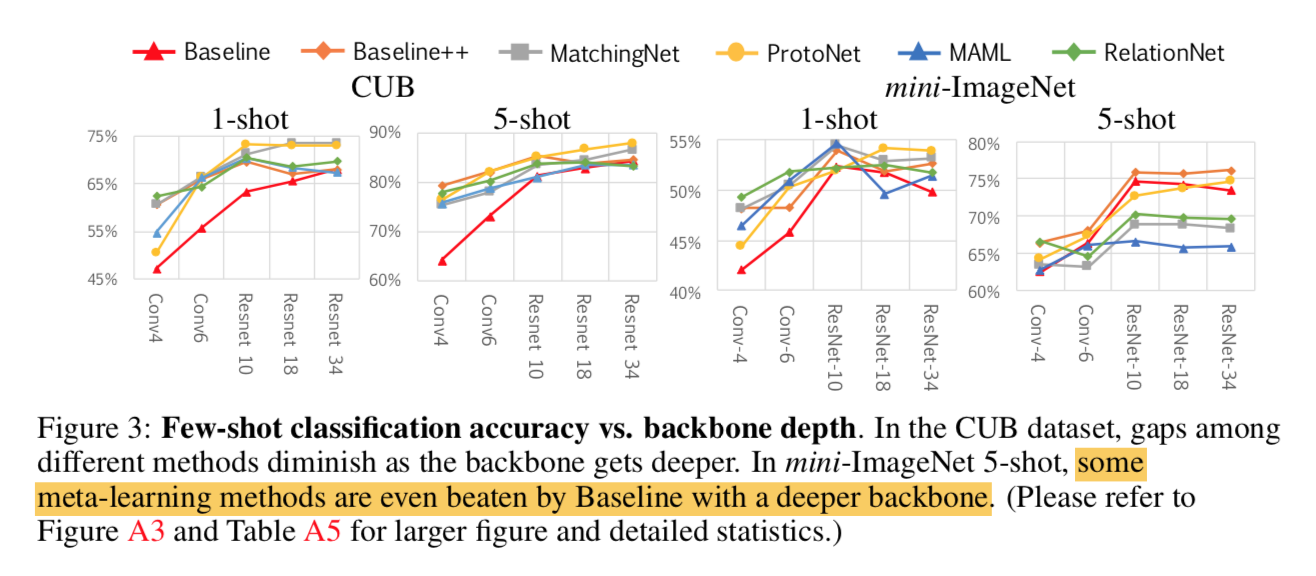
但是要注意的是这是在4-layer-conv的backbone setting下,deeper backbone can inherently reduce intra-class variation
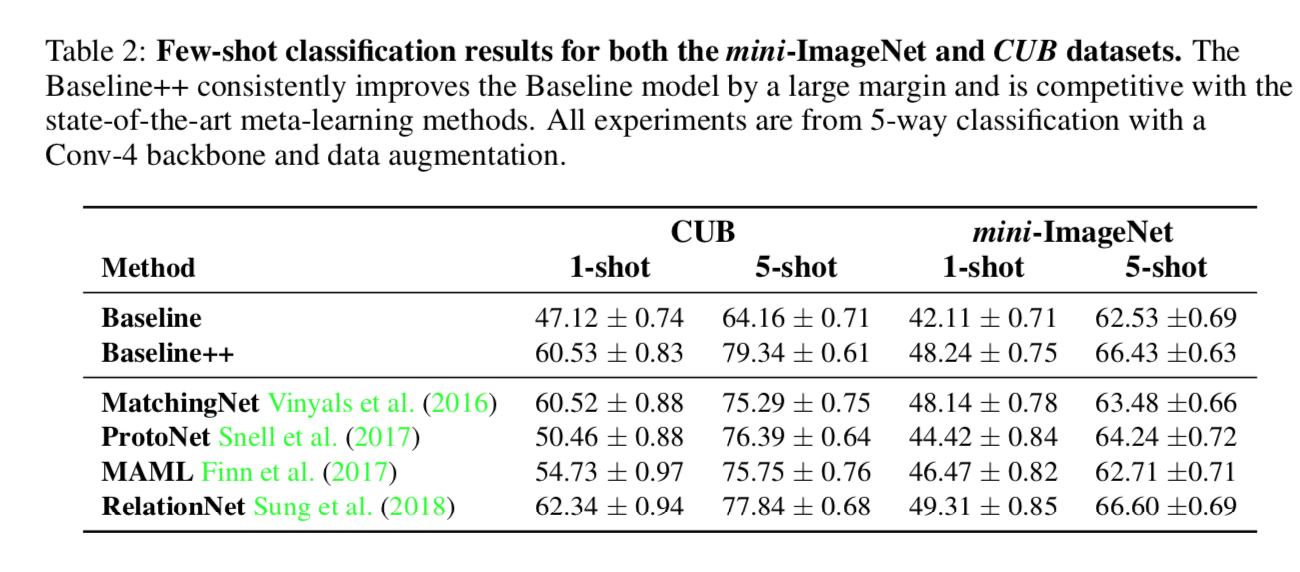
增加网络深度
- 上面说了,deeper backbone能够隐式地降低类内距离
- deeper models
- conv4
- conv6:相对于conv4那个模型,加了两层conv blocks without pooling
- resnet10:简化版resnet18,r18里面conv block的两层卷积换成一层
- resnet18:origin paper
- resnet34:origin paper
随着网络加深,各方法的精度差异缩小,baseline方法甚至反超了一些meta learning方法
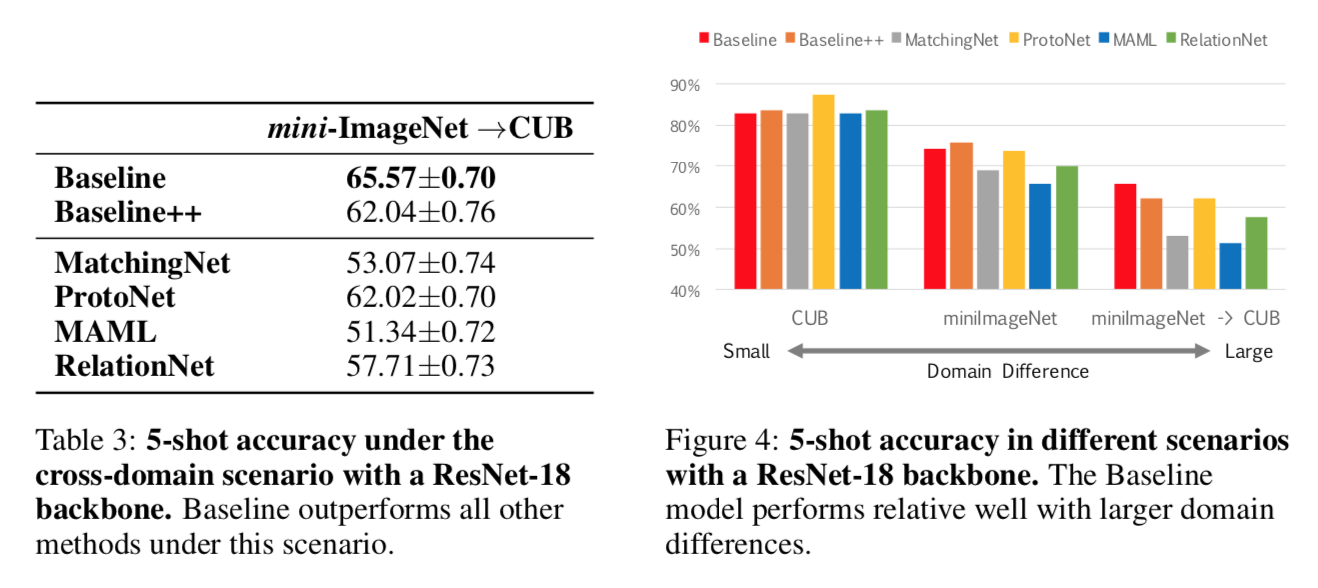
effect of domain shift
- 一个现实场景:mini-ImageNet —> CUB,收集general class data相对容易,收集fine-grained数据集则更困难
- 用resnet18实验
- Baseline outperforms all meta-learning methods under this scenario
- 因为meta learning methods的学习完全依赖于base support class,not able to adapt
- 随着domain difference get larger,Baseline相对于其他方法的gap也逐渐拉大
说明了在domain shift场景下,adaptation based method的必要性
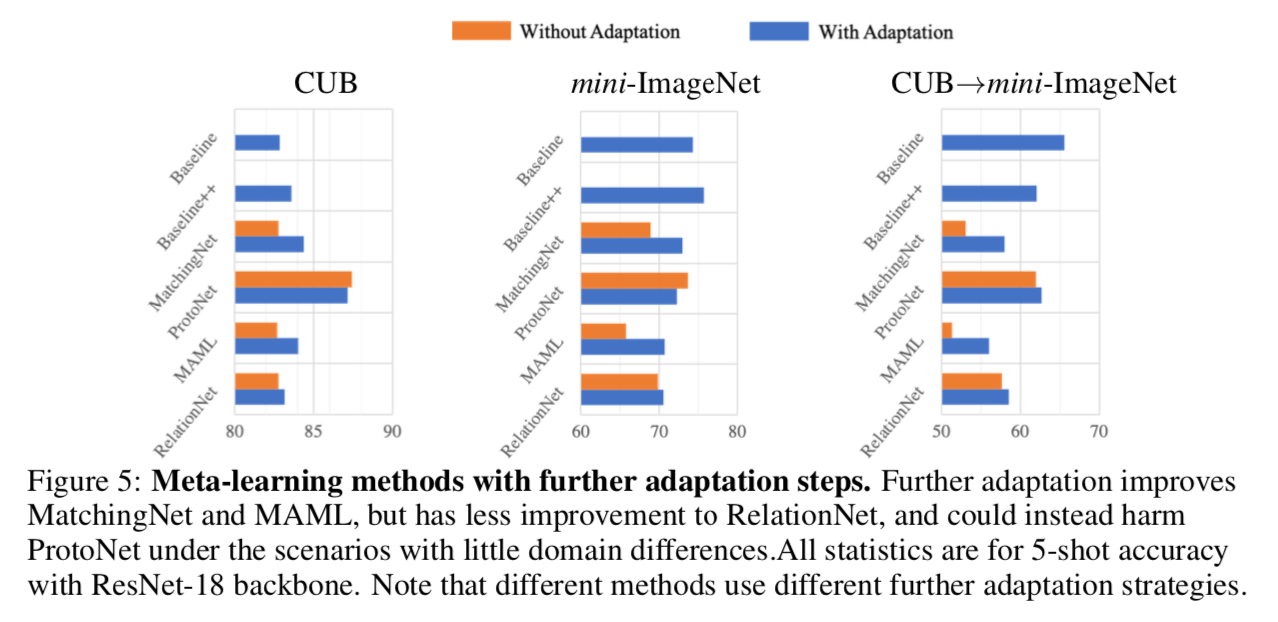
further adapt meta-learning methods
- MatchingNet & ProtoNet:跟baseline方法一样,fix feature extractor,然后用novel set train a new classifier
- MAML:not feasible to fix the feature,用novel set finetune整个网络
- RelationNet:features是conv maps而不是vector,randomly split一部分novel set作为训练集
MatchingNet & MAML都有大幅精度提升,尤其在domain shift场景下,但是ProtoNet会掉点,说明adaptation是影响精度的key factor,但是还没有完美解决方案