ATSS: Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
动机
- anchor-based和anchor-free方法的本质区别是对正负样本的定义,这也直接导致了performance gap
- we propose ATSS
- adaptive training sample selection
- automatically select positive and negative samples according to statistical characteristics of objects
- anchor-based&anchor-free模型上都涨点
- discuss tiling multiple anchors
论点
- 主流anchor-based方法
- one-stage/two-stage
- tile a large number of preset anchors on the image
- output these refined anchors as detection results
- anchor-free detectors主要分成两种
- key-point based:预测角点/轮廓点/heatmap,然后bound轮廓得到框
- center-based:预测中心点,然后基于中心点回归4个距离
- 消除pre-defined anchors的hyper-params:强化generalization ability
- 举例对比RetinaNet&FCOS
- RetinaNet:one-stage anchor-based
- FCOS:center-based anchor-free
- 主要区别1:anchor数量,RetinaNet是hxwx9,FCOS是hxwx1
- 主要区别2:正样本定义,RetinaNet是与gt box的IOU大于一定阈值的anchor,FCOS是featuremap上所有落进框内的格子点
- 主要区别3:回归方式,RetinaNet是回归gt相对pos anchor的相对偏移量,FCOS是预测四条边相对中心点的绝对距离
- 主流anchor-based方法
Difference Analysis of Anchor-based and Anchor-free Detection
we focus on the last two differences:正负样本定义 & 回归starting status
设定RetinaNet也是one square anchor per location,和FCOS保持一致
experiment setting
- MS COCO:80类前景,common split
- ImageNet pretrained ResNet-50
- resize input
- SGD,90K iterations,0.9 momentum,1e-4 weight decay,16 batch size,0.01 lr with 0.1 lr decay/60K
- testing:
- 0.05 score to filter out bg boxes
- output top 1000 detections per feature pyramid
- 0.6 IoU thresh per class NMS to give final top 100 detections per image
inconsistency removal
- 五大improvements加在FCOS上进一步boost the gap
我们将其逐步加在RetinaNet上,能够拉到37%,和FCOS还有0.8个点的差距
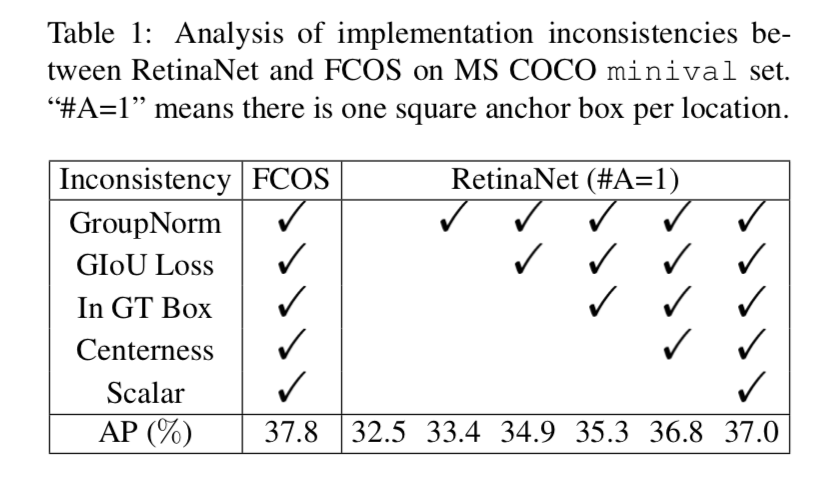
分析essential difference
训练一个检测模型,首先要分出正负样本,然后用正样本来回归
Classification
- RetinaNet用anchor boxes与gt box的IoU决定正负样本:best match anchor和大于一定IoU thresh的anchor是正样本,小于一定IoU thresh的anchor是负样本,其他的是ignore样本
FCOS用spatial and scale constraints选择正负样本:gt box以内的所有像素作为候选正样本,然后去掉部分尺度不匹配的候选样本,正样本以外都是负样本,没有ignore
两个模型在两种样本选择策略上实验:Spatial and Scale Constraint相比较于IoU都会显著提点
当两种方法都使用Spatial and Scale Constraint策略选择正负样本,模型精度就没啥差别了

Regression
- RetinaNet regresses from the anchor box with 4 offsets:回归gt box相对于anchor box的偏移量,regression starting status是个box
FCOS regresses from the anchor point with 4 distances:回归gt box四条边相对于anchor center的距离,regression starting status是个point
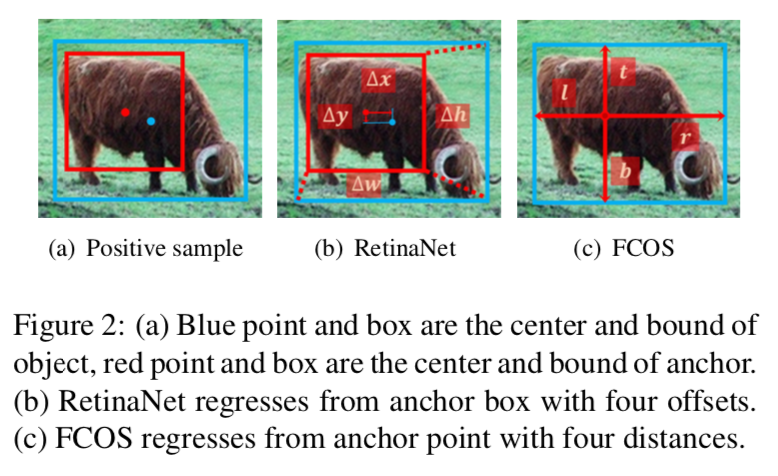
上面那个表说明了选择同样的正负样本,regression starting status就是个无关项,不影响精度
Adaptive Training Sample Selection (ATSS)
影响检测模型精度的essential difference在于how to define positive and negative training samples
previous strategies都有sensitive hyperparameters(anchors/scale),some outer objects may be neglected
we propose ATSS
- almost no hyper
divides pos/neg samples according to data statistical characteristics

对每个gt box,首先在每个level上,基于L2 center distance,找到k-closest anchor——k*L个candidates per gt box
- 计算每个candidates的mean & var
- 基于mean & var 计算这个gt box的IoU thresh
- 在candidates里面选取大于等于IoU thresh,同时anchor center在gt box内的,留作正样本
- 如果一个acnhor box匹配了多个gt box,选择IoU大的那个作为标签
基于center distance选择anchor box:因为越靠近目标中心,越容易produce高品质框
用mean+var作为IoU thresh:
- higher mean indicates high-quality candidates,对应的IoU thresh应该高一点
- higher variation indicates level specific,mean+var作为thresh能将candidates里面IoU较高的筛选出来
limit the anchor center in object:anchor中心不在目标框内显然不是个好框,用于筛掉前两步里的漏网之鱼,双保险
fair between different objects
- 统计下来每类目标都有差不多0.2kL个正样本,与尺度无关
- 但是RetinaNet和FCOS都是大目标正样本多,小目标正样本少
hyperparam-free:只有一个k,【还有anchor-setting呢???】
verification
- lite version:被FCOS官方引用并称作center sampling,scale limit still exists in this version
- full version:本文版本
两个方法选择candidates的方法完全一致,就是select final postives的方法不同
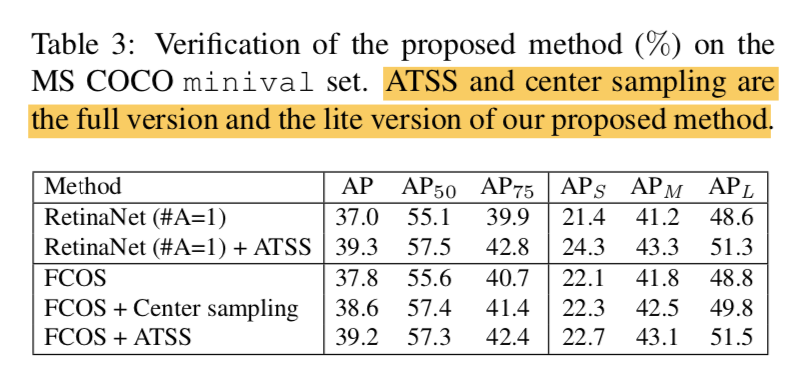
hyperparam的鲁棒性
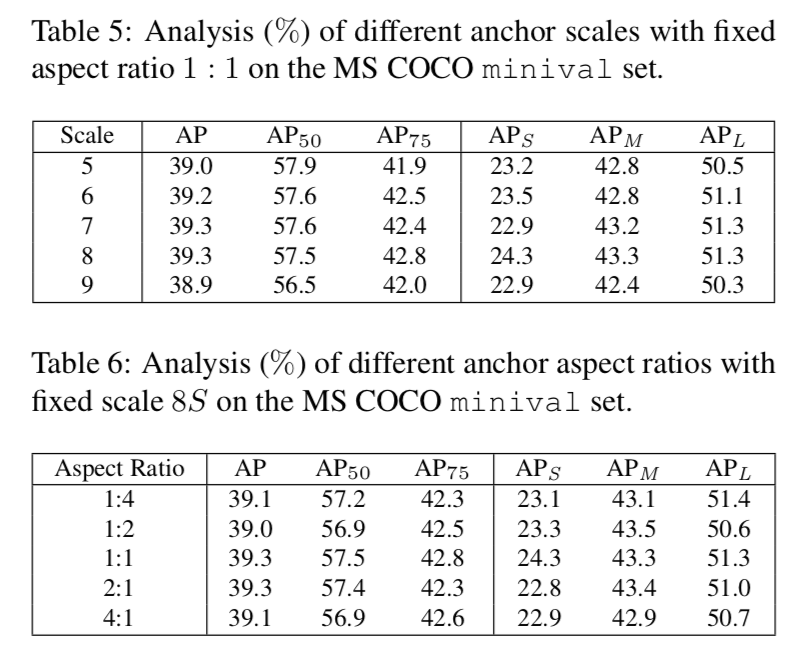
k在一定范围内(7-17)相对insensitive,太多了低质量框太多,太少了less statistical

尝试不同的fix-ratio anchor scale和fix-scale anchor ratio,发现精度相对稳定,说明robust to anchor settings
multi-anchors settings
RetinaNet在不同的anchor setting下,精度基本不变,说明主要正样本选的好,不管一个location绑定几个anchor结果都一样