papers:
[2019 MoCo v1] Momentum Contrast for Unsupervised Visual Representation Learning,kaiming
[2020 SimCLR] A Simple Framework for Contrastive Learning of Visual Representations,Google Brain,混进来是因为它improve based on MoCo v1,而MoCo v2/v3又都是基于它改进
[2020 MoCo v2] Improved Baselines with Momentum Contrastive Learning,kaiming
[2021 MoCo v3] An Empirical Study of Training Self-Supervised Visual Transformers,kaiming
preview: 自监督学习 Self-supervised Learning
reference:https://ankeshanand.com/blog/2020/01/26/contrative-self-supervised-learning.html
overview
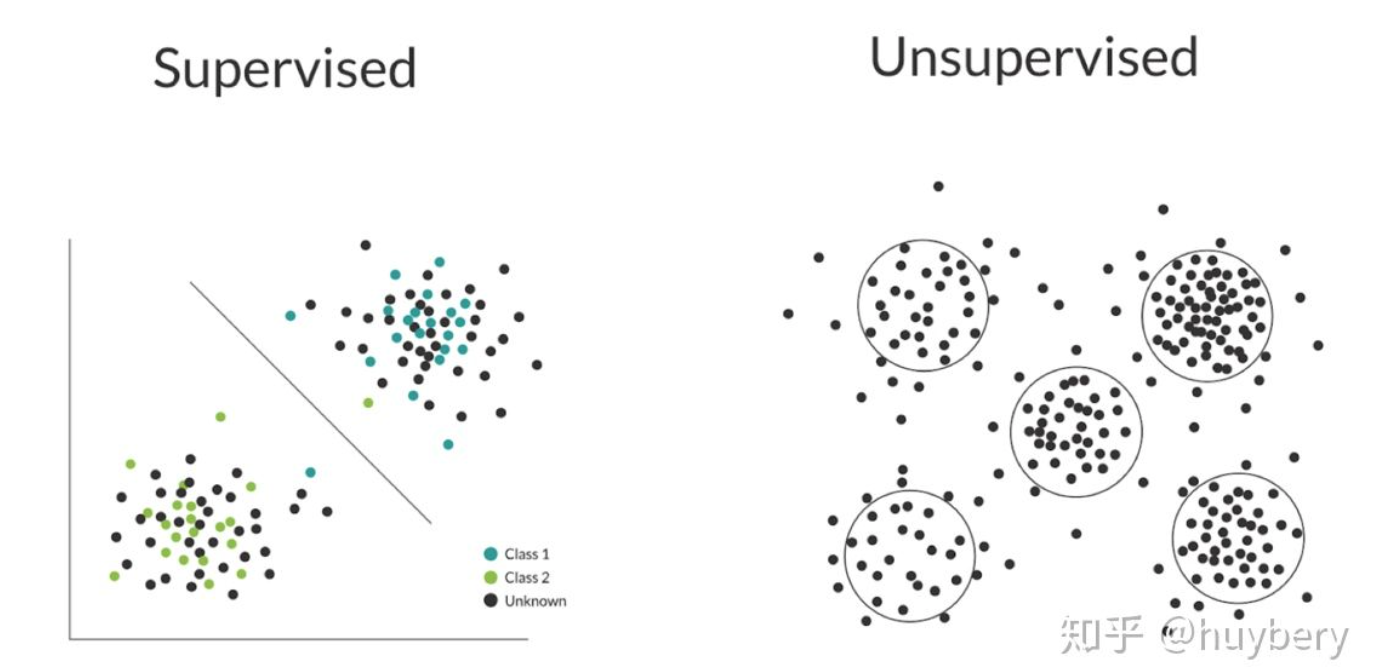
- 就是无监督
- 针对的痛点(有监督训练模型)
- 标注成本高
- 迁移性差
- 会基于数据特点,设置Pretext tasks(最常见的任务就是生成/重建),构造Pesdeo Labels来训练网络
- 通常模型用来作为其他学习任务的预训练模型
- 被认为是用来学习图像的通用视觉表示
methods
从结构上区分主要就是两大类方法
- 生成式:通过encoder-decoder结构还原输入,监督信号是输入输出尽可能相似
- 重建任务开销大
- 没有建立直接的语义学习
- 外加GAN的判别器使得任务更加复杂难训
- 判别式:输入两张图片,通过encoder编码,监督信号是判断两张图是否相似,判别式模型也叫Contrastive Learning
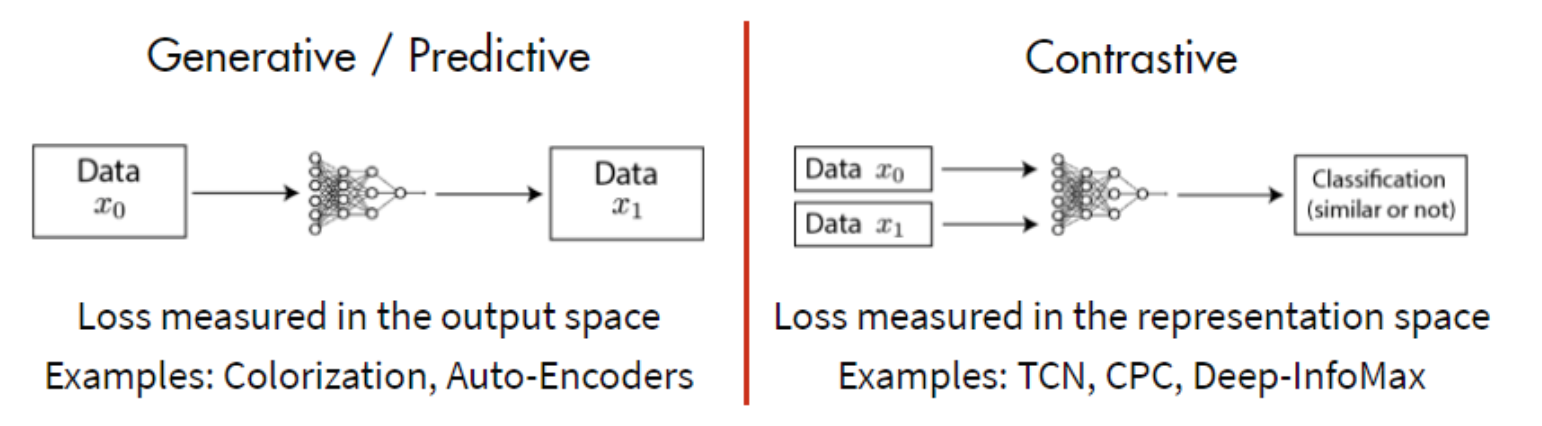
- 生成式:通过encoder-decoder结构还原输入,监督信号是输入输出尽可能相似
从Pretext tasks上划分主要分为三类
- 基于上下文(Context based) :如bert的MLM,在句子/图片中随机扣掉一部分,然后推动模型基于上下文/语义信息预测这部分/相对位置关系
- 基于时序(Temporal Based):如bert的NSP,视频/语音,利用相邻帧的相似性,构建不同排序的序列,判断B是否是A的下一句/是否相邻帧
- 基于对比(Contrastive Based):比较正负样本,最大化相似度的loss在这里面被叫做InfoNCE
memory-bank
- Contrastive Based方法最常见的方式是在一个batch中构建正负样本进行对比学习
- end-to-end
- 每个mini-batch中的图像增强前后的两张图片互为正样本
- 字典大小就是minibatch大小
- memory bank包含数据集中所有样本编码后特征
- 随机采样一部分作为keys
- 每个迭代只更新被采样的样本编码
- 因为样本编码来自不同的training step,一致性差
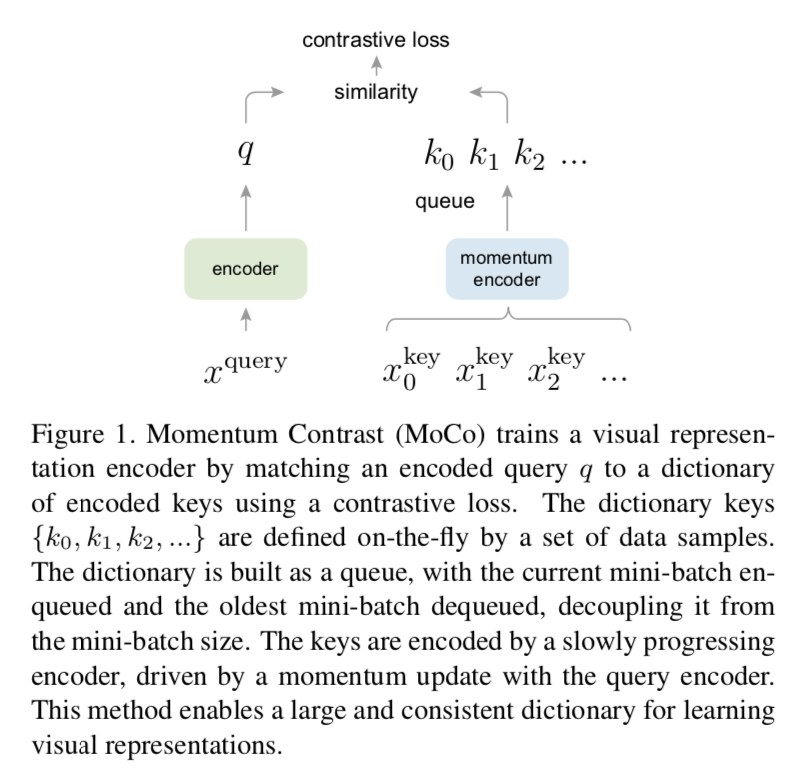
MoCo
- 动态编码库:out-of-date的编码出列
- momentum update:一致性提升
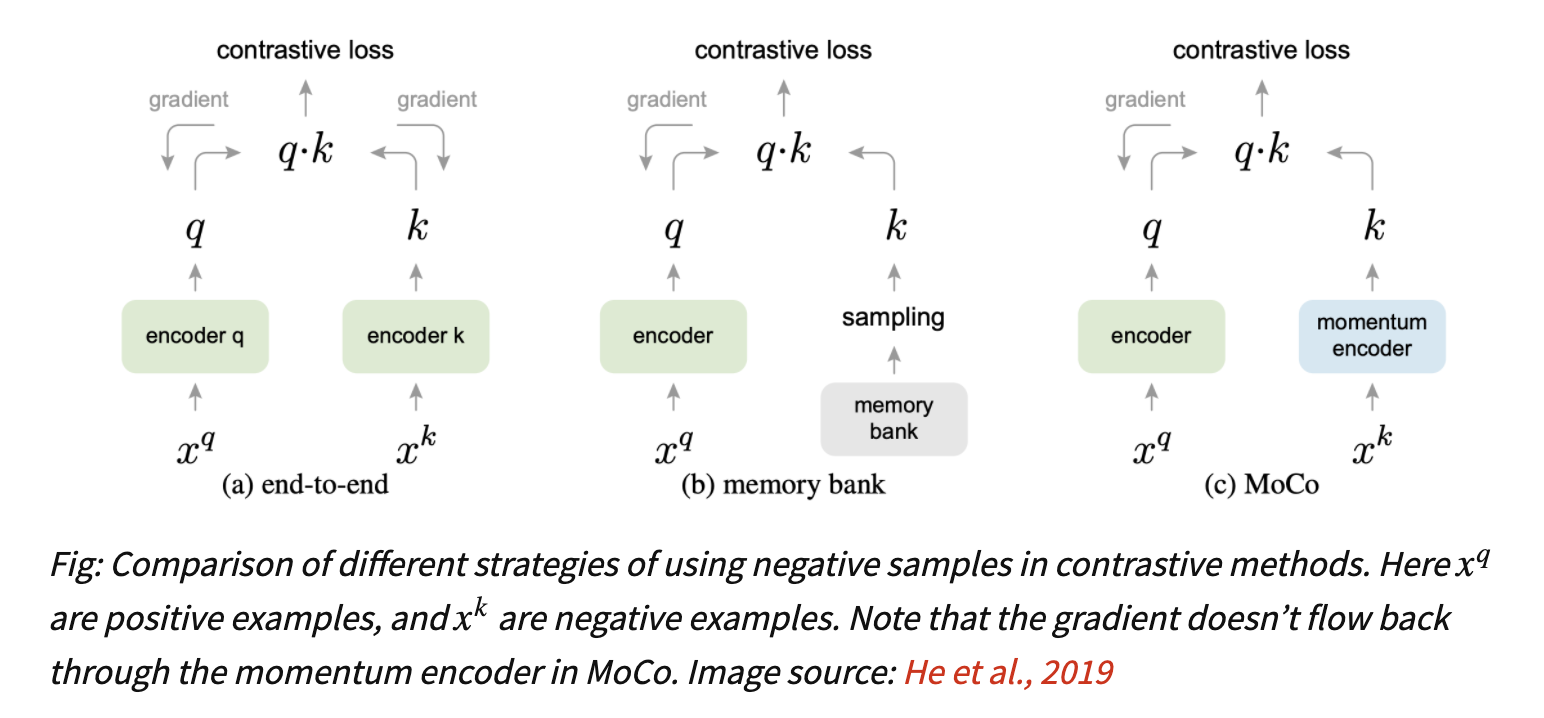
- Contrastive Based方法最常见的方式是在一个batch中构建正负样本进行对比学习
InfoNCE
deep mind在CPC(Contrastive Predictive Coding)提出,论文以后有机会再展开
- unsupervised
- encoder:encode x into latent space representations z,resnet blocks
- autoregressive model:summarize each time-step set of {z} into a context representation c,GRUs
probabilistic contrastive loss
- Noise-Contrastive Estimation
- Importance Sampling
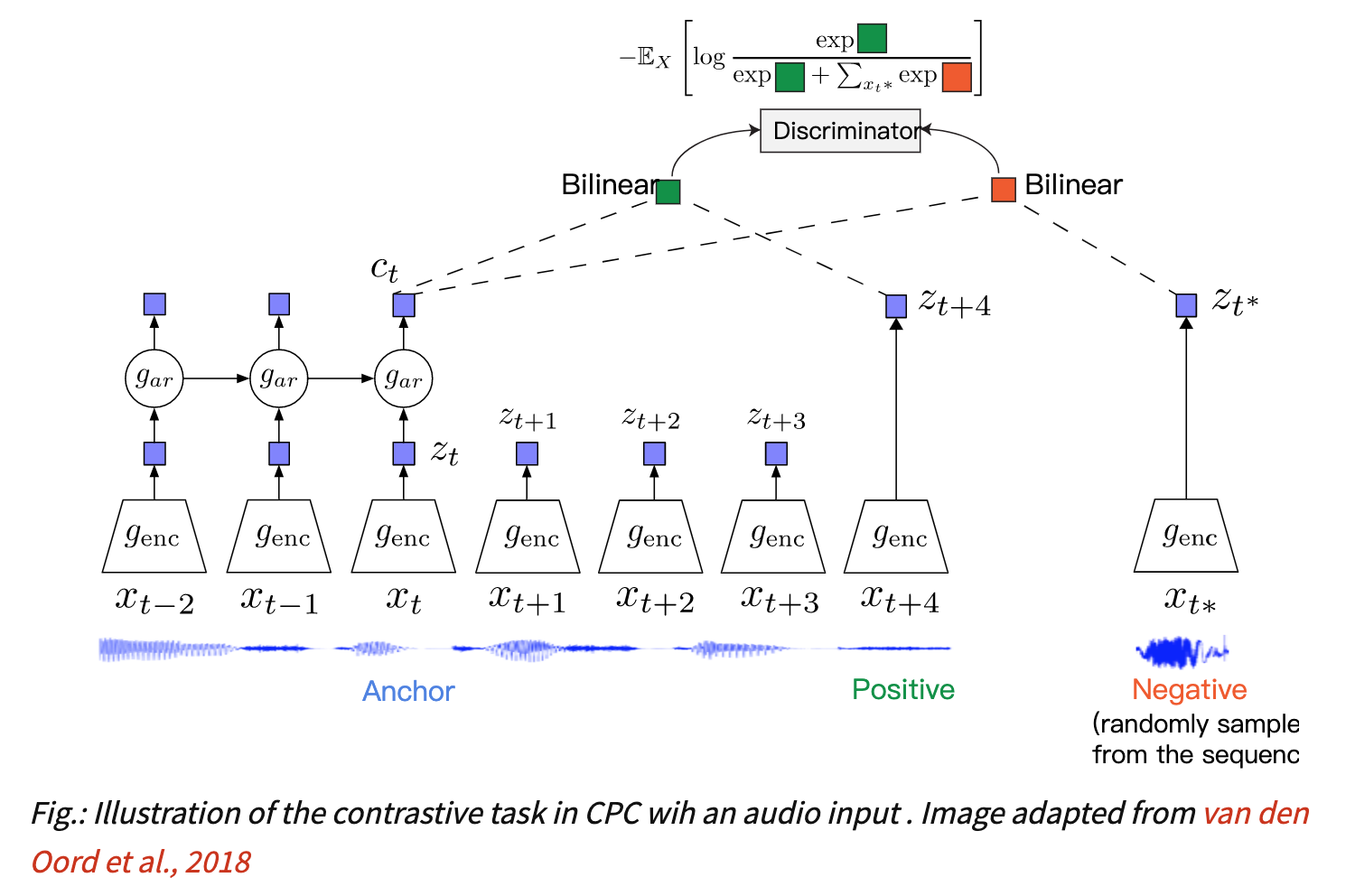
训练目标是输入数据x和context vector c之间的mutual information
- 每次从$p(x_{t+k}|c_t)$中采样一个正样本:正样本是这个序列接下来预测的东西,和c的相似性肯定要高于不想干的token
- 从$p(x_{t+k})$中采样N-1个负样本:负样本是别的序列里面随机采样的东西
目标是让正样本与context相关性高,负样本低
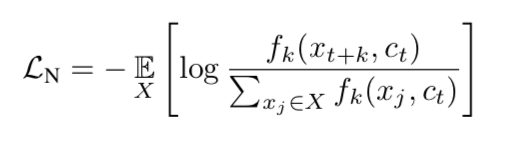
MoCo v1: Momentum Contrast for Unsupervised Visual Representation Learning
动机
- unsupervised visual representation learning
- contrastive learning
dynamic dictionary
- large
- consisitent
verified on
- 7 down-stream tasks
- ImageNet classification
- VOC & COCO det/seg
论点
Unsupervised representation learning
- highly successful in NLP,in CV supervised is still the main-stream
- 两个核心
- pretext tasks
- loss functions
- loss functions
- 生成式方法的loss是基于prediction和一个fix target来计算的
- contrastive-based的key target则是vary on-the-fly during training
- Adversarial losses没展开
- pretext tasks
- tasks involving recover:auto-encoder
- task involving pseudo-labels:通常有个exemplar/anchor,然后计算contrastive loss
- contrastive learning VS pretext tasks
- 大量pretext tasks可以通过设计一些contrastive loss来实现
recent approaches using contrastive loss
- dynamic dictionaries
- 由keys组成:sampled from data & represented by an encoder
- train the encoder to perform dictionary look-up
- given an encoded query
- similar to its matching key and dissimilar to others
- dynamic dictionaries
desirable dictionary
- large:better sample
- consistent:training target consistent
MoCo:Momentum Contrast
- queue
- 每个it step的mini-batch的编码入库
- the oldest are dequeued
EMA:
- a slowly progressing key encoder
- momentum-based moving average of the query encoder
similar的定义:q & k are from the same image
方法
contrastive learning
- a encoded query $q$
- a set of encoded samples $\{k_0, k_1, …\}$
- assume:there is a single key $k_+$ in the dictionary that $q$ matches
- similarity measurement:dot product
- InfoNCE:
- $L_q = -log \frac{exp(qk_+/\tau)}{\sum_0^K exp(qk/\tau)}$
- 1 positive & K negtive samples
- 本质上是个softmax-based classifier,尝试将$q$分类成$k_+$
- unsupervised workflow
- with a encoder network $f_q$ & $f_k$
- thus we have query & sample representation $q=f_q(x^q)$ & $k=f_k(x^k)$
- inputs $x$ can be images/patches/context(patches set)
- $f_q$ & $f_k$ can be identical/partially shared/different
momentum contrast
dictionary as a key
- the dictionary always represents a sampled subset of all data
- the current mini-batch入列
- the oldest mini-batch出列
momentum update
large dictionary没法对keys进行back-propagation:因为sample太多了
only $f_q$ are updated by back-propagation:mini-batch
naive solution:copy $f_q$的参数给$f_k$,yields poor results,因为key encoder参数变化太频繁了,representation inconsistent issue
momentum update:$f_k = mf_k + (1-m)f_q$,$m=0.999$
三种更新方式对比
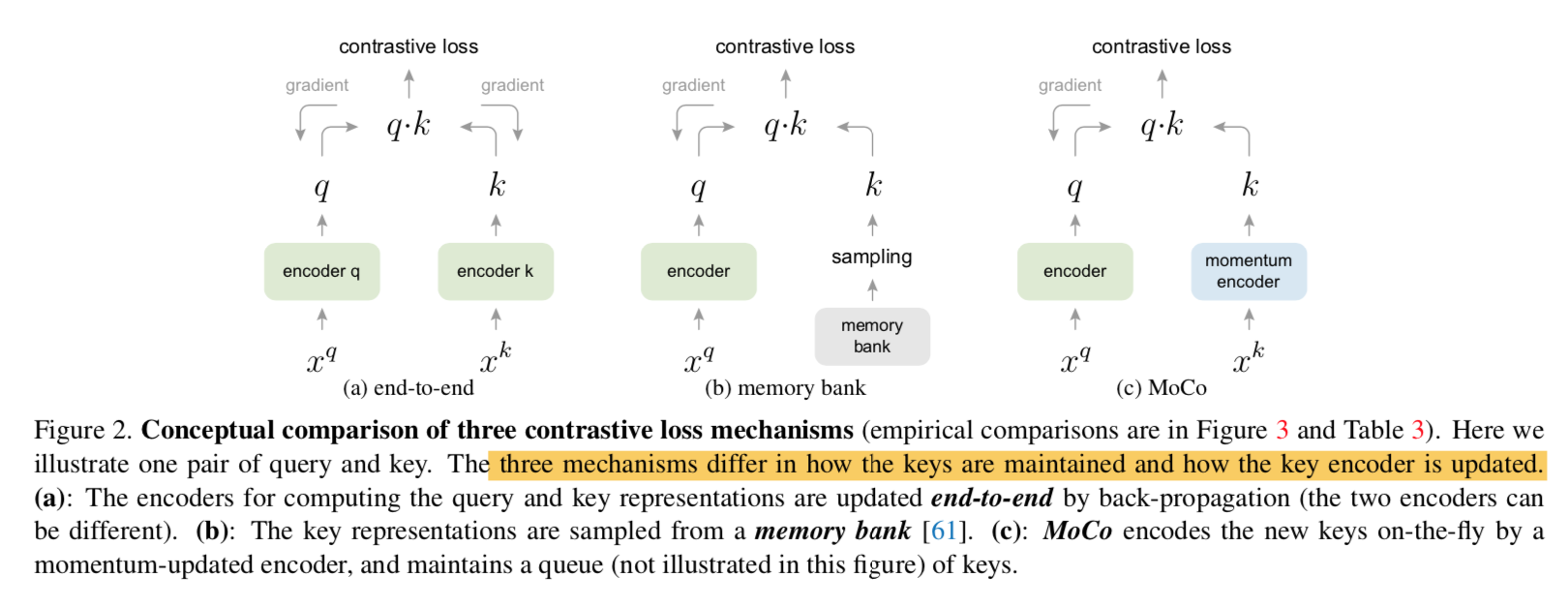
- 第一种end-to-end method:
- use samples in current mini-batch as the dictionary
- keys are consistently encoded
- dictionary size is limited
- 第二种memory bank
- A memory bank consists of the representations of all samples in the dataset
- the dictionary for each mini-batch is randomly sampled from the memory bank,不进行bp,thus enables large dictionary
- key representation is updated when it was last seen:inconsistent
- 有些也用momentum update,但是是用在representation上,而不是encoder参数
- 第一种end-to-end method:
pretext task
- define positive pair:if the query and the key come from the same image
- 我们从图上take two random views under random augmentation to form a positive pair
- 然后用各自的encoder编码成q & k
- 每一对计算similarity:pos similarity
- 然后再计算input queries和dictionary的similarity:neg similarity
- 计算ce,update $f_q$
- 用$f_q$ update $f_k$
- 把k加入dictionary队列
把最早的mini-batch出列

技术细节
- resnet:last fc dim=128,L2 norm
- temperature $\tau=0.07$
- augmentation
- random resize + random(224,224) crop
- random color jittering
- random horizontal flip
- random grayscale conversion
- shuffling BN
- 实验发现使用resnet里面的BN会导致不好的结果:猜测是intra-batch communication引导模型学习了一种cheating的low-loss solution
- 具体做法是给$f_k$的输入mini-batch先shuffle the order,然后进行fp,然后再shuffle back,这样$f_q$和$f_k$的BN计算的mini-batch的statics就是不同的
实验
SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
动机
- simplify recently proposed contrastive self-supervised learning algorithms
- systematically study the major components
- data augmentations
- learnable unlinear prediction head
- larger batch size and more training steps
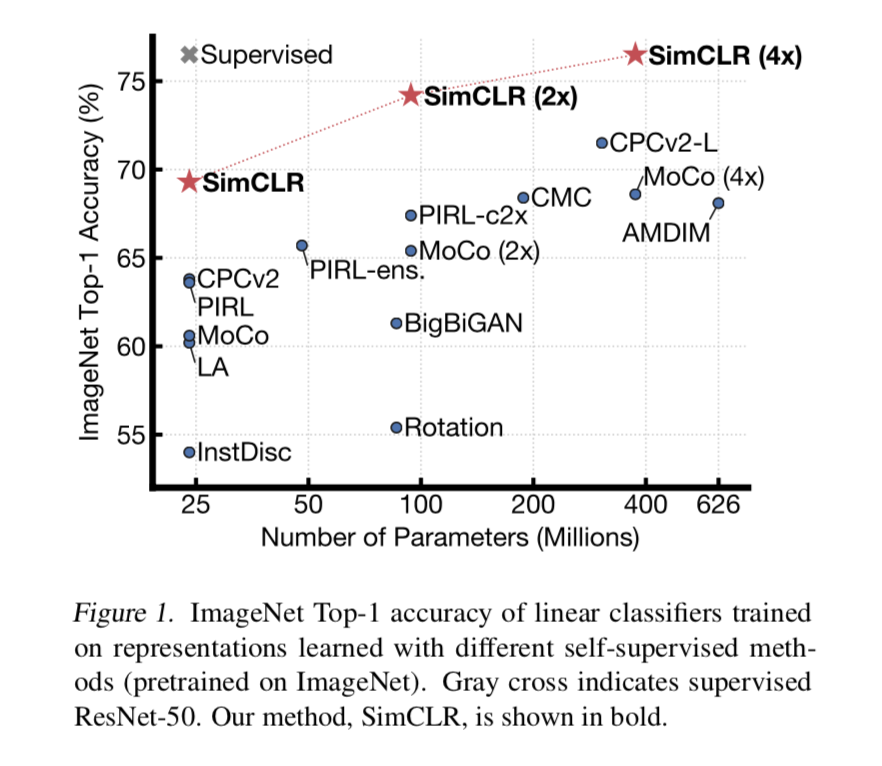
outperform previous self-supervised & semi-supervised learning methods on ImageNet
论点
discriminative approaches based on contrastive learning
- maximizing agreement between differently augmented views of the same data sample
- via a contrastive loss in the latent space
major components & conclusions
- 数据增强很重要,unsupervised比supervised benefits more
- 引入的learnable nonlinear transformation提升了representation quality
- contrastive cross entropy loss受益于normalized embedding和adjusted temperature parameter
- larger batch size and more training steps很重要,unsupervised比supervised benefits more
方法
common framework
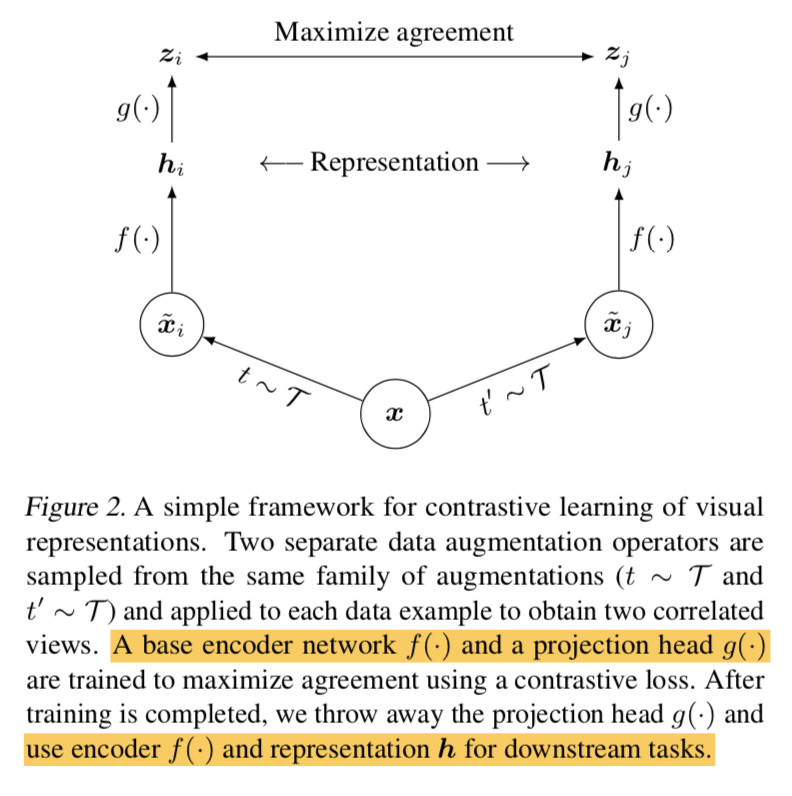
4 major components
- 随机数据增强
- results in two views of the same sample,构成positive pair
- crop + resize back + color distortions + gaussian blur
- base encoder
- 用啥都行,本文用了resnet including the GAP
- a projection head
- 将representation dim映射到the space where contrastive loss is applied(given 1 pos pair & N neg pair,就是N+1 dim)
- 之前有方法直接用linear projection
- 我们用了带一个hidden layer的MLP:fc-bn-relu-fc
- a contrastive loss
- 随机数据增强
overall workflow
- random sample a minibatch of N
- random augmentation results in 2N data points
- 对每个样本来讲,有1个positive pair,其余2(N-1)个data points都是negative samples
- set cosine similarity $sim(u,v)=u^Tv/|u||v|$
- given positive pair $(i,j)$ then the loss is $l_{i,j} = -log \frac{exp(s_{i,j}/\tau)}{\sum_{k\neq i}^{2N} exp(s_{i,k}/\tau)}$
- 对每个positive pair都计算,包括$(i,j)$ 和$(j,i)$,叫那个symmetrized loss
update encoder

training with large batch size
- batch 8192,negatives 16382
- 大batch时,linear learning rate scaling可能不稳定,所以用了LARS optmizer
- global BN,aggregate BN mean & variance over all devices
- TPU
MoCo v2: Improved Baselines with Momentum Contrastive Learning
动机
- still working on contrastive unsupervised learning
- simple modifications on MoCo
- introduce two effective SimCLR’s designs:
- an MLP head
- more data augmentation
- requires smaller batch size than SimCLR,making it possible to run on GPU
- verified on
- ImageNet classification
- VOC detection
论点
- MoCo & SimCLR
- contrastive unsupervised learning frameworks
- MoCo v1 shows promising
- SimCLR further reduce the gap
- we found two design imrpovements in SimCLR 在两个方法中都work,而且用在MoCo中shows better transfer learning results
- an MLP projection head
- stronger data augmentation
- 同时MoCo framework相比较于SimCLR ,远不需要large training batches
- SimCLR based on end-to-end mechanism,需要比较大的batch size,来提供足够多的negative pair
- MoCo则用了动态队列,所以不限制batch size
- SimCLR
- improves the end-to-end method
- larger batch:to provide more negative samples
- output layer:replace fc with a MLP head
- stronger data augmentation
MoCo
- a large number of negative samples are readily available
- 所以就把后两项引入进来了
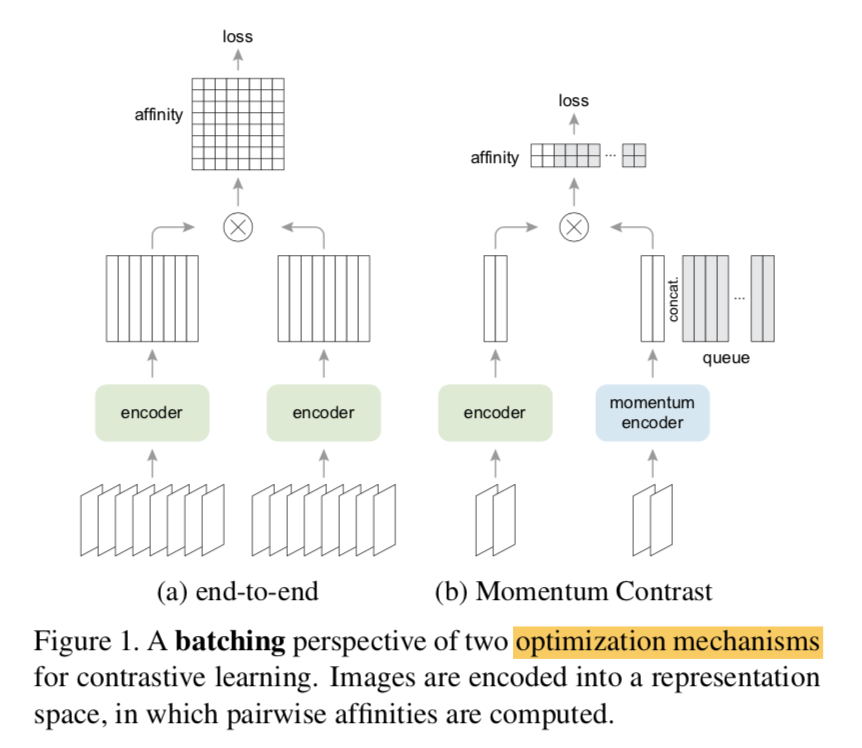
- MoCo & SimCLR
方法
MLP head
- 2-layer MLP(hidden dim=2048, ReLU)
- 仅影响unsupervised training,有监督transfer learning的时候换头
temperature param调整:从default 0.07 调整成optimal value 0.2

augmentation
- add blur
- SimCLR还用了stronger color distortion:we found stronger color distortion in SimCLR hurts in our MoCo,所以没加
实验
ablation
- MLP:在分类任务上的提升比检测大
augmentation:在检测上的提升比分类大
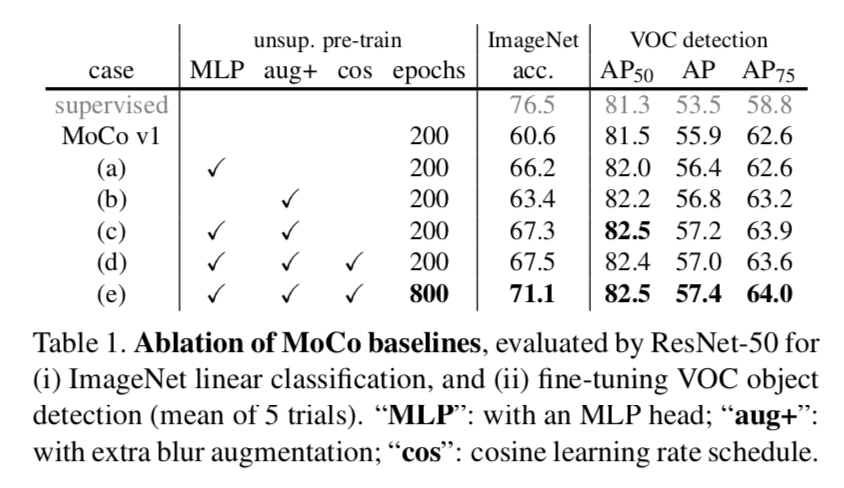
comparison
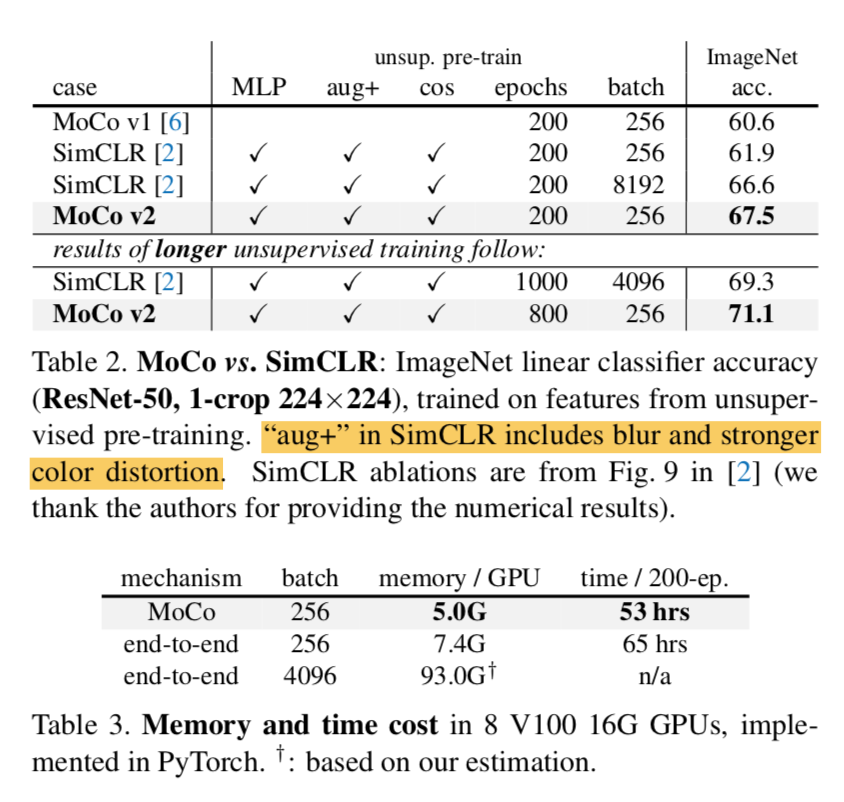
- large batches are not necessary for good acc:SimCLR longer training那个版本精度更高
- end-to-end的方法肯定more costly in memory and time:因为要bp两个encoder
MoCo v3: An Empirical Study of Training Self-Supervised Visual Transformers
动机
- self-supervised frameworks that based on Siamese network, including MoCo
- ViT:study the fundamental components for training self-supervised ViT
- MoCo v3:an incremental improvement of MoCo v1/2,striking for a better balance of simplicity & accuracy & scalability
- instability is a major issue
- scaling up ViT models
- ViT-Large
- ViT-Huge
论点
- we go back to the basics and investigate the fundamental components of training deep neural networks
- batch size
- learning rate
- optmizer
- instability
- instability is a major issue that impacts self-supervised ViT training
- but may not result in catastrophic failure,只会导致精度损失
- 所以称之为hidden degradation
- use a simple trick to improve stability:freeze the patch projection layer in ViT
- and observes increasement in acc
- NLP里面基于masked auto-encoding的framework效果要比基于contrastvie的framework好,图像正好反过来
- we go back to the basics and investigate the fundamental components of training deep neural networks
方法
MoCo v3
- take two crops for each image under random augmentation
- encoded by two encoders $f_q$ & $f_k$ into vectors $q$ & $k$
- we use the keys that naturally co-exist in the same batch
- abandon the memory queue:因为发现batch size足够大(4096)的时候,memory queue就没啥acc gain了
- 回归到batch-based sample pair
- 但是encoder k仍旧不回传梯度,还是基于encoder q进行动量更新
symmetrized loss:
- $ctr(q_1, k_2) + ctr(q_2,k_1)$
- InfoNCE
- temperature
- 两个crops分别计算ctr

encoder
- encoder $f_q$
- a backbone
- a projection head
- an extra prediction head
- encoder $f_k$
- a backbone
- a projection head
- encoder $f_k$ is updated by the moving average of $f_q$,excluding the prediction head
- encoder $f_q$
baseline acc

- basic settings,主要变动就是两个:
- dynamic queue换成large batch
- encoder $f_q$的extra prediction head
- basic settings,主要变动就是两个:
use ViT
直接用ViT替换resnet back met instability issue
batch size
ViT里面的一个观点就是,model本身比较heavy,所以large batch is desirable
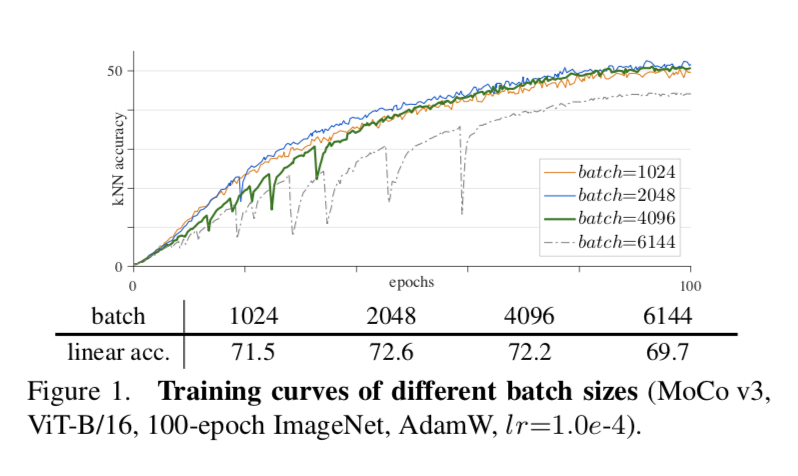
实验发现
- a batch of 1k & 2k produces reasonably smooth curves:In this regime, the larger batch improves accuracy thanks to more negative samples
- a batch of 4k 有明显的untable dips:
a batch of 6k has worse failure patterns:我们解读为在跳水点,training is partially restarted and jumps out of the current local optimum
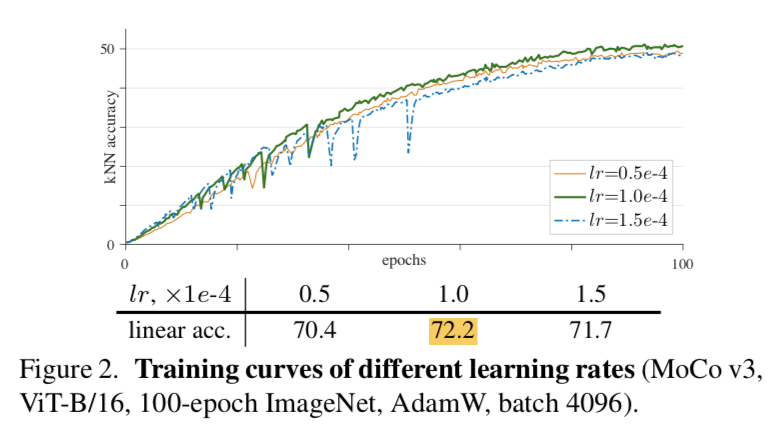
learning rate
- lr较小,training比较稳定,但是容易欠拟合
- lr过大,会导致unstable,也会影响acc
总体来说精度还是决定于stability
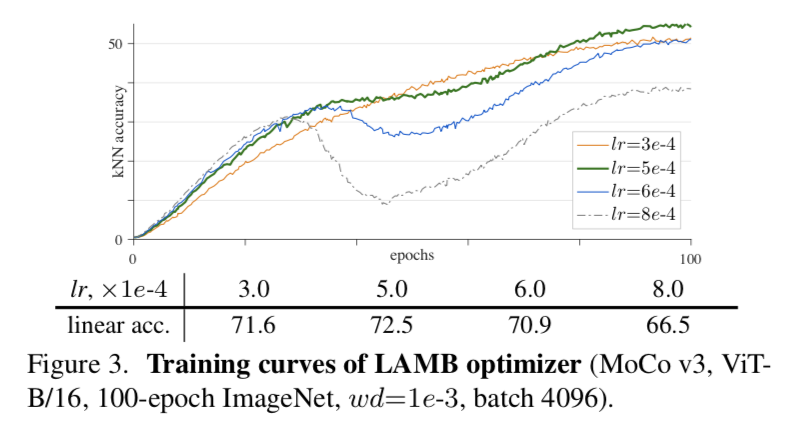
optimizer
- default adamW,batch size 4096
- 有些方法用了LARS & LAMB for large-batch training
LAMB
- sensitive to lr
- optmal lr achieves slightly better accuracy than AdamW
- 但是lr一旦过大,acc极速drop
- 但是training curves still smooth,虽然中间过程有drop:我们解读为LAMB can avoid sudden change in the gradients,但是避免不了negative compact,还是会累加
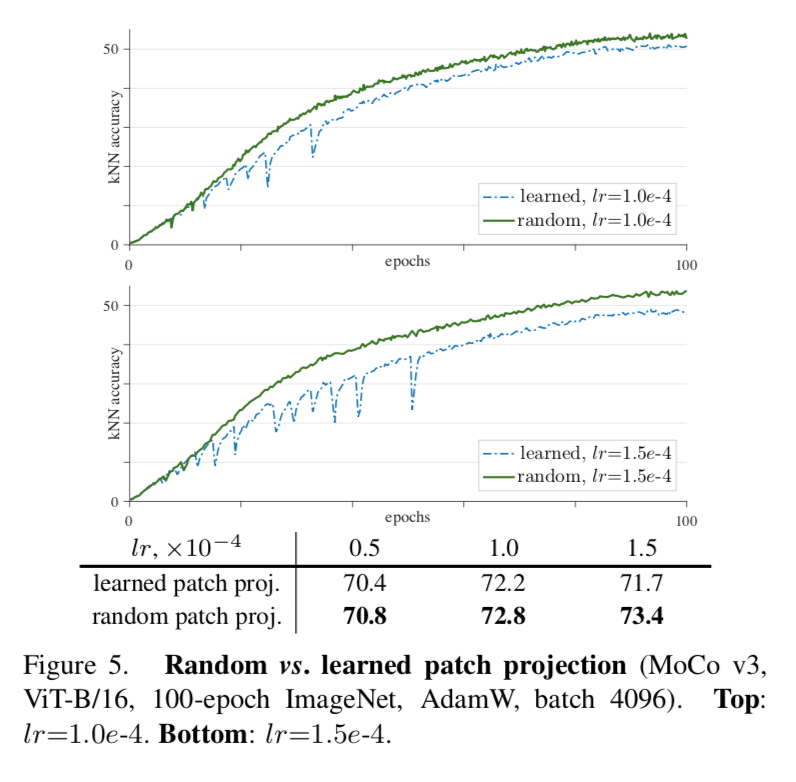
a trick for improving stability
- we found a spike in gradient causes a dip in the training curve
- we also observe that gradient spikes happen earlier in the first layer (patch projection)
所以尝试freezing the patch projection layer during training,也就是一个random的patch projection layer
- This stability benefits the final accuracy
- The improvement is bigger for a larger lr
- 在别的ViT-back-framework上也有效(SimCLR、BYOL)
we also tried BN,WN,gradient clip
- BN/WN does not improve
- gradient clip在threshold足够小的时候有用,推到极限就是freezing了
implementation details
- AdamW
- batch size 4096
- lr:warmup 40 eps then cosine decay
MLP heads
- projection head:3-layers,4096-BN-ReLU-4096-BN-ReLU-256
- prediction head:2-layers,4096-BN-ReLU-256
loss
- ctr里面有个scale的参数,$2\tau$
- makes it less sensitive to $\tau$ value
- $\tau=0.2$
ViT architecture
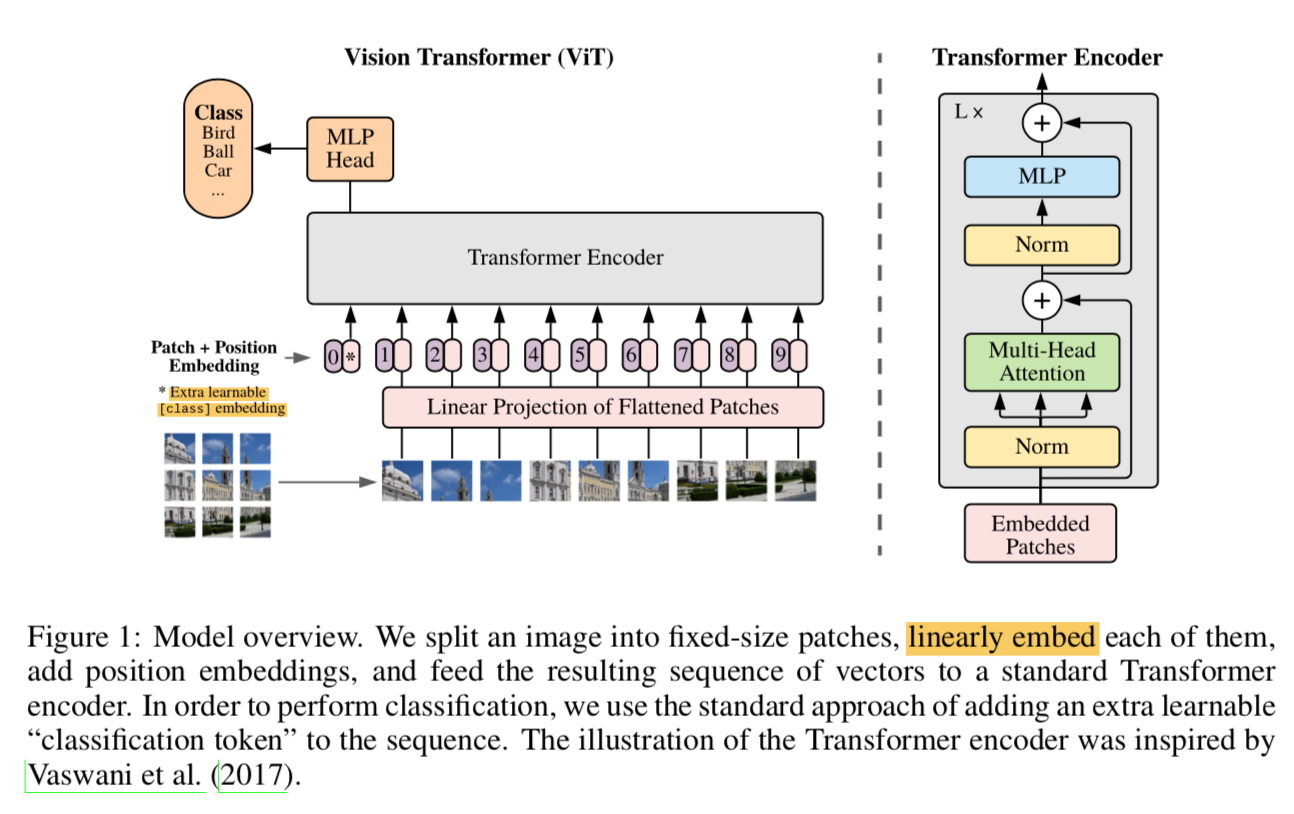
- 跟原论文保持一致
- 输入是224x244的image,划分成16x16/14x14的patch sequence,project成256d/196d的embedding
- 加上sine-cosine-2D的PE
- 再concat一个cls token
- 经过一系列transformer blocks
- The class token after the last block (and after the final LayerNorm) is treated as the output of the backbone,and is the input to the MLP heads