NFNet: High-Performance Large-Scale Image Recognition Without Normalization
动机
- NF:
- normalization-free
- aims to match the test acc of batch-normalized networks
- attain new SOTA 86.5%
- pre-training + fine-tuning上也表现更好89.2%
- batch normalization
- 不是完美解决方案
- depends on batch size
- non-normalized networks
- accuracy
- instabilities:develop adaptive gradient clipping
- NF:
论点
- vast majority models
- variants of deep residual + BN
- allow deeper, stable and regularizing
- disadvantages of batch normalization
- computational expensive
- introduces discrepancy between training & testing models & increase params
- breaks the independence among samples
- methods seeks to replace BN
- alternative normalizers
- study the origin benefits of BN
- train deep ResNets without normalization layers
- key theme when removing normalization
- suppress the scale of the residual branch
- simplest way:apply a learnable scalar
- recent work:suppress the branch at initialization & apply Scaled Weight Standardization,能追上ResNet家族,但是没追上Eff家族
- our NFNets’ main contributions
- propose AGC:解决unstable问题,allow larger batch size and stronger augmentatons
- NFNets家族刷新SOTA:又快又准
- pretraining + finetuning的成绩也比batch normed models好
- vast majority models
方法
Understanding Batch Normalization
- four main benefits
- downscale the residual branch:从initialization就保证残差分支的scale比较小,使得网络has well-behaved gradients early in training,从而efficient optimization
- eliminates mean-shift:ReLU是不对称的,stacking layers以后数据分布会累积偏移
- regularizing effect:mini-batch作为subset对于全集是有偏的,这种noise可以看作是regularizer
- allows efficient large-batch training:数据分布稳定所以loss变化稳定,同时大batch更接近真实分布,因此我们可以使用更大的learning rate,但是这个property仅在使用大batch size的时候有效
- four main benefits
NF-ResNets
- recovering the benefits of BN:对residual branch进行scale和mean-shift
residual block:$h_{i+1} = h_i + \alpha f_i (h_i/\beta_i)$
$\beta_i = Var(h_i)$:对输入进行标准化(方差为1),这是个expected value,不是算出来的,结构定死就定死了
Scaled Weight Standardization & scaled activation
- 比原版的WS多了一个$\sqrt N$的分母
- 源码实现中比原版WS还多了learnable affine gain
- 使得conv-relu以后输出还是标准分布

- 比原版的WS多了一个$\sqrt N$的分母
$\alpha=0.2$:rescale
residual branch上,最终的输出为$\alpha*$标准分布,方差是$\alpha^2$
id path上,输出还是$h_{i}$,方差是$Var(h_i)$
update这个block输出的方差为$Var(h_{i+1}) = Var(h_i)+\alpha^2$,来更新下一个block的 $\beta$
variance reset
- 每个transition block以后,把variance重新设定为$1+\alpha^2$
- 在接下来的non-transition block中,用上面的update公式更新expected std
- 每个transition block以后,把variance重新设定为$1+\alpha^2$
再加上additional regularization(Dropout和Stochastic Depth两种正则手段),就满足了BN benefits的前三条
- 在batch size较小的时候能够catch up甚至超越batch normalized models
- 但是large batch size的时候perform worse
- 在batch size较小的时候能够catch up甚至超越batch normalized models
对于一个标准的conv-bn-relu,从workflow上看
- origin:input——一个free的conv weighting——BN(norm & rescale)——activation
- NFNet:input——standard norm——normed weighting & activation——rescale
- origin:input——一个free的conv weighting——BN(norm & rescale)——activation
Adaptive Gradient Clipping for Efficient Large-Batch Training
梯度裁剪:
- clip by norm:用一个clipping threshold $\lambda$ 进行rescale,training stability was extremely sensitive to 超参的选择,settings(model depth, the batch size, or the learning rate)一变超参就要重新调
clip by value:用一个clipping value进行上下限截断
AGC
given 某层的权重$W \in R^{NM}$ 和 对应梯度$G \in R^{NM}$
ratio $\frac{||G||_F}{||W||_F}$ 可以看作是梯度变化大小的measurement
所以我们直观地想到将这个ratio进行限幅:所谓的adaptive就是在梯度裁剪的时候不是对所有梯度一刀切,而是考虑其对应权重大小,从而进行更合理的调节
但是实验中发现unit-wise的gradient norm要比layer-wise的好:每个unit就是每行,对于conv weights就是(hxwxCin)中的一个
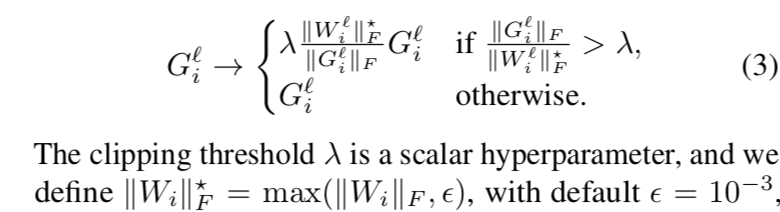
scalar hyperparameter $\lambda$
* the optimal value may depend on the choice of optimizer, learning rate and batch size * empirically we found $\lambda$ should be smaller for larger batchesablations for AGC
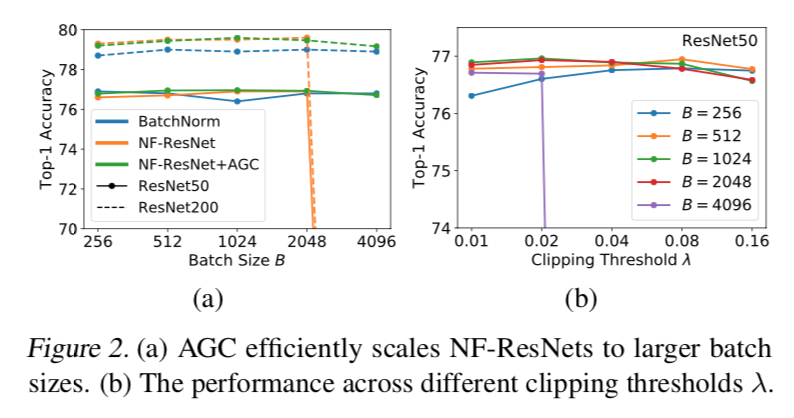
- 用pre-activation NF-ResNet-50 和 NF-ResNet-200 做实验,batch size选择从256到4096,学习率从0.1开始基于batch size线性增长,超参$\lambda$的取值见右图
- 左图结论1:在batch size较小的情况下,NF-Nets能够追上甚至超越normed models的精度,但是batch size一大(2048)情况就恶化了,但是有AGC的NF-Nets则能够maintaining performance comparable or better than~~~
- 左图结论2:the benefits of using AGC are smaller when the batch size is small
- 用pre-activation NF-ResNet-50 和 NF-ResNet-200 做实验,batch size选择从256到4096,学习率从0.1开始基于batch size线性增长,超参$\lambda$的取值见右图
- 右图结论1:超参$\lambda$的取值比较小的时候,我们对梯度的clipping更strong,这对于使用大batch size训练的稳定性来说非常重要
whether or not AGC is beneficial for all layers
* it is always better to not clip the final linear layer * 最开始的卷积不做梯度裁剪也能稳定训练- 最终we apply AGC to every layer except for the final linear layer
Normalizer-Free Architectures
begin with SE-ResNeXt-D model
about group width
* set group width to 128- the reduction in compute density means that 只减少了理论上的FLOPs,没有实际加速
about stages
* R系列模型加深的时候是非线性增长,疯狂叠加stage3的block数,因为这一层resolution不大,channel也不是最多,兼顾了两侧计算量- 我们给F0设置为[1,2,6,3],然后在deeper variants中对每个stage的block数用一个scalar N线形增长
about width
* 仍旧对stage3下手,[256,512,1536,1536] * roughly preserves the training speed- 一个论点:stage3 is the best place to add capacity,因为deeper enough同时have access to deeper levels同时又比最后一层有slightly higher resolution
about block
* 实验发现最有用的操作是adding an additional 3 × 3 grouped conv after the first * overview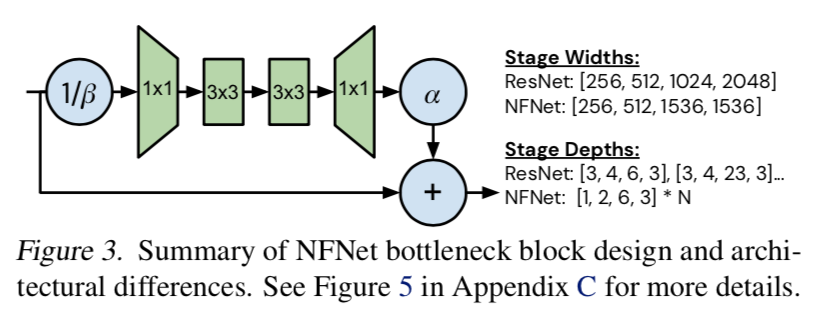
about scaling variants
* eff系列采用的是R、W、D一起增长,因为eff的block比较轻量但是对R系列来说,只增长D和R就够了
补充细节
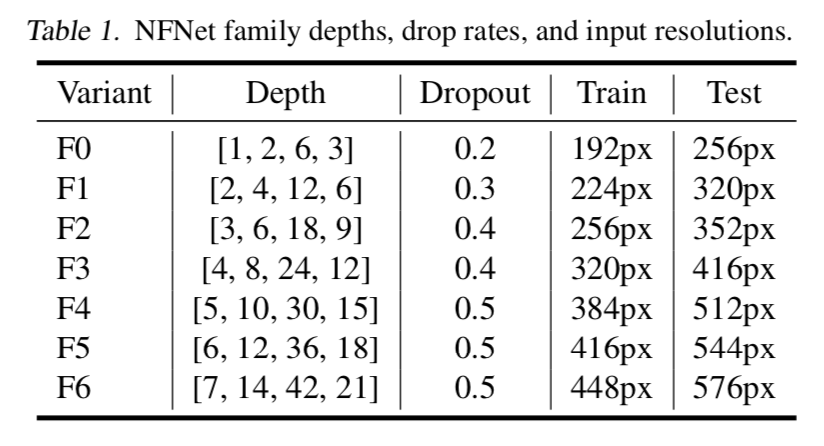
* 在inference阶段使用比训练阶段slightly higher resolution- 随着模型加大increase the regularization strength:
- scale the drop rate of Dropout
- 调整stochastic depth rate和weight decay则not effective
se-block的scale乘个2
SGD params:
- Nesterov=True, momentum=0.9, clipnorm=0.01
- lr:
- 先warmup再余弦退火:increase from 0 to 1.6 over 5 epochs, then decay to zero with cosine annealing
- 余弦退火cosine annealing
summary
- 总结来说,就是拿来一个SE-ResNeXt-D
- 先做结构上的调整,modified width and depth patterns以及a second spatial convolution,还有drop rate,resolution
- 再做对梯度的调整:除了最后一个线形分类层以外,全用AGC,$\lambda=0.01$
最后是训练上的trick:strong regularization and data augmentation
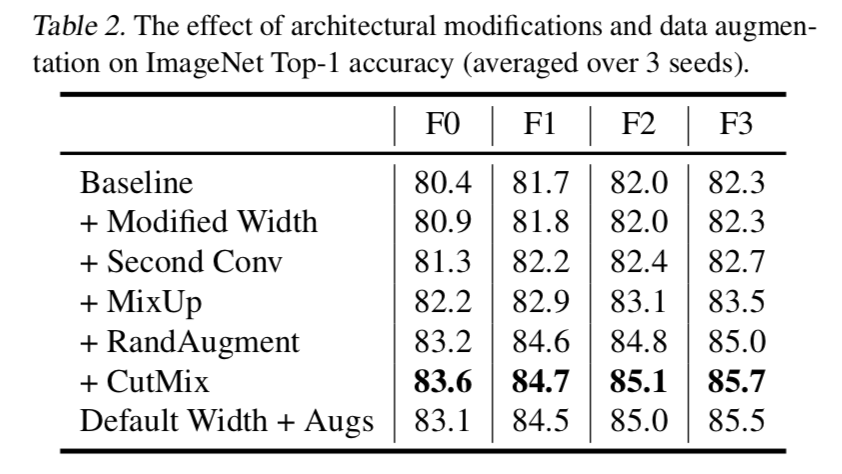
- 随着模型加大increase the regularization strength:
detailed view of NFBlocks
- transition block:有下采样的block
- 残差branch上,bottleneck的narrow ratio是0.5
- 每个stage的3x3 conv的group width永远是128,而group数目是在随着block width变的
- skip path接在 $\beta$ downscaling 之后
- skip path上是avg pooling + 1x1 conv
non-transition block:无下采样的block
- bottleneck-ratio仍旧是0.5
- 3x3conv的group width仍旧是128
- skip path接在$\beta$ downscaling 之前
- skip path就是id
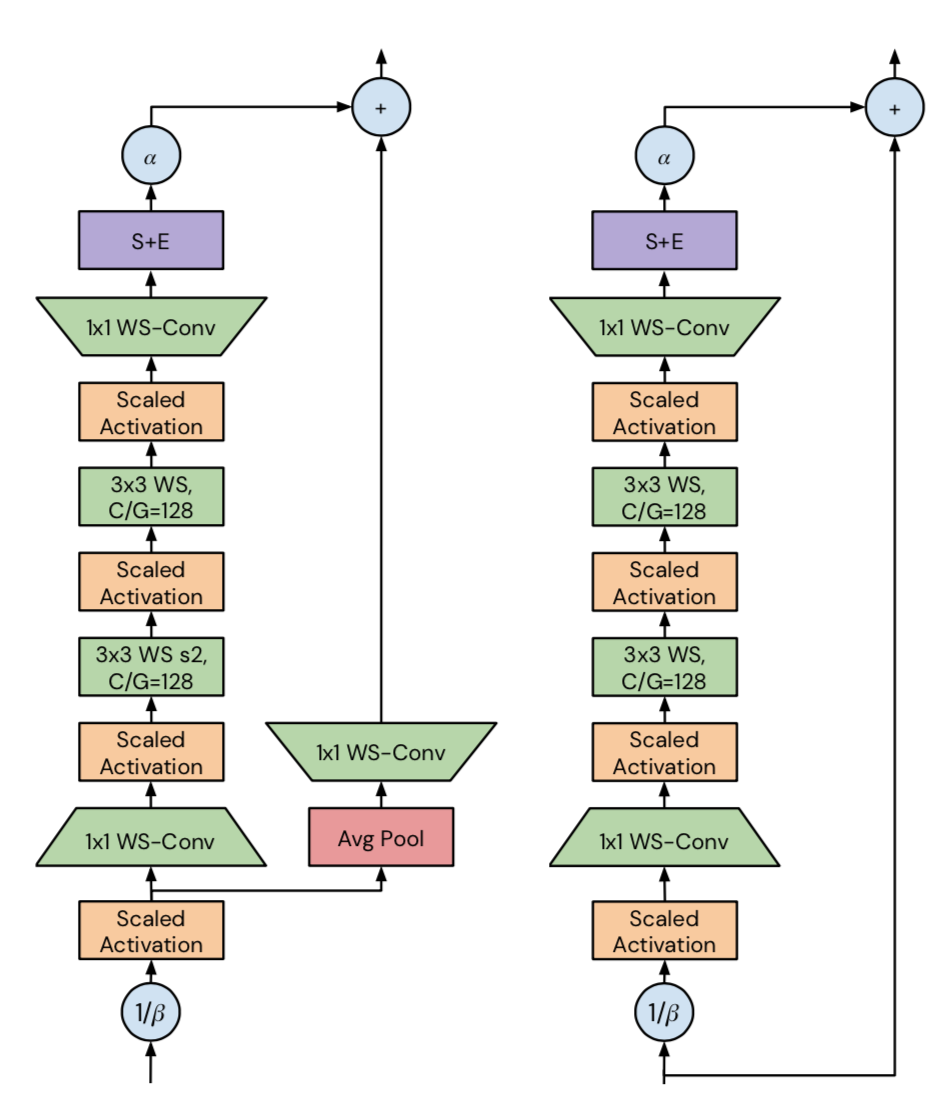
- transition block:有下采样的block
实验