RepVGG: Making VGG-style ConvNets Great Again
动机
- plain ConvNets
- simply efficient but poor performance
- propose a CNN architecture RepVGG
- 能够decouple为training-time和inference-time两个结构
- 通过structure re-paramterization technique
- inference-time architecture has a VGG-like plain body
- faster
- 83% faster than ResNet-50 or 101% faster than ResNet-101
- accuracy-speed trade-off
- reaches over 80% top-1 accuracy
- outperforms ResNets by a large margin
- verify on classification & semantic segmentation tasks
- plain ConvNets
论点
well-designed CNN architectures
- Inception,ResNet,DenseNet,NAS models
- deliver higher accuracy
- drawbacks
- multi-branch designs:slow down inference and reduce memory utilization,对高并行化的设备不友好
- some components:depthwise & channel shuffle,increase memory access cost
- MAC(memory access cost) constitutes a large time usage in groupwise convolution:我的groupconv实现里cardinality维度上计算不并行
- FLOPs并不能precisely reflect actual speed,一些结构看似比old fashioned VGG/resnet的FLOPs少,但实际并没有快
multi-branch
- 通常multi-branch model要比plain model表现好
- 因为makes the model an implicit ensemble of numerous shallower models
- so that avoids gradient vanishing
- benefits are all for training
- drawbacks are undesired for inference
the proposed RepVGG
- advantages
- plain architecture:no branches
- 3x3 conv & ReLU组成
- 没有过重的人工设计痕迹
- training time use identity & 1x1 conv branches
at inference time
- identity 可以看做degraded 1x1 conv
- 1x1 conv 可以看做degraded 3x3 conv
- 最终整个conv-bn branches能够整合成一个3x3 conv
- inference-time model只包含conv和ReLU:没有max pooling!!
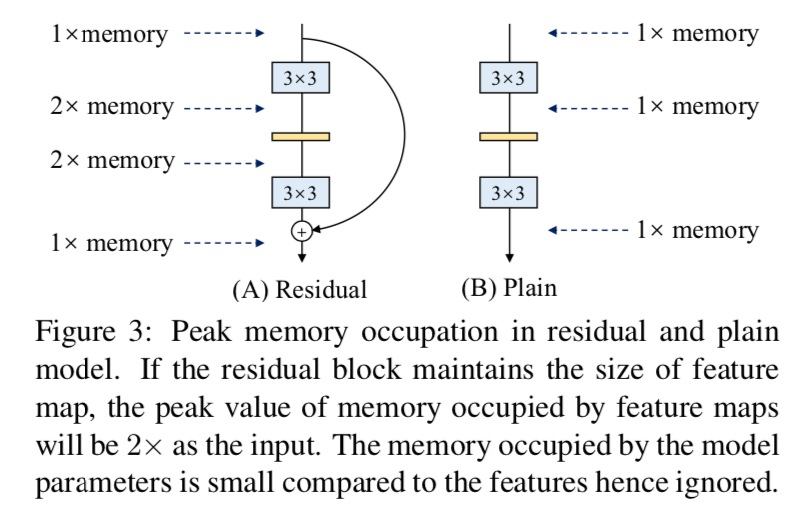
- fewer memory units:分支会占内存,直到分支计算结束,plain结构的memory则是immediately released
- advantages
方法
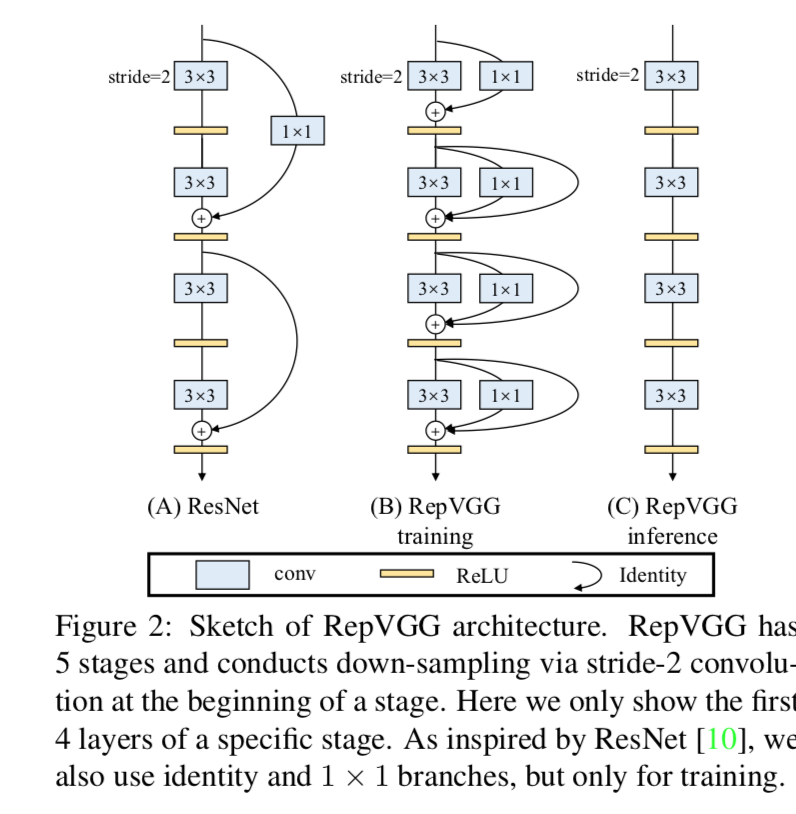
training-time
- ResNet-like block
- id + 1x1 conv + 3x3 conv multi-branches
- use BN in each branch
- with n blocks, the model can be interpreted as an ensemble of $3^n$ models
- stride2的block应该没有id path吧??
- simply stack serveral blocks to construct the training model
- ResNet-like block
inference-time
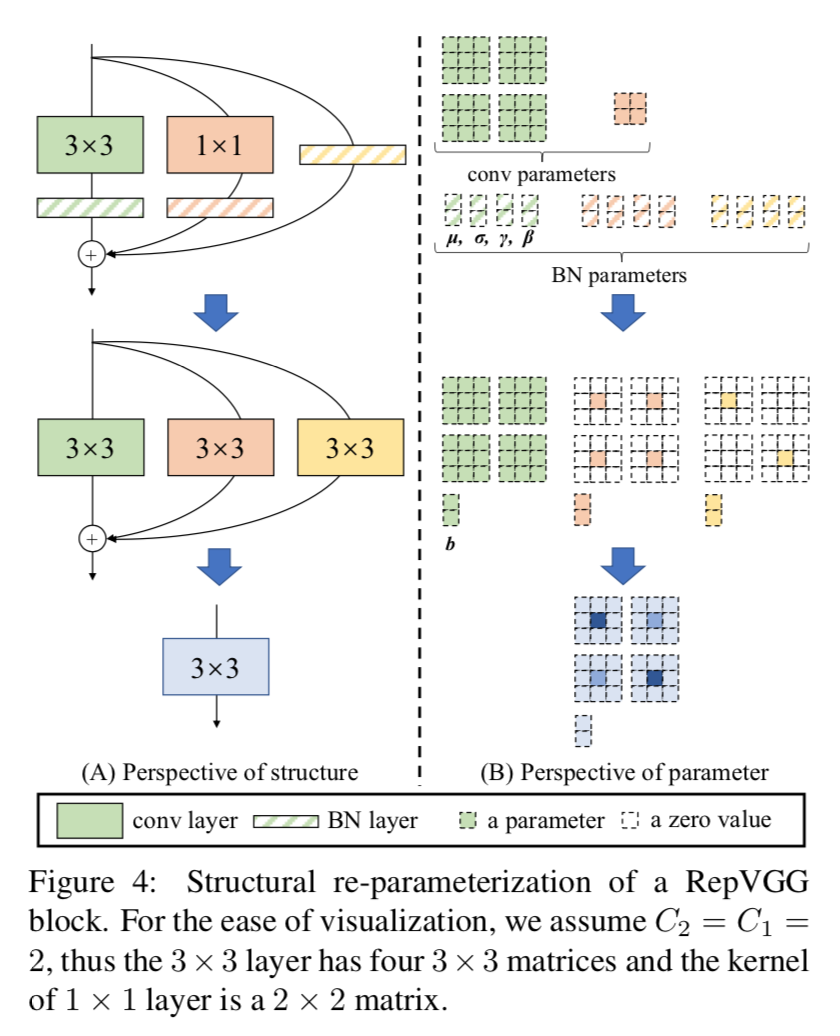
re-param
- inference-time BN也是一个线性计算
- 两个1x1 conv都可以转换成中通的3x3 kernel,有权/无权
要求各branch has the same strides & padding pixel要对齐
architectural specification
- variety:depth and width
- does not use maxpooling:只有一种operator:3x3 conv+relu
- head:GAP + fc / task specific
- 5 stages
- 第一个stage处理high resolution,stride2
- 第五个stage shall have more channels,所以只用一层,save parameters
- 给倒数第二个stage最多层,考虑params和computation的balance
- RepVGG-A:[1,2,4,14,1],用来compete against轻量和中量级model
RepVGG-B:deeper in s2,3,4,[1,4,6,16,1],用来compete against high-performance ones
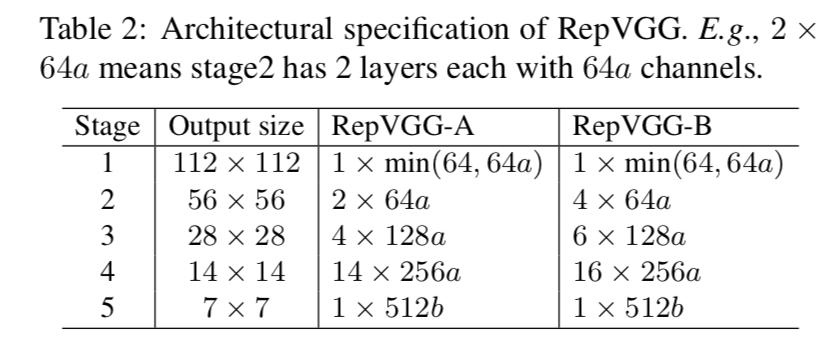
basic width:[64, 128, 256, 512]
- width multiplier a & b
- a控制前4个stage宽度,b控制最后一个stage
- [64a, 128a, 256a, 512b]
第一个stage的宽度只接受变小不接受变大,因为大resolution影响计算量,min(64,64a)
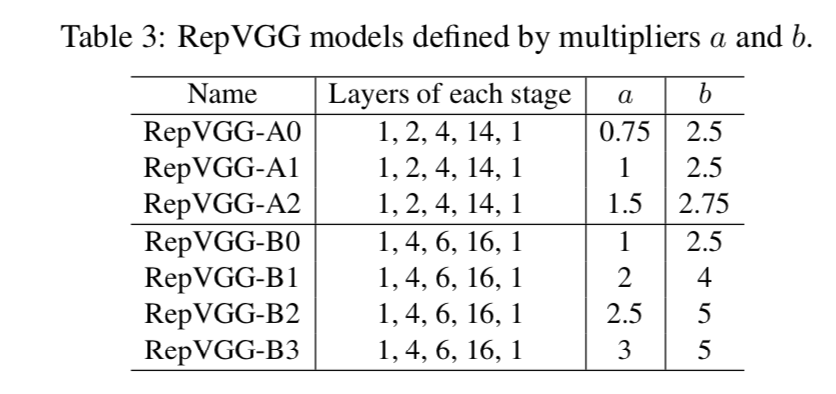
further reduce params & computation
- groupwise 3x3 conv
- 跳着层换:从第三开始,第三、第五、
- number of groups:1,2,4 globally
实验
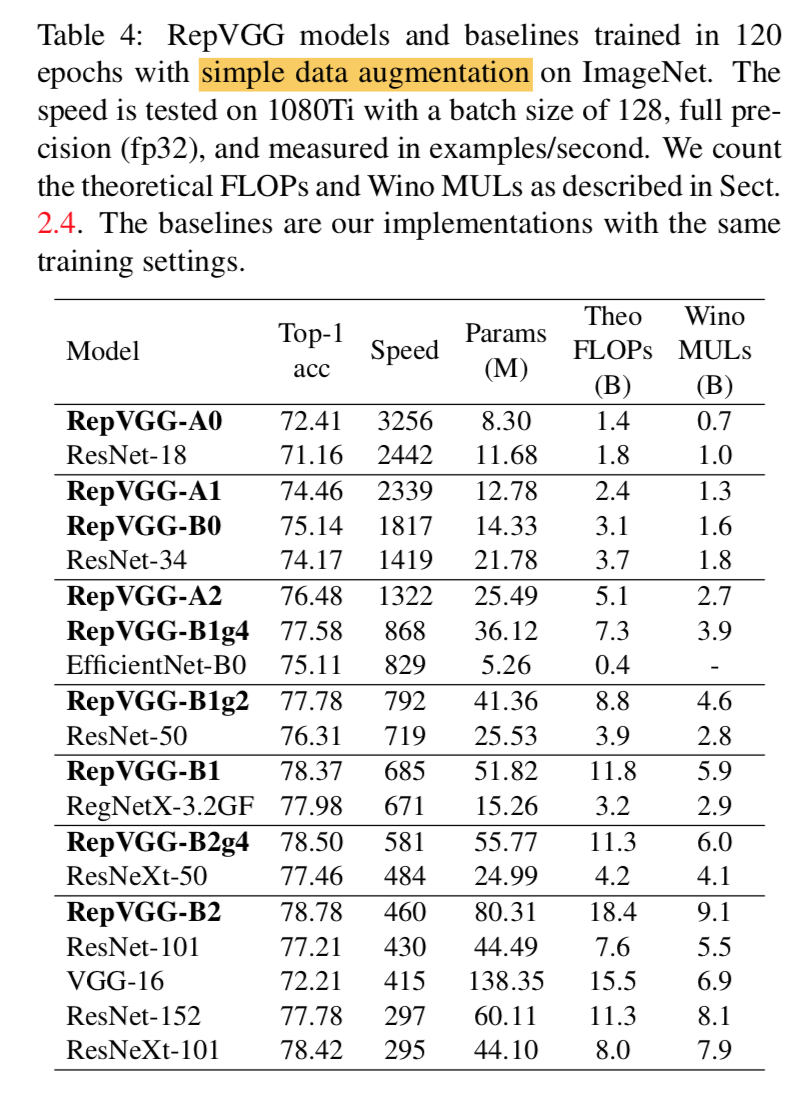
分支的作用

结构上的微调
- id path去掉BN
- 把所有的BN移动到add的后面
每个path加上relu
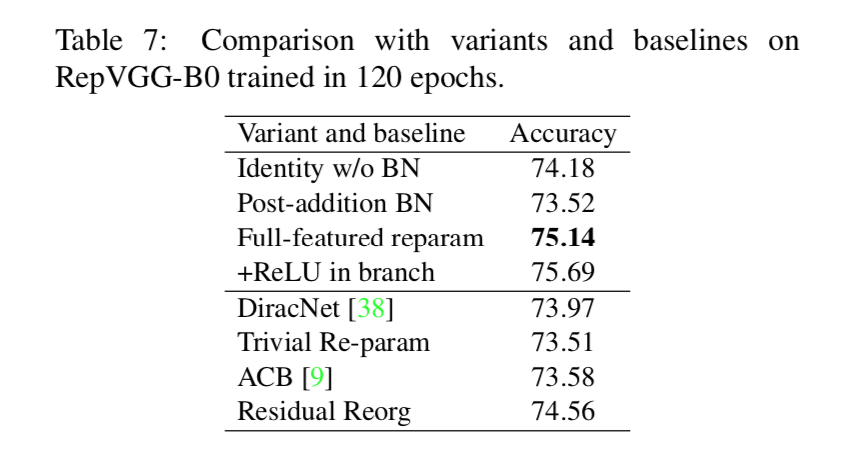
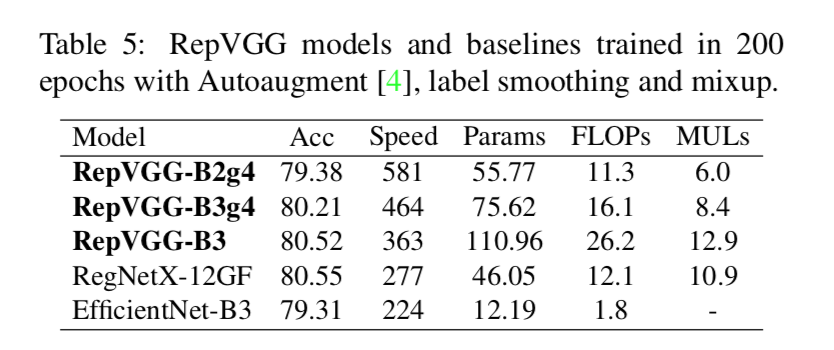
ImageNet分类任务上对标其他模型
simple augmentation
strong:Autoaugment, label smoothing and mixup