原作者知乎reference:https://zhuanlan.zhihu.com/p/55854246
- 不完全是anchor-free,因为还是有decision grid to choose from的,应该说是adaptive anchor instead of hand-picked
- 为了特征和adaptive anchor对齐,引入deformable conv
Region Proposal by Guided Anchoring
动机
- most methods
- predefined anchors
- do a uniformed dense prediction
- our method
- use sematic features to guide the anchoring
- anchor size也是网络预测参数,compute from feature map
- arbitrary aspect ratios
- feature inconsistency
- 不同的anchor loc都是对应feature map上某一个点
- 变化的anchor size和固定的位置向量之间存在inconsistency
- 引入feature adaption module
- use high-quality proposals
- GA-RPN提升了proposal的质量
- 因此我们对proposal进入stage2的条件更严格
- adopt in Fast R-CNN, Faster R-CNN and RetinaNet均涨点
- RPN提升显著:9.1
- MAP也有涨点:1.2-2.7
- 还可以boosting trained models
- boosting a two-stage detector by a fine-tuning schedule
- most methods
论点
alignment & consistency
我们用feature map的pixels作为anchor representations,那么anchor centers必须跟feature pixels保持align
不同pixel的reception field必须跟对应的anchor size保持匹配
- previous sliding window scheme对每个pixel都做一样的操作,用同样一组anchor,因此是align和consist的
- previous progressly refining scheme对anchor的位置大小做了refinement,ignore the alignment & consistency issue,是不对的!!
disadvantage of predefined anchors
- hard hyperparams
- huge pos/neg imbalance & computation
we propose GA-RPN
- learnable anchor shapes to mitigate the hand-picked issue
- feature adaptation to solve the consistency issue
- key concerns in this paper
- learnable anchors
- joint anchor distribution
- alignment & consistency
- high-quality proposals
方法
formulation
- $p(x,y,w,h|I) = p(x,y|I)p(w,h|x,y,I)$
- 将问题解耦成位置和尺寸的预测,首先anchor的loc服从full image的均匀分布,anchor的size建立在loc存在的基础上
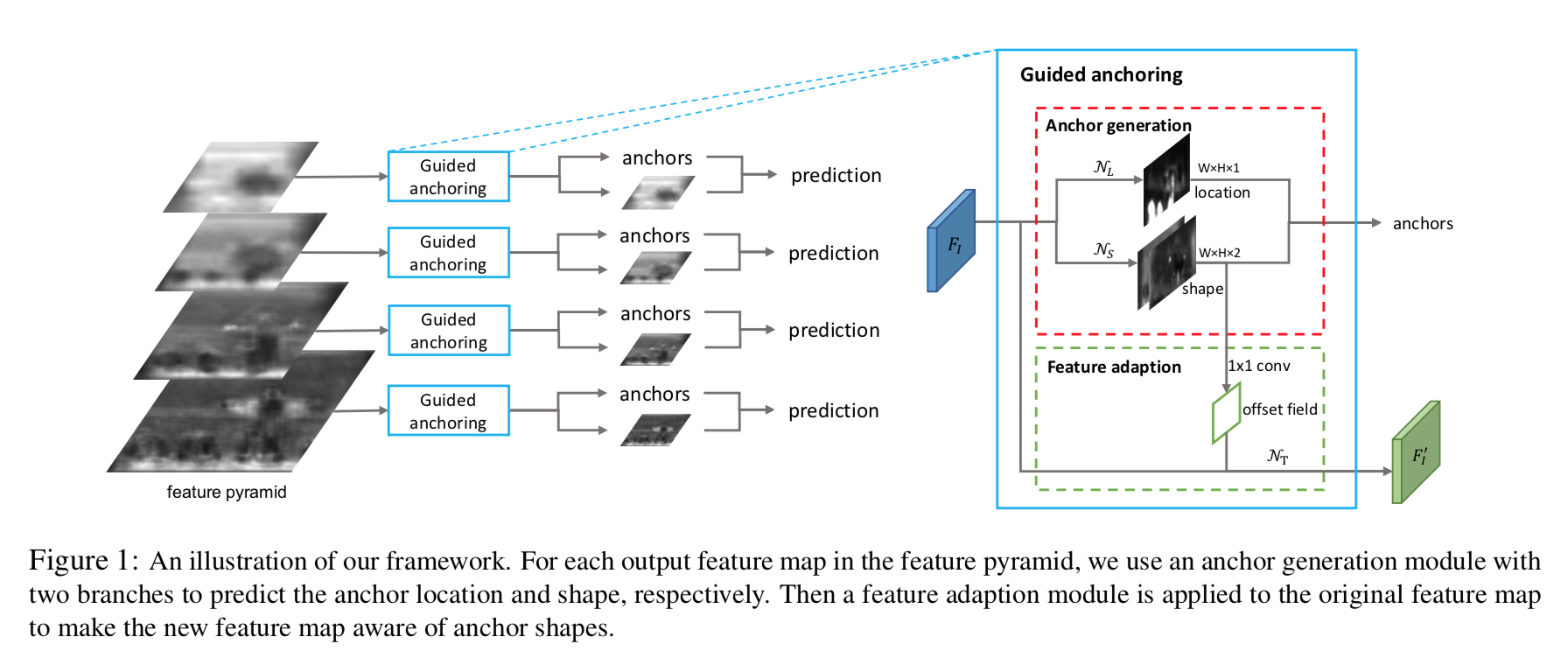
- two branches for loc & shape prediction
- loc:binary classification,hxwx1
- shape:location-dependent shapes,hxwx2
- anchors:loc probabilities above a certain threshold & correponding ‘most probable’ anchor shape
- multi-scale
- the anchor generation parameters are shared
feature adaptation module
- adapts the feature according to the anchor shape
anchor location prediction
- indicates the probability of an object’s center
- 一层卷积:1x1 conv,channel1,sigmoid
- transform back:each grid(i,j) corresponds to coords ((i+0.5)*s, (j+0.5)*s) on the origin map
- filter out 90% of the regions
- thus replace the ensuing conv layers by masked convs
- groud truth
- binary label map
- each level:center region & ignore region & outside region,基于object center的方框
- $\sigma_1=0.2,\sigma_2=0.5$:region box的长宽系数
- ???用centerNet的heatmap会不会更好???
- focal loss $L_{loc}$
- anchor shape prediction
- predicts the best shape for each location
- best shape:a shape that lead to best iou with the nearest gt box
- 一层卷积:1x1 conv,channel2,[-1,1]
- transform layer:transform direct [-1,1] outputs to real box shape
- $w = \sigma s e^{dw}$
- $h = \sigma s e^{dh}$
- s:stride
- $\sigma$:经验参数,8 in experiments
- set 9 pairs of (w,h) as RetinaNet,calculate the IoU of these sampled anchors with gt,take the max as target value
- bounded iou loss:$L_{shape} = L_1(1-min(\frac{w}{w_g}, \frac{w_g}{w})) + L_1(1-min(\frac{h}{h_g}, \frac{h_g}{h}))$
- feature adaptation
- intuition:the feature corresponding to different size of anchor shapes应该encode different content region
- inputs:feature map & anchor shape
- location-dependent transformation:3x3 deformable conv
- deformable conv的offset是anchor shape得到的
- outputs:adapted features
- with adapted features
- then perform further classification and bounding-box regression
- training
- jointly optimize:$L = \lambda_1 L_{loc} + \lambda_2 L_{shape} + L_{cls} + L_{reg}$
- $\lambda_1=0.2,\lambda_2=0.5$
- each level of feature map should only target objects of a specific scale range:但是ASFF论文主张说这种arrange by scale的模式会引入前背景inconsistency??
- High-quality Proposals
- set a higher positive/negative threshold
- use fewer samples