Learning Spatial Fusion for Single-Shot Object Detection
动机
- inconsistency when fuse across different feature scales
- propose ASFF
- suppress the inconsistency
- spatially filter conflictive information:想法应该跟SSE-block类似
build on yolov3
- introduce a bag of tricks
- anchor-free pipeline
- 论点
- ssd is one of the first to generate pyramidal feature representations
- deeper layers reuse the formers
- bottom-up path
- small instances suffers low acc because containing insufficient semanic info
- FPN use top-down path
- shares rich semantics at all levels
- improvement:more strengthening feature fusion
- 在使用FPN时,通常不同scale的目标绑定到不同的level上面
- inconsistency:其他level的feature map对应位置的信息则为背景
- some methods set ignore region in adjacent features
- ssd is one of the first to generate pyramidal feature representations
方法
- introduce advanced techniques
- mixup
- cosine learning rate schedule
- sync-bn
- an anchor-free branch to run jointly with anchor-based ones
- L1 loss + IoU loss
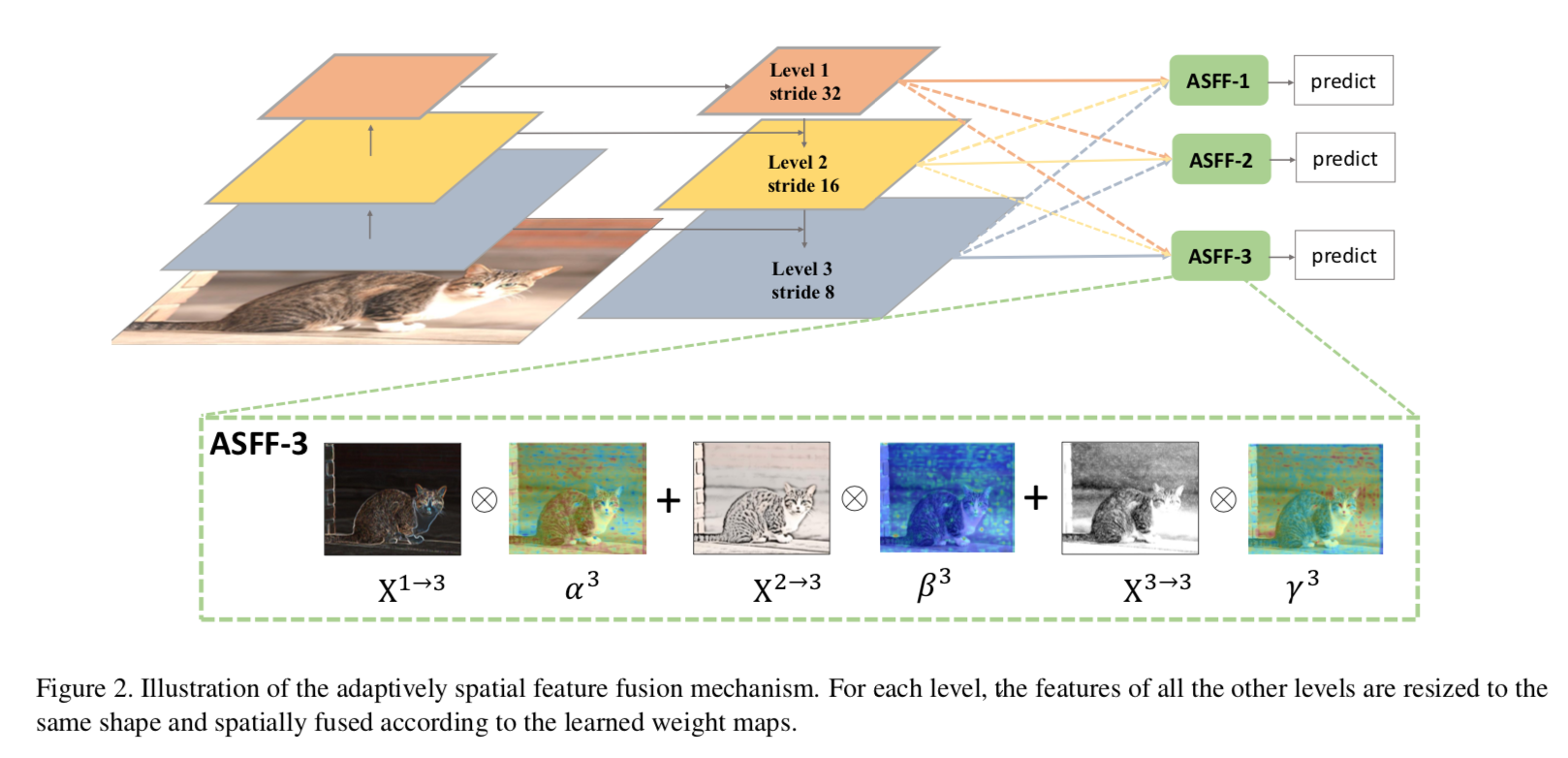
- fusion
- 全联接而非adjacent merge:三个level的fuse map都来自三个level的feature map
- 上采样:
- 1x1 conv:对齐channel
- upsamp with interpolation
- 下采样:
- s2:3x3 s2 conv
- s4:maxpooling + 3x3 s2 conv
- adaptive fusion
- pixel level的reweight
- shared across channels:hxwx1
- 对来自三个level的feature map,resolution对齐以后,分别1x1conv,channel 1
- norm the weights:softmax
- 为啥能suppress inconsistency:三个level的像素点,只激活一个另外两个是0的情况是绝对不harm的,相当于上面ignore那个方法拓展成adaptive
- training
- apply mixup on the classification pretraining of D53
- turn off mixup augmentation for the last 30 epochs.
- inference
- the detection header at each level first predicts the shape of anchors???这个不太懂
- ASFF & ASFF*
- enhanced version of ASFF by integrating other lightweight modules
- dropblock & RFB
- introduce advanced techniques
实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68class ASFF(nn.Module):
def __init__(self, level, activate, rfb=False, vis=False):
super(ASFF, self).__init__()
self.level = level
self.dim = [512, 256, 128]
self.inter_dim = self.dim[self.level]
if level == 0:
self.stride_level_1 = conv_bn(256, self.inter_dim, kernel=3, stride=2)
self.stride_level_2 = conv_bn(128, self.inter_dim, kernel=3, stride=2)
self.expand = conv_bn(self.inter_dim, 512, kernel=3, stride=1)
elif level == 1:
self.compress_level_0 = conv_bn(512, self.inter_dim, kernel=1)
self.stride_level_2 = conv_bn(128, self.inter_dim, kernel=3, stride=2)
self.expand = conv_bn(self.inter_dim, 256, kernel=3, stride=1)
elif level == 2:
self.compress_level_0 = conv_bn(512, self.inter_dim, kernel=1, stride=1)
self.compress_level_1= conv_bn(256,self.inter_dim,kernel=1,stride=1)
self.expand = conv_bn(self.inter_dim, 128, kernel=3, stride=1)
compress_c = 8 if rfb else 16
self.weight_level_0 = conv_bn(self.inter_dim, compress_c, 1, 1, 0)
self.weight_level_1 = conv_bn(self.inter_dim, compress_c, 1, 1, 0)
self.weight_level_2 = conv_bn(self.inter_dim, compress_c, 1, 1, 0)
self.weight_levels = conv_bias(compress_c * 3, 3, kernel=1, stride=1, padding=0)
self.vis = vis
def forward(self, x_level_0, x_level_1, x_level_2):
# 跟论文描述一样:上采样先1x1conv对齐,再upinterp,下采样3x3 s2 conv
if self.level == 0:
level_0_resized = x_level_0
level_1_resized = self.stride_level_1(x_level_1)
level_2_downsampled_inter = F.max_pool2d(x_level_2, 3, stride=2, padding=1)
level_2_resized = self.stride_level_2(level_2_downsampled_inter)
elif self.level == 1:
level_0_compressed = self.compress_level_0(x_level_0)
sh = torch.tensor(level_0_compressed.shape[-2:])*2
level_0_resized = F.interpolate(level_0_compressed, tuple(sh), 'nearest')
level_1_resized = x_level_1
level_2_resized = self.stride_level_2(x_level_2)
elif self.level == 2:
level_0_compressed = self.compress_level_0(x_level_0)
sh = torch.tensor(level_0_compressed.shape[-2:])*4
level_0_resized = F.interpolate(level_0_compressed, tuple(sh), 'nearest')
level_1_compressed = self.compress_level_1(x_level_1)
sh = torch.tensor(level_1_compressed.shape[-2:])*2
level_1_resized = F.interpolate(level_1_compressed, tuple(sh),'nearest')
level_2_resized = x_level_2
# 这里得到的resized特征图不直接转换成一通道的weighting map,
# 而是先1x1conv降维到8/16,然后concat,然后3x3生成3通道的weighting map
# weighting map相当于一个prediction head,所以是conv_bias_softmax,无bn
level_0_weight_v = self.weight_level_0(level_0_resized)
level_1_weight_v = self.weight_level_1(level_1_resized)
level_2_weight_v = self.weight_level_2(level_2_resized)
levels_weight_v = torch.cat((level_0_weight_v, level_1_weight_v, level_2_weight_v), 1)
levels_weight = self.weight_levels(levels_weight_v)
levels_weight = F.softmax(levels_weight, dim=1)
# reweighting
fused_out_reduced = level_0_resized * levels_weight[:, 0:1, :, :] + \
level_1_resized * levels_weight[:, 1:2, :, :] + \
level_2_resized * levels_weight[:, 2:, :, :]
# 3x3的conv,是特征图平滑
out = self.expand(fused_out_reduced)
if self.vis:
return out, levels_weight, fused_out_reduced.sum(dim=1)
else:
return out