An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection
动机
- denseNet
- dense path:diverse receptive fields
- heavy memory cost & low efficiency
- we propose a backbone
- preserve the benefit of concatenation
- improve denseNet efficiency
- VoVNet comprised of One-Shot Aggregation (OSA)
- apply to one/two stage object detection tasks
- outperforms denseNet & resNet based ones
- better small object detection performance
- denseNet
论点
- main difference between resNet & denseNet
- aggregation:summation & concatenation
- summation would washed out the early features
- concatenation last as it preserves
- aggregation:summation & concatenation
- GPU parallel computation
- computing utilization is maximized when operand tensor is larger
- many 1x1 convs for reducing dimension
- dense connections in intermediate layers are inducing the inefficiencies
VoVNet
- hypothesize that the dense connections are redundant
- OSA:aggregates intermediate features at once
- test as object detection backbone:outperforms DenseNet & ResNet with better energy efficiency and speed
factors for efficiency
- FLOPS and model sizes are indirect metrics
- energy per image and frame per second are more practical
- MAC:
- memory accesses cost,$hw(c_i+c_o) + k^2 c_ic_o$
- memory usage不止跟参数量有关,还跟特征图尺寸相关
- MAC can be minimized when input channel size equals the output
- FLOPs/s
- splitting a large convolution operation into several fragmented smaller operations makes GPU computation inefficient as fewer computations are processed in parallel
- 所以depthwise/bottleneck理论上降低了计算量FLOP,但是从GPU并行的角度efficiency降低,并没有显著提速:cause more sequential computations
- 以时间为单位的FLOPs才是fair的
- main difference between resNet & denseNet
方法
hypothesize
- dense connection makes similar between neighbor layers
- redundant
OSA
- dense connection:former features concats in every following features
one-shot connection:former features concats once in the last feature
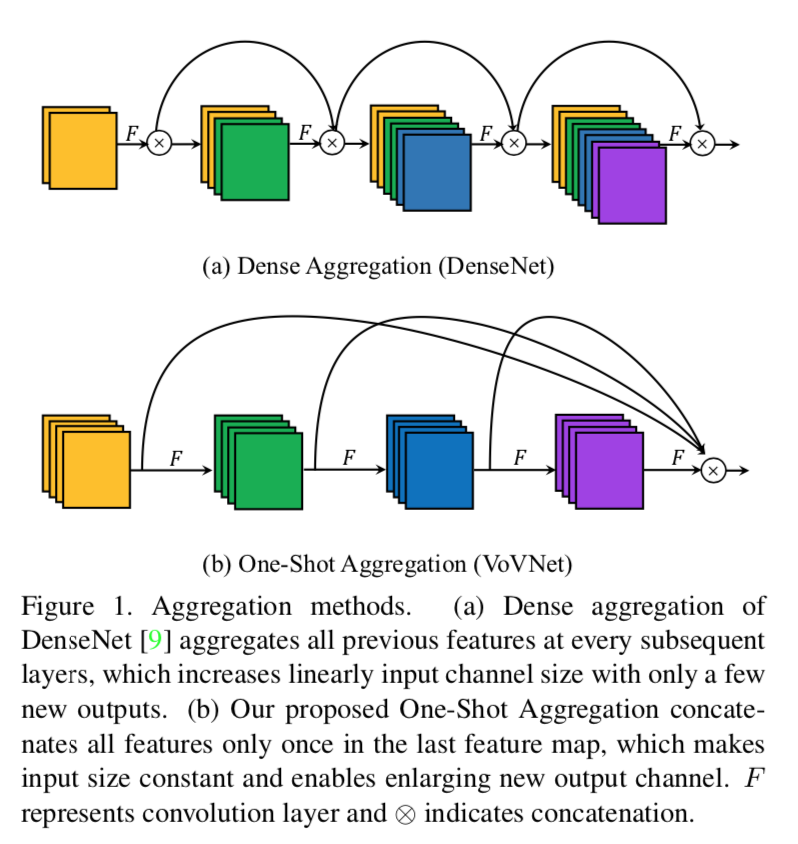
最开始跟dense block保持参数一致:一个block里面12个layers,channel20,发现深层特征contributes less,所以换成浅层,5个layers,channel43,发现有涨点:implies that building deep intermediate feature via dense connection is less effective than expected
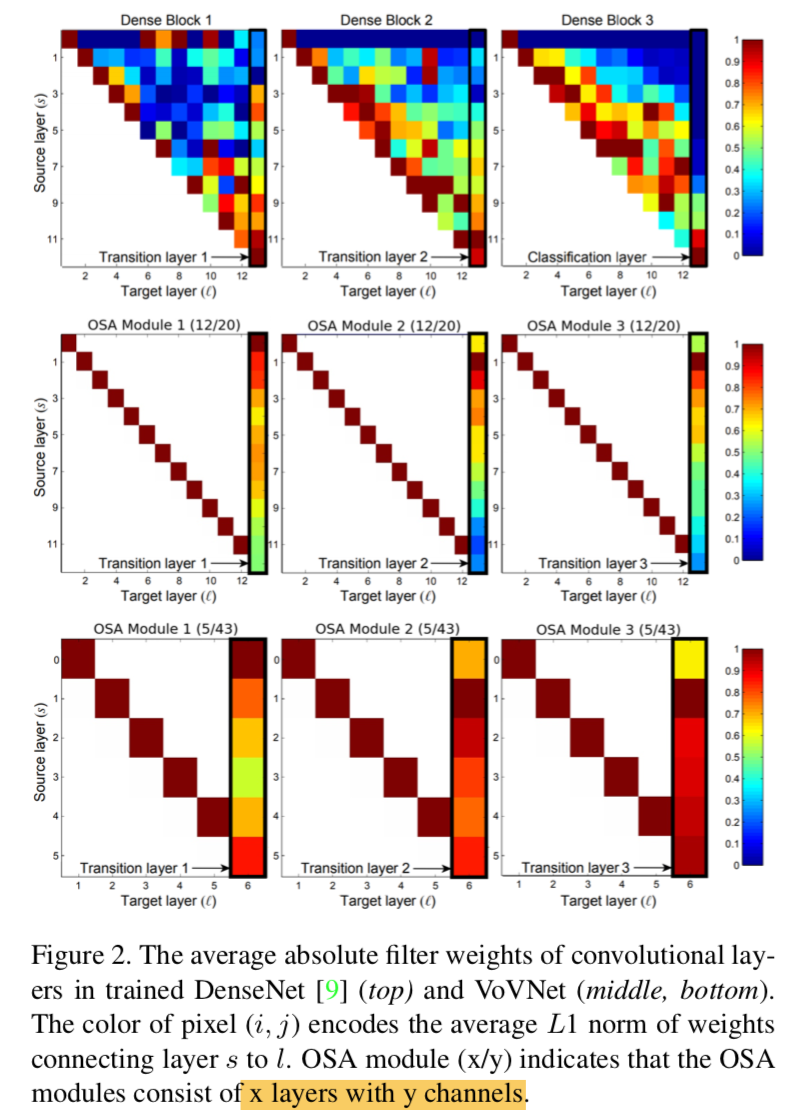
in/out channel数相同
- much less MAC:
- denseNet40:3.7M
- OSA:5layers,channel43,2.5M
- 对于higher resolution的detection任务impies more fast and energy efficient
- GPU efficiency
- 不需要那好几十个1x1
- much less MAC:
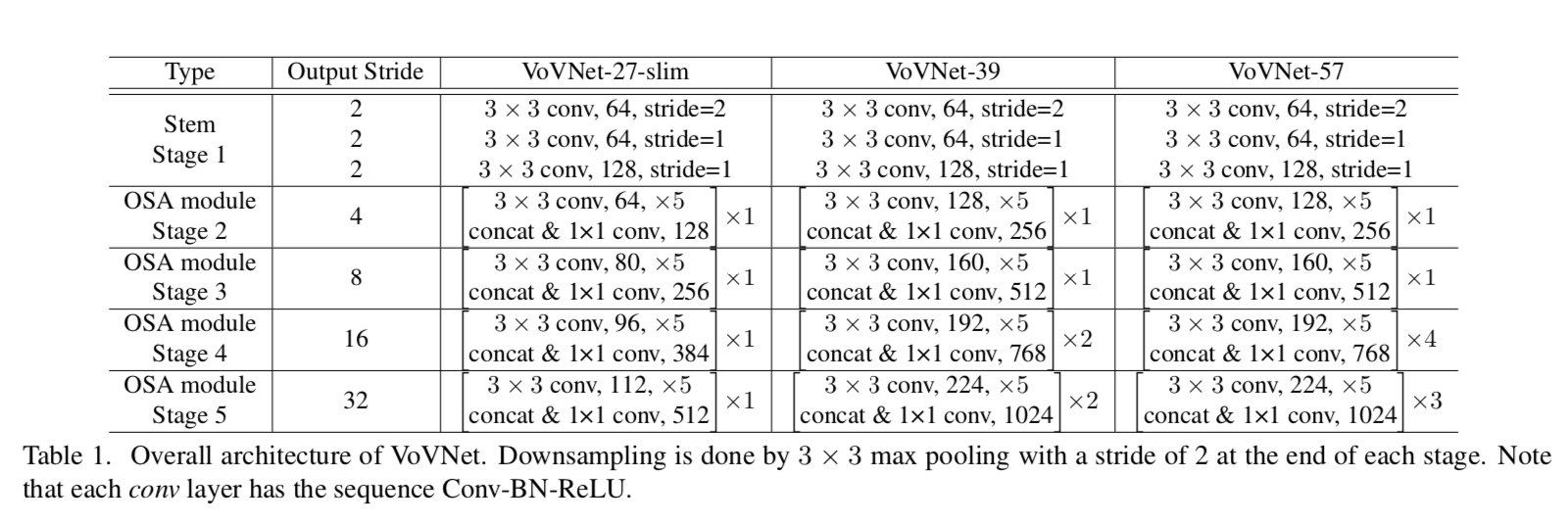
architecture
- stem:3个3x3conv
- downsamp:s2的maxpooling
- stages:increasing channels enables more rich semantic high-level information,better feature representation
deeper:makes more modules in stage3/4
实验
- one-stage:refineDet
- two-stage:Mask-RCNN