startup
reference1:https://mp.weixin.qq.com/s/Rm899vLhmZ5eCjuy6mW_HA
reference2:https://zhuanlan.zhihu.com/p/308301901
NLP & RNN
- 文本涉及上下文关系
- RNN时序串行,建立前后关系
- 缺点:对超长依赖关系失效,不好并行化
NLP & CNN
- 文本是1维时间序列
- 1D CNN,并行计算
- 缺点:CNN擅长局部信息,卷积核尺寸和长距离依赖的balance
NLP & transformer
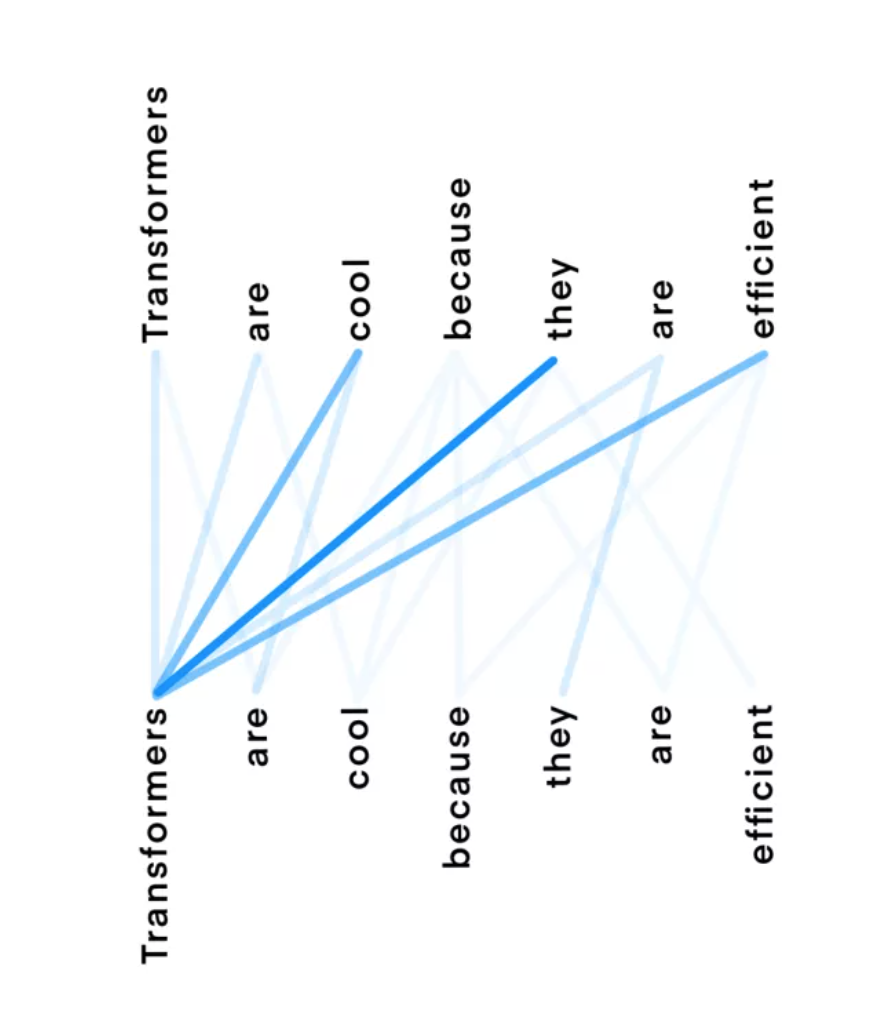
- 对流入的每个单词,建立其对词库的权重映射,权重代表attention
- 自注意力机制
建立长距离依赖
put in CV
- 插入类似的自注意力层
- 完全抛弃卷积层,使用Transformers
RNN & LSTM & GRU cell
标准要素:输入x、输出y、隐层状态h
RNN
- RNN cell每次接收一个当前输入$x_t$,和前一步的隐层输出$h_{t-1}$,然后产生一个新的隐层状态$h_t$,也是当前的输出$y_t$
- formulation:$y_t, h_t = f(x_t, h_{t-1})$
- same parameters for each time step:同一个cell每个time step的权重共享
一个问题:梯度消失/爆炸
- 考虑hidden states’ chain的简化形式:$h_t = \theta^t h_0$,一个sequence forward下去就是same weights multiplied over and over again
- 另外tanh也是会让神经元梯度消失/爆炸
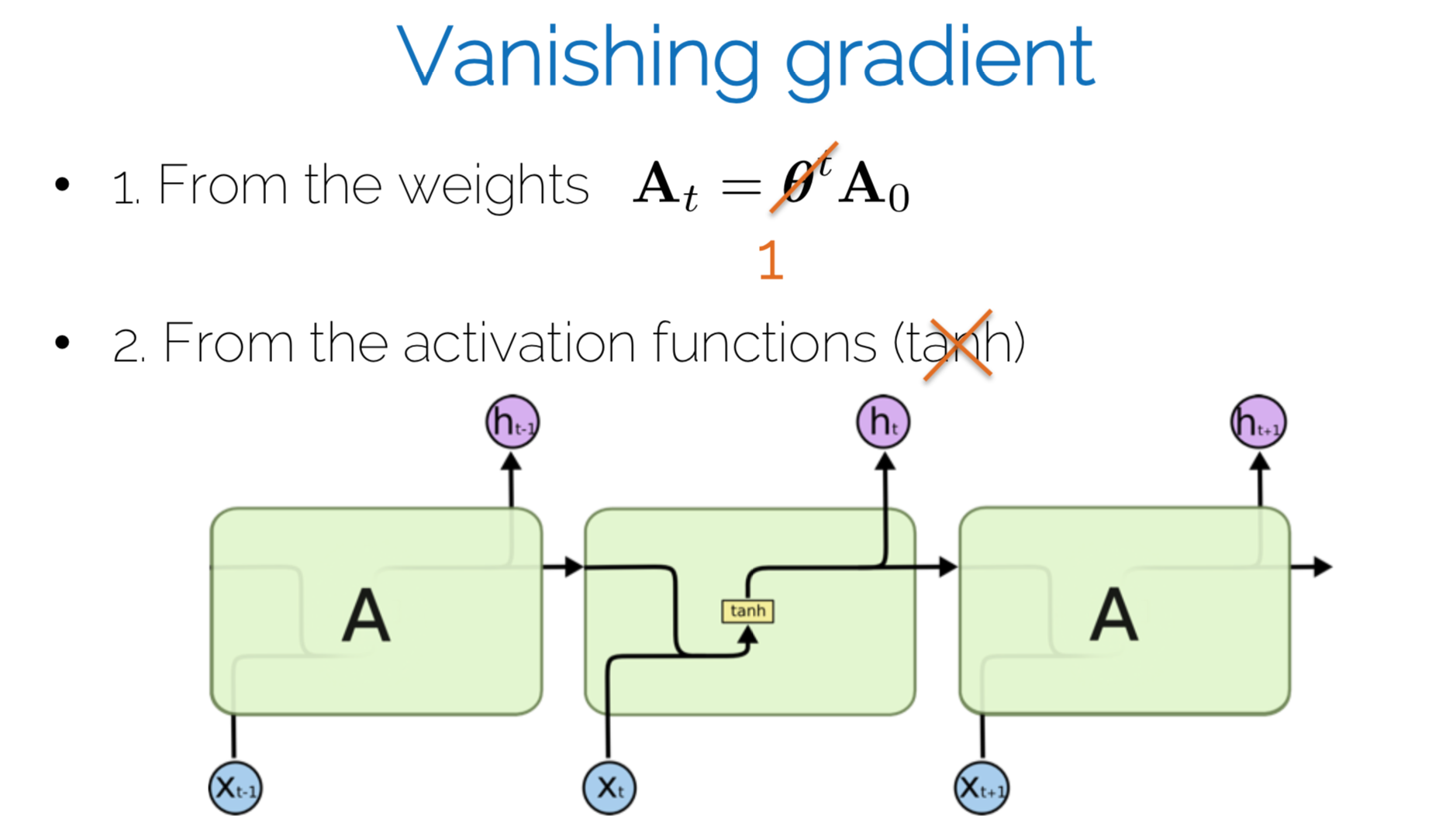
LSTM
key ingredient
- cell:增加了一条cell state workflow,优化梯度流
- gate:通过门结构删选携带信息,优化长距离关联
可以看到LSTM的循环状态有两个:细胞状态$c_t$和隐层状态$h_t$,输出的$y_t$仍旧是$h_t$
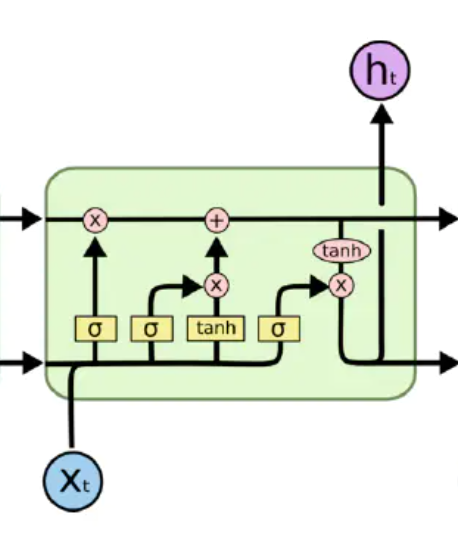
GRU
LSTM的变体,仍旧是门结构,比LSTM结构简单,参数量小,据说更好训练
papers
[一个列了很多论文的主页] https://github.com/dk-liang/Awesome-Visual-Transformer
[经典考古]
* [Seq2Seq 2014] Sequence to Sequence Learning with Neural Networks,Google,最早的encoder-decoder stacking LSTM用于机翻
* [self-attention/Transformer 2017] Transformer: Attention Is All You Need,Google,
* [bert 2019] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,Google,NLP,输入single sentence/patched sentences,用Transformer encoder提取bidirectional cross sentence representation,用输出的第一个logit进行分类
[综述]
* [综述2020] Efficient Transformers: A Survey,Google,
* [综述2021] Transformers in Vision: A Survey,迪拜,
* [综述2021] A Survey on Visual Transformer,华为,
[classification]
* [ViT 2020] AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE,Google,分类任务,用transformer的encoder替换CNN再加分类头,每个feature patch作为一个input embedding,channel dim是vector dim,可以看到跟bert基本一样,就是input sequence换成patch,后续基于它的提升有DeiT、LV-ViT
* [BotNet 2021] Bottleneck Transformers for Visual Recognition,Google,将CNN backbone最后几个stage替换成MSA
* [CvT 2021] CvT: Introducing Convolutions to Vision Transformers,微软,
* [Swin 2021] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows,微软
* [PVT2021] Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions,跟swin一样也是multi-scale features
[detection]
* [DeTR 2020] DeTR: End-to-End Object Detection with Transformers,Facebook,目标检测,CNN+transformer(en-de)+预测头,每个feature pixel作为一个input embedding,channel dim是vector dim
* [Deformable DETR]
* [Anchor DETR]
* 详见《det-transformers》
[segmentation]
* [SETR] Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers,复旦,水,感觉就是把FCN的back换成transformer
[Unet+Transformer]:
* [UNETR 2021] UNETR: Transformers for 3D Medical Image Segmentation,英伟达,直接使用transformer encoder做unet encoder
* [TransUNet 2021] TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation,encoder stream里面加transformer block
* [TransFuse 2021] TransFuse: Fusing Transformers and CNNs for Medical Image Segmentation,大学,CNN feature和Transformer feature进行bifusion
* 详见《seg-transformers》
Sequence to Sequence
[a keras tutorial][https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html]
general case
- extract the information of the entire input sequence
- then start generate the output sequence
seq2seq model workflow
- a (stacking of) RNN layer acts as encoder
- processes the input sequence
- returns its own internal state:不要RNN的outputs,只要internal states
- encoder编码得到的东西叫Context Vector
- a (stacking of) RNN layer acts as decoder
- given previous characters of the target sequence
- it is trained to predict the next characters of the target sequence
- teacher forcing:
- 输入是target sequence,训练目标是使模型输出offset by one timestep的target sequence
- 也可以不teacher forcing:直接把预测作为next step的输入
- Context Vector的同质性:每个step,decoder都读取一样的Context Vector作为initial_state
- when inference
- 第一步获取input sequence的state vectors
- repeat
- 给decoder输入input states和out sequence(begin with a 起始符)
- 从prediction中拿到next character
- append the character to the output sequence
- until:得到end character / hit the character limit
- a (stacking of) RNN layer acts as encoder
implementation
https://github.com/AmberzzZZ/transformer/blob/master/seq2seq.py
one step further
- 改进方向
- bi-directional RNN:粗暴反转序列,有效涨点
- attention:本质是将encoder的输出Context Vector加权
- ConvS2S:还没看
- 主要都是针对RNN的缺陷提出
- 改进方向
动机
- present a general end-to-end sequence learning approach
- multi-layered LSTMs
- encode the input seq to a fix-dim vector
- decode the target seq from the fix-dim vector
- LSTM did not have difficulty on long sentences
reversing the order of the words improved performance
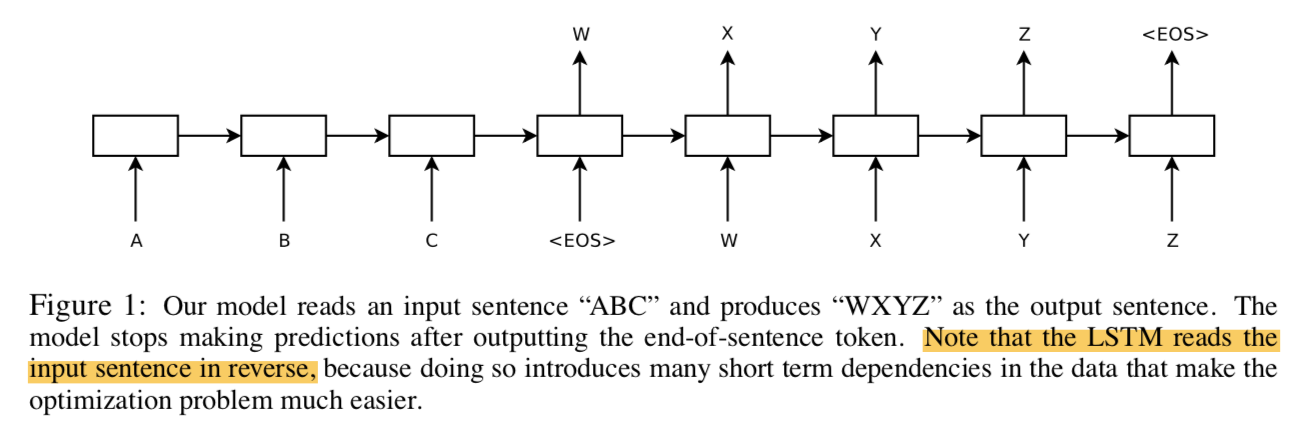
- present a general end-to-end sequence learning approach
方法
standard RNN
given a sequence $(x_1, x_2, …, x_T)$
iterating:
如果输入、输出的长度事先已知且固定,一个RNN网络就能建模seq2seq model了
如果输入、输出的长度不同、并且服从一些更复杂的关系?就得用两个RNN网络,一个将input seq映射成fixed-sized vector,另一个将vector映射成output seq,but long-term-dependency issue
LSTM
- LSTM是始终带着全部seq的信息的,如上图那样
our actual model
- use two LSTMs:encoder-decoder能够增加参数量
- an LSTM with four layers:deeper
- input sequence倒序:真正的句首更接近trans的句首,makes it easy for SGD to establish communication
training details
- LSTM:4 layers,1000 cells
- word-embedding:1000-dim,(input vocab 160,000, output vocab 80,000)
- naive softmax
- uniform initialization:(-0.08, 0.08)
- SGD,lr=0.7,half by every half epoch,total 7.5 epochs
- gradient norm [10, 25]
- all sentences in a minibatch are roughly of the same length
Transformer: Attention Is All You Need
动机
- sequence2sequence models
- encoder + decoder
- RNN / CNN + an attention path
- we propose Transformer
- base solely on attention mechanisms
- more parallelizable and less training time
- sequence2sequence models
论点
- sequence modeling
- 主流:RNN,LSTM,gated
- align the positions to computing time steps
- sequential本质阻碍并行化
- Attention mechanisms acts as a integral part
- in previous work used in conjunction with the RNN
- 为了并行化
- some methods use CNN as basic building blocks
- difficult to learn dependencies between distant positions
- 主流:RNN,LSTM,gated
- we propose Transformer
- rely entirely on an attention mechanism
- draw global dependencies
- self-attention
- relating different positions of a single sequence
- to generate a overall representation of the sequence
- sequence modeling
方法
encoder-decoder
- encoder:doc2emb
- given an input sequence of symbol representation $(x_1, x_2, …, x_n)$
- map to a sequence of continuous representations $(z_1, z_2, …, z_n)$,(embeddings)
- decoder:hidden layers
- given embeddings z
- generate an output sequence $(y_1, y_2, …, y_m)$ one element at a time
- the previous generated symbols are served as additional input when computing the current time step
- encoder:doc2emb
Transformer Architecture
Transformer use
- for both encoder and decoder
stacked self-attention and point-wise fully-connected layers
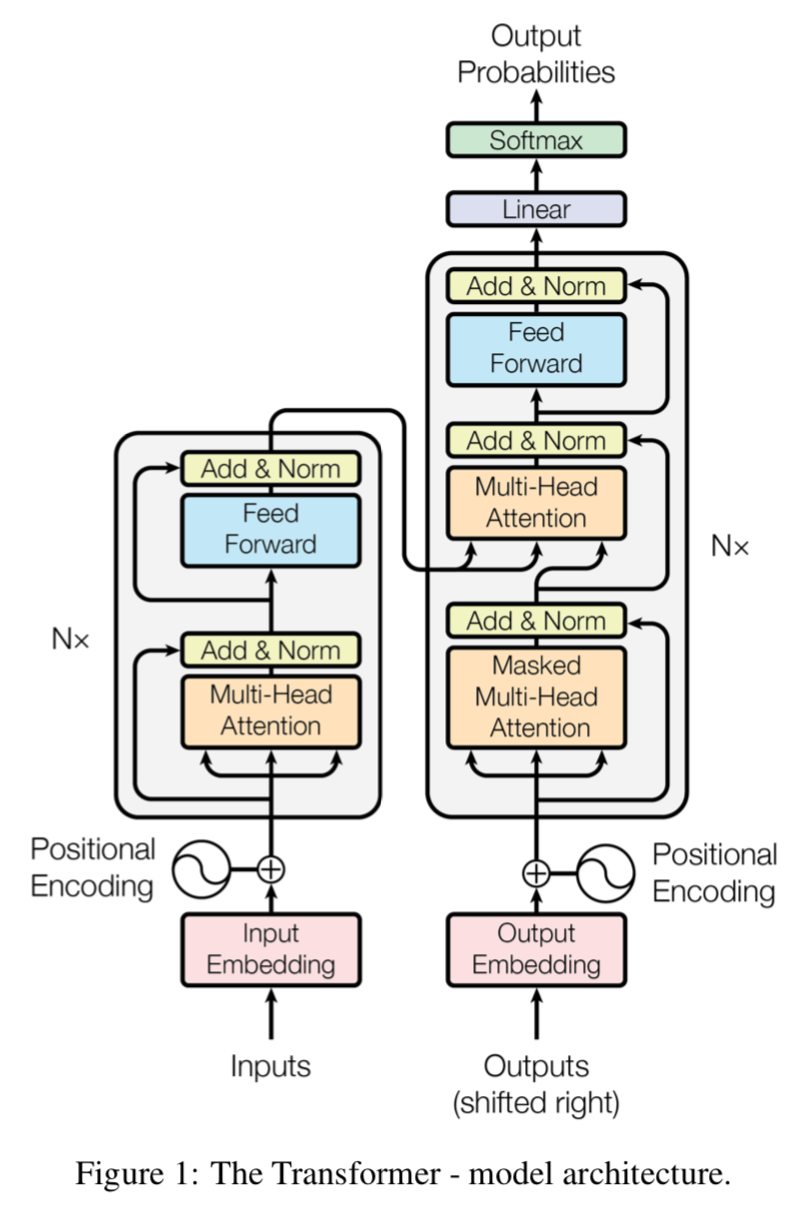
encoder
- N=6 identical layers
- each layer has 2 sub-layers
- multi-head self-attention mechanism
- postision-wise fully connected layer
- residual
- for two sub-layers independently
- add & layer norm
- d=512
decoder
- N=6 identical layers
- 3 sub-layers
- [new] masked multi-head self-attention:combine了先验知识,output embedding只能基于在它之前的time-step的embedding计算
- multi-head self-attention mechanism
- postision-wise fully connected layer
- residual
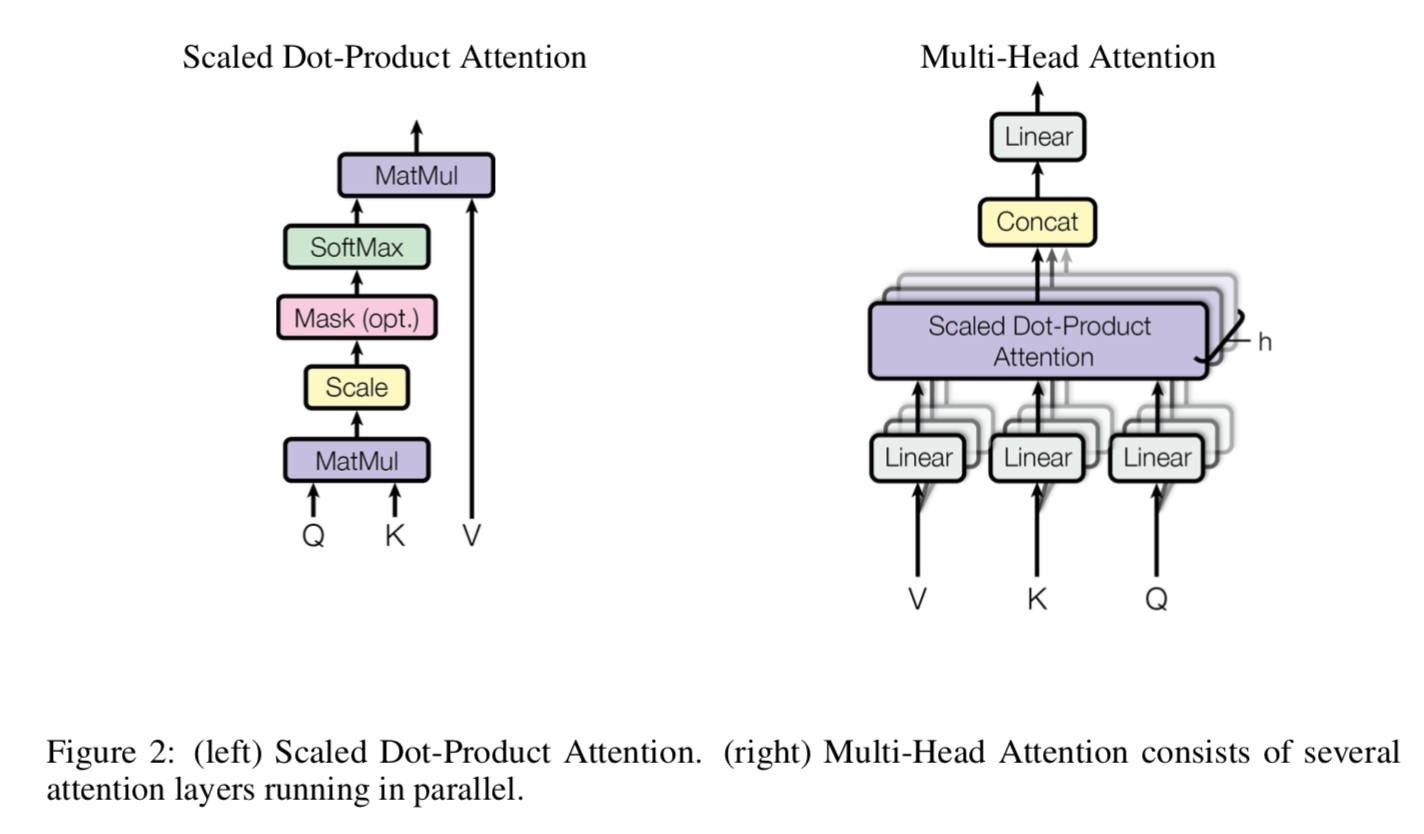
attention
- reference:https://bbs.cvmart.net/articles/4032
- step1:project embedding to query-key-value pairs
- $Q = W_Q^{dd} A^{dN}$
- $K = W_K^{dd} A^{dN}$
- $V = W_V^{dd} A^{dN}$
- step2:scaled dot-product attention
- $A^{N*N}=softmax(K^TQ/\sqrt{d})$
- $B^{dN} = V^{dN}A^{N*N}$
- multi-head attention
- 以上的step1&step2操作performs a single attention function
- 事实上我们可以用多组projection得到多组$\{Q,K,V\}^h$,in parallel地执行attention运算,得到多组$\{B^{d*N}\}^h$
- concat & project
- concat in d-dim:$B\in R^{(dh)N}$
- linear project:$out = W^{d(dh)} B$
- h=8
- $d_{in}/h=64$:embedding的dim
- $d_{out}=64$:query-key-value的dim
positional encoding
数学本质是一个hand-crafted的映射矩阵$W^P$和one-hot的编码向量$p$:
用PE表示e
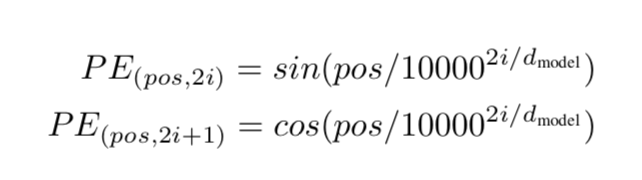
- pos是sequence x上的position
- 2i和2i+1是embedding a上的idx
point-wise feed-forward network
- fc-ReLU-fc
- dim_fc=2048
- dim_in & dim_out = 512
运行过程
encoder是可以并行计算的
- 输入是sequence embedding和positional embedding:$A\in R^{d*N}$
- 经过repeated blocks
- 输出是另外一个sequence:$B\in R^{d*N}$
- self-attention:Q、K、V是一个东西
- encoder的本质就是在解析自注意力:
- 并行的全局两两比较,一步到位
- RNN要by step
- CNN要stack layers
decoder是在训练阶段是可以并行的,在inference阶段by step
输入是encoder的输出和上一个time-step decoder的输出embedding
输出是当前time-step对应position的输出词的概率
第一个attention layer是out embedding的self-attention:要实现像RNN一样依次解码出来,每个time step要用到上一个位置的输出作为输入——masking
- given输入sequence是\ I have a cat,5个元素
- 那么mask就是$R^{5*5}$的下三角矩阵
输入embedding经过transformation变成Q、K、V三个矩阵
仍旧是$A=K^TQ$计算attention
这里有一些attention是非法的:位置靠前的query只能用到比他位置更靠前的query,因此要乘上mask矩阵:$A=M A$
softmax:$A=softmax(A)$
scale:$B = VA$
concat & projection
- 第二个attention layer是in & out sequence的注意力,其key和value来自encoder,query来自上一个decoder block的输出
why self-attention
- 衡量维度
- total computational complexity per layer
- amount of computation that can be parallelized
- path-length between long-range dependencies
- given input sequence with length N & dim $d_{in}$,output sequence with dim $d_{out}$
- RNN need N sequencial operations of $W\in R^{d_{in} * d_{out}}$
- CNN need N/k stacking layers of $d_{in}d_{out}$ sequence operations of $W\in R^{kk}$,generally是RNN的k倍
- 衡量维度
training
- optimizer:$Adam(lr, \beta_1=0.9, \beta_2=0.98, \epsilon=10^{-9})$
- lrschedule:warmup by 4000 steps,then decay
dropout
- residual dropout:就是stochastic depth
- dropout to the sum of embeddings & PE for both encoder and decoder
- drop_rate = 0.1
label smoothing:smooth_factor = 0.1
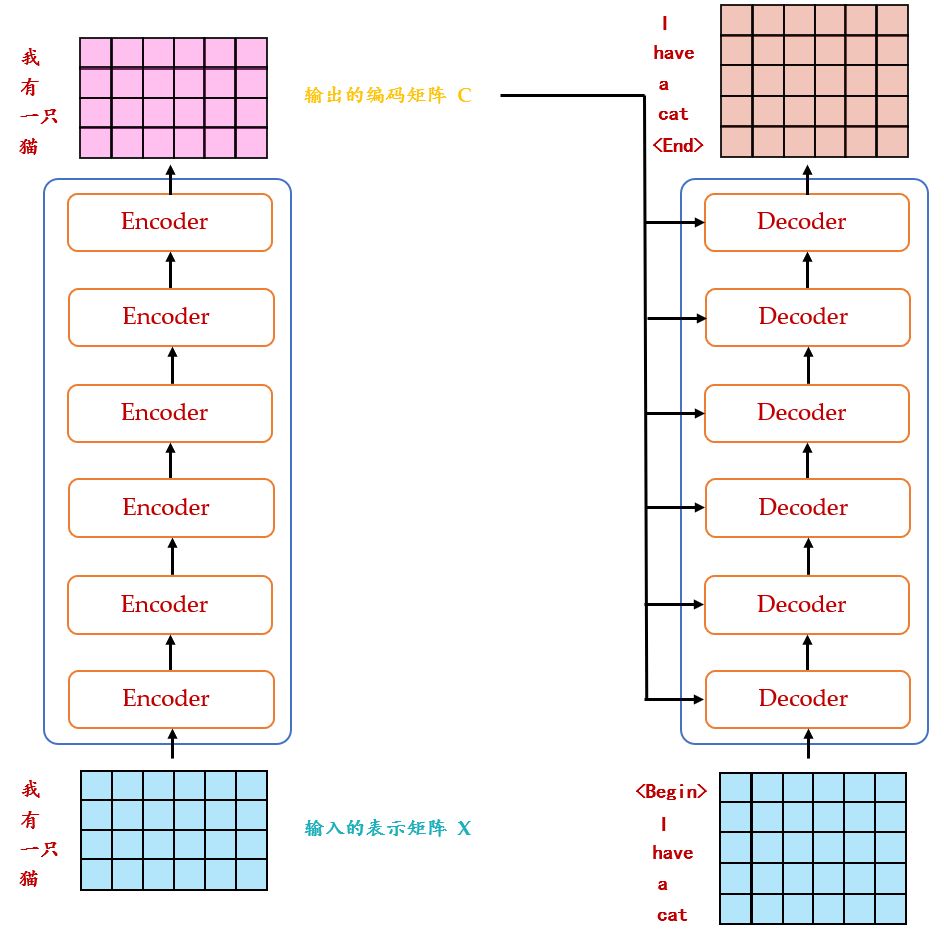
实验
- A:vary the number of attention heads,发现多了少了都hurts
- B:reduce the dim of attention key,发现hurts
- C & D:大模型+dropout helps
- E:learnable & sincos PE:nearly identical
最后是big model的参数
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
动机
- BERT:Bidirectional Encoder Representations from Transformers
- Bidirectional
- Encoder
- Representations
- Transformers
- workflow
- pretrain bidirectional representations from unlabeled text
- tune with one additional output layer to obtain the model
- SOTA
- GLUE score 80.5%
- BERT:Bidirectional Encoder Representations from Transformers
论点
- pretraining is effective in NLP tasks
- feature-based method:use task-specfic architectures,仅使用pretrained model的特征
- fine-tuining method:直接fine-tune预训练模型
- 两种方法在预训练阶段训练目标一致:use unidirectional language models to learn general language representations
- reduce the need for many heavily-engineered task- specific architectures
- current methods’ limitations
- unidirectional:
- limit the choice of architectures
- 事实上token的上下文都很重要,不能只看上文
- 简单的concat两个independent的L2R和R2L模型(biRNN)
- independent
- shallow concat
- unidirectional:
- BERT
- masked language model:在一个sequence中预测被遮挡的词
- next sentence prediction:trains text-pair representations
- pretraining is effective in NLP tasks
方法
two steps
- pre-training
- unlabeled data
- different pretraining tasks
- fine-tuning
- labeled data of the downstream tasks
- fine-tune all the params
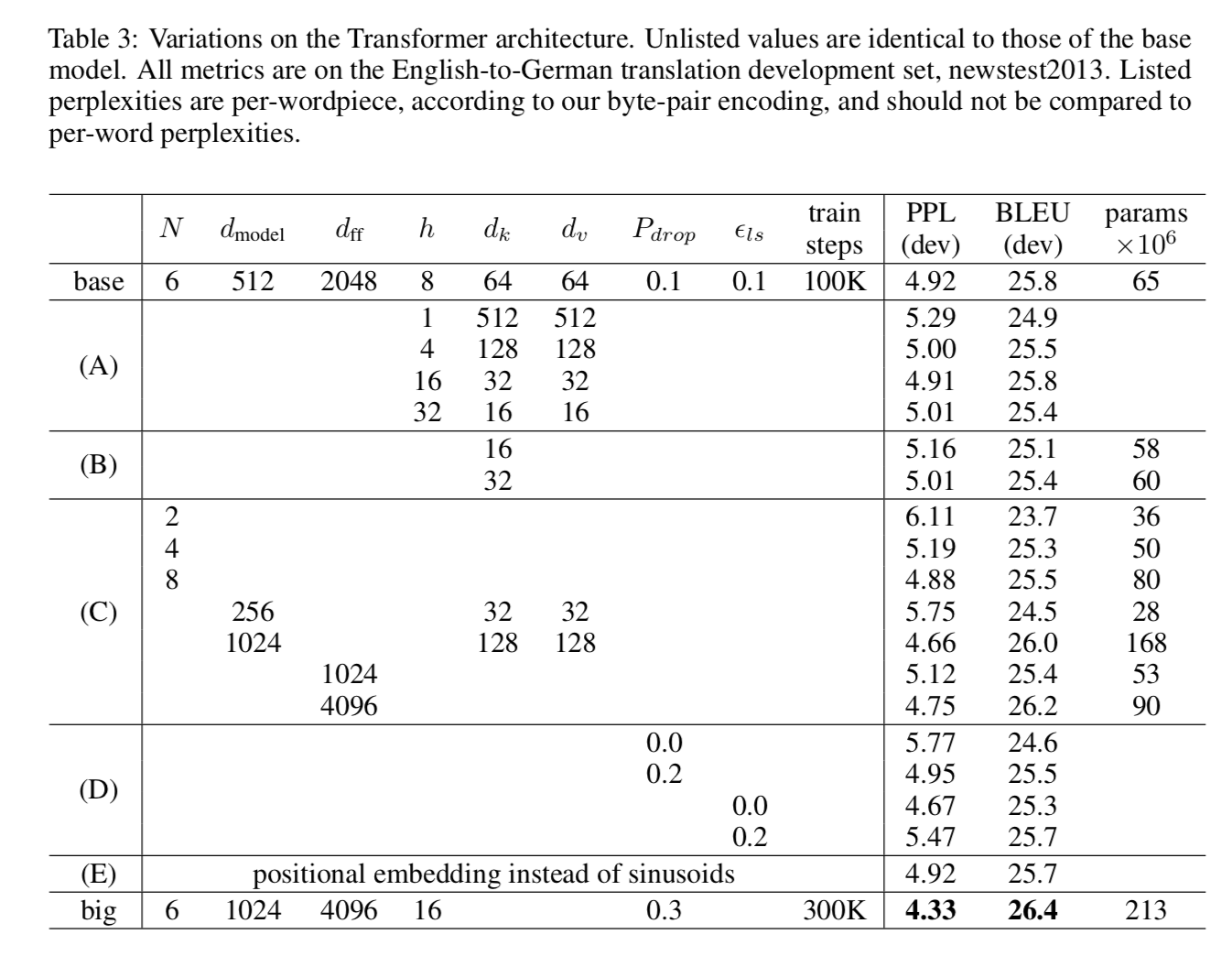
两个阶段的模型,只有输出层不同
- 例如问答模型
- pretraining阶段,输入是两个sentence,输入的起始有一个CLS symbol,两个句子的分隔有一个SEP symbol
- fine-tuning阶段,输入分别是问和答,【输出是啥?】
- pre-training
architecture
multi-layer bidirectional Transformer encoder
- number of transfomer blocks L
- hidden size H
- number of self-attention heads A
- FFN dim 4H
Bert base:L=12,H=768,A=12
Bert large:L=24,H=1024,A=16
input/output representations
- a single sentence / two packed up sentence:
- 拼接的sentence用特殊token SEP衔接
- segment embedding:同时add a learned embedding to every token indicating who it belongs
- use WordPiece embeddings with 30000 token vocabulary
- 输入sequence的第一个token永远是一个特殊符号CLS,它对应的final state输出作为sentence整体的representation,用于分类任务
overall网络的input representation是通过将token embeddings拼接上上特殊符号,加上SE和PE得到
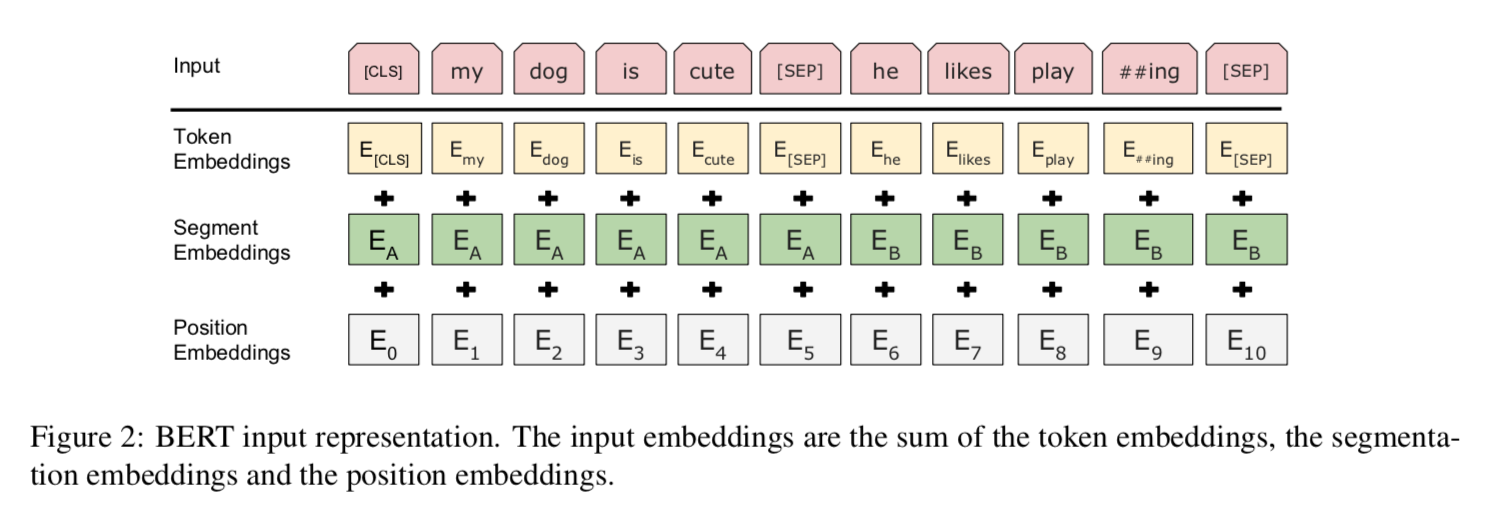
- a single sentence / two packed up sentence:
pre-training
- two unsupervised tasks
- Masked LM (MLM)
- mask some percentage of the input tokens at random:15%
- 80%的概率用MASK token替换
- 10%的概率用random token替换
- 10%的概率unchanged
- then predict those masked tokens
- the final hidden states corresponding to the masked tokens are fed into a softmax
- 相比较于传统的left2right/right2left/concat模型
- 既有前文又有后文
- 只预测masked token,而不是全句预测
- mask some percentage of the input tokens at random:15%
- Next Sentence Prediction (NSP)
- 对于relationship between sentences:
- 例如question&answer,句子推断
- not direatly captured by language modeling,模型直观学习的是token relationship
- binarized next sentence prediction task
- 选取sentence A&B:
- 50%的概率是真的上下文(IsNext)
- 50%的概率是random(NotNext)
- 构成了一个二分类问题:仍旧用CLS token对应的hidden state C来预测
- 选取sentence A&B:
- 对于relationship between sentences:
- Masked LM (MLM)
- two unsupervised tasks
fine-tuning
- BERT兼容many downstream tasks:single text or text pairs
- 直接组好输入,end-to-end fine-tuning就行
- 输出还是用CLS token对应的hidden state C来预测,接分类头
A Survey on Visual Transformer
动机
- provide a comprehensive overview of the recent advances in visual transformers
- discuss the potential directions for further improvement
develop timeline
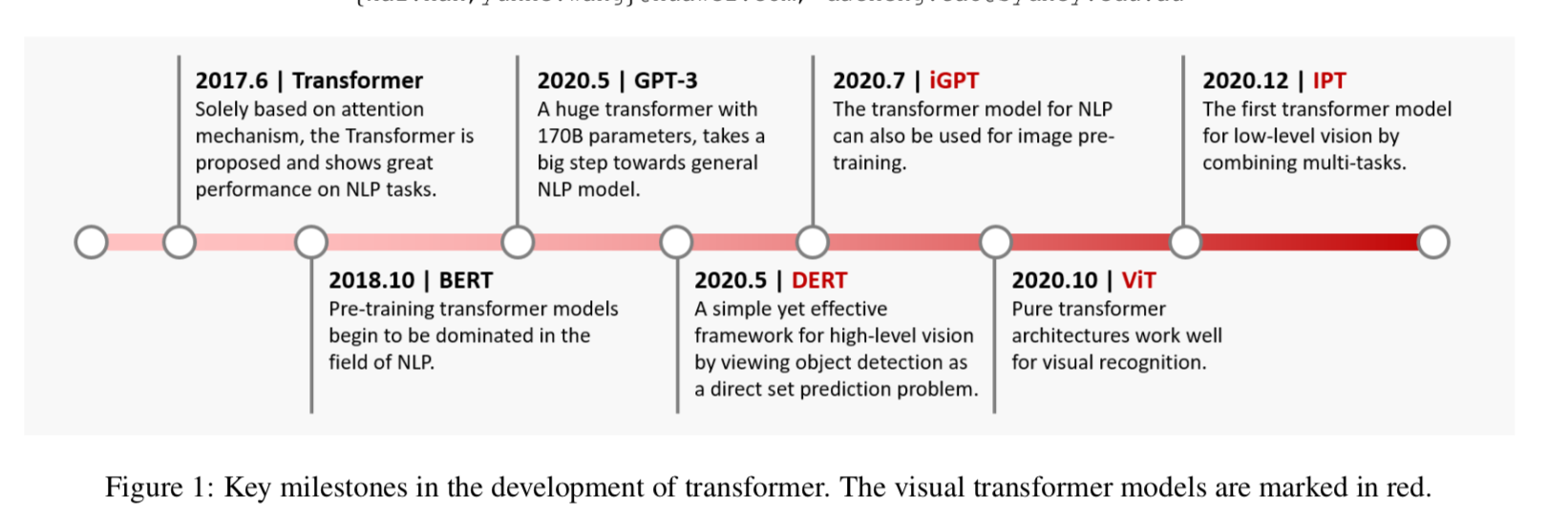
按照应用场景分类
- backbone:分类
- high/mid-level vision:通常是语义相关的,检测/分割/姿态估计
- low-level vision:对图像本身进行操作,超分/图像生成,目前应用较少
video processing
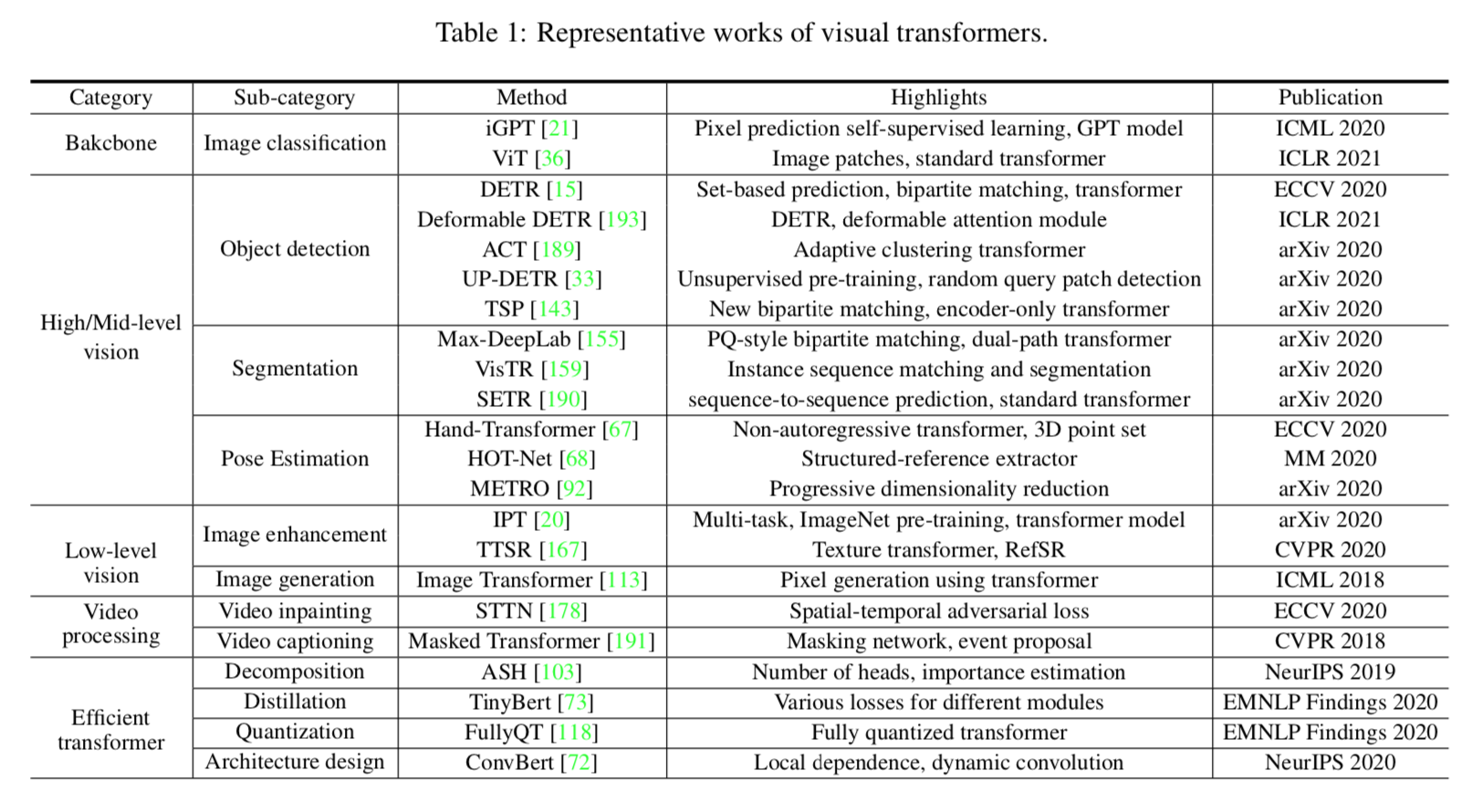
revisiting transformer
key-concepts:sentence、embedding、positional encoding、encoder、decoder、self-attention layer、encoder-decoder attention layer、multi-head attention、feed-forward neural network
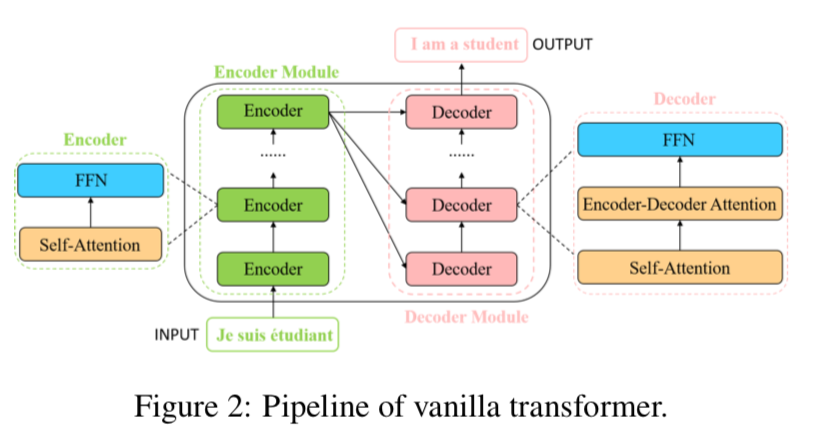
self-attention layer
- input vector is transformed into 3 vectors
- input vector is embedding+PE(pos,i):pos是word在sequence中的位置,i是PE-element在embedding vec中的位置
- query vec q
- key vec k
- value vec v
- $d_q = d_k = d_v = d_{model} = 512$
- then calculate:$Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V$
- encoder-decoder attention layer
- K和V是从encoder中拿到
- Q是从前一层拿到
- 计算是相似的
- input vector is transformed into 3 vectors
- multi-head attention
- 一个attention是一个softmax,对应了一对强相关,同时抑制了其他word的相关性
- 考虑一个词往往与几个词强相关,这就需要多个attention
- multi-head:different QKV matrices are used for different heads
- given a input vector,the number of heads h
- 先产生h个
- $d_q=d_k=d_v=d_{model}/h=64$
- 这h个pair,分别计算attention vector,得到h个[b,d]的context vector
- concat along-d-axis and linear projection to final [b,d] vector
- 先产生h个
- residual & layer-norm:layer-norm在residual-add以后
- feed-forward network
- fc-GeLU-fc
- $d_h=2048$
- final-layer in decoder
- dense+softmax
- $d_{words}=$ number of words in the vocabulary
- when applied in CV tasks
- most transformers adopt the original transformer’s encoder module
- used as a feature selector
- 相比较于CNN,能够capture long-distance characteristics,derive global information
- 相比较于RNN,能够并行计算
- 计算量
- 首先是三个线性层:线性时间复杂度O(n),计算量与$d_{model}$成正比
- 然后是self-attention层:QKV矩阵乘法运算,平方时间复杂度O(n^2)
- multi-head的话,还有一个线性层:平方时间复杂度O(n^2)
revisiting transformers for NLP
- 最早期的RNN + attention:rnn的sequential本质影响了长距离/并行化/大模型
transformer的solely attention结构:解决以上问题,促进了large pre-trained models (PTMs) for NLP
BERT and its variants
- are a series of PTMs built on the multi-layer transformer encoder architecture
- pre-trained
- Masked language modeling
- Next sentence prediction
- fine-tuned
- add an output layer
- Generative Pre-trained Transformer models (GPT)
- are another type of PTMs based on the transformer decoder architecture
- masked self-attention mechanisms
- pre-trained
- 与BERT最大的不同是有向性
visual transformer
【category1】: backbone for image classification
- transformer的输入是tokens,在NLP里是embedding形式的分词序列,在CV里就是representing a certain semantic concept的visual token
- visual token可以来自CNN的feature
- 也可以直接来自image的小patch
purely use transformer来做image classification任务的模型有iGPT、ViT、DeiT
iGPT
- pretraining stage + finetuning stage
- pre-training stage
- self-supervised:自监督,所以结果较差
- given an unlabeled dataset
- train the model by minimizing the -log(density),感觉是在force光栅排序正确
- fine-tuning stage
- average pool + fc + softmax
- jointly train with L_gen & L_CE
- ViT
- pre-trained on large datasets
- standard transformer’s encoder + MLP head
- treats all patches equally
- 有一个类似BERT class token的东西
- 从训练的角度,gather knowledge of the entire class
- inference的时候,只拿了这第一个logit用来做预测
- fine-tuning
- 换一个zero-initialized的MLP head
- use higher resolution & 插值pe
- pre-trained on large datasets
- DeiT
- Data-efficient image transformer
- better performance with
- a more cautious training strategy
- and a token-based distillation
- transformer的输入是tokens,在NLP里是embedding形式的分词序列,在CV里就是representing a certain semantic concept的visual token
【category2】: High/Mid-level Vision
【category3】: Low-level Vision
【category4】: Video Processing
efficient transformer:瘦身&加速
- Pruning and Decomposition
- Knowledge Distillation
- Quantization
Compact Architecture Design
ViT: AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
动机
- attention in vision
- either in conjunction with CNN
- or replace certain part of a CNN
- overall都还是CNN-based
- use a pure transformer to sequence of image patches
- verified on image classification tasks in supervised fashion
- attention in vision
论点
- transformer lack some inductive biases inherent to CNNs,所以在insufficient data上not generalize well
- however large scale training trumps inductive bias,大数据集上ViT更好
- naive application of self-attention
- 建立pixel之间的两两关联:计算量太大了
- 需要approximation:local/改变size
- we use transformer
- wih global self-attention
- to full-sized images
方法
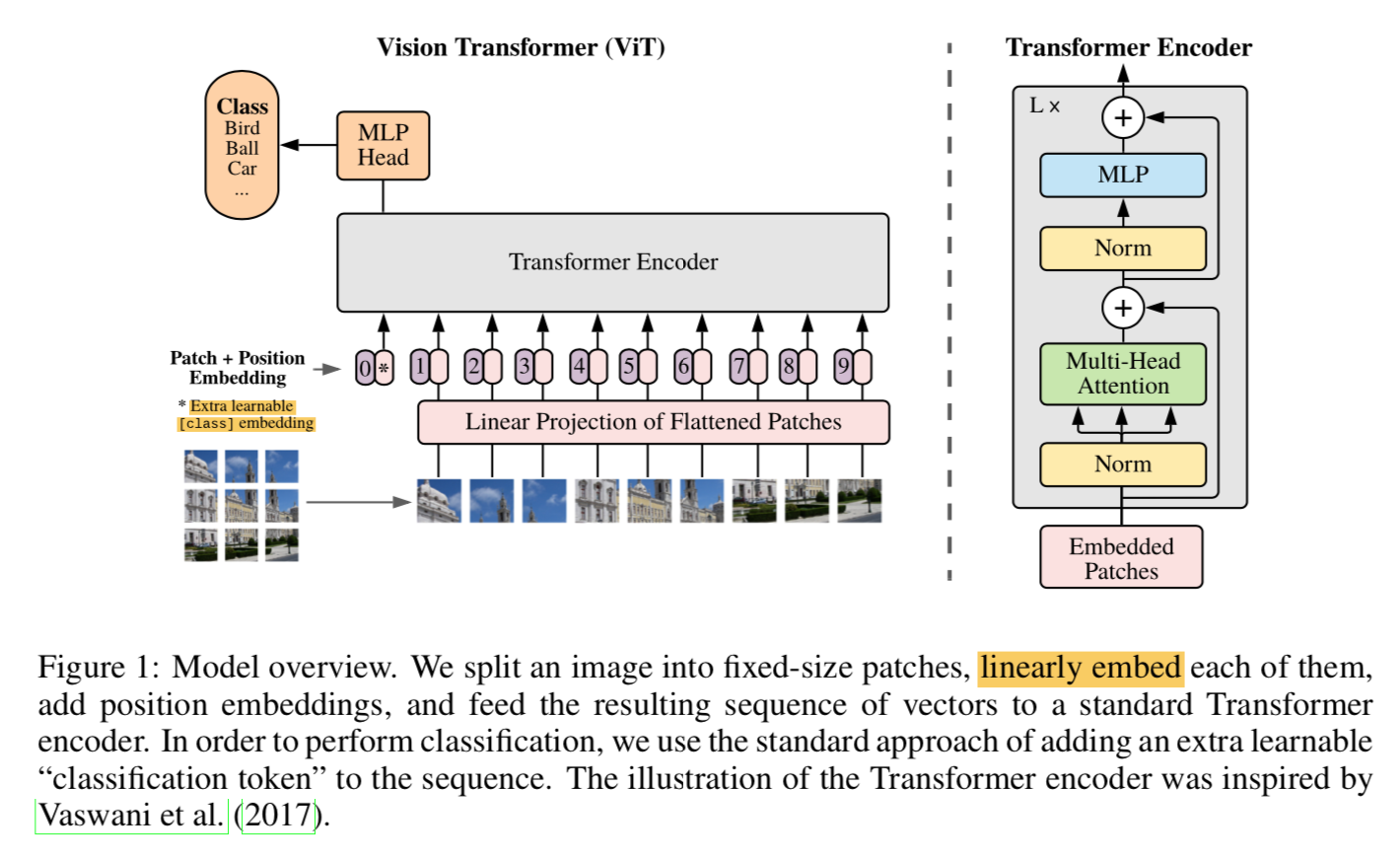
input 1D-embedding sequence
- 将image $x\in R^{HWC}$ 展开成patches $\{x_p \in R^{P^2C}\}$
- thus sequence length $N=HW/P^2$
- patch embedding:
- use a trainable linear projection
- fixed dimension size through-all
- position embedding:
- add to patch embedding
- standard learnable 1D position embedding
- prepended embedding:
- 前置的learnable embedding $x_{class}$
- similar to BERT’s class token
- 以上三个embedding组合起来,作为输入sequence
transformer encoder
- follow the original Transformer
- 交替的MSA和MLP
- layer norm LN
- residual
GELU
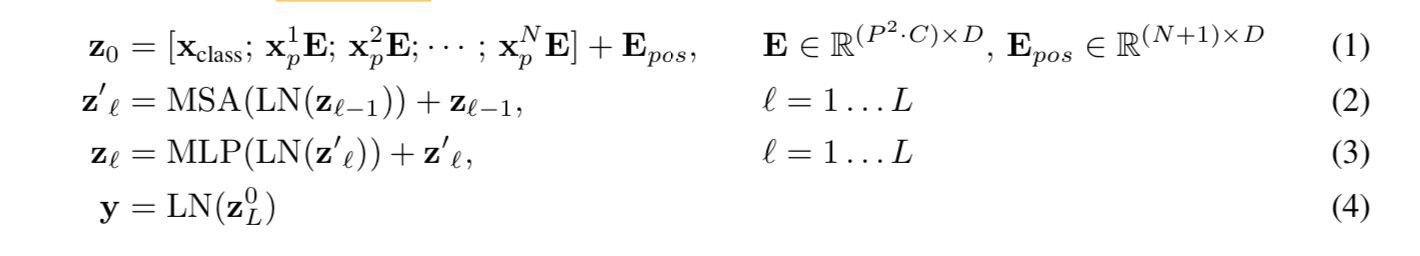
hybrid architecture
- input sequence也可以来源于CNN的feature maps
- patch size可以是1x1
classification head
- attached to $z_L^0$:是class token用来做预测
- pre-training的时候是MLP
- fine-tuning的时候换一个zero-initialized的single linear layer
workflow
- typically先pre-train on large datasets
- 再fine-tune to downstream tasks
- fine-tune的时候替换一个zero-initialized的新线性分类头
- when feeding images with higher resolution
- keep the patch size
- results in larger sequence length
- 这时候pre-trained PE就no longer meaningful了
- we therefore perform 2D interpolation基于它在原图上的位置
training details
- Adam:$\beta_1=0.9,\beta_2=0.999$
- batch size 4096
- high weight decay 0.1
- linear lr warmup & decay
fine-tuning details
- SGDM
- cosine LR
- no weight decay
- 【????】average 0.9999
win Transformer: Hierarchical Vision Transformer using Shifted Windows
动机
- use Transformer as visual tasks’ backbone
- challenges of Transformer in vision domain
- large variations of scales of the visual entities
- high resolution of pixels
- we propose hierarchical Transformer
- shifted windows
- self-attention in local windows
- cross-window connection
- verified on
- classification:ImageNet top1 acc 86.4
- detection:COCO box-MAP 58.7
- segmentation:ADE20K
- this paper主要介绍分类,检测是以swin作为backbone,用MaskRCNN等二阶段架构来训练的,分割是以swin作为backbone,用UperNet去训练的,具体模型配置official repo的readme里面有详细列表
论点
- when transfer Transformer’s high performance in NLP domain to CV domain
- differences between the two modalities
- scale:NLP里面,word tokens serves as the basic element,但是CV里面,patch的形态大小都是可变的,previous methods里面,都是统一设定固定大小的patch token
- resolution:主要问题就是self-attention的计算复杂度,是image size的平方
- we propose Swin Transformer
- hierarchial feature maps
- linear computatoinal complexity to image size
- differences between the two modalities
- hierarchical
- start from small patches
- merge in deeper layers
- 所以对不同尺度的特征patch进行了融合
linear complexity
- compute self-attention locally in each window
- 每个window的number of patches是设定好的,window数是与image size成正比的
- 所以是线性
shifted window approach
- 跨层的window shift,建立起相邻window间的桥梁
【QUESTION】all query patches within a window share the same key set
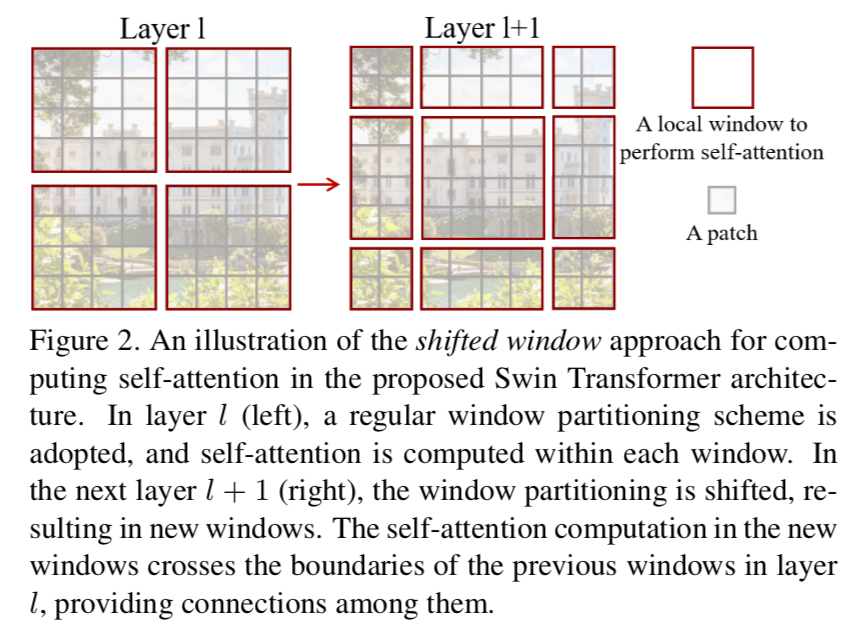
previous attemptations of Transformer
- self-attention based backbone architectures
- 将部分/全部conv layers替换成self-attention
- 模型主体架构还是ResNet
- slightly better acc
- larger latency caused by self-att
- self-attention complement CNNs
- 作为additional block,给到backbone/head,提供长距离信息
- 有些检测/分割网络也开始用了transformer的encoder-decoder结构
- transformer-based vision backbones
- 主要就是ViT及其衍生品
- ViT requires large-scale training sets
- DeiT introduces training strategies
- 但是还存在high resolution计算量的问题
- self-attention based backbone architectures
- when transfer Transformer’s high performance in NLP domain to CV domain
方法
overview
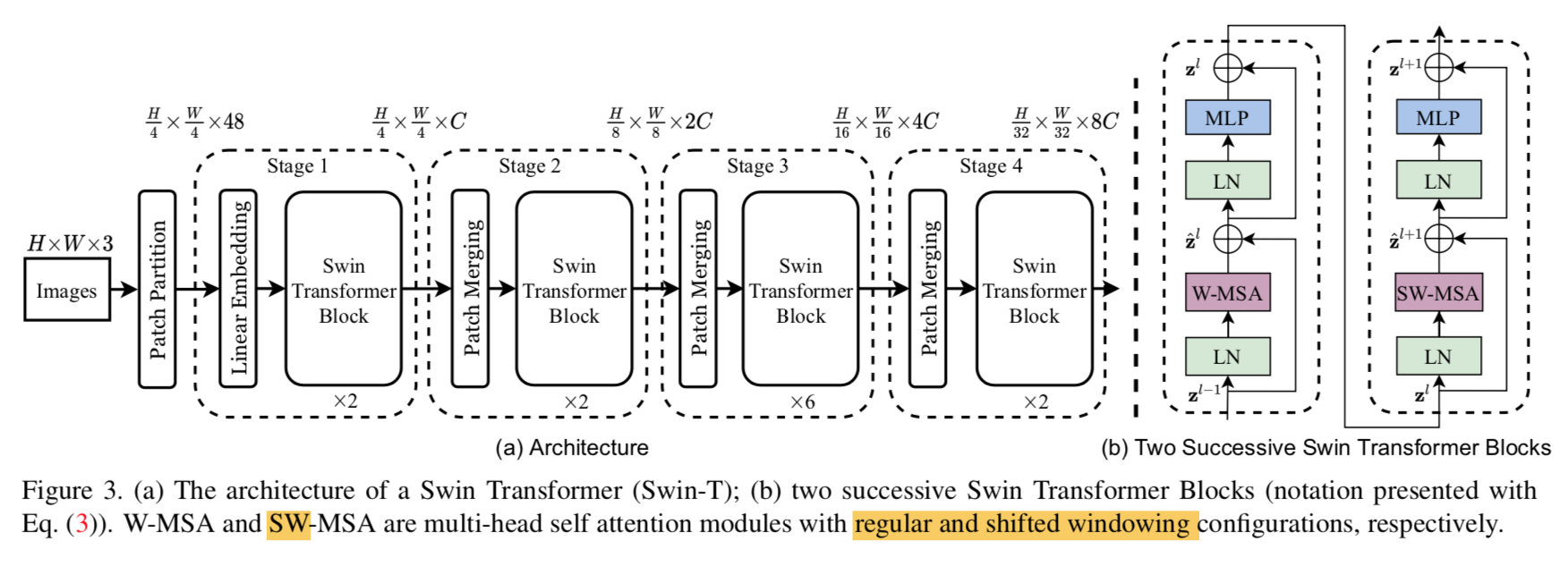
- Swin-T:tiny version
- 第一步是patch partition:
- 将RGB图切成non-overlapping patches
- patches:token,basic element
- feature input dim:with patch size 4x4,dim=4x4x3=48
- 然后是linear embedding layer
- 将raw feature re-projection到指定维度
- 指定维度C:default=96
- 接下来是Swin Transformer blocks
- the number of tokens maintain
- patch merging layers负责reduce the number of tokens
- 第一个patch merging layer concat 所有2x2的neighbor patches:4C-dim vec each
- 然后用了一个线性层re-projection
- number of tokens(resolution):(H/4*W/4)/4 = (H/8*W/8),跟常规的CNN一样变化的
- token dims:2C
- 后面接上一个Transformer blocks
- 合起来叫stage2(stage3、stage4)
Swin Transformer blocks
跟原始的Transformer block比,就是把原始的MSA替换成了window-based的MSA
原始的attention:global computation leads to quadratic complexity
window-based attention:
- attention的计算只发生在每个window内部
- non-overlapping partition
- 很显然lacks connections across windows
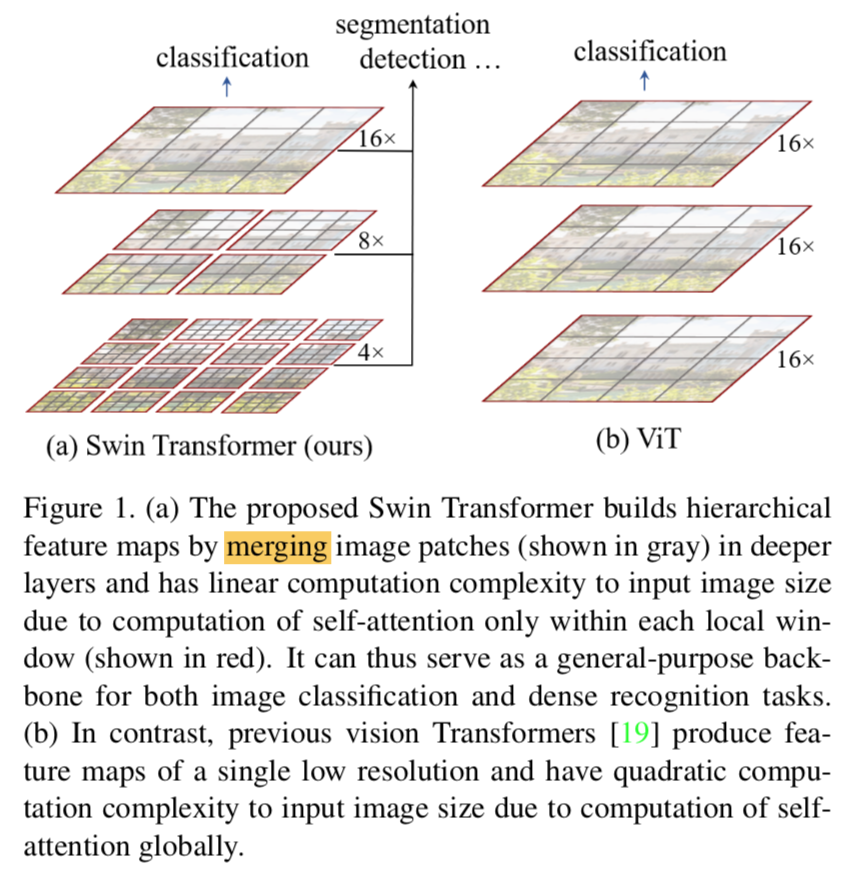
shifted window partitioning in successive blocks
两个attention block
第一个用常规的window partitioning strategy:从左上角开始,take M=4,window size 4x4(一个window里面包含4x4个patch)
第二层的window,基于前一层,各平移M/2
introduce connections between neighbor non-overlapping windows in the previous layer
efficient computation
shifted window会导致window尺寸不一致,不利于并行计算
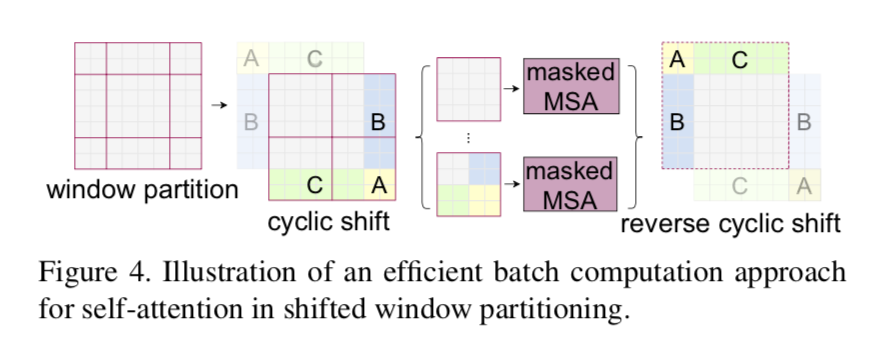
relative position bias
- 我们在MxM的window内部计算local attention:也就是input sequence的time-step是$M^2$
- Q、K、V $\in R ^ {M^2 d}$
- $Attention(Q,K,V)=Softmax(QK^T/\sqrt{d}+B)V$
- 这个B作为local的position bias,在二维上,在每个轴上的变化范围[-M+1,M-1]
- we parameterized a smaller-sized bias matrix $\hat B\in R ^{(2M-1)*(2M-1)}$
- values in $B \in R ^ {M^2*M^2}$ are taken from $\hat B$
- the learnt relative position bias可以用来initialize fine-tuned model
Architecture variants
base model:Swin-B,参数量对标ViT-B
Swin-T:0.25x,对标ResNet-50 (DeiT-S)
Swin-S:0.5x,对标ResNet-101
Swin-L:2x
window size:M=7
query dim:d=32,(每个stage的input sequence dim逐渐x2,heads num逐渐x2)
MLP:expansion ratio=4
channel number C:第一个stage的embdding dim,(后续逐渐x2)
hypers:
- drop_rate:0.0
- drop_path_rate:0.1

acc
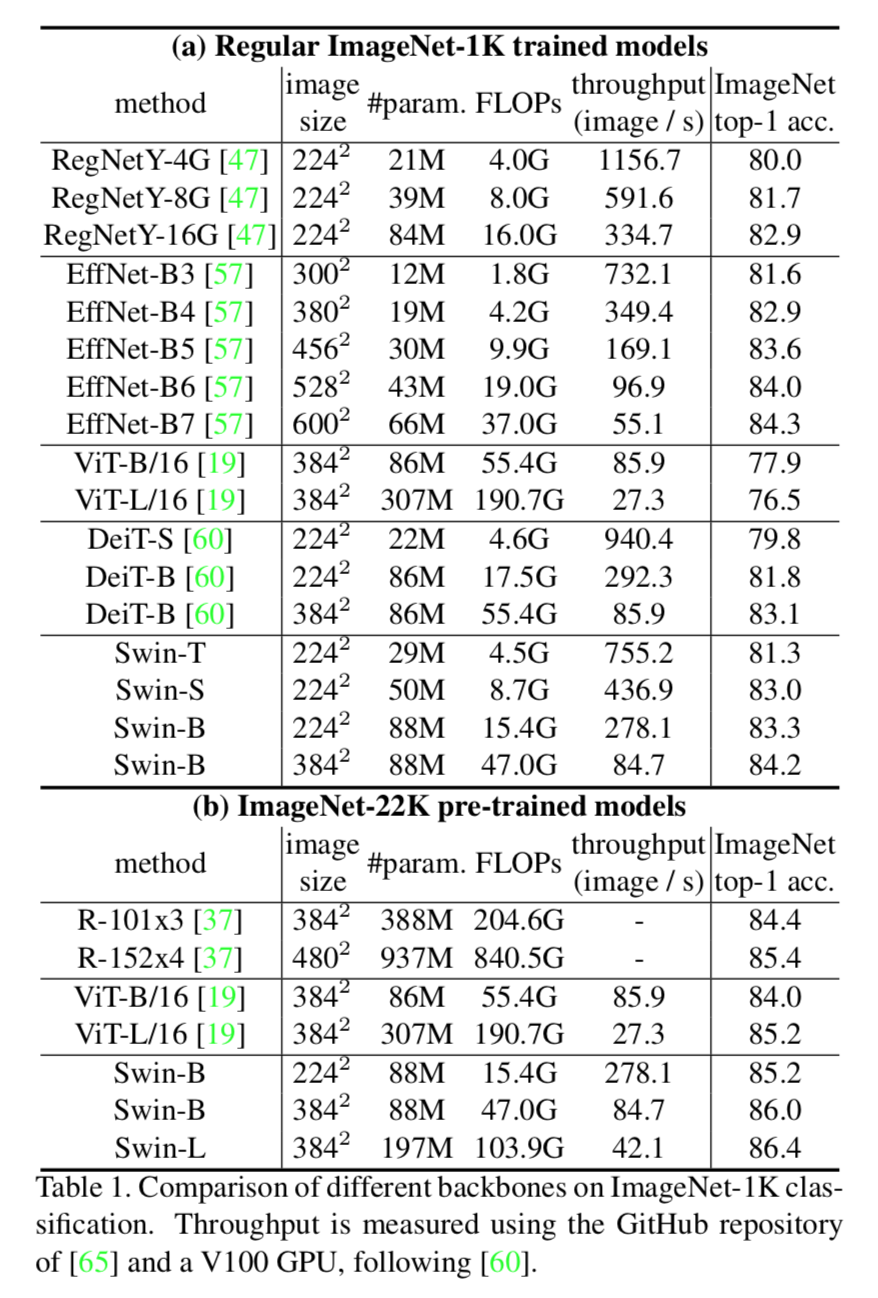
official repo: https://github.com/microsoft/Swin-Transformer/blob/main/get_started.md
keras官方也出了一版:https://github.com/keras-team/keras-io/blob/master/examples/vision/swin_transformers.py
model zoo
model | resolution | C | num_layers | num_heads | window_size
Swin-T | 224 | 96 | {2,2,6,2} | {3,6,12,24} | 7
Swin-S | 224 | 96 | {2,2,18,2} | {3,6,12,24} | 7
Swin-B | 224/384 | 128 | {2,2,18,2} | {4,8,16,32} | 7/12
Swin-L | 224/384 | 192 | {2,2,18,2} | {6,12,24,48} | 7/12
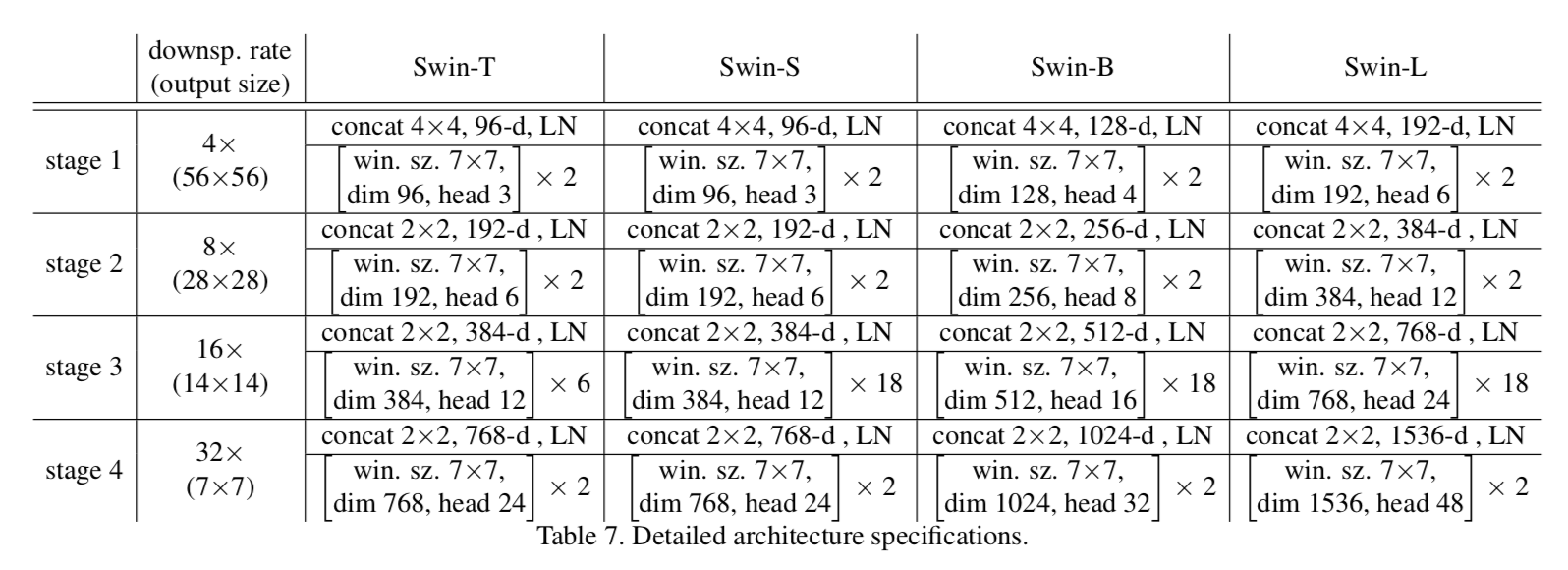
models/build.py
- SwinTransformer & SwinMLP:前者就是论文里的,basic block是transformer的MSA加上MLP layers,后者是没用MSA,就用MLP来建模相邻windows之间的global relationship的,用的conv1d。
DETR: End-to-End Object Detection with Transformers
动机
- new task formulation:a direct set prediction problem
- main gradients
- a set-based global loss
- a transformer en-de architecture
- remove the hand-designed componets like nms & anchor
- acc & run-time on par with Faster R-CNN on COCO
- significantly better performance on large objects
- lower performances on small objects
论点
modern detectors run object detection in an indirect way
- 基于格子/anchor/proposals进行回归和分类
- 算法性能受制于nms机制、anchor设计、target-anchor的匹配机制
end-to-end approach
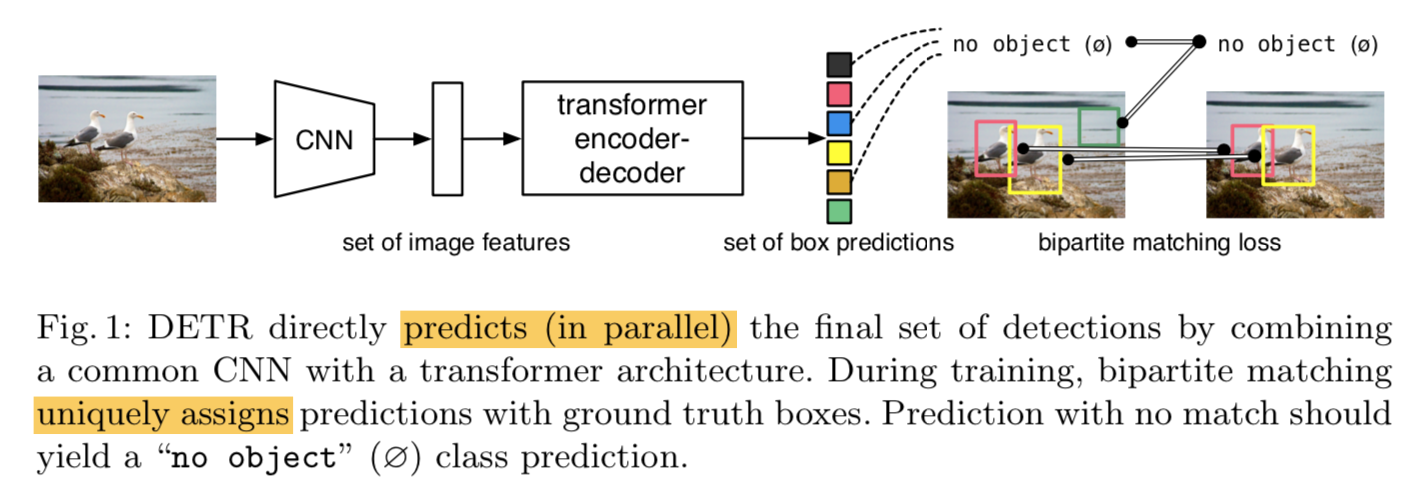
- transformer的self-attention机制,explicitly model all pairwise interactions between elements:内含了去重(nms)的能力
- bipartite matching:set loss function,将预测和gt的box一一匹配,run in parallel
- DETR does not require any customized layers, thus can be reproduced easily
- expand to segmentation task:a simple segmentation head trained on top of a pre-trained DETR
set prediction:to predict a set of bounding boxes and the categories for each
- basic:multilabel classification
- detection task has near-duplicates issues
- set prediction是postprocessing-free的,它的global inference schemes能够avoid redundancy
- usual loss:bipartite match
object detection
- set-based loss
- modern detectors use non-unique assignment rules together with NMS
- bipartite matching是target和pred一一对应
- set-based loss
方法
overall
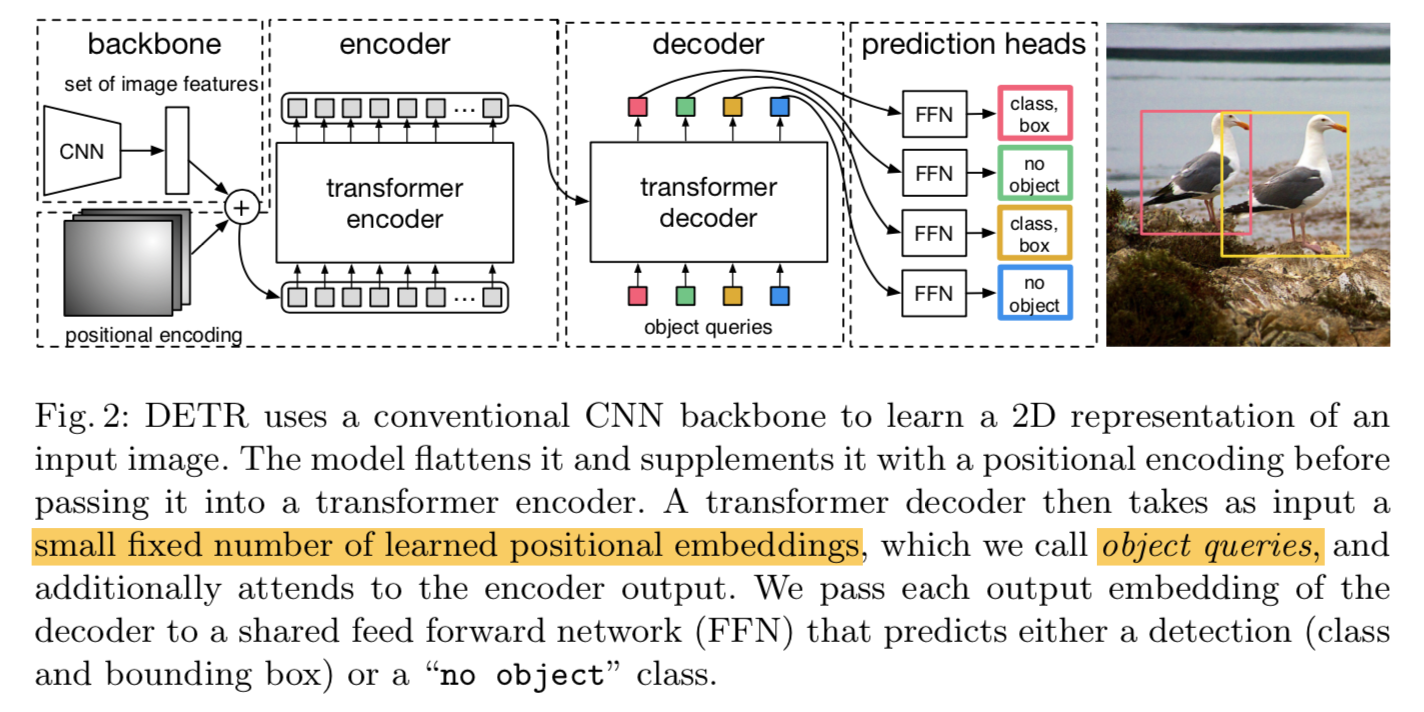
- three main components
- a CNN backbone
- an encoder-decoder transformer
- a simple FFN
- three main components
backbone
- conventional r50
- input:$[H_0, W_0, 3]$
- output:$[H,W,C], H=\frac{H_0}{32}, W=\frac{W_0}{32}, C=2048$
transformer encoder
- reduce channel dim to $d$:1x1 conv,$d=512$
- collapse the spatial dimensions:feature sequence [d, HW],每个spatial pixel作为一个feature
- fixed positional encodings:
- added to the input of each attention layer
- 【QUESTION】加在K和Q上还是embedding上?
transformer decoder
- 输入N个dim=d的embedding
- 叫object queries:表示我们预测固定值N个目标
- 因为decoder也是permutation-invariant的(因为all shared),所以要输入N个不一样的embedding
- learnt positional encodings
- add them to the input of each attention layer
- decodes the N objects in parallel
- 输入N个dim=d的embedding
prediction FFN
- 3 layer,ReLU,
- box prediction:normalized center coords & height & width
- class prediction:
- an additional class label $\varnothing$ 表示no object
auxiliary losses
- each decoder layer后面都接一个FFN prediction和Hungarian loss
- shared FFN
- an additional shared LN to norm the inputs of FFN
- three components of the loss
- class loss:CE loss
- box loss
- GIOU loss
- L1 loss
technical details
- AdamW:
- initial transformer lr=10e-4
- initial backbone lr=10e-5
- weight decay=10e-4
- Xavier init
- imagenet-pretrained resnet weights with frozen batchnorm layers:r50 & r101,DETR & DETR-R101
- a variant:
- increase feature resolution version
- remove stage5’s stride and add a dilation
- DETR-DC5 & DETR-DC5-R101
- improve performance for small objects
- overall 2x computation increase
- augmentation
- resize input
- random crop:with 0.5 prob then resize
- transformer default dropout 0.1
- lr schedule
- 300 epochs
- drop by factor 10 after 200 epochs
- 4 images per GPU,total batch 64
- AdamW:
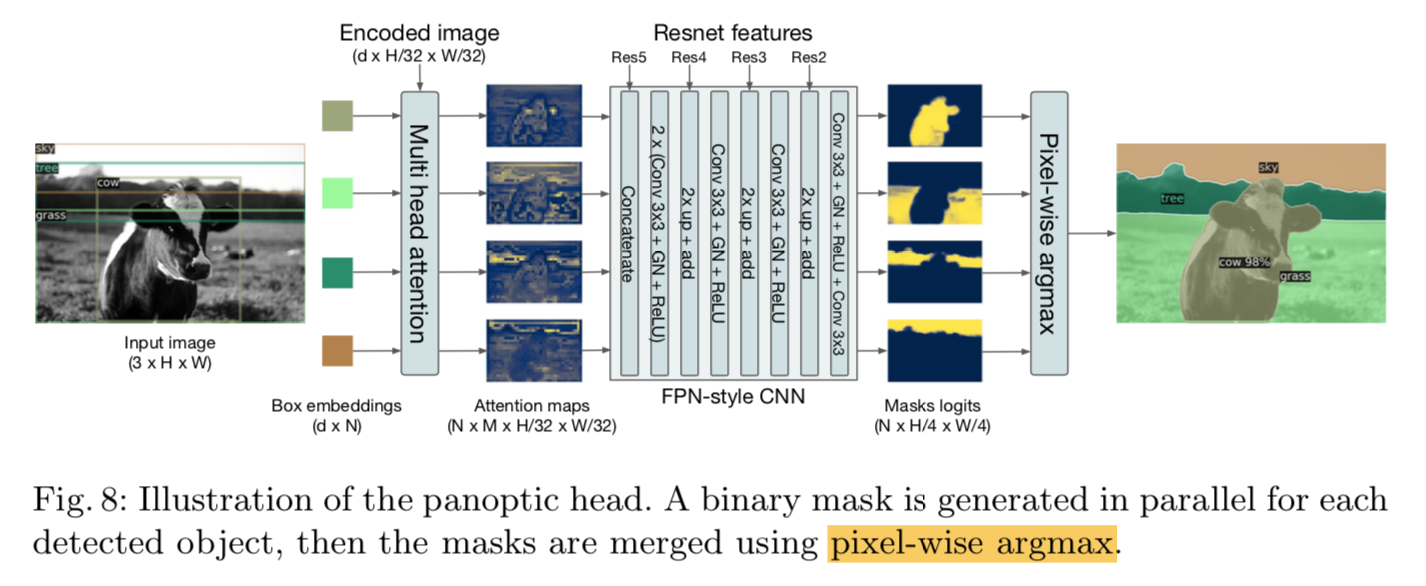
for segmentation task:全景分割
- 给decoder outputs加mask head
- compute multi-head attention among
- decoder box predictions
- encoder outputs
- generate M attention heatmaps per object
- add a FPN styled CNN to recover resolution
pixel-wise argmax
UNETR: Transformers for 3D Medical Image Segmentation
动机
- unet结构用于医学分割
- encoder learns global context
- decoder utilize the representations to predict the semanic ouputs
- the locality of CNN limits long-range spatial dependency
- our method
- use a pure transformer as the encoder
- learn sequence representations of the input volume
- global
- multi-scale
- encoder directly connects to decoder with skip connections
- unet结构用于医学分割
论点
- unet结构
- encoder用来提取全图特征
- decoder用来recover
- skip connections用来补充spatial information that is lost during downsampling
- localized receptive fields:
- disadvantage in capturing multi-scale contextual information
- 如不同尺寸的脑肿瘤
- 缓和手段:atrous convs,still limited
- transformer
- self-attention mechanism in NLP
- highlight the important features of word sequences
- learn its long-range dependencies
- in ViT
- an image is represented as a patch embedding sequence
- self-attention mechanism in NLP
- our method
- formulation
- 1D seq2seq problem
- use embedded patches
- the first completely transformer-based encoder
- formulation
- other unet- transformer methods
- 2D (ours 3D)
- employ only in the bottleneck (ours pure transformer)
- CNN & transformer in separate streams and fuse
- unet结构
方法
overview
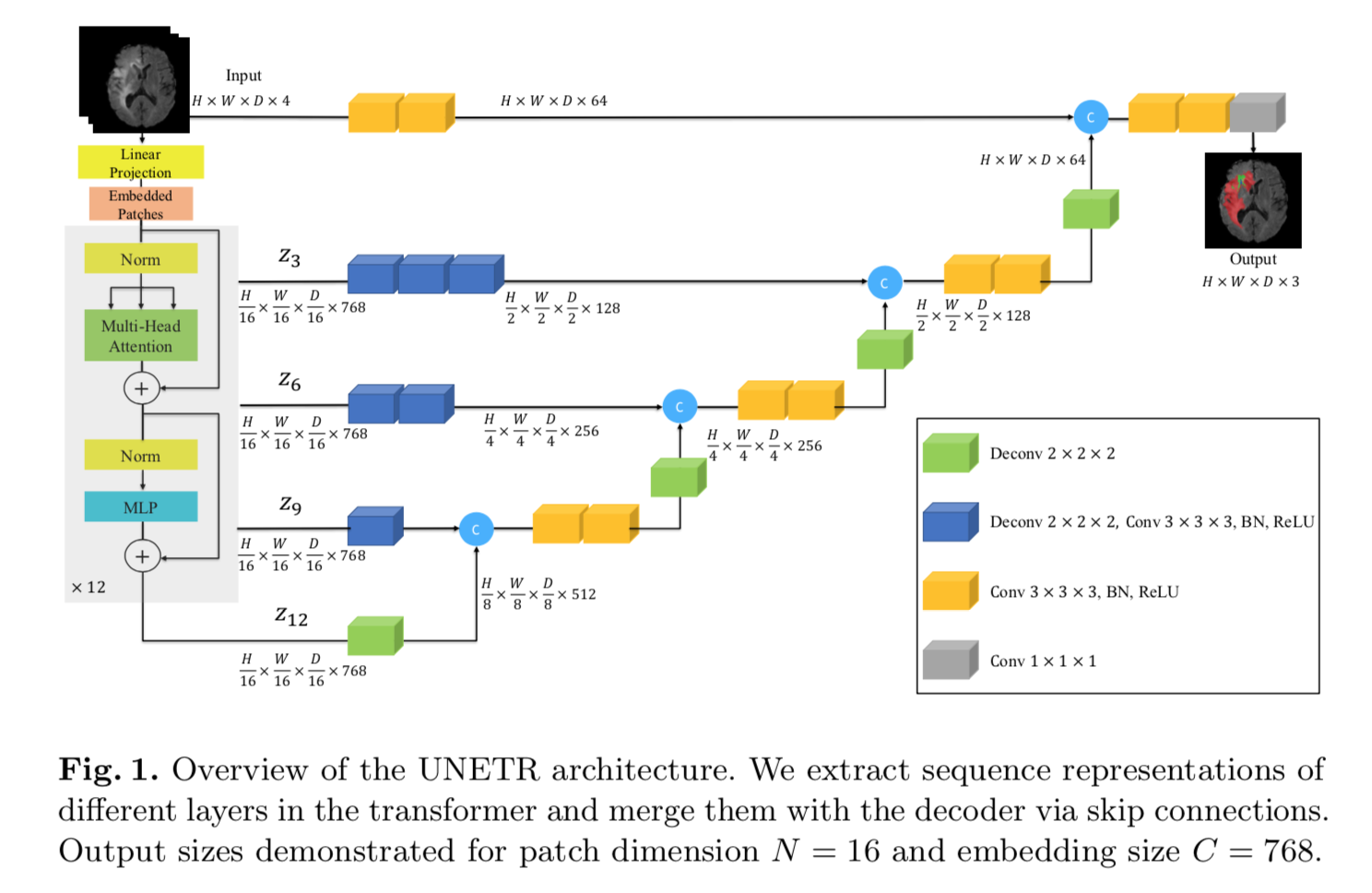
transformer encoder
- input:1D sequence of input embeddings
- given 3D volume $x \in R^{HWDC}$
- divide into flattened uniform non-overlapping patches $x\in R^{LCN^3}$
- $L=HWD/N^3$:the sequence length
- $N^3$:patch dimension
- linear projection to K-dim $E \in R^{LCK}$:remain constant through transformer
- 1D learnable positional embedding $E_{pos} \in R^LD$
- 12 self-att blocks:MSA + MLP
- decoder &skip connections
- 选取encoder第{3,6,9,12}个block的输出
- reshape back to 3D volume $[\frac{H}{N},\frac{W}{N},\frac{D}{N},C]$
- consecutive 3x3x3 conv+BN+ReLU
- bottleneck
- deconv by 2 to increase resolution
- then concat with the previous resized feature
- then jointly consecutive conv
- then upsample with deconv…
- concat到原图resolution以后,consecutive conv以后,再1x1x1 conv+softmax
- loss
- dice loss
- dice:for each class channel,计算dice,然后求类平均
- 1-dice
- ce loss
- for each pixel,求bce,然后求所有pixel的平均
- dice loss