reference:https://mp.weixin.qq.com/s/SWQHgogAP164Kr082YkF4A
图
- $G = (V,E)$:节点 & 边,连通图 & 孤立点
- 邻接矩阵A:NxN,有向 & 无向
- 度矩阵D:NxN对角矩阵,每个节点连接的节点
- 特征矩阵X:NxF,每个1-dim F是每个节点的特征向量
特征学习
- 可以类比CNN:对其邻域(kernel)内特征进行线性变换(w加权),然后求和,然后激活函数
- $H^{k+1} = f(H^{k},A) = \sigma(AH^{k}W^{k})$
- H:running updating 特征矩阵,NxFk
- A:0-1邻接矩阵,NxN
- W:权重,$F_k$x$F_{k+1}$
- 权重所有节点共享
- 节点的邻接节点可以看做感受野
- 网络加深,感受野增大:节点的特征融合了更多节点的信息
图卷积
A中没有考虑自己的特征:添加自连接
- A = A + I
加法规则对度大的节点,特征会越来越大:归一化
使得邻接矩阵每行和为1:左乘度矩阵的逆
数学实质:求平均
one step further:不单对行做平均,对度较大的邻接节点也做punish

GCN网络
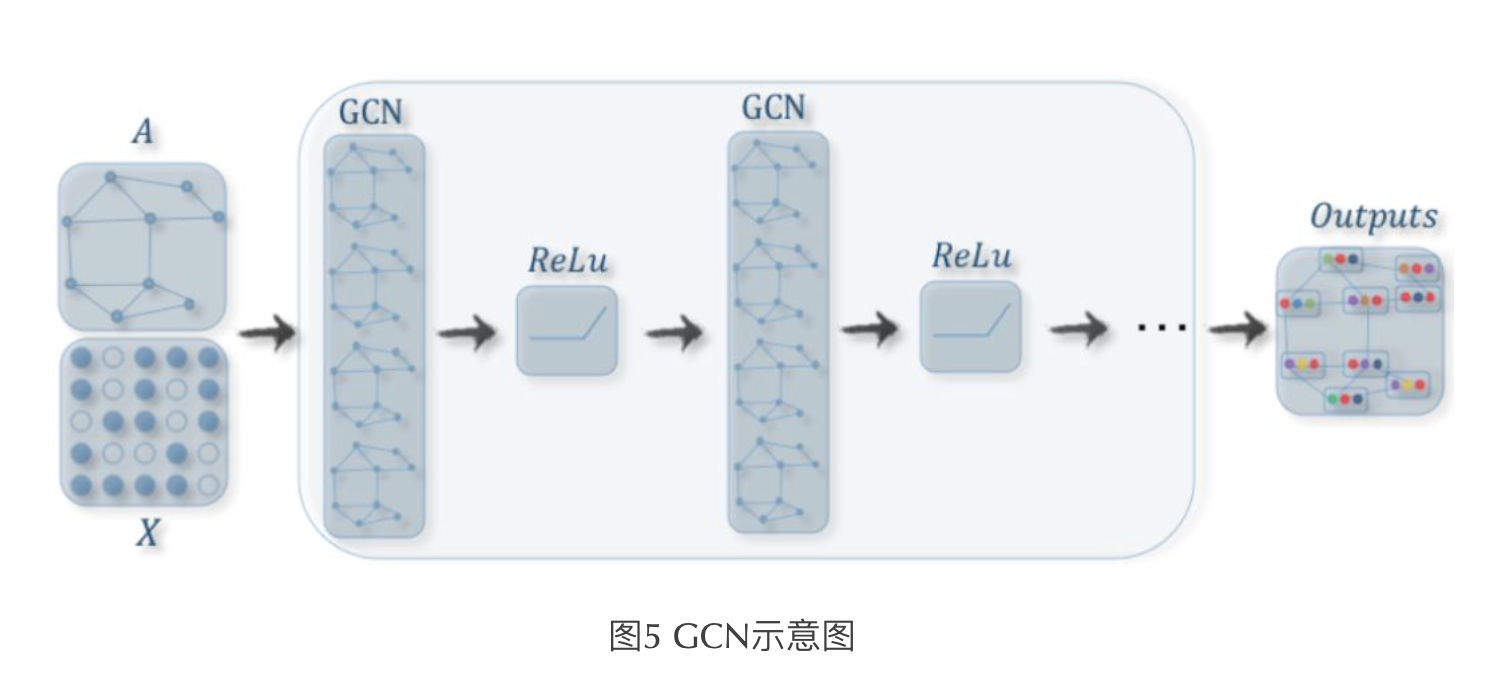
实现
weights:in x out,kaiming_uniform_initialize
bias:out,zero_initialize
activation:relu
A x H x W:左乘是系数矩阵乘法
邻接矩阵的结构从输入开始就不变了,和每层的特征矩阵一起作为输入,传入GCN
分类头:最后一层预测Nxn_class的特征向量,提取感兴趣节点F(n_class),然后softmax,对其分类
归一化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# 对称归一化
def normalize_adj(adj):
"""compute L=D^-0.5 * (A+I) * D^-0.5"""
adj += sp.eye(adj.shape[0])
degree = np.array(adj.sum(1))
d_hat = sp.diags(np.power(degree, -0.5).flatten())
norm_adj = d_hat.dot(adj).dot(d_hat)
return norm_adj
# 均值归一化
def normalize_adj(adj):
"""compute L=D^-1 * (A+I)"""
adj += sp.eye(adj.shape[0])
degree = np.array(adj.sum(1))
d_hat = sp.diags(np.power(degree, -1).flatten())
norm_adj = d_hat.dot(adj)
return norm_adj
应用场景
[半监督分类GCN]:SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS,提出GCN
[skin GCN]:Learning Differential Diagnosis of Skin Conditions with Co-occurrence Supervision using Graph Convolutional Networks,体素,一个单独的基于图的相关性分支,给feature加权
[Graph Attention]:Graph Attention Networks,图注意力网络
Learning Differential Diagnosis of Skin Conditions with Co-occurrence Supervision using Graph Convolutional Networks
动机
- 皮肤病:发病率高,experts少
- differential diagnosis:鉴别诊断,就是从众多疾病类别中跳出正确类别
- still challenging:timely and accurate
- propose a DLS(deep learning system)
- clinical images
- multi-label classification
- 80 conditions,覆盖病种
- labels incompleteness:用GCN建模成Co-occurrence supervision,benefit top5
论点
- google的DLS
- 26中疾病
- 建模成multi-class classification problem:非0即1的多标签表达破坏了类别间的correlation
- our DLS:GCN-CNN
- multi-label classification task over 80 conditions
- incomplete image labels:GCN that characterizes label co-occurrence supervision
- combine the classification network with the GCN
- 数据量:136,462 clinical images
- 精度:test on 12,378 user taken images,top-5 acc 93.6%
- GCN
- original application:
- nodes classification,only a small subset of nodes had their labels available:半监督文本分类问题,只有一部分节点用于训练
- the graph structure is contructed from data
- ML-GCN:
- multi-label classification task
- correlation map(图结构)则是通过数据直接建立
- 图节点是每个类别的semantic embeddings
- original application:
- google的DLS
方法
overview
- 一个trainable的CNN,将图片转化成feature vector
- 一个GCN branch:两层图卷积,都是order-1,图结构是基于训练集计算,无向图,encoding的是图像labels之间的dependency,用它 implicitly supervises the classification task
然后两个feature vector相乘,给出最终结果
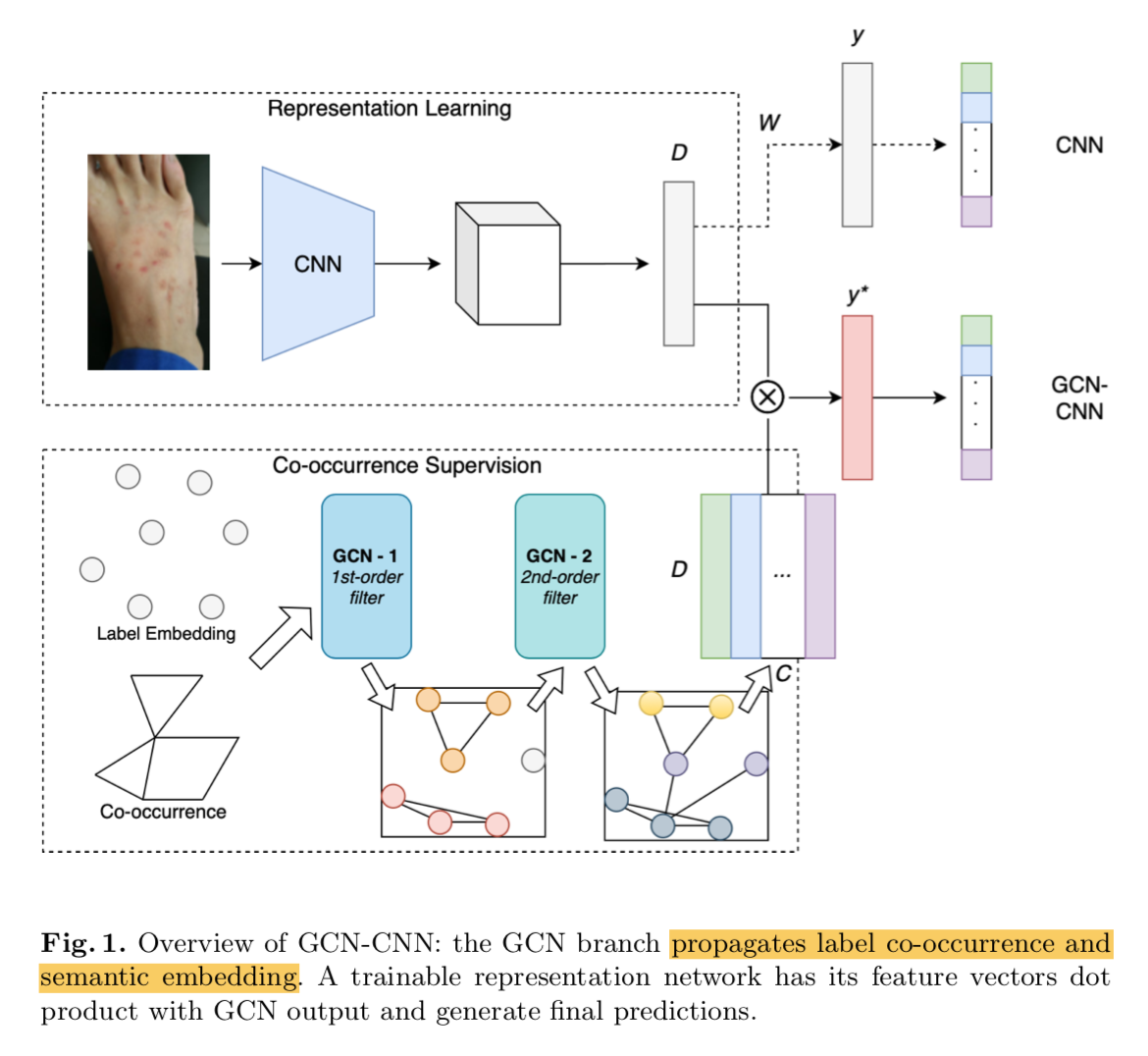
GCN branch
- two graph convolutional (GC) layers
- 一种estimated图结构:build co-occurence graph using only training data
- node embed semantic meaning to labels
- 边的值定义有点像类别间的相关性强度:$e_{ij} = 1(\frac{C(i,j)}{C(i)+C(j)} \geq t)$,分子是有两种标签的样本量,分母是各自样本量
- 一种designed图结构:intial value是基于有经验的专家构建
- node representation
- graph branch的输入 label embedding
- 用了BioSentVec,一个基于生物医学语料库训练的word bag
- GCN
- randomly initialize
- GCN-0:dim 700
- GCN-1:dim 1024
- GCN-2:dim 2048
- 最终得到(cls,2048)的node features
cls branch
- input:downsized to 448x448
- resnet101:执行到FC-2048,作为image features
- 先训练300 epochs,lr 0.1,step decay
GCN-CNN
- 先预训练resnet backbone,
- 然后整体一起训练300 epochs,lr 0.0003,
- image feature和node features通过dot product融合,得到(cls, )的cls vec,
实验
- 图结构不能random initialization,会使结果变差
基于数据集估计的graph initialization有显著提升
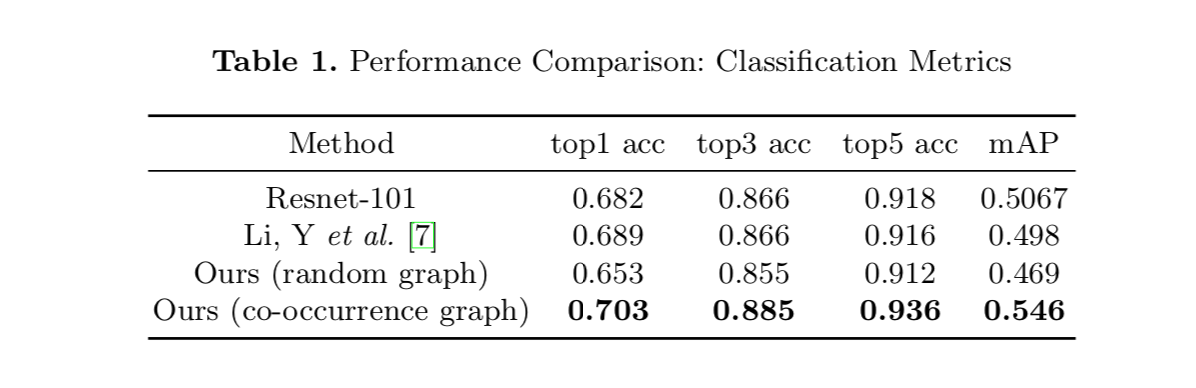
基于专家设计的graph initialization有进一步提升,但是不明显,考虑到标注工作繁重不太推荐
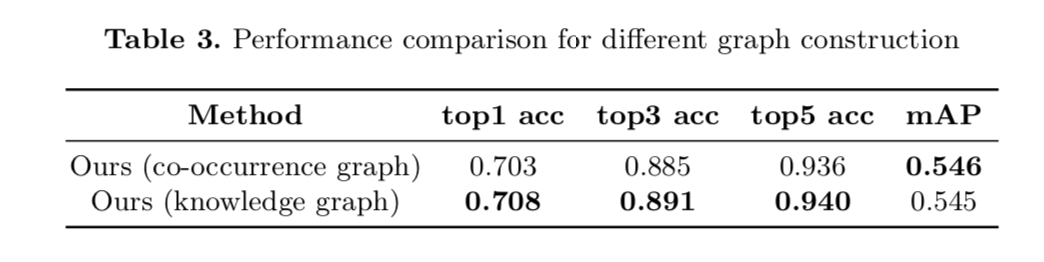
SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS
reference
论点
- 场景
- semi-supervised learning
- on graph-structured data
- 比如:在一个citation network,classifying nodes (such as documents),labels are only available for a small subset of nodes,任务的目标是对大部分未标记的节点预测类别
- previous approach
- Standard Approach
- loss由两部分组成:单个节点的fitting error,和相邻节点的distance error
- 基于一个假设:相邻节点间的label相似
- 限制了模型的表达能力
- Embedding-based Approach
- 分两步进行:先学习节点的embedding,再基于embedding训练分类器
- 不end-to-end,两个task分别执行,不能保证学到的embedding是适合第二个任务的
- Standard Approach
- 思路
- train on a supervised target for nodes with labels
- 然后通过图的连通性,trainable adjacency matrix,传递梯度给unlabeled nodes
- 使得全图得到监督信息
- contributions
- introduce a layer-wise propagation rule,使得神经网络能够operate on graph,实现end-to-end的图结构分类器
- use this graph-based neural network model,训练一个semi-supervised classification of nodes的任务
- 场景
方法
fast approximate convolutions on graphs
given:
- layer input:$H^l$
- layer output:$H^{l+1}$
- kernel pattern:$A$,在卷积里面是fixed kxk 方格,在图里面就是自由度更高的邻接矩阵
- kernel weights:$W$
general layer form:$H^{l+1}=f(H^l,A)$
inspiration:卷积其实是一种特殊的图,每个grid看作一个节点,每个节点都加上其邻居节点的信息,也就是:
- W是在对grids加权
A是在对每个grids加上他的邻接节点
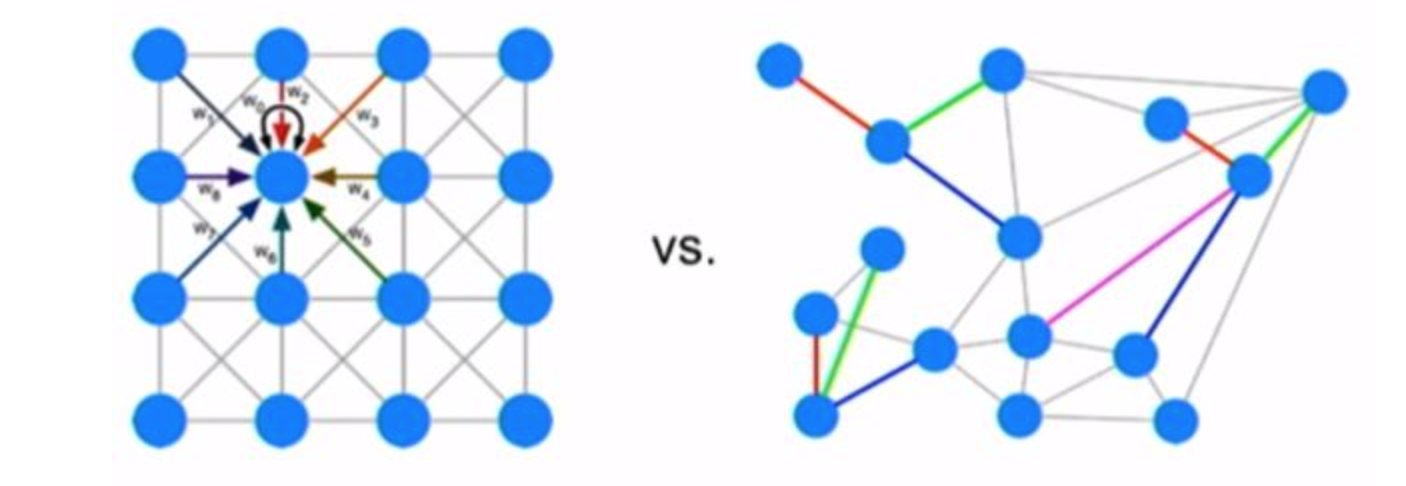
details in practice
- 自环:保留自身节点信息,$\hat A=A+I$
- 正则化:stabilize the scale,$H^{l+1}=\sigma(\hat D^{-\frac{1}{2}}\hat A\hat D^{-\frac{1}{2}}H^lW)$
一个实验:只利用图的邻接矩阵,就能够学得效果不错
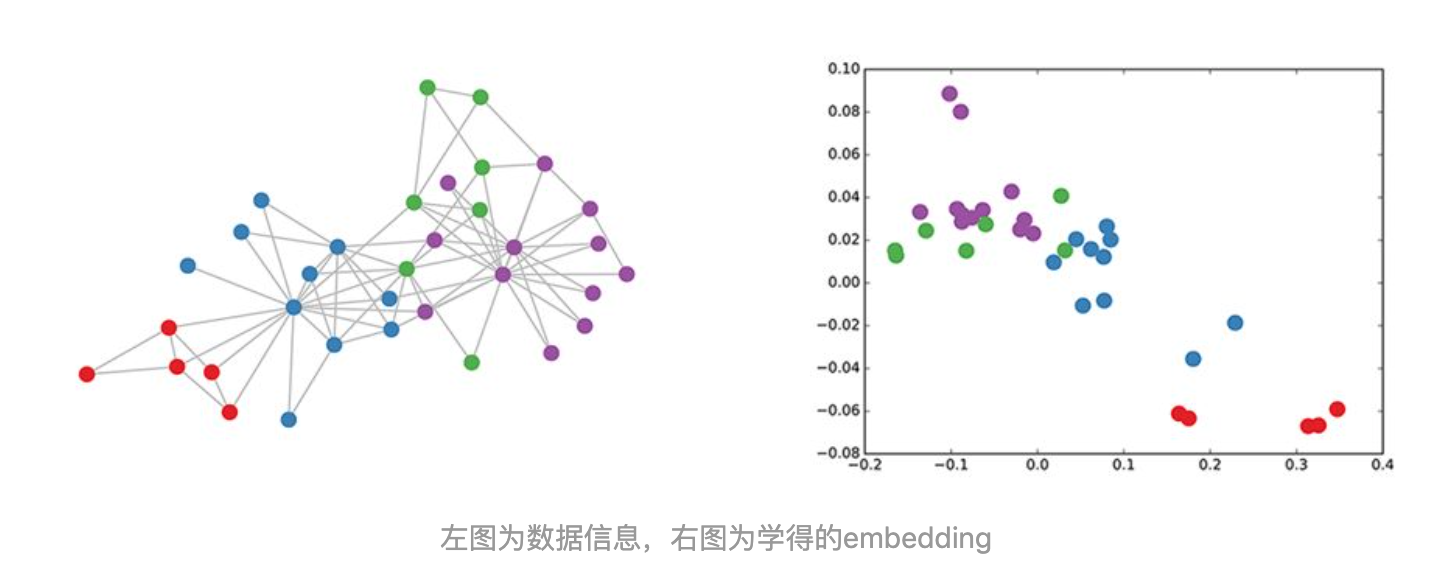
semi-supervised node classification
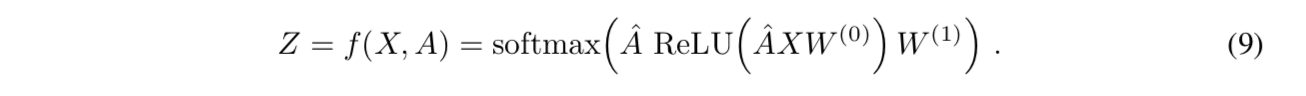
- 思路就是在所有有标签节点上计算交叉熵loss
- 模型结构
- input:X,(b,N,D)
- 两层图卷积
- GCN1-relu:hidden F,(b,N,F)
- GCN2-softmax:output Z,(b,N,cls)
- 计算交叉熵
code
- torch/keras/tf官方都有:
- https://github.com/tkipf/gcn,论文里给的tf这个链接
- torch和keras的readme里面有说明,initialization scheme, dropout scheme, and dataset splits和tf版本不同,不是用来复现论文
- python setup.py bdist_wheel
- 数据集:Cora dataset,是一个图数据集,用于分类任务,数据集介绍https://blog.csdn.net/yeziand01/article/details/93374216
- cora.content是所有论文的独自的信息,总共2708个样本,每一行都是论文编号+词向量1433-dim+论文类别
- cora.cites是论文之间的引用记录,A to B的reflect pair,5429行,用于创建邻接矩阵
- torch/keras/tf官方都有: