[pre-training] Rethinking ImageNet Pre-training,He Kaiming,imageNet pre-training并没有真正helps acc,只是speedup,random initialization能够reach no worse的结果,前提是数据充足增强够猛,对小门小户还是没啥用,我们希望speedup
[pre-training & self-training] Rethinking Pre-training and Self-training,Google Brain,提出task-specific的pseudo label要比pre-training中搞出来的各种标签要好,前提还是堆数据,对小门小户没啥用,low-data下还是pre-train保平安
总体上都是针对跨任务下,imageNet pre-training意义的探讨,
- 分类问题还是可以继续pretrained
- kaiming这个只是fact,没有现实指导意义
- google这个one step further,提出了self-training在现实条件中可以一试
Rethinking Pre-training and Self-training
动机
- given fact:ImageNet pre-training has limited impact on COCO object detection
- investigate self-training to utilize the additional data
论点
- common practice pre-training
- supervised pre-training
- 首先要求数据有标签
- pre-train the backbone on ImageNet as a classification task
- 弱监督学习
- with pseudo/noisy label
- kaiming:Exploring the limits of weakly supervised pretraining
- self-supervised pre-training
- 无标签的海量数据
- 构造学习目标:autoencoder,contrastive,…
- https://zhuanlan.zhihu.com/p/108906502
- supervised pre-training
- self-training paradigm on COCO
- train an object detection model on COCO
- generate pseudo labels on ImageNet
- both labeled data are combined to train a new model
- 基本基于noisy student的方法
- observations
- with stronger data augmentation, pre-training hurts the accuracy, but helps in self-training
- both supervised and self-supervised pre-training methods fails
- the benefit of pre-training does not cancel out the gain by self-training
- flexible about unlabeled data sources, model architectures and computer vision tasks
- common practice pre-training
方法
- data augmentation
- vary the strength of data augmentation as 4 levels
pre-training
- efficientNet-B7
- AutoAugment weights & noisy student weights

self-training
- noisy student scheme
- 实验发现self-training with this standard loss function can be unstable
- implement a loss normalization technique
- experimental settings
- object detection
- COCO dataset for supervised learning
- unlabeled ImageNet and OpenImages dataset for self-training:score thresh 0.5 to generate pesudo labels
- retinaNet & spineNet
- batch:half supervised half pesudo
- semantic segmentation
- PASCAL VOC 2012 for supervised learning
- augmented PASCAL & COCO & ImageNet for self-training:score thresh 0.5 to generate pesudo masks & multi-scale
- NAS-FPN
- object detection
- data augmentation
实验
pre-training
- Pre-training hurts performance when stronger data augmentation is used:因为会sharpen数据差异?
- More labeled data diminishes the value of pre-training:通常我们的实验数据fraction都比较小的相对imageNet,所以理论上不会harm?
self-supervised pre-training也会一样harm,在augment加强的时候
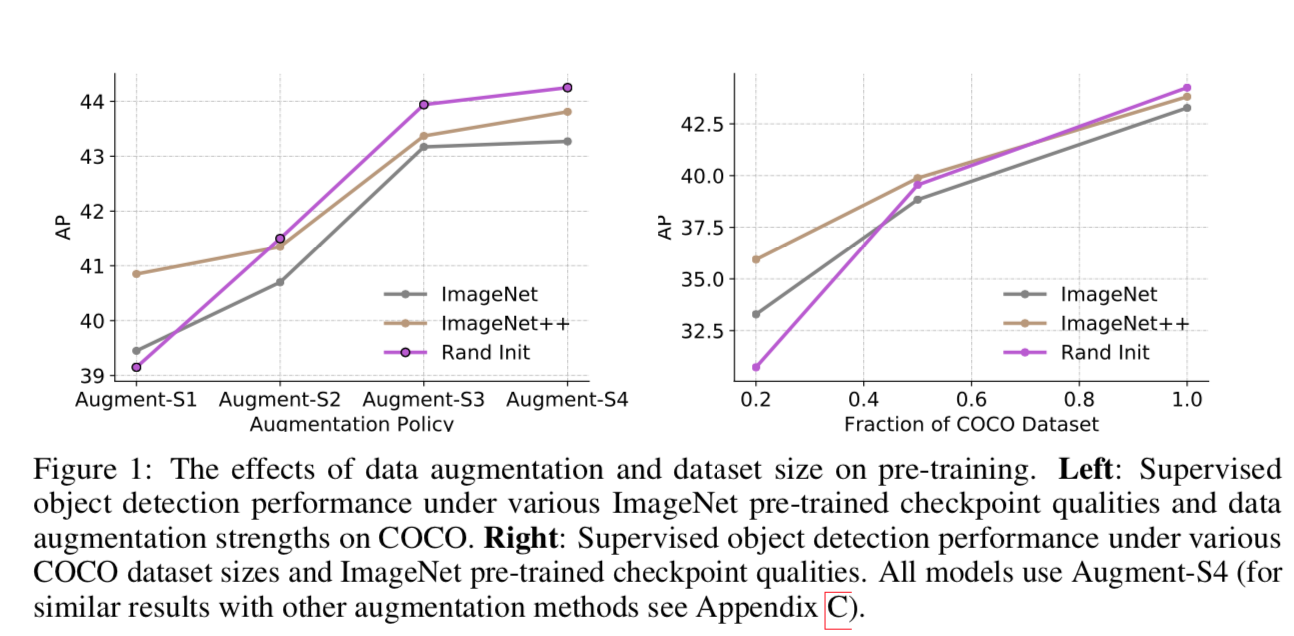
self-training
Self-training helps in high data/strong augmentation regimes, even when pre-training hurts:不同的augment level,self-training对最终结果都有加成

Self-training works across dataset sizes and is additive to pre-training:不同的数据量,也都有加成,但是low data regime下enjoys the biggest gain
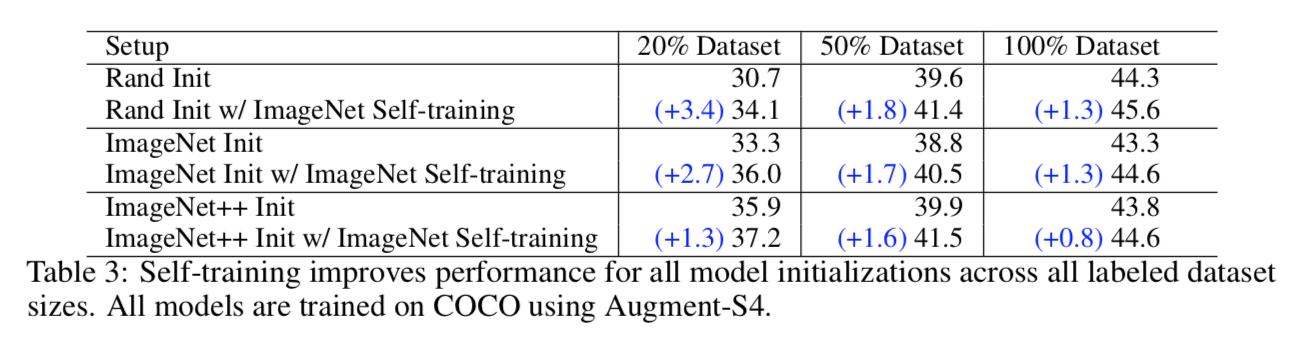
discussion
- weak performance of pre-training is that pre-training is not aware of the task of interest and can fail to adapt
- jointly training also helps:address the mismatch between two dataset
- noisy labeling is worse than targeted pseudo labeling
总体结论:小样本量的时候,pre-training还是有加成的,再加上self-training进一步提升,样本多的时候就直接self-training
Rethinking ImageNet Pre-training
- 动机
- thinking random initialization & pre-training
- ImageNet pre-training
- speed up
- but not necessarily improving
- random initialization
- can achieve no worse result
- robust to data size, models, tasks and metrics
- rethink current paradigm of ‘pre- training and fine-tuning’
- 论点
- no fundamental obstacle preventing us from training from scratch
- if use normalization techniques appropriately
- if train sufficiently long
- pre-training
- speed up
- when fine-tuning on small dataset new hyper-parameters must be selected to avoid overfitting
- localization-sensitive task benefits limited from pre-training
- aimed at communities that don’t have enough data or computational resources
- no fundamental obstacle preventing us from training from scratch
- 方法
- normalization
- form
- normalized parameter initialization
- normalization layers
- BN layers makes training from scratch difficult
- small batch size degrade the acc of BN
- fine-tuning可以freeze BN
- alternatives
- GN:对batch size不敏感
- syncBN
- with appropriately normalized initialization可以train from scratch VGG这种不用BN层的
- form
- convergence
- pre-training model has learned low-level features that do not need to be re-learned during
- random-initial training need more iterations to learn both low-level and semantic features
- normalization
- 实验
- investigate maskRCNN
- 替换BN:GN/sync-BN
- learning rate:
- training longer for the first (large) learning rate is useful
- but training for longer on small learning rates often leads to overfitting
- 10k COCO往上,train from scratch results能够catch up pretraining results,只要训的够久
- 1k和3.5k的COCO,converges show no worse,但是在验证集上差一些:strong overfitting due to lack of data
- PASCAL的结果也差一点,因为instance和category都更少,not directly comparable to the same number of COCO images:fewer instances and categories has a similar negative impact as insufficient training data
- investigate maskRCNN