[bag of tricks] Bag of Tricks for Long-Tailed Visual Recognition with Deep Convolutional Neural Networks:结论就是两阶段,input mixup + CAM-based DRS + muted mixup fine-tuning组合使用最好
[balanced-meta softmax] Balanced Meta-Softmax for Long-Tailed Visual Recognition:商汤
[eql] Equalization Loss for Long-Tailed Object Recognition
[eql2] Equalization Loss v2: A New Gradient Balance Approach for Long-tailed Object Detection
[Class Rectification Loss] Imbalanced Deep Learning by Minority Class Incremental Rectification:提出CRL使得模型能够识别分布稀疏的小类们的边界,以此避免大类主导的影响
Bag of Tricks for Long-Tailed Visual Recognition with Deep Convolutional Neural Networks
动机
- to give a detailed experimental guideline of common tricks
- to obtain the effective combinations of these tricks
- propose a novel data augmentation approach
论点
- long-tailed datasets
- poor accuray on the under-presented minority
- long-tailed CIFAR:
- 指数型衰减
- imbalance factor:50/100
- test set unchanged
- ImageNet-LT
- sampling the origin set follow the pareto distribution
- test set is balanced
- iNaturalist
- extremely imbalanced real world dataset
- fine-grained problem
- different learning paradigms
- metric learning
- meta learning
- knowledge transfer
- suffer from high sensitivity to hyper-parameters
- training tricks
- re-weighting
- re-sample
- mixup
- two-stage training
- different tricks might hurt each other
- propose a novel data augmentation approach based on CAM:generate images with transferred foreground and unchanged background
- long-tailed datasets
方法
start from baseline
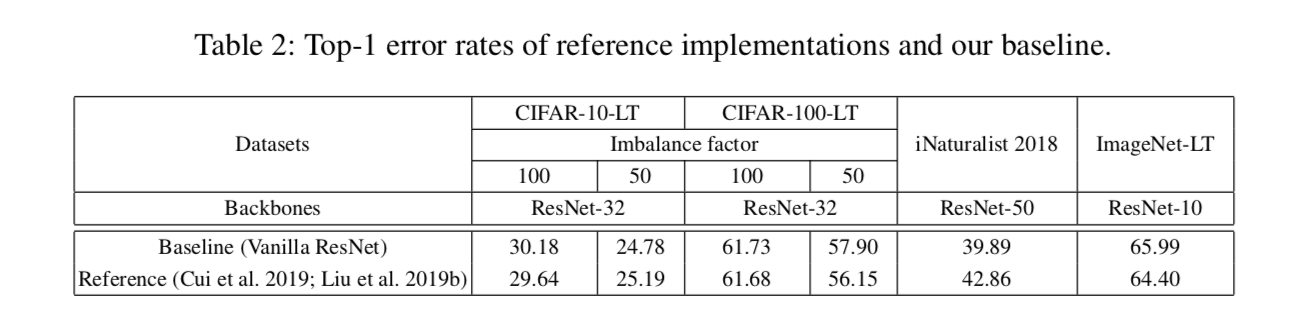
re-weighting
- baseline:CE
- re-weighting methods:
- cost-sensitive CE:按照样本量线性加权$\frac{n_c}{n_{min}}$
- focal loss:困难样本加权
- class-balanced loss:
- effective number rather than 样本量$n_c$
- hyperparameter $\beta$ and weighting factor:$\frac{1-\beta}{1-\beta^{n_c}}$
- 在cifar10上有效,但是cifar100上就不好了
- directly application in training procedure is not a proper choice
- especially when类别增多,imbalance加剧的时候
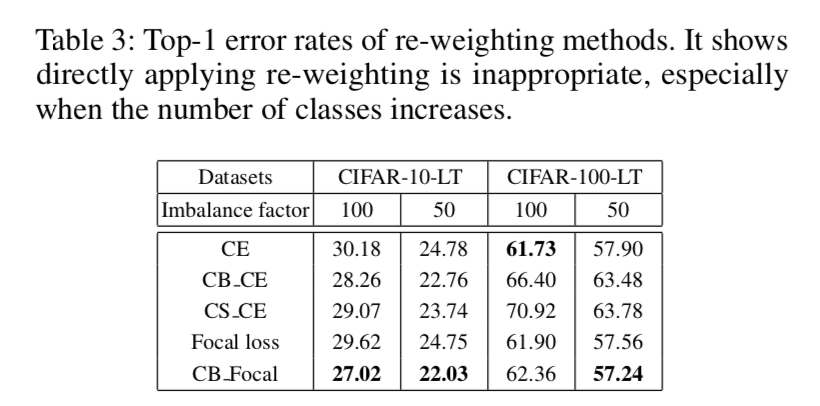
re-sampling
- re-sampling methods
- over-sampling:
- 随机复制minority
- might leads to overfitting
- under-sampling
- 随机去掉一些majority
- be preferable to over-sampling
- 有规律地sampling
- 大体都是imbalanced向着lighter imbalanced向着balanced推动
- artificial sampling methods
- create artificial samples
- sample based on gradients and features
- likely to introduce noisy data
- over-sampling:
- 观察到提升效果不明显
- re-sampling methods
mixup
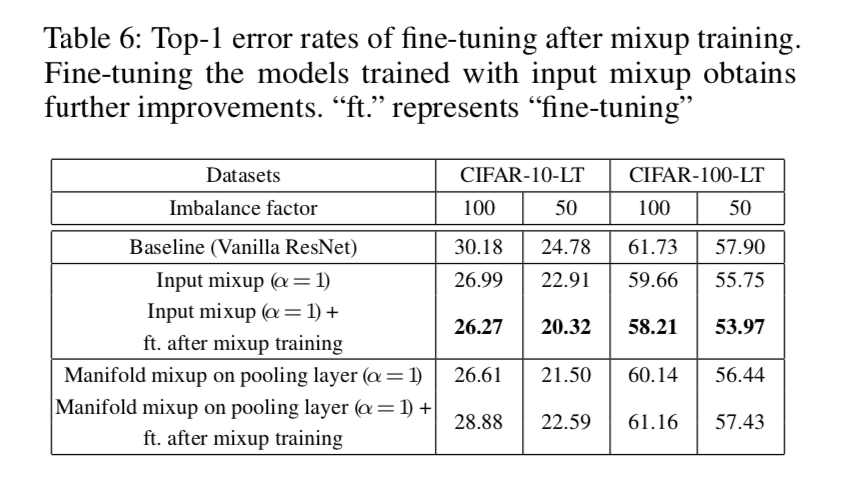
- input mixup:input mixup can be further improved if we remove the mixup in last several epochs
- manifold mixup:on only one layer
观察到两种mixup功效差不多,后面发现input mixup更好些
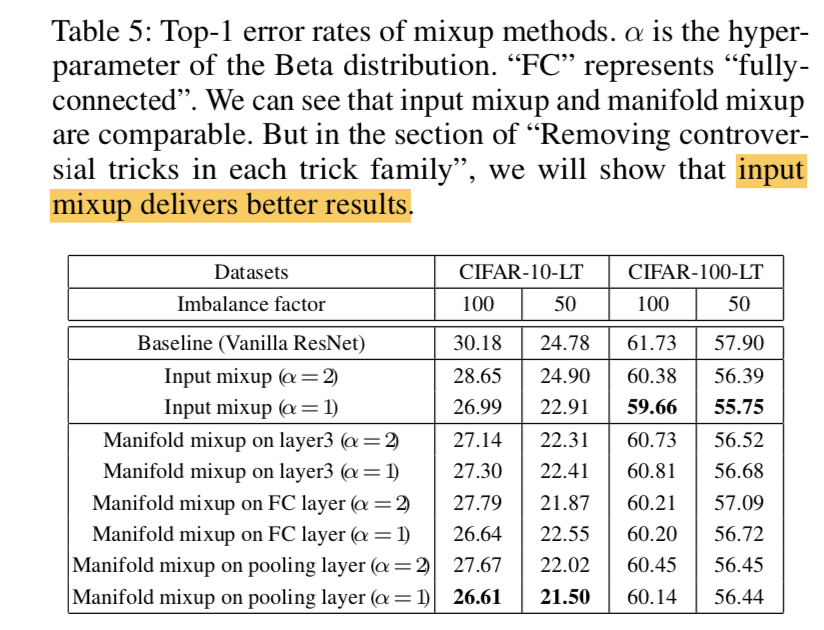
- input mixup去掉再finetuning几个epoch结果又提升,manifold则会变差
two-stage training
- imbalanced training + balanced fine-tuning
- vanilla training schedule on imbalanced data
- 先学特征
- fine-tune on balanced subsets
- 再调整recognition accuracy
- deferred re-balancing by re-sampling (DRS) :propose CAM-based sampling
- deferred re-balancing by re-weighting (DRW)
- proposed CAM-based sampling
- DRS only replicate or remove
- for each sampled image, apply the trained model & its ground truth label to generate CAM
- 用heatmap的平均值作为阈值来区分前背景
- 对前景apply transformations
- horizontal flipping
- translation
- rotating
- scaling
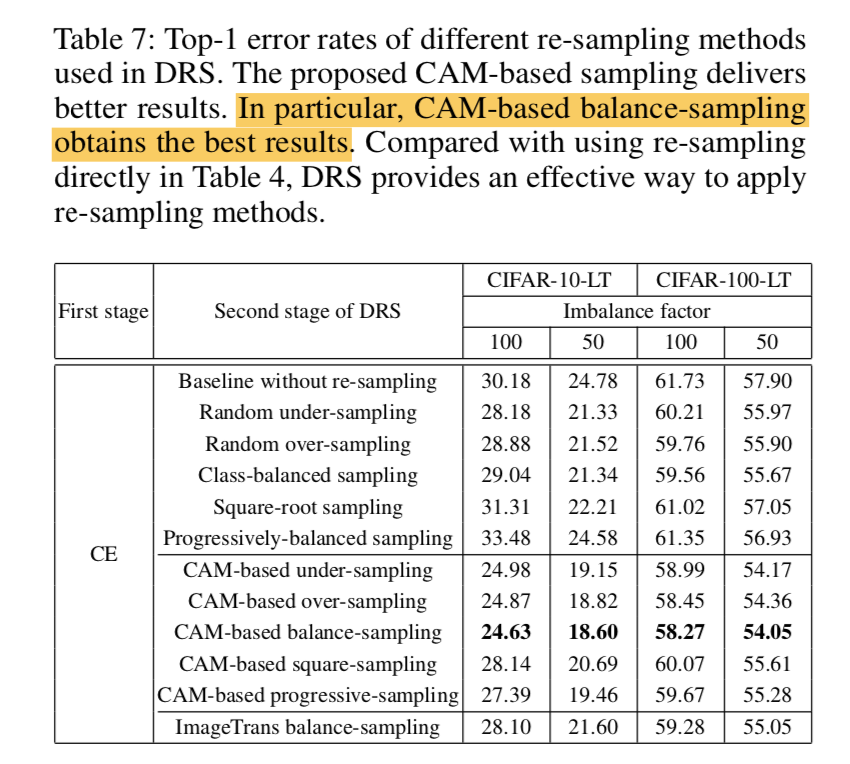
- 发现fine-tuning时候再resample比直接resample的结果好
- proposed CAM-based sampling好于其他sampling,其中CAM-based balance- sampling最好
ImageTrans balance-sampling只做变换,不用CAM区分前背景,结果不如CAM-based,证明CAM有用
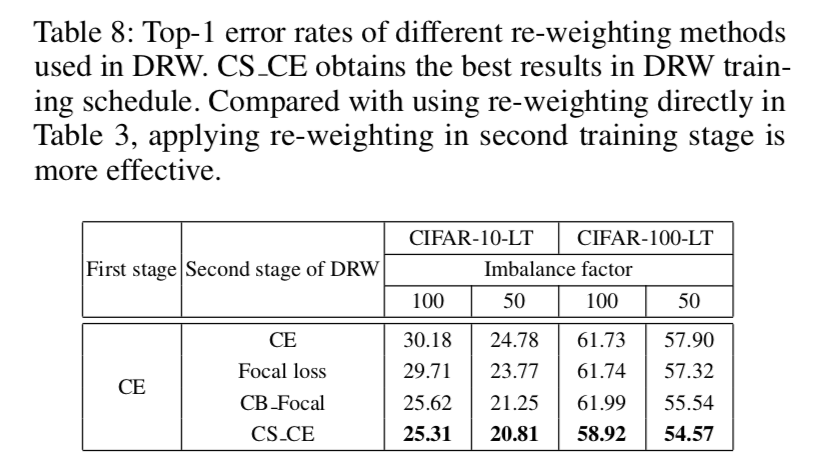
发现fine-tuning时候再reweight比直接reweight的结果好
其中CSCE(按照样本量线性加权)最好
整体来看DRS的结果稍微比DRW好一点
trick combinations
- two-stage的CAM-based DRS略好于DRW,两个同时用不会further improve
- 再加上mixup的话,input比manifold好一些
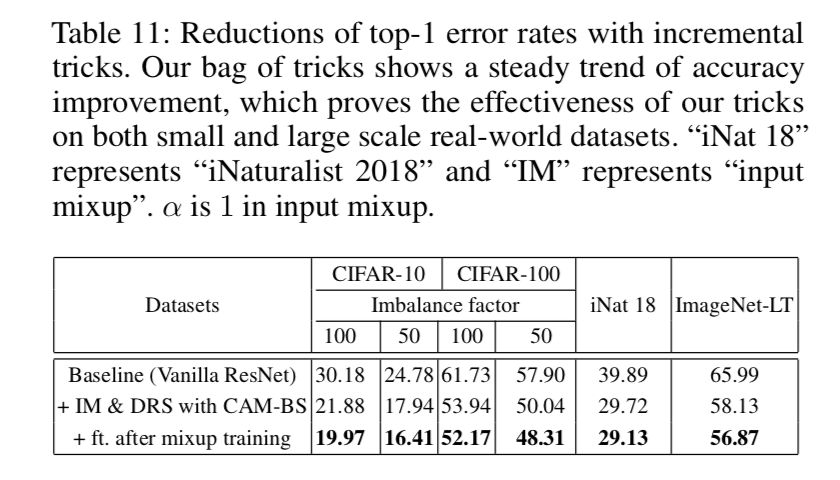
结论就是:input mixup + CAM-based DRS + mute fine-tuning,apply the tricks incrementally
Balanced Meta-Softmax for Long-Tailed Visual Recognition
动机
- long-tailed:mismatch between training and testing distributions
- softmax:biased gradient estimation under the long-tailed setup
- propose
- Balanced Softmax:an elegant unbiased extension of Softmax
- apply a complementary Meta Sampler:optimal sample rate
- classification & segmentation
论点
- raw baseline:a model that minimizes empirical risk on long-tailed training datasets often underperforms on a class-balanced test set
- most methods use re-sampling or re-weighting
- to simulate a balanced dataset
- may under-class the majority or have gradient issue
- meta-learning
- optimize the weight per sample
- need a clean and unbiased dataset
- decoupled training
- 就是上面一篇论文中的两阶段,第一阶段先学表征,第二阶段调整分布fine-tuning
- not adequate for datasets with extremely high imbalance factor
- LDAM
- Label-Distribution-Aware Margin Loss
- larger generalization error bound for minority
- suit for binary classification
- we propose BALMS
- Balanced Meta-Softmax
- theoretically equivalent with generalization error bound
- for datasets with high imbalance factors should combine Meta Sampler
方法
balanced softmax
- biased:从贝叶斯条件概率公式看,standard softmax上默认了均匀采样的p(y),在长尾分布的时候,就是有偏的
加权:
- 加在softmax项里面
- 基于样本量线性加权
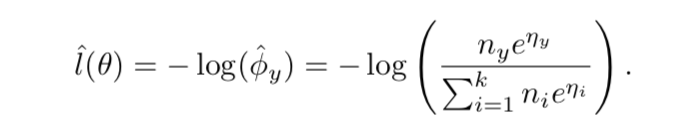
数学意义上:we need to focus on minimizing the training loss of the tail classes
meta sampler
- resample和reweight直接combine可能会worsen performance
- class balance resample可能有over-balance issue
combination procedures

- 对当前分布,先计算balanced-softmax,保存一个梯度更新后的模型
- 计算这个临时模型在meta set上的CE,对分布embedding进行梯度更新:评估当前分布咋样,往一定方向矫正
- 对真正的模型,用最新的分布,计算balanced-softmax,进行梯度更新:用优化后的分布,引导模型学习
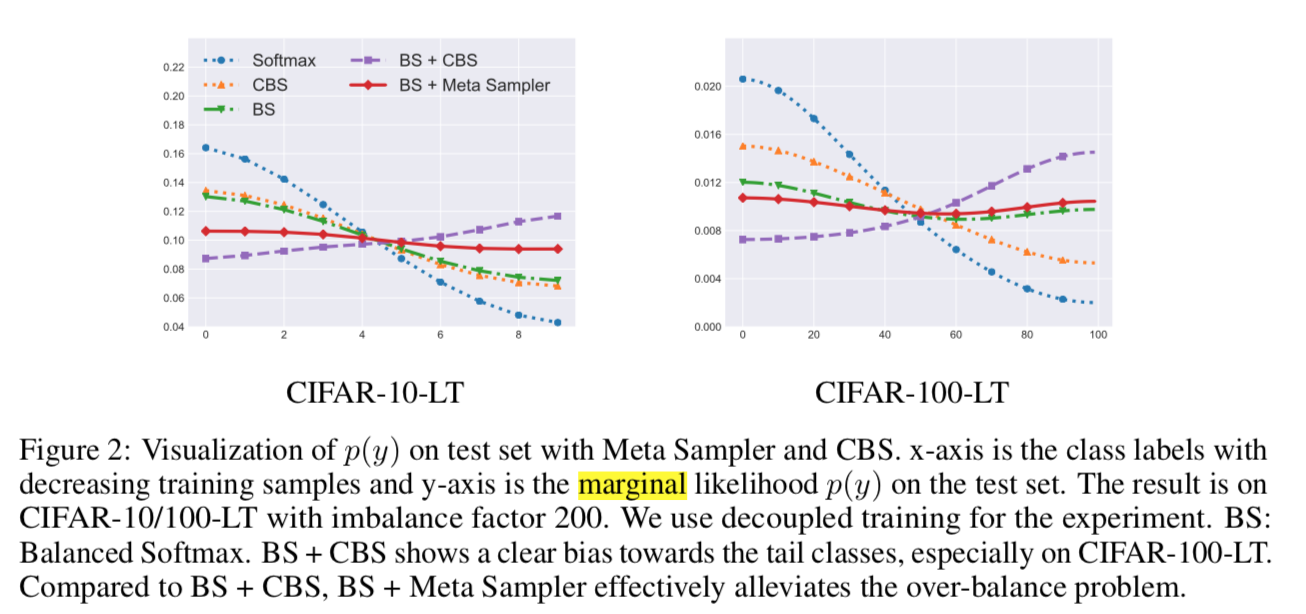
实验
- CE的结果呈现明显的长尾同分布趋势
- CBS有缓解
- BS更好
- BS+CBS会over sample
BS+meta最好
Imbalanced Deep Learning by Minority Class Incremental Rectification
动机
- significantly imbalanced training data
- propose
- batch-wise incremental minority class rectification model
- Class Rectification Loss (CRL)
bring benefits to both minority and majority class boundary learning

论点
- Most methods produce learning bias towards the majority classes
- to eliminate bias
- lifting the importance of minority classes:over-sampling can easily cause model overfitting,可能造成对小类别的过分关注,而对大类别不够重视,影响模型泛化能力
- cost-sensitive learning:difficult to optimise
- threshold-adjustment technique:given by experts
- to eliminate bias
- previous methods mainly investigate single-label binary-class with small imbalance ratio
- real data
- large ratio:power-law distributions
- Subtle appearance discrepancy
- hard sample mining
- hard negatives are more informative than easy negatives as they violate a model class boundary
- we only consider hard mining on the minority classes for efficiency
- our batch-balancing hard mining strategy:eliminating exhaustive searching
- LMLE
- 唯一的竞品:考虑了data imbalance的细粒度分类
- not end-to-end
- global hard mining
- computationally complex and expensive
- Most methods produce learning bias towards the majority classes
方法
CRL overview
- explicitly imposing structural discrimination of minority classes
- batch-wise
- operate on CE
- forcus on minority class only:the conventional CE loss can already model the majority classes well
limitations of CE
- CE treat the individual samples and classes as equally important
- the learned model is suboptimal
- boundaries are biased towards majority classes
profile the class distribution for each class
- hard mining
overview

minority class hard sample mining
selectively “borrowing” majority class samples from class decision boundary
to minority class’s perspective:mining both hard-positive and hard-negative samples
define minority class:selected in each mini-batch
Incremental refinement:
- eliminates the LMLE’s drawback in assuming that local group structures of all classes can be estimated reliably by offline global clustering
- mini-batch的data distribution和训练集不是完全一致的
steps
profile the minority and majority classes per label in each training mini-batch
- for each sample,for each class $j$,for each pred class $k$,we have $h^j=[h_1^j, …, h_k^j, …, h_{n_cls}^j]$
- sort $h_k^j$ in descent order,define the minority classes for each class with $C_{min}^j = \sum_{k\in C_{min}^j}h_k^j \leq \rho * n_{bs}$,with $\rho=0.5$
hard mining
hardness
- score based:prediction score,class-level
- feature based:feature distance,instance-level
class-level,for class c
- hard-positives:same gt class,but low prediction
- hard-negative:different gt class,with high prediction
instance-level,for each sample in class c
- hard-positives:same gt class,large distance with current sample
- hard-negative:different gt class,small distance with current sample
top-k mining
- hard-positives:bottom-k scored on c/top-k distance on c
- hard-negative:top-k scored on c/bottom-k distance on c
score-based yields superior to distance-based

CRL
- final weighted loss:$L = \alpha L_{crl}+(1-\alpha)L_{ce}$,$\alpha=\eta\Omega_{imbalance}$
- class imbalance measure $\Omega$:more weighting is assigned to more imbalanced labels
- form
- triplet loss:类内+类间
- contrastive loss:类内
- modelling the distribution relationship of positive and negative pairs:没看懂
总结
就是套用现有的metric learning,定义了一个变化的minority class,垃圾。
说到底就是大数据——CE,小数据——metric learning。