RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
引用量1452,但是没有几篇技术博客??
动机
- 语义分割
- dense classification on every single pixel
- refineNet
- long-range residual connections
- chained residual pooling
- 语义分割
论点
- pooling/conv stride:
- losing finer image structure
- deconv is not able to recover the lost info
- atrous
- high reso:large computation
- dilated conv:coarse sub-sampling of feature
- FCN
- fuse features from all levels
- stage-wise rather than end-to-end???存疑
this paper
- main idea:effectively exploit middle layer features
- RefineNet
- fuse all level feature
- residual connections with identity skip
- chained residual pooling to capture background context:看描述感觉像inception downsamp
- end-to-end
- 是整个分割网络中的一个component
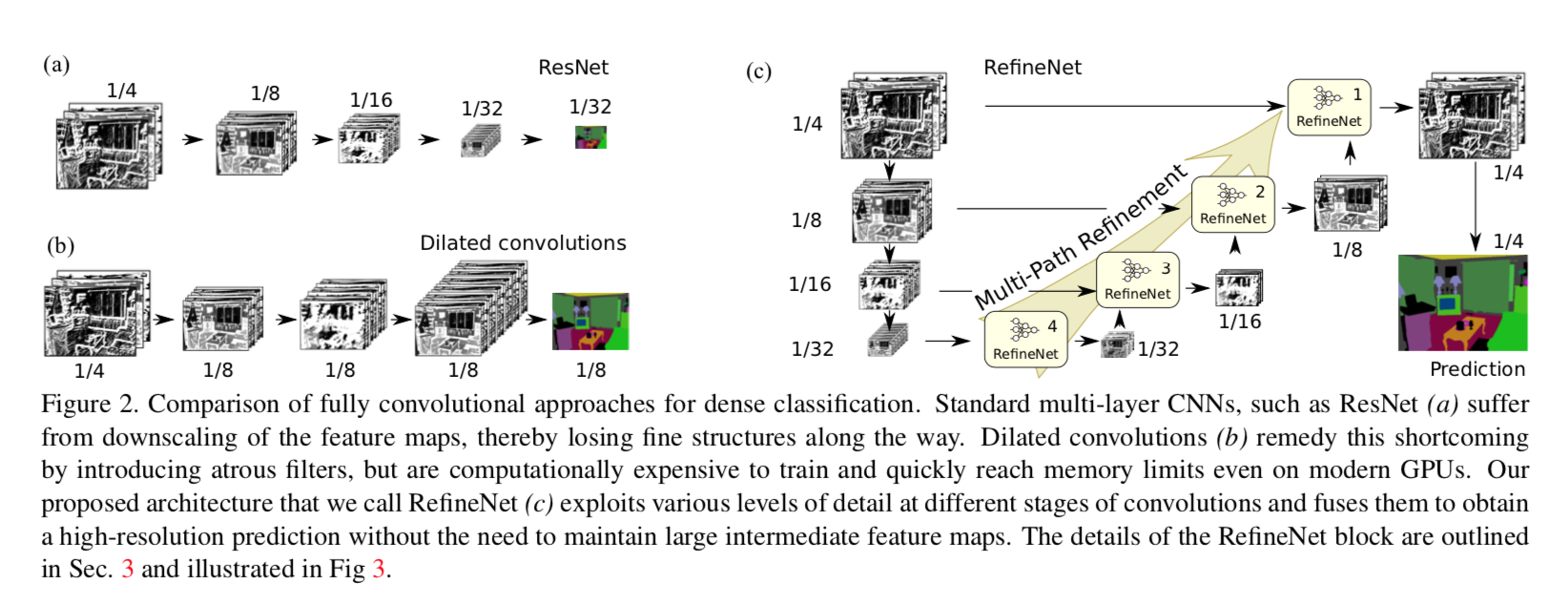
- pooling/conv stride:
方法
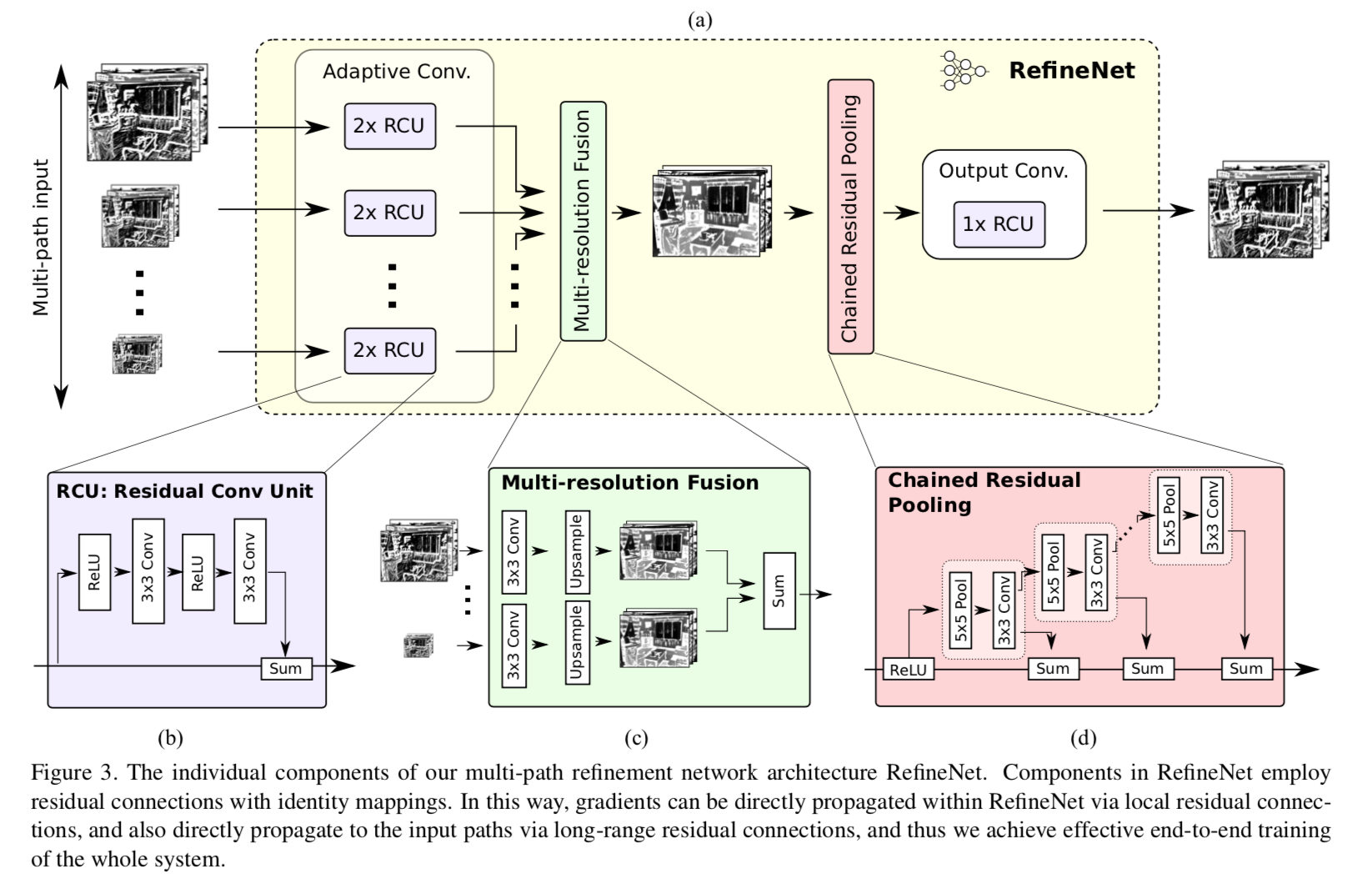
- backbone
- pretrained resnet
- 4 blocks:x4 - x32,each block:pool-residual
- connection:每个输出连接一个RefineNet unit
- 4-cascaded architecture
- final ouput:
- high-resolution feature maps
- dense soft-max
- bilinear interpolation to origin resolution
- cascade inputs
- output from backbone block
- ouput from previous refineNet block
- final ouput:
- refineNet block
- adapt conv:
- to adapt the dimensionality and refine special task
- BN layers are removed
- channel 512 for R4,channel 256 for the rest
- fusion:
- 先用conv to adapt dimension and recale the paths
- 然后upsamp
- summation
- 如果single input:walk through and stay unchanged
- chained residual pooling:
- aims to capture background context from a large image region
- chained:efficiently pool features with multiple window sizes
- pooling blocks:s1 maxpooling+conv
- in practice用了两个pooling blocks
- use one ReLU in the chained residual pooling block
- output conv:
- 一个residual:to employ non-linearity
- dimension remains unchanged
- final level:two additional RCUs before the final softmax prediction
- adapt conv:
- residual identity mappings
- a clean information path not block by any non-linearity:所有relu都在residual path里面
- 只有chained residual pooling模块起始时候有个ReLU:one single ReLU in each RefineNet block does not noticeably reduce the effectiveness of gradient flow
- linear operations:
- within the fusion block
- dimension reduction operations
- upsamp operations
- backbone
其他结构
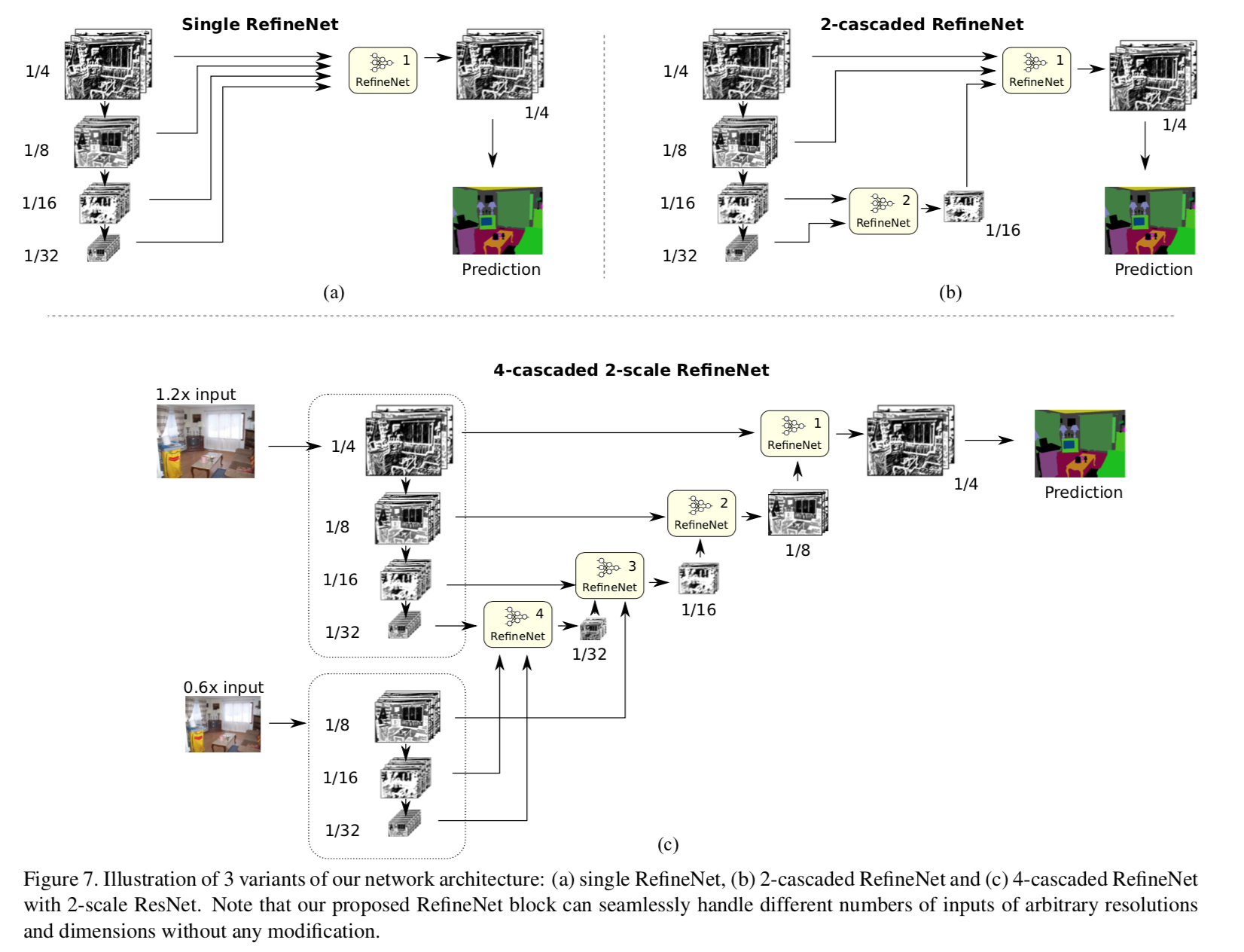
- 级联的就叫cascaded
- 一个block就叫single
- 多个input resolution就叫mult-scale
实验
- 4-cascaded works better than 1-cas & 2-cas
- 2-scale works better than 1-scale