[papers]
[centerNet] 真centerNet: Objects as Points,utexas,这个是真的centerNet,基于分割架构,预测中心点的heatmap,以及2-N个channel其他相关参数的回归
[cornet-centerNet] centerNet: Keypoint Triplets for Object Detection,这个抢先叫了centerNet,但是我觉得叫corner-centerNet更合适,它是基于cornerNet衍生的,在cornerNet的基础上再加一刀判定,基于角点pair的中心点是否是前景来决定是否保留这个框
[centerNet2] Probabilistic two-stage detection,utexas,
centerNet: Objects as Points
动机
anchor-based
- exhaustive list of potential locations
- wasteful, inefficient, requires additional post-processing
our detector
- center:use keypoint estimation to find center points
- other properties:regress
tasks
- object detection
- 3d object detection
multi-person human pose estimation
论点
- 相比较于传统一阶段、二阶段检测
- anchor:
- box & kp:一个是框,一个是击中格子
- nms:take local peaks,no need of nms
- larger resolution:hourglass架构,输出x4的heatmap,eliminates the need for multiple anchors
- anchor:
- 相比较于key point estimantion network
- them:require grouping stage
- our:只定位一个center point,no need for group or post-processing
- 相比较于传统一阶段、二阶段检测
方法
loss
关键点loss
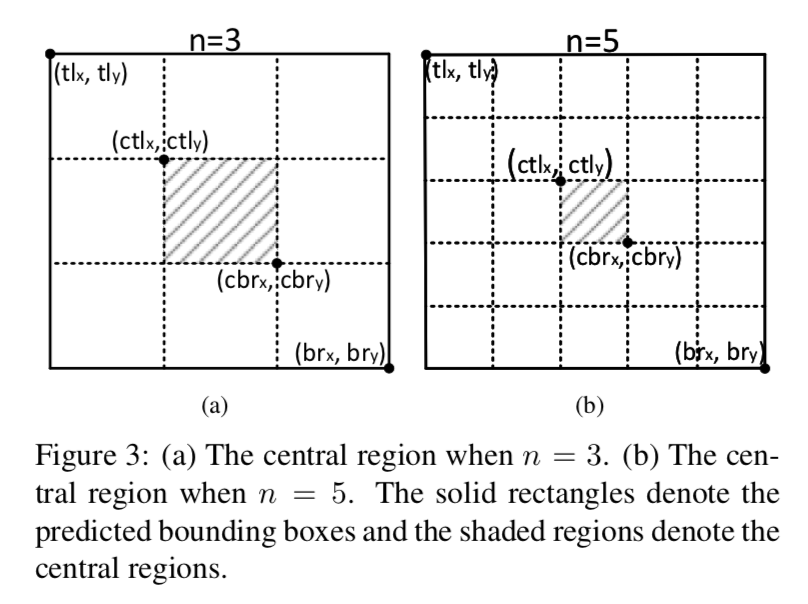
center point关键点定义:每个目标的gt point只有一个,以它为中心,做object size-adaptive的高斯penalty reduction,overlap的地方取max
focal loss:基本与cornetNet一致
- $\alpha=2, \beta=4$
- background points有penalty,根据gt的高斯衰减来的
offset loss
- 只有两个通道(x_offset & y_offset):shared among categories
- gt的offset是原始resolution/output stride向下取整得到
- L1 loss
centerNet
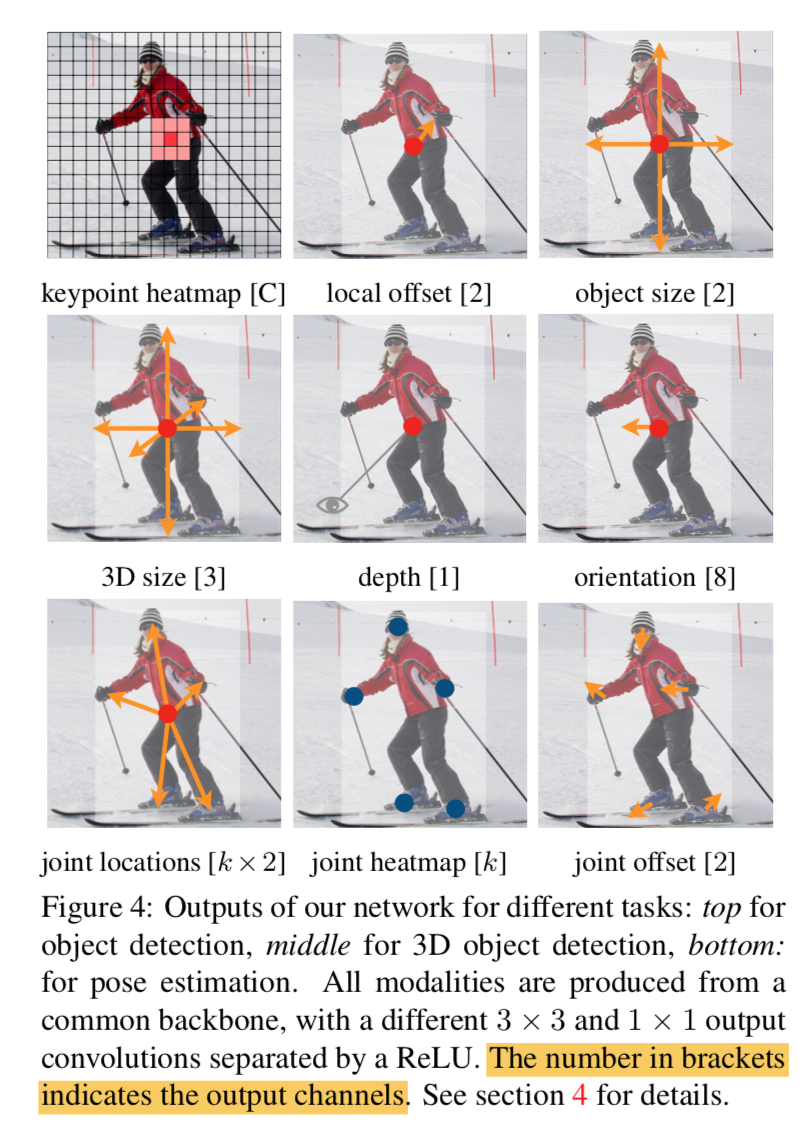
output
- 第一个部分:中心点,[h,w,c],binary mask for each category
- 第二个部分:offset,[h,w,2],shared among
- 第三个部分:size,[h,w,2],shared among
- L1 loss,use raw pixel coordinates
- overall
- C+4 channels,跟传统检测的formulation是一致的,只不过传统检测gt是基于anchor计算的相对值,本文直接回归绝对值
- $L_{det} = L_k + \lambda_{size} L_{size} + \lambda_{off} L_{off}$
- 其他task的formulation看第一张图
inference workflow
- local peaks:
- for each category channel
- all responses greater or equal to its 8-connected neighbors:3x3 max pooling
- keep the top100
- generate bounding boxes
- 组合offset & size predictions
- ????没有后处理了???假阳????
- local peaks:
encoder-decoder backbone:x4
- hourglass104
- stem:x4
- modules:两个
- resnet18/101+deformable conv upsampling
- 3x3 deformable conv, 256/128/64
- bilinear interpolation
DLA34+deformable conv upsampling
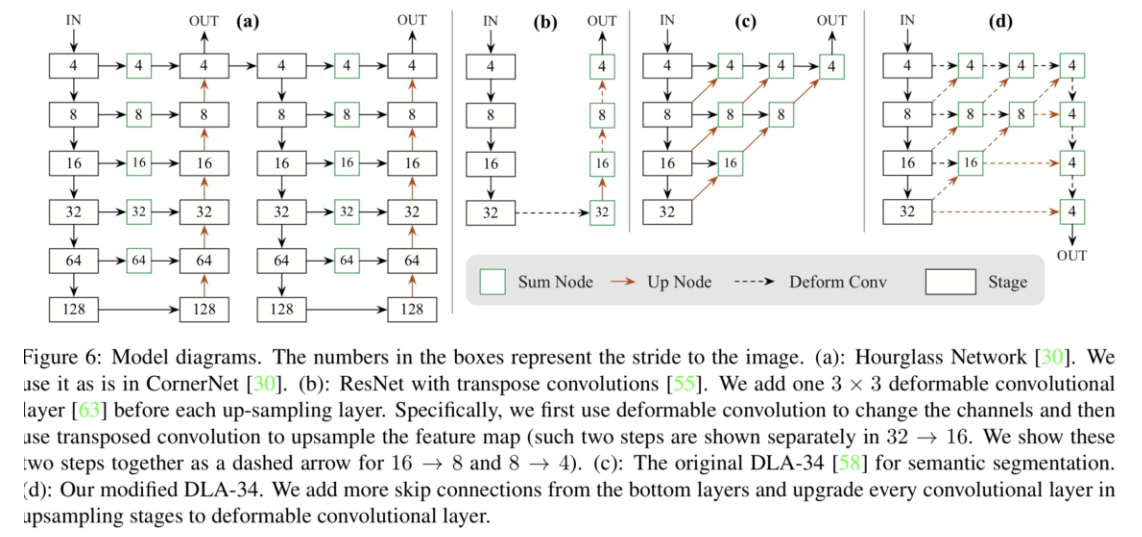
- hourglass104
heads
- independent heads
- one 3x3 conv,256
- 1x1 conv for prediction
总结
个人感觉,centerNet和anchor-based的formulation其实是一样的,
- center的回归对标confidence的回归,区别在于高斯/[0,1]/[0,-1,1]
- size的回归变成了raw pixel,不再基于anchor
- hourglass结构就是fpn,级联的hourglass可以对标bi-fpn
- 多尺度变成了单一大resolution特征图,也可以用多尺度预测,需要加NMS
centerNet2: Probabilistic two-stage detection
动机
- two-stage
- probabilistic interpretation
- the suggested pipeline
- stage1:infer proper object-backgroud likelihood,专注前背景分离
- stage2:inform the overall score
- verified on COCO
- faster and more accurate than both one and two stage detectors
- outperform yolov4
- extreme large model:56.4 mAP
- standard ResNeXt- 32x8d-101-DCN back:50.2 mAP
论点
- one-stage detectors
- dense predict
- jointly predict class & location
- anchor-based:RetinaNet用focal loss来deal with 前背景imbalance
- anchor-free:FCOS & CenterNet不基于anchor基于grid,缓解imbalance
- deformable conv:AlignDet在output前面加一层deformable conv to get richer features
- sound probablilistic interpretation
- heavier separate classification and regression branches than two-stage models:如果类别特别多的情况,头会非常重,严重影响性能
- misaligned issue:一阶段预测是基于local feature,感受野、anchor settings都会影响与目标的对齐程度
- two-stage detectors
- first RPN generates coarse object proposals
- then per-region head to classify and refine
- ROI heads:Faster-RCNN用了两个fc层作为ROI heads
- cascaded:CascadeRCNN用了三个连续的Faster-RCNN,with a different positive threshold
- semantic branch:HTC用了额外的分割分支enhance the inter-stage feature flow
- decouple:TSD将cls&pos两个ROI heads解耦
- weak RPN:因为尽可能提升召回率,proposal score也不准,丧失了一个clear的probabilistic interpretation
- independent probabilistic interpretation:两个阶段各训各的,最后的cls score仅用第二阶段的
- slow:proposals太多了所以slow down
- other detectors
- point-based:cornetNet预测&组合两个角点,centerNet预测中心点并基于它回归长宽
- transformer:DETR直接预测a set of bounding boxes,而不是传统的结构化的dense output
网络结构
- one/two-stage detectors:image classification network + lightweight upsampling layers + heads
- point-based:FCN,有symmetric downsampling and upsampling layer,预测一个小stride的heatmap
- DETR:feature extraction + transformer decoder
our method
- 第一个阶段
- 做二分类的one-stage detector,提前景,
- 实现上就用region-level feature+classifier(FCN-based)
- 第二阶段
- 做position-based类别预测
- 实现上既可以用一个Faster-RCNN,也可以用classifier
- 最终的loss由两个阶段合并得到,而不是分阶段训练
- 跟former two-stage framework的主要不同是
- 加了joint probabilistic objective over both stages
- 以前的二阶段RPN的用途主要是最大化recall,does not produce accurate likelihoods
- faster and more accurate
- 首先是第一个阶段的proposal更少更准
- 其次是第二个阶段makes full use of years of progress in two-stage detection,二阶段的设计站在伟人的肩膀上
- 第一个阶段
- one-stage detectors
方法
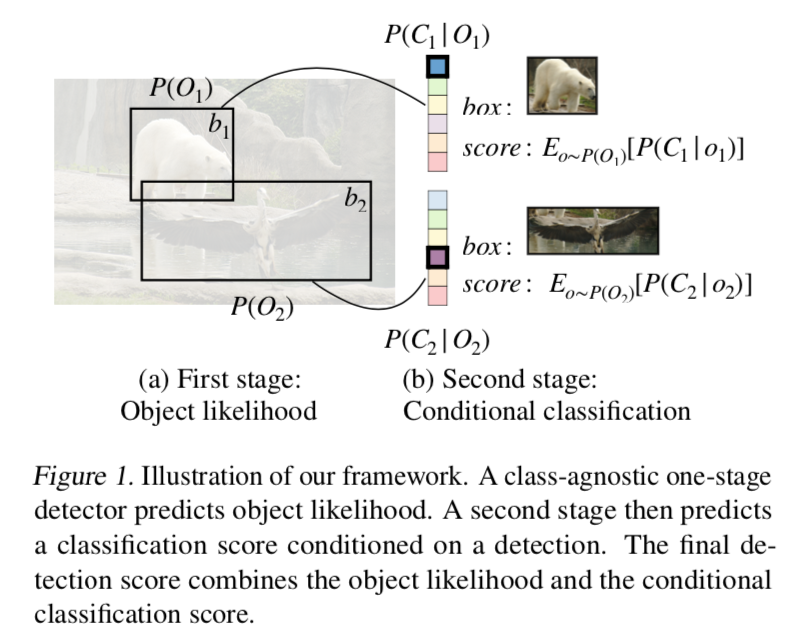
- joint class distribution:先介绍怎么将一二阶段联动
- 【第一阶段的前背景score】 乘上 【第二阶段的class score】
- $P(C_k) = \sum_o P(C_k|O_k=o)P(O_k=o)$
- maximum likelihood estimation
- for annotated objects
- 退阶成independent maximum-likelihood
- $log P(C_k) = log P(C_k|O_k=1) + log P(O_k=1)$
- for background class
- 不分解
- $log P(bg) = log( P(bg|O_k=1) * P(O_k=1) + P(O_k=0))$
- lower bounds,基于jensen不等式得到两个不等式
- $log P(bg) \ge P(O_k=1) * log( P(bg|O_k=1))$:如果一阶段前景率贼大,那么就
- $log P(bg) \ge P(O_k=0)$:
- optimize both bounds jointly works better
- for annotated objects
network design:介绍怎么在one-stage detector的基础上改造出一个two-stage probabilistic detector
- experiment with 4 different designs for first-stage RPN
- RetinaNet
- RetinaNet其实和two-stage的RPN高度相似核心区别在于:
- a heavier head design:4-conv vs 1-conv
- RetinaNet是backbone+fpn+individual heads
- RPN是backbone+fpn+shared convs+individual heads
- a stricter positive and negative anchor definition:都是IoU-based anchor selection,thresh不一样
- focal loss
- a heavier head design:4-conv vs 1-conv
- first-stage design
- 以上三点都在probabilistic model里面保留
- 然后将separated heads改成shared heads
- RetinaNet其实和two-stage的RPN高度相似核心区别在于:
- centerNet
- 模型升级
- 升级成multi-scale:use ResNet-FPN back,P3-P7
- 头是FCOS那种头:individual heads,不share conv,然后cls branch预测centerness+cls,reg branch预测regress params
- 正样本也是按照FCOS策略:position & scale-based
- 升级模型进行one-stage & two-stage实验:centerNet*
- 模型升级
- ATSS
- 是一个adaptive IoU thresh的方法,centerness来表示一个格子的score
- 我们将centerness*classification score定义为这个模型的proposal score
- 另外就是two-stage下还是将RPN的cls & reg heads合并
- GFL:还没看过,先跳过吧
- second-stage designs:FasterRCNN & CascadeR- CNN
- deformable conv:这个在centerNetv1的ResNet和DLA back里面都用了,在v2里面,主要是用ResNeXt-32x8d-101-DCN,
hyperparameters for two-stage probabilistic model
- 两阶段模型通常是用P2-P6,一阶段通常用P3-P7:我们用P3-P7
- increase the positive IoU threshold:0.5 to [0.6,0.7,0.8]
- maximum of 256 proposals (对比origin的1k)
- increase nms threshold from 0.5 to 0.7
- SGD,90K iterations
- base learning rate:0.02 for two-stage & 0.01 for one-stage,0.1 decay
- multi-scale training:短边[640,800],长边不超过1333
- fix-scale testing:短边用800,长边不超过1333
- first stage loss weight:0.5,因为one-stage detector通常用0.01 lr开始训练
- joint class distribution:先介绍怎么将一二阶段联动
实验
4种design的对比
- 所有的probabilistic model都比one-stage model强,甚至还快(因为简化了脑袋)
- 所有的probabilistic FasterRCNN都比原始的RPN-based FasterRCNN强,也快(因为P3-P7比P2-P6的计算量小一半,而且第二阶段fewer proposals)
CascadeRCNN-CenterNet design performs the best:所以以后就把它叫CenterNet2

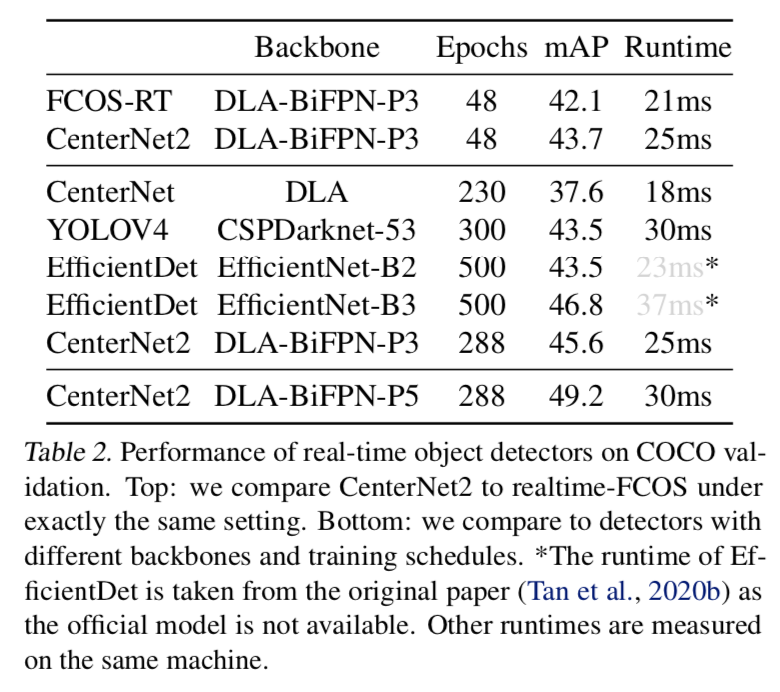
和其他real-time models对比
- 大多是real-time models都是一阶段模型
可以看到二阶段不仅能够比一阶段模型还快,精度还更高
SOTA对比
- 报了一个56.4%的sota,但是大家口碑上好像效果很差
- 不放图了
corner-centerNet: Keypoint Triplets for Object Detection
动机
based on cornerNet
triplet
- corner keypoints:weak grouping ability cause false positives
correct predictions can be determined by checking the central parts

cascade corner pooling and center poolling
论点
- whats new in CenterNet
- triplet inference workflow
- after a proposal is generated as a pair of corner keypoints
- checking if there is a center keypoint of the same class
- center pooling
- for predicting center keypoints
- by making the center keypoints on feature map having the max sum Hori+Verti responses
- cascade corner pooling
- equips the original corner pooling module with the ability of perceiving internal information
- not only consider the boundary but also the internal directions
- triplet inference workflow
- CornetNet痛点
- fp rate高
- small object的fp rate尤其高
- 一个idea:cornerNet based RPN
- 但是原生RPN都是复用的
- 计算效率?
- whats new in CenterNet
方法
center pooling
- geometric centers & semantic centers
center pooling能够有效地将语义信息最丰富的点(semantic centers)传达到物理中心点(geometric centers),也就是central region