MegDet: A Large Mini-Batch Object Detector
动机
- past methods mainly come from novel framework or loss design
this paper studies the mini-batch size
- enable training with a large mini-batch size
- warmup learning rate policy
- cross-gpu batch normalization
faster & better acc
论点
potential drawbacks with small mini-batch sizes
long training time
inaccurate statistics for BN:previous methods use fixed statistics from ImageNet which is a sub-optimal trade-off
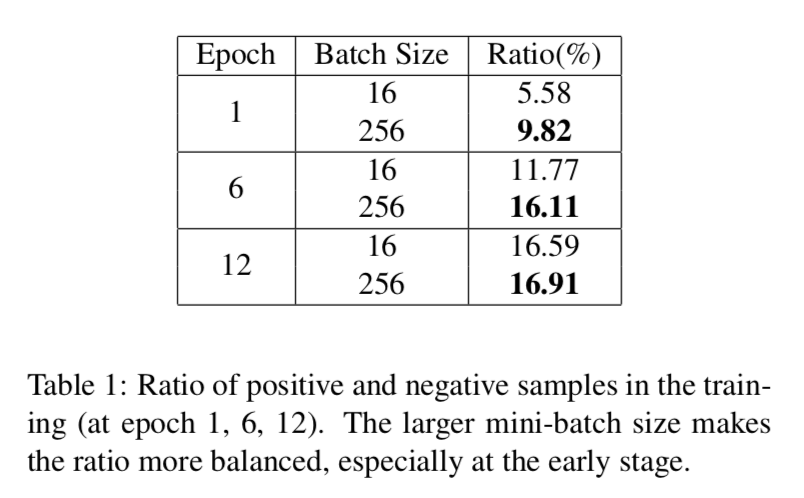
positive & negative training examples are more likely imblanced
加大batch size以后,正负样本比例有提升,所以yolov3会先锁着back开大batchsize做warmup
learning rate dilemma
- large min-batch size usually requires large learning rate
- large learning rate is likely leading to convergence failure
- a smaller learning rate often obtains inferior results
solution of the paper
- linear scaling rule
- warmup
- Cross-GPU Batch Normalization (CGBN)
方法
warmup
- set up the learning rate small enough at the be- ginning
- then increase the learning rate with a constant speed after every iteration, until fixed
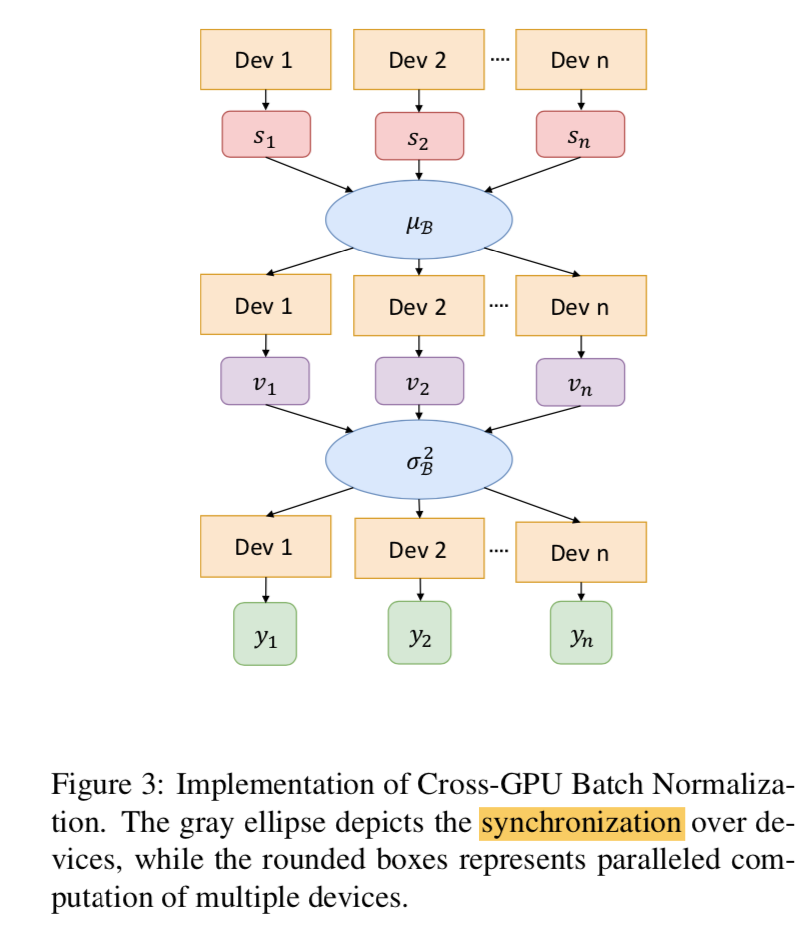
Cross-GPU Batch Normalization
- 两次同步
tensorpack里面有

一次同步
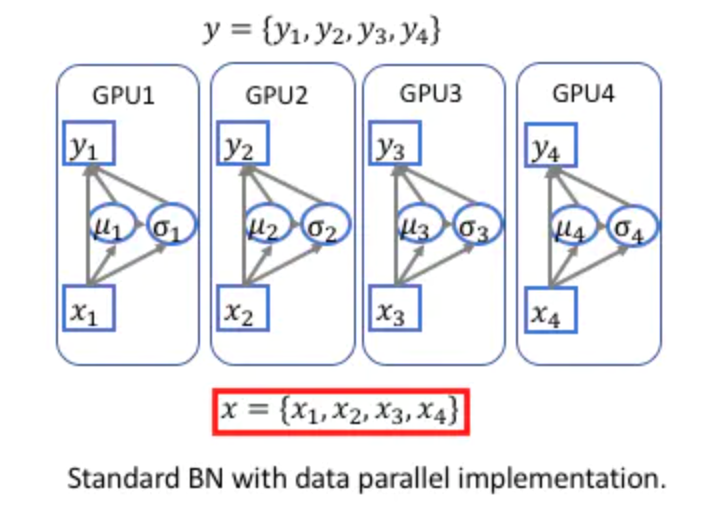
异步BN:batch size 较小时,每张卡计算得到的统计量可能与整体数据样本具有较大差异
同步:
需要同步的是每张卡上计算的统计量,即BN层用到的均值$\mu$和方差$\sigma^2$
这样多卡训练结果才与单卡训练效果相当
两次同步:
第一次同步均值:计算全局均值
第二次同步方差:基于全局均值计算各自方差,再取平均
一次同步:
核心在于方差的计算
首先均值:$\mu = \frac{1}{m} \sum_{i=1}^m x_i$
- 然后是方差:
* 计算每张卡的$\sum x_i$和$\sum x_i^2$,就可以一次性算出总均值和总方差