[MimicDet] ResNeXt-101 backbone on the COCO: 46.1 mAP
MimicDet: Bridging the Gap Between One-Stage and Two-Stage Object Detection
动机
- mimic task:knowledge distillation
- mimic the two-stage features
- a shared backbone
- two heads for mimicking
- end-to-end training
- specialized designs to facilitate mimicking
- dual-path mimicking
- staggered feature pyramid
- reach two-stage accuracy
论点
- one-stage detectors adopt a straightforward fully convolutional architecture
- two-stage detectors use RPN + R-CNN
- advantages of two-stage detectors
- avoid class imbalance
- less proposals enables larger cls net and richer features
- RoIAlign extracts location consistent feature -> better represenation
- regress the object location twice -> better refined
- one-stage detectors’ imitation
- RefineDet:cascade detection flow
- AlignDet:RoIConv layer
- still leaves a big gap
- network mimicking
- knowledge distillation
- use a well-trained large teacher model to supervise
- difference
- mimic in heads instead of backbones
- teacher branch instead of model
- trained jointly
- this method
- not only mimic the structure design, but also imitate in the feature level
- contains both one-stage detection head and two-stage detection head during training
- share the same backbone
- two-stage detection head, called T-head
- one-stage detection head, called S-head
- similarity loss for matching feature:guided deformable conv layer
- together with detection losses
- specialized designs
- decomposed detection heads
- conduct mimicking in classification and regression branches individually
- staggered feature pyramid
方法
overview
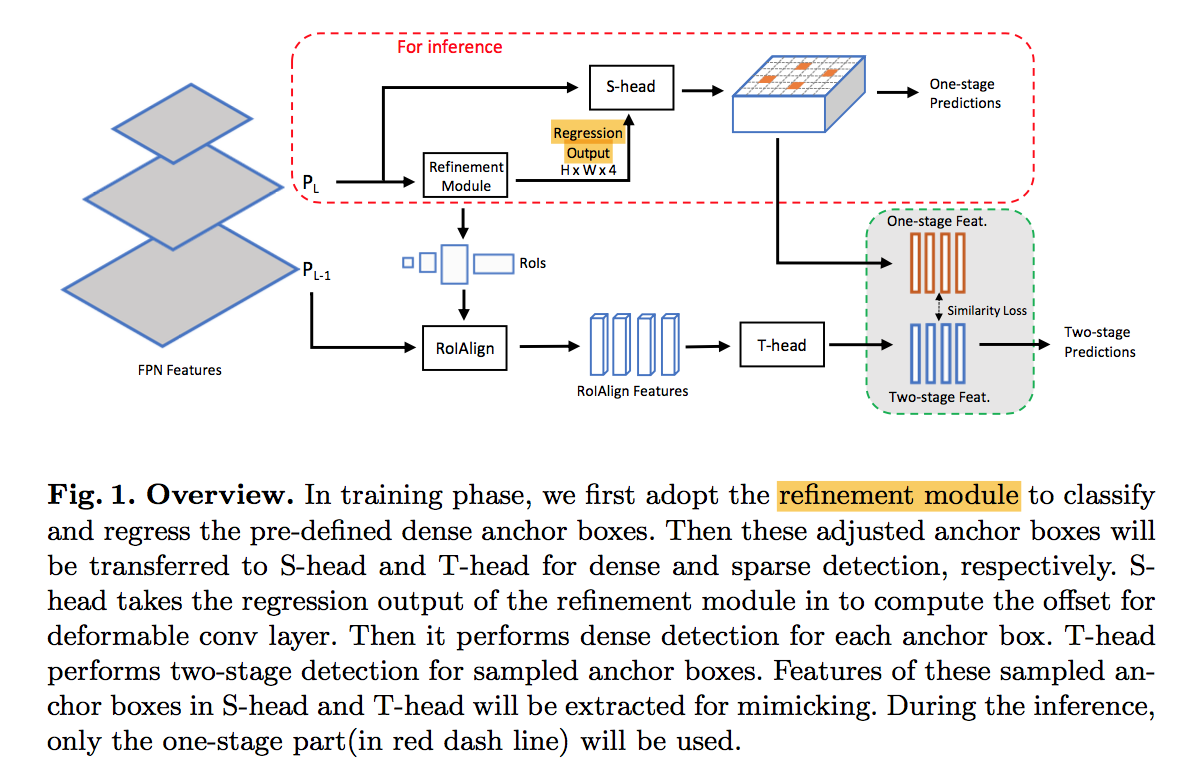
back & fpn
- RetinaNet fpn:with P6 & P7
- crucial modification:P2 ~ P7
- staggered feature pyramid
- high-res set {P2 to P6}:for T-head & accuray
- low-res set {P3 to P7}:for S-head & computation speed
refinement module
- filter out easy negatives:mitigate the class imbalance issue
- adjust the location and size of pre-defined anchor boxes:anchor initialization
- module
- on top of the feature pyramid
- one 3x3 conv
- two sibling 1x1 convs
- binary classification:bce loss
- bounding box regression:the same as Faster R-CNN,L1 loss
- top-ranked boxes transferred to T-head and S-head
- one anchor on each position:avoid feature sharing among proposals
- assign the objects to feature pyramid according to their scale
- positive area:0.3 times shrinking of gt boxes from center
- positive sample:
- valid scale range:gt target belongs to this level
- central point of anchor lies in the positive area
detection heads
- T-head
- heavy head
- run on a sparse set of anchor boxes
- use the staggered feature pyramid
- generate 7x7 location-sensitive features for each anchor box
- cls branch
- two 1024-d fc layers
- one 81-d fc layer + softmax:ce loss
- reg branch
- four 3x3 convs,ch256
- flatten
- 1024-d fc
- 4-d fc:L1 loss
- mimicking target
- 81-d classification logits
- 1024-d regression feature
- S-head
- light-weight
- directly dense detection on fpn
- 【不太理解】introducing the refinement module will break the location consistency between the anchor box and its corresponding features:我的理解是refine以后的anchor和原始anchor对应的特征图misalign了,T-head用的是refined anchor,S-head用的是original grid,所以misalign
- use deformable convolution to capture the misaligned feature
- deformation offset is computed by a micro-network
- takes the regression output of the refinement module as input
- three 1x1 convs,ch64/128/18(50)
- 3x3 Dconv for P3 and 5x5 for others,ch256
- two sibling 1x1 convs,ch1024
- cls branch:1x1 conv,ch80
- reg branch:1x1 conv,ch4
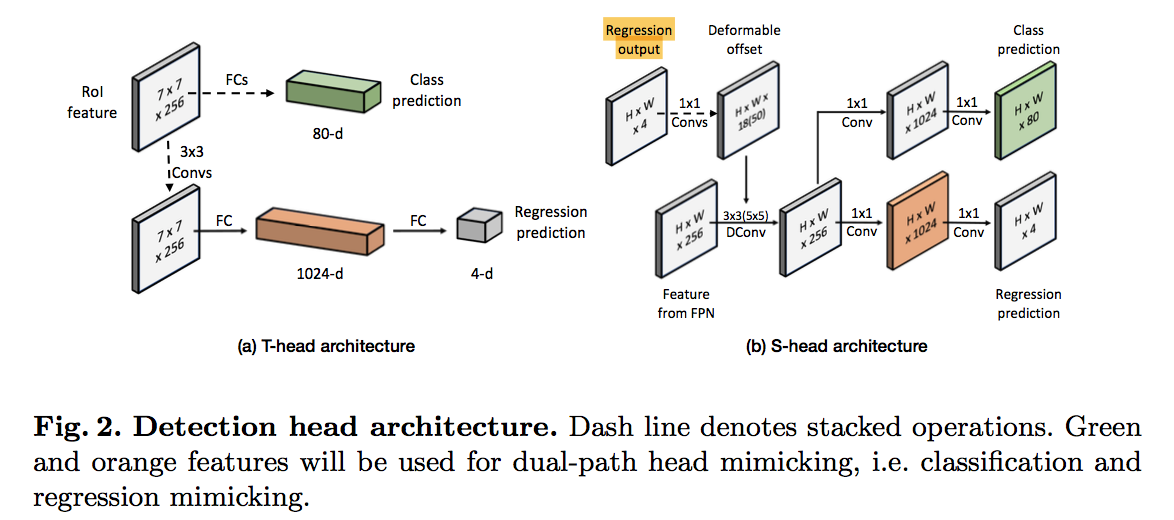
- T-head
head mimicking
- cosine similarity
- cls logits & refine params
- To get the S-head feature of an adjusted anchor box
- trace back to its initial position
- extract the pixel at that position in the feature map
- loss:$L_{mimic} = 1 - cosine(F_i^T, F_i^S)$
- multi-task training loss
- $L = L_R + L_S + L_T + L_{mimic}$
- $L_R$:refine module loss,bce+L1
- $L_S$:S-head loss,ce+L1
- $L_T$:T-head loss,ce+L1
- $L_{mimic}$:mimic loss
- training details
- network:resnet50/101,resize image with shorter side 800
- refinement module
- run NMS with 0.8 IoU threshold on anchor boxes
- select top 2000 boxes
- T-head
- sample 128 boxes from proposal
- p/n:1/3
- S-head
- hard mining:select 128 boxes with top loss value
- inference
- take top 1000 boxes from refine module
- NMS with 0.6 IoU threshold and 0.005 score threshold
- 【??】finally top 100 scoring boxes:这块不太理解,最后应该不是结构化输出了啊,应该是一阶段检测头的re-refine输出啊