因为不是googlenet家族官方出品,所以放在外面
[EfficientFCN] EfficientFCN: Holistically-guided Decoding for Semantic Segmentation:商汤,主要针对upsampling是局部感受野,重建失真多,分割精度差的问题,提出了Holistically-guided Decoder (HGD) ,用来recover the high-resolution (OS=8) feature maps,想法上接近SCSE-block,数学表达上接近bilinear-CNN,性能提升主要归因于eff back吧。
EfficientFCN: Holistically-guided Decoding for Semantic Segmentation
动机
- Semantic Segmentation
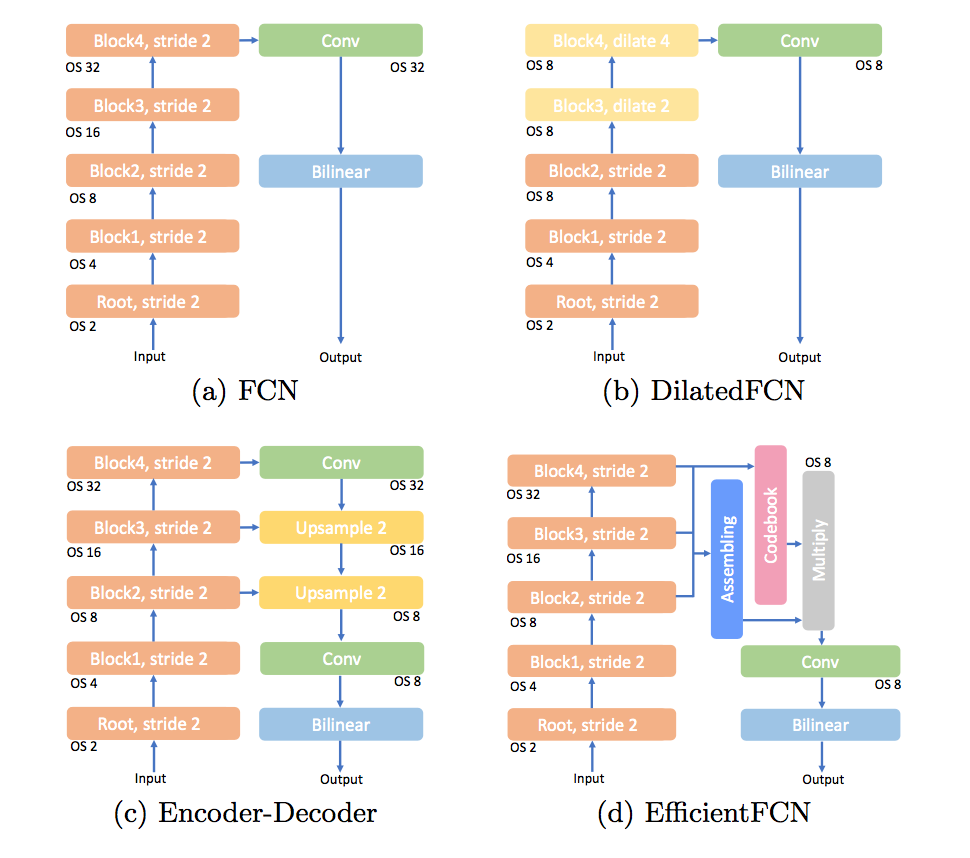
- dilatedFCN:computational complexity
- encoder-decoder:performance
- proposed EfficientFCN
- common back without dilated convolution
- holistically-guided decoder
- balance performance and efficiency
- Semantic Segmentation
论点
- key elements for semantic segmentation
- high-resolution feature maps
- pre-trained weights
- OS32 feature map:the fine-grained structural information is discarded
- dilated convolution:no extra parameters introduced but equire high computational complexity and memory consumption
- encoder-decoder based methods
- repeated upsampling + skip connection procedure
- upsampling
- concat/add
- successive convs
- Even with the skip connections, lower-level high-resolution feature maps cannot provide abstractive enough features for achieving high- performance segmentation
- The bilinear upsampling or deconvolution operations are conducted in a local manner(from a limited receptive filed)
- improvements
- reweight:SE-block
- scales each feature channel but maintains the original spatial size and structures:【scse block对spacial有加权啊】
- repeated upsampling + skip connection procedure
propose EfficientFCN
- widely used classification model
- Holistically-guided Decoder (HGD)
- take OS8, OS16, OS32 feature maps from backbone
- OS8和OS16用来spatially guiding the feature upsampling process
- OS32用来encode the global context然后基于guidance进行上采样
- linear assembly at each high-resolution spatial location:感觉就是对上采样特征图做了加权
- key elements for semantic segmentation
方法
Holistically-guided Decoder
- multi-scale feature fusion
- holistic codebook generation
- from high-level feature maps
- holistic codewords:without any spatial order
codeword assembly
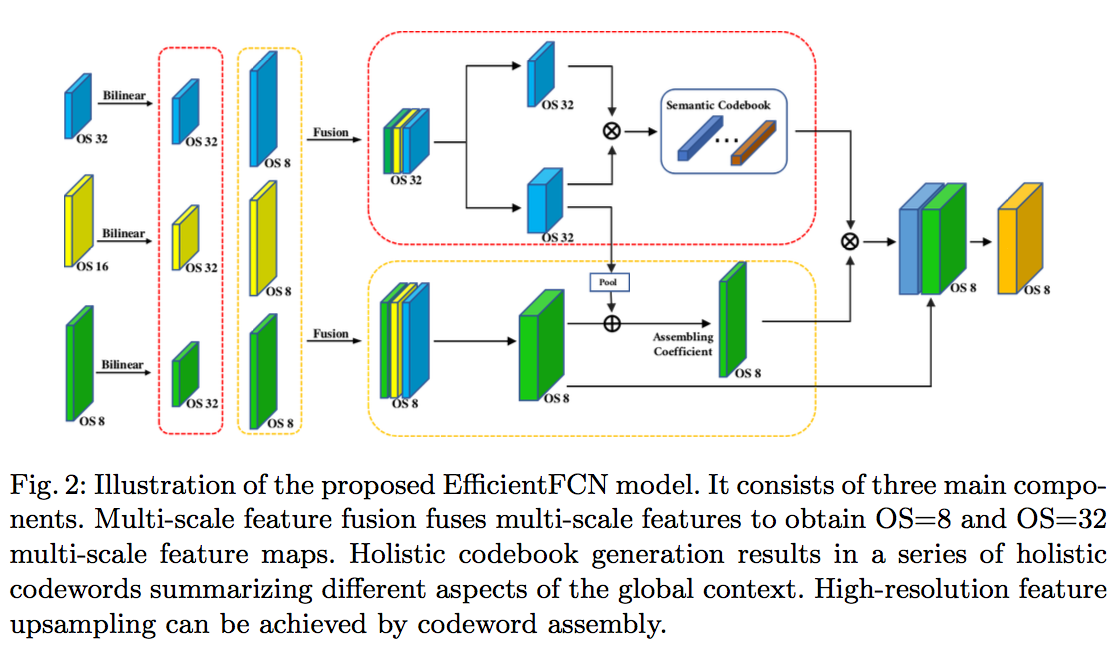
multi-scale feature fusion
- we observe the fusion of multi-scale feature maps generally result in better performance
- compress:separate 1x1 convs
- bilinear downsamp/upsamp
- concatenate
- fused OS32 $m_{32}$ & fused OS8 $m_8$
holistic codebook generation
- from $m_{32}$
- two separate 1x1 conv
- a codeword based map $B \in R^{1024(H/32)(W/32)}$:每个位置用一个1024-dim的vector来描述
- n spatial weighting map $A\in R^{n(H/32)(W/32)}$:highlight 特征图上不同区域
- softmax norm in spatial-dim
- $\widetilde A_i(x,y)=\frac{exp(A_i(x,y))}{\sum_{p,q} exp(A_i(p,q))}, i\in [0,n)$
- codeword $c_i \in R^{1024}$
- global description for each weighting map
- weighted average of B on all locations
- $c_i = \sum_{p,q} \widetilde A_i(p,q) B(p,q)$
- each codeword captures certain aspect of the global context
- orderless high-level global features $C \in R^{1024*n}$
- $C = [c_1, …, c_n]$
codeword assembly
- raw guidance map $G \in R^{1024(H/8)(W/8)}$:1x1 conv on $m_8$
- fuse semantic-rich feature map $\overline B \in R^{1024}$:global average vector
- novel guidance feature map $\overline G = G \oplus \overline B $:location-wise addition【????】
- linear assembly weights of the n codewords $W \in R^{n(H/8)(W/8)}$:1x1 conv on $\overline G$
- holistically-guided upsampled feature $\tilde f_8 = W^T C$:reshape & dot
- final feature map $f_8$:concat $\tilde f_8$ and $G$
final segmentation
- 1x1 conv
- further upsampling
实验
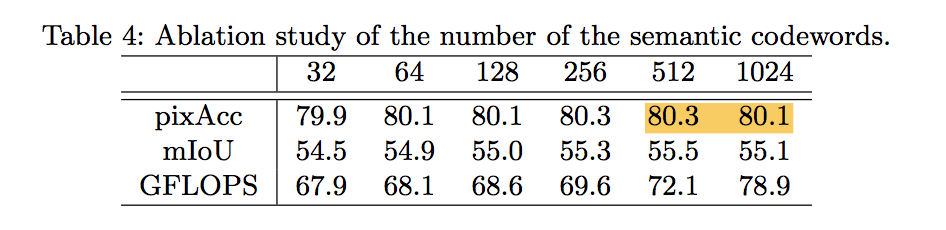
numer of holistic codewords
- 32-512:increase
- 512-1024:slight drop
we observe the number of codewords needed is approximately 4 times than the number of classes