papers
- [v1 2019] Deep High-Resolution Representation Learning for Human Pose Estimation:base HRNet,提出parallel multi-resolution subnetworks,highest resolution output作为输出
- [v2 2019] High-Resolution Representations for Labeling Pixels and Regions:simple modification,在末端输出的时候加了一步融合,将所有resolution-level的feature上采样到output-level然后concat
Deep High-Resolution Representation Learning for Human Pose Estimation
动机
- human pose estimation
- high-resolution representations through
- existing methods recover high-res feature from the low,大多数方法是recover系
- this methods maintain the high-res from start to the end,本文是maintaining系
- add high-to-low resolution subnetworks
- repeated multi-scale fusions
- more accurate and spatially more precise
- estimate on the high-res output,最后的high-res representation作为输出,接各种task heads
论点
in parallel rather than in series:potentially spatially more precise,相比较于recover类的架构,不会导致过多的spatial resolution loss,recover类的架构有时会用空洞卷积来维持resolution来降低spatial resolution loss
repeated multi- scale fusions:boost both high&low representations,more accurate
pose estimation
- probabilistic graphical model
- regression
- heatmap
High-to-low and low-to-high frameworks
- Symmetric high-to-low and low-to-high:Hourglass
- Heavy high-to-low and light low-to-high:ResNet back + simple bilinear upsampling
Heavy high-to-low with dilated convolutions and further lighter low-to-high:ResNet with atrous conv + fewer bilinear upsampling
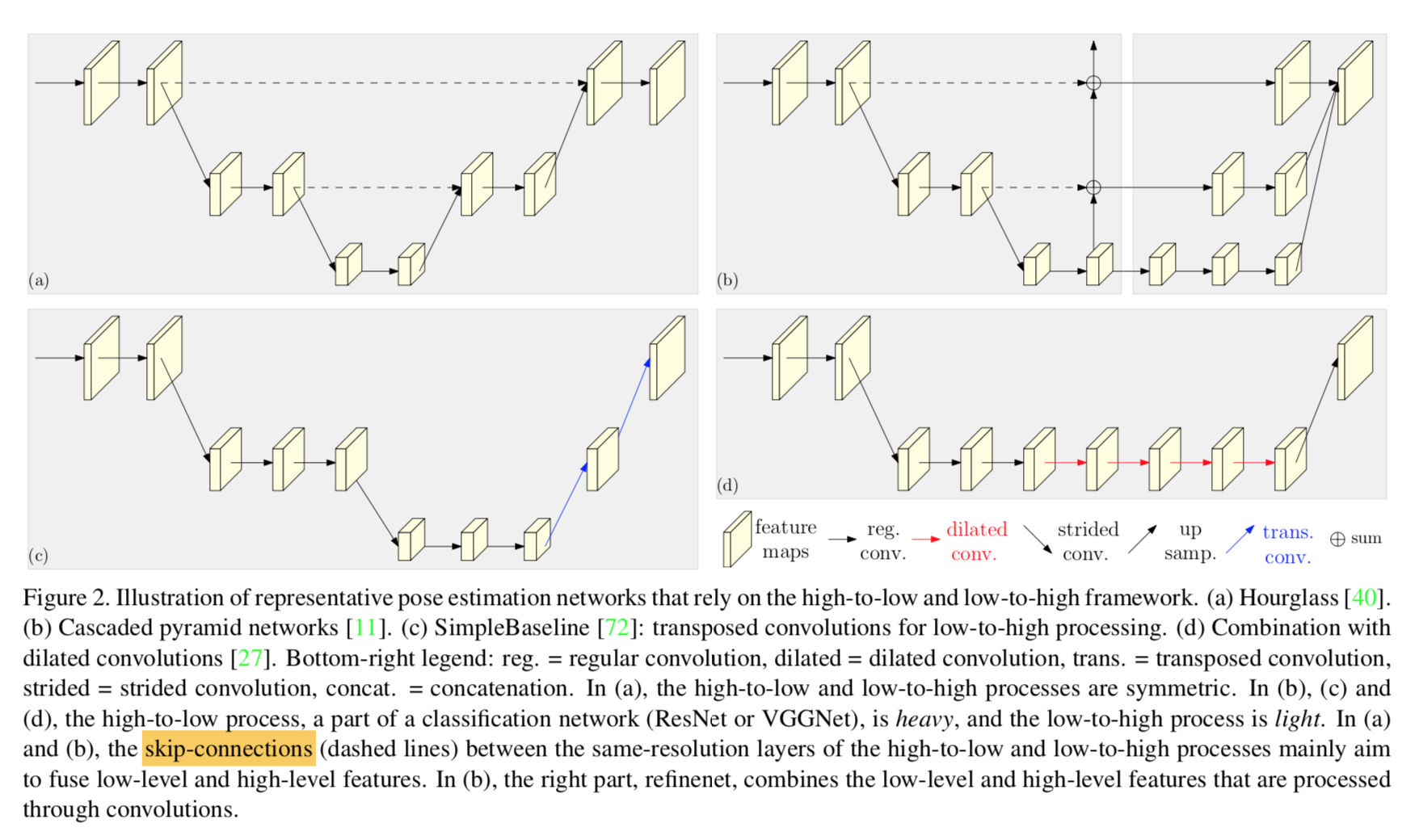
high-to-low part和low-to-hight part:有对称和不对称两种,对称就如Hourglass,不对称就是down-path使用heavy classification backboens,up-path使用轻量的上采样
- fusion:
- a和b都有skip-connections,将down-path和up-path的特征融合,目的是融合low-level和high-level的特征
- a里面还有不同resolution level的融合
- fusion方式有sum/concat
- refinenet:也就是up-path,可以用upSampling/transpose convs
方法
task description
- human pose estimation = keypoint detection
- detect K keypoints from an Image (H,W,3)
- state-of-the art methods:predict K heatmaps,each indicates one of the keypoint
- a stem with 2 strided conv
- a body outputting features with the same input resolution
- a regressor estimating heatmaps
- we focus on the design of the main body
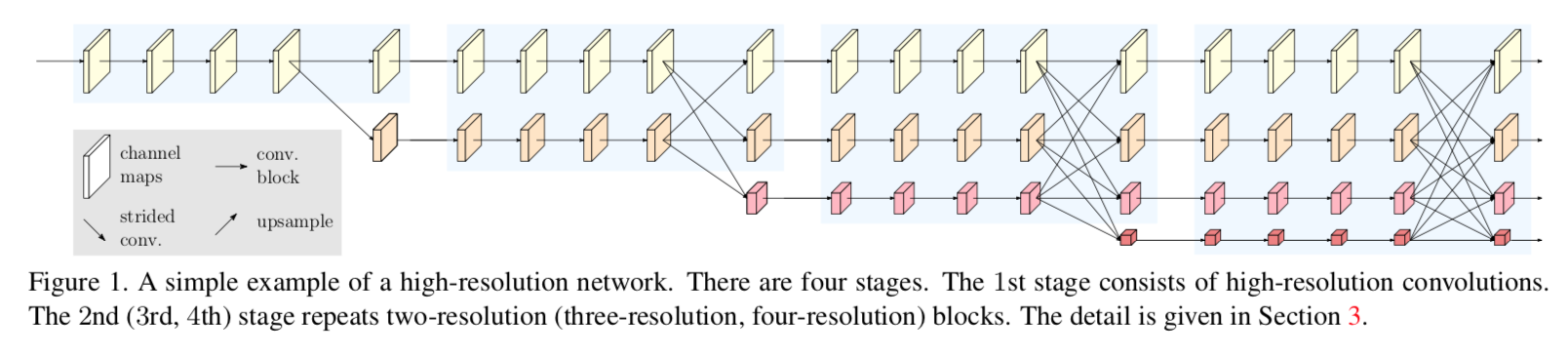
sequential & parallel multi-resolution networks
notation:$N_{sr}$
- s is the stage
- r is the resolution index,denotes $\frac{1}{2^{r-1}}$ of the resolution of the first subnetwork
sequential
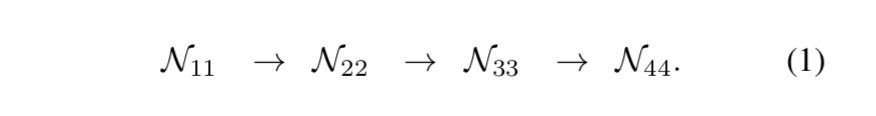
parallel
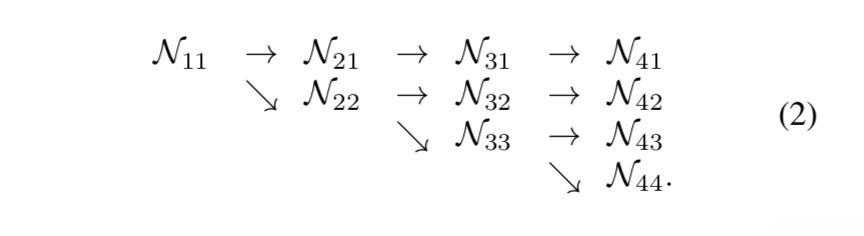
overview
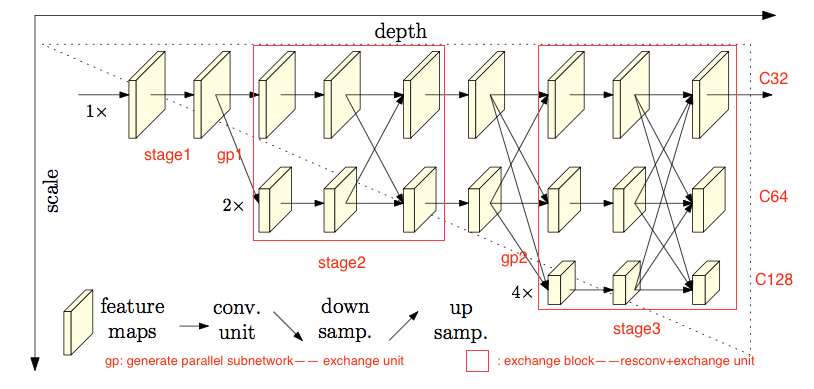
- four stages
- channels double when halve the res
- 1st stage
- 第一个stage是一个high-resolution subnetwork,没有下采样,没有parallel分支
- 4 residual units,bottleneck resblock
- width=64
- 3x3 conv reducing width to C
- 2、3、4 stages
- 接下来的stage gradually add high-to-low subnetwork
- 是multi-resolution subnetworks
- 每个subnetwork都比前一个多一个extra lower one resolution
- contain 1, 4, 3 exchange blocks respectively
- exchange block
- conv:4 residual units,two 3x3 conv
- exchange unit
- width
- C:width of the high-resolution subnetworks in last three stages
- other three parallel subnetworks
- HRNet-W32:64, 128, 256
- HRNet-W48:96, 192, 384
repeated multi-scale fusion
exchange blocks:每个high-to-low subnetwork包含多个parallel分支,每条path称为exchange block,每个exchange block包含一系列3-conv-units + a exchange unit
3-conv-units:堆叠卷积核,提取特征,加深网络
exchange unit:交换不同resolution level的信息
notations:一系列输入$\{X_1,X_2, …, X_r\}$,一系列输出$\{Y_1,Y_2, …, Y_r\}$,如果跨stage还有一个$Y_{r+1}$
每个$Y_k$都是一个aggregation of the input maps:$Y_k=\sum^s_i a(X_i,k)$
- i<k:需要下采样,每下采样一倍都是一个stride2-3x3-conv
- i=k:identify connection
- i>k:需要上采样,nearest neighbor upsamp + 1x1-align-conv
k=$r+1$:需要在$Y_r$的基础上,在执行一次stride2-3x3-conv下采样得到
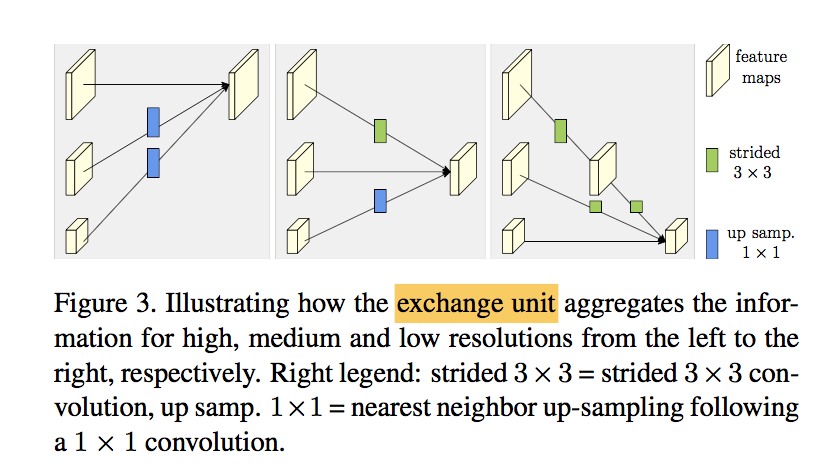
fusion:sum,所以上/下采样都需要通道对齐,输出map和对应level的输入map保持尺寸不变
heatmap estimation
- from the last high-res exchange unit
- mse
- gt gassian map:std=1
network instantiation
- stem + 4 stages
- 每个new stage input:res halved and channel doubled
- stem
- 两个s2-conv-bn-relu,channel 64
- first stage:
- 使用和ResNet-50中一样的4个residual units,channel 64
- 然后用一个3x3-conv调整channel到一个起始channel C
- 2/3/4 stage
- 堆叠exchange blocks,分别有1/4/3个exchange block
- 每个exchange block使用4个residual units和1个exchange unit
- 也就是总共有8次multi-scale fusion
- channel C/2C/4C
- HRNet-32:C=64
- HRNet-48:C=96
HRNet v2: High-Resolution Representations for Labeling Pixels and Regions
动机
- High-resolution representation很重要
- HRNet v1已经有不错的结果
- a further study on high resolution representations
- a small modification:之前只关注high-resolution representations,现在关注所有level的output representations
论点
获得high resolution representation的两大方式
- recover系:先下采样,然后用low-resolution重建,Hourglass,U-net,encoder-decoder
- maintain系:始终保留high-resolution的representation,同时不断用parallel low-resolution representations来strengthen,HRNet
HRNet
- maintains high-resolution representations
- connecting high-to-low resolution convolutions in parallel
- repeatedly conducting multi-scale fusions across levels
- 简单来说,就是在每个阶段,保留现有resolution level,同时
不仅representation足够强大(融合了low-level high semantic info),还spatially precise
our modification HRNetV2
- HRNet 里面我们只关注最上面的high-resolution representation
- HRNet V2里面我们探索所有high-to-low parallel paths上面的representations
- 在语意分割任务中我们使用output high resolution representations来生成heatmaps
- 在检测任务中我们将multi-level的representations给到FastRCNN
方法
Architecture
- multi-resolution block
- multi-resolution group convolution:在每个representation level分别执行分组卷积,deeper
- multi-resolution convolution:发生在所有representation level上
- 下采样:stride-2 3x3 conv
- 上采样:bilinear /nearest neighbor
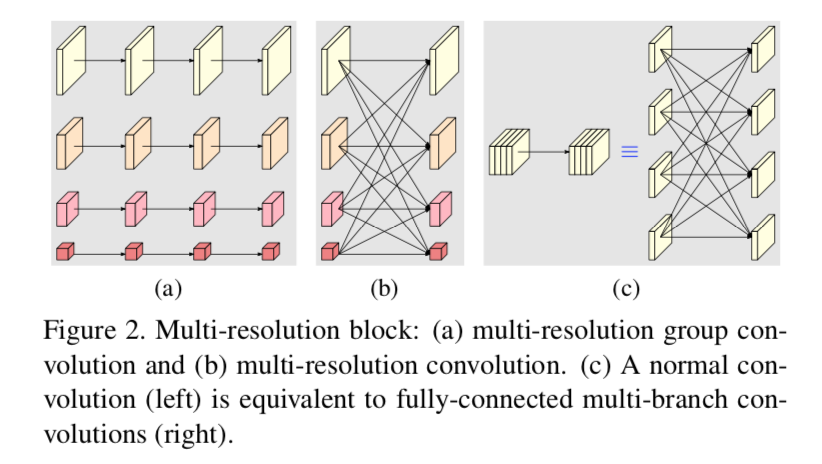
- multi-resolution block
Modification
- HRNetV1:只把最后一个阶段 highest resolution的representation作为输出
HRNetV2:最后一个阶段,每个resolution level的representations都上采样到highest,然后concat作为输出,甚至还将这个输出进一步下采样得到feature pyramid
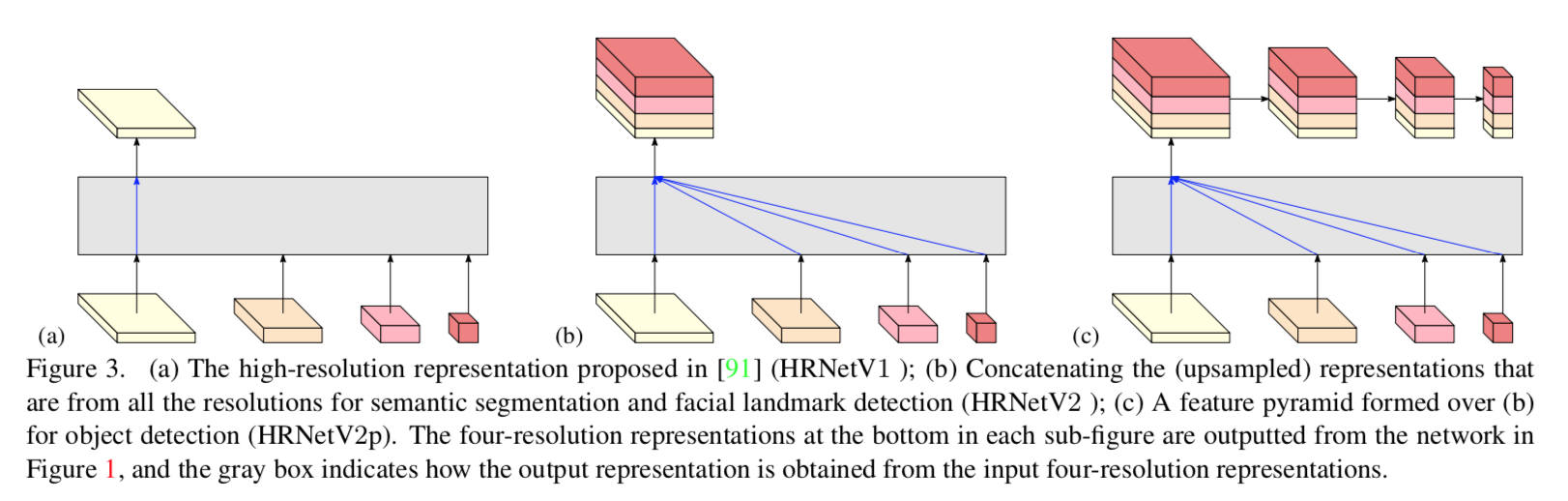
HRNet for classification:也可以反向操作,将最后一个阶段每个resolution level的representations都下采样到lowest,然后sum,最后output 2048-dim representation is fed into the classifier

实验