[mixup] mixup: BEYOND EMPIRICAL RISK MINIMIZATION:对不同类别的样本,不仅可以作为数据增广手段,还可以用于semi-supervised learning(MixMatch)
[mixmatch] MixMatch: A Holistic Approach to Semi-Supervised Learning:针对半监督数据的数据增广
[mosaic] from YOLOv4
[AutoAugment] AutoAugment: Learning Augmentation Policies from Data:google
[RandAugment] RandAugment: Practical automated data augmentation with a reduced search space:google
RandAugment: Practical automated data augmentation with a reduced search space
动机
- AutoAugment
- separate search phase
- run on a subset of a huge dataset
- unable to adjust the regularization strength based on model or dataset size
RandAugment
- significantly reduced search space
- can be used uniformly across tasks and datasets
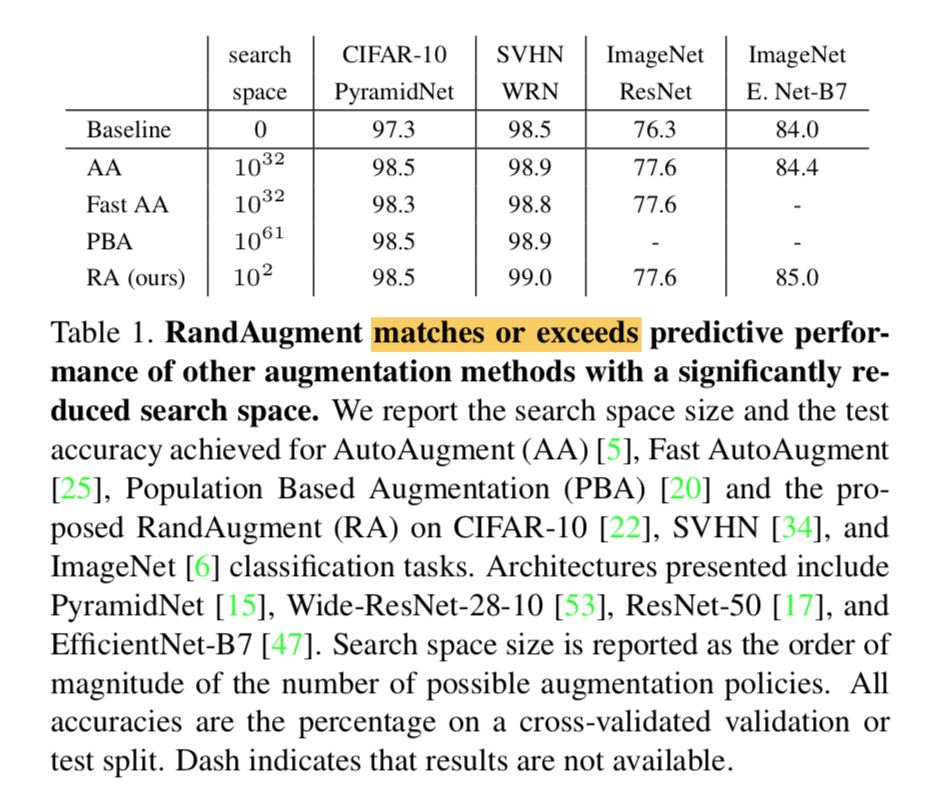
- match or exceeds the previous val acc
- AutoAugment
方法
formulation
always select a transformation with uniform prob $\frac{1}{K}$
given N transformations for an image:there are $K^N$ potential policies
fixied magnitude schedule M:we choose Constant,因为只要一个hyper

run naive grid search
疑问:这样每个op等概率,就不再data-specific了,也看不出自然图像更prefer color transformation这种结论了
AutoAugment: Learning Augmentation Policies from Data
动机
search for data augmentation policies
propose AutoAugment
- create a search space composed of augmentation sub-policies
- one sub-policy is randomly choosed per image per mini-batch
- a sub-policy consists of two base operations
find the best policy:yields the highest val acc on the target dataset
the learned policy can transfer
- create a search space composed of augmentation sub-policies
论点
- data augmentation
- to teach a model about invariance
- in data domain is easier than hardcoding it into model architecture
- currently dataset-specific and often do not transfer:
- MNIST:elastic distortions, scale, translation, and rotation
- CIFAR & ImageNet:random cropping, image mirroring and color shifting / whitening
- GAN:直接生成图像,没有归纳policy
- we aim to automate the process of finding an effective data augmentation policy for a target dataset
- each policy:
- operations in certain order
- probabilities after applying
- magnitudes
- use reinforcement learning as the search algorithm
- each policy:
- contributions
- SOTA on CIFAR & ImageNet & SVHN
- new insight on transfer learning:使用预训练权重没有显著提升的dataset上,使用同样的aug policies则会涨点
- data augmentation
方法
formulation
search space of policies
- policy:a policy consists of 5 sub-policies
- sub-policy:each sub-policy consisting of two image operations
- operation:each operation is also associated with two hyperparameters
- probability:of applying the operation,uniformly discrete into 11 values
- magnitude:of the operation,uniformly discrete into 10 values
- a mini-batch share the same chosen sub-policy
operations:16 in total,mainly use PIL
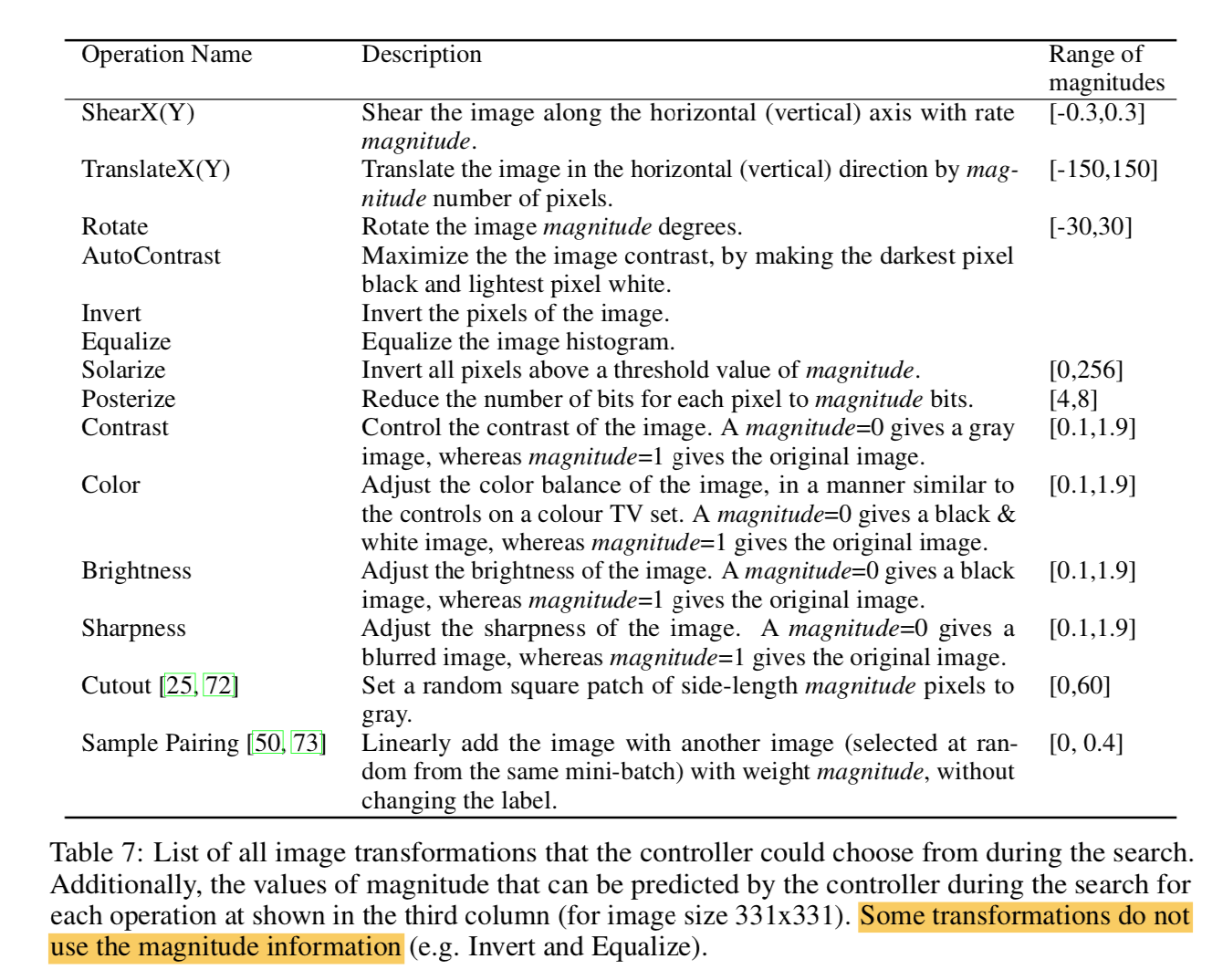
- https://blog.csdn.net/u011583927/article/details/104724419有各种operation的可视化效果
- shear是砍掉图像一个角的畸变
- equalize是直方图均衡化
- solarize是基于一定阈值的invert,高于阈值invert,低于阈值不变
- posterize也是一种像素值截断操作
- color是调整饱和度,mag<1趋近灰度图
- sharpness决定图像模糊/锐化
- sample pairing:两张图加权求和,但是不改变标签
searching goal
- with $(161011)^2$ choices of sub-policies
- we want 5
example
- 一个sub-policy包含两个operation
- 每个operation有一定的possibility做/不做
每个operation有一定的magnitude决定做后的效果

结论
On CIFAR-10, AutoAugment picks mostly color-based transformations
on ImageNet, AutoAugment focus on color-based transformations as well, besides geometric transformation and rotate is commonly used
one of the best policy

overall results

mixup: BEYOND EMPIRICAL RISK MINIMIZATION
动机
- classification task
- memorization and sensitivity issue
- reduces the memorization of corrupt labels
- increases the robustness to adversarial examples
- improves the generalization
- can be used to stabilize the training of GANs
- propose convex combinations of pairs of examples and their labels
论点
ERM(Empirical Risk Minimization):issue of generalization
- allows large neural networks to memorize (instead of generalize from) the training data even in the presence of strong regularization
- neural networks change their predictions drastically when evaluated on examples just outside the training distribution
VRM(Vicinal Risk Minimization):introduce data augmentation
- e.g. define the vicinity of one image as the set of its horizontal reflections, slight rotations, and mild scalings
- vicinity share the same class
- does not model the vicinity relation across examples of different classes
- ERM中的training set并不是数据的真实分布,只是用有限数据来近似真实分布,memorization也会最小化training error,但是对training seg以外的sample就leads to undesirable behaviour
- mixup就是VRM的一种,propose a generic vicinal distribution,补充vicinity relation across examples of different classes
方法
mixup
constructs virtual training examples
use two examples drawn at random:raw inputs & raw one-hot labels
理论基础:linear interpolations of feature vectors should lead to linear interpolations of the associated targets
hyper-parameter $\alpha$
- $\lambda = np.random.beta(\alpha, \alpha)$
- controls the strength of interpolation
初步结论
three or more examples mixup does not provide further gain but more computation
interpolating only between inputs with equal label did not lead to the performance gains
key elemets——two inputs with different label
vis
decision boundaries有了一个线性过渡
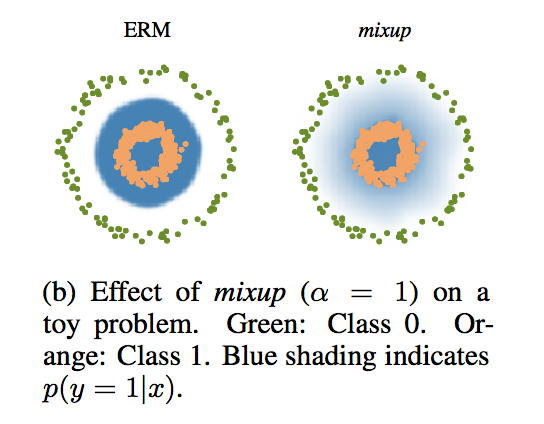
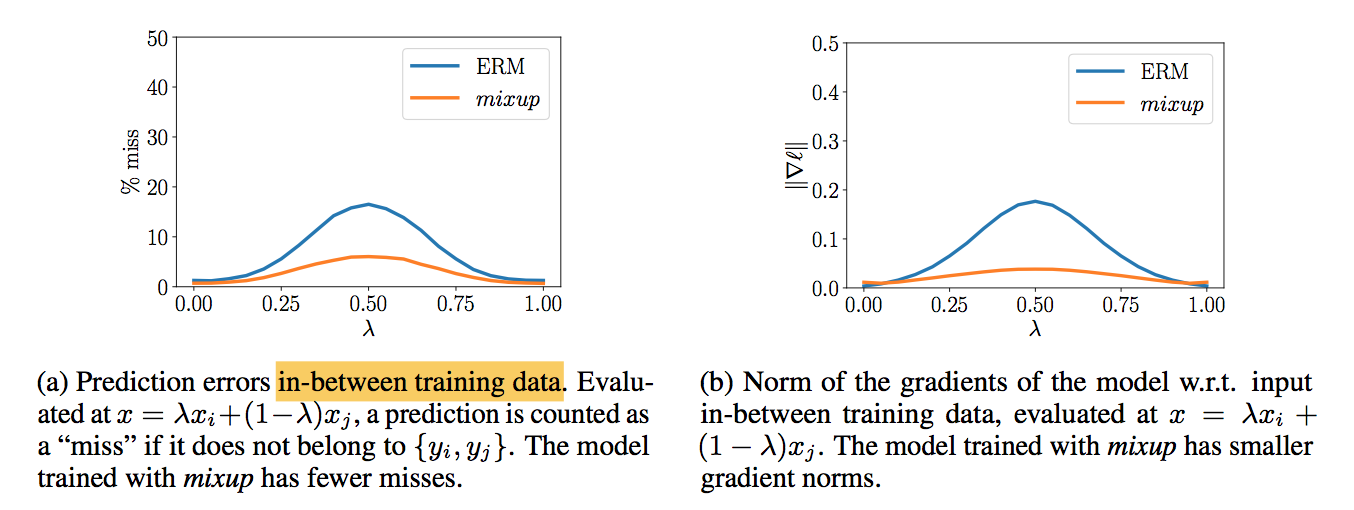
更准确 & 梯度更小:error少所以loss小所以梯度小??
实验
初步分类实验
- $\alpha \in [0.1, 0.4]$ leads to improved performance,largers leads to underfitting
- models with higher capacities and/or longer training runs are the ones to benefit the most from mixup
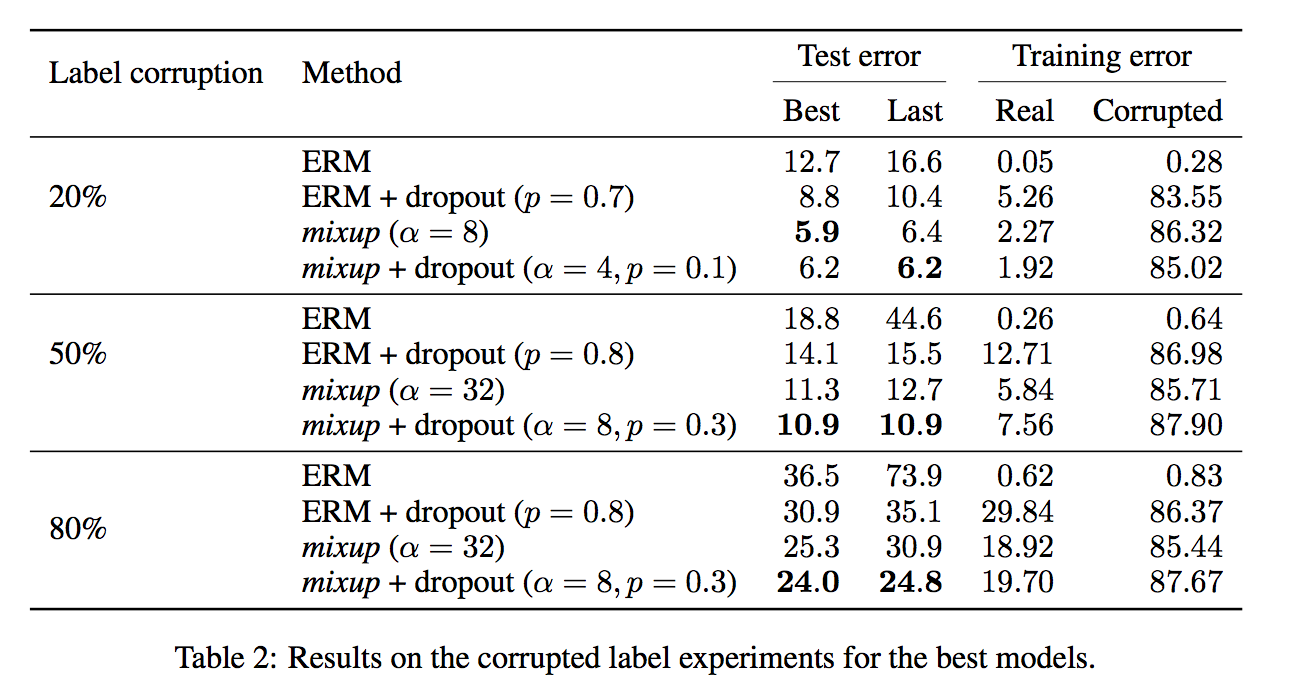
memorization of corrupted labels
- 将数据集中一部分label换成random noise
- ERM直接过拟合,在corrupted sample上面training error最小,测试集上test error最大
- dropout有效防止过拟合,但是mixup outperforms它
corrupted label多的情况下,dropout+mixup performs the best
robustness to adversarial examples
- Adversarial examples are obtained by adding tiny (visually imperceptible) perturbations
- 常规操作data augmentation:produce and train on adversarial examples
- add significant computational:样本数量增多,梯度变化大
- mixup results in a smaller loss and gradient norm:因为mixup生成的假样本“更合理一点”,梯度变化更小
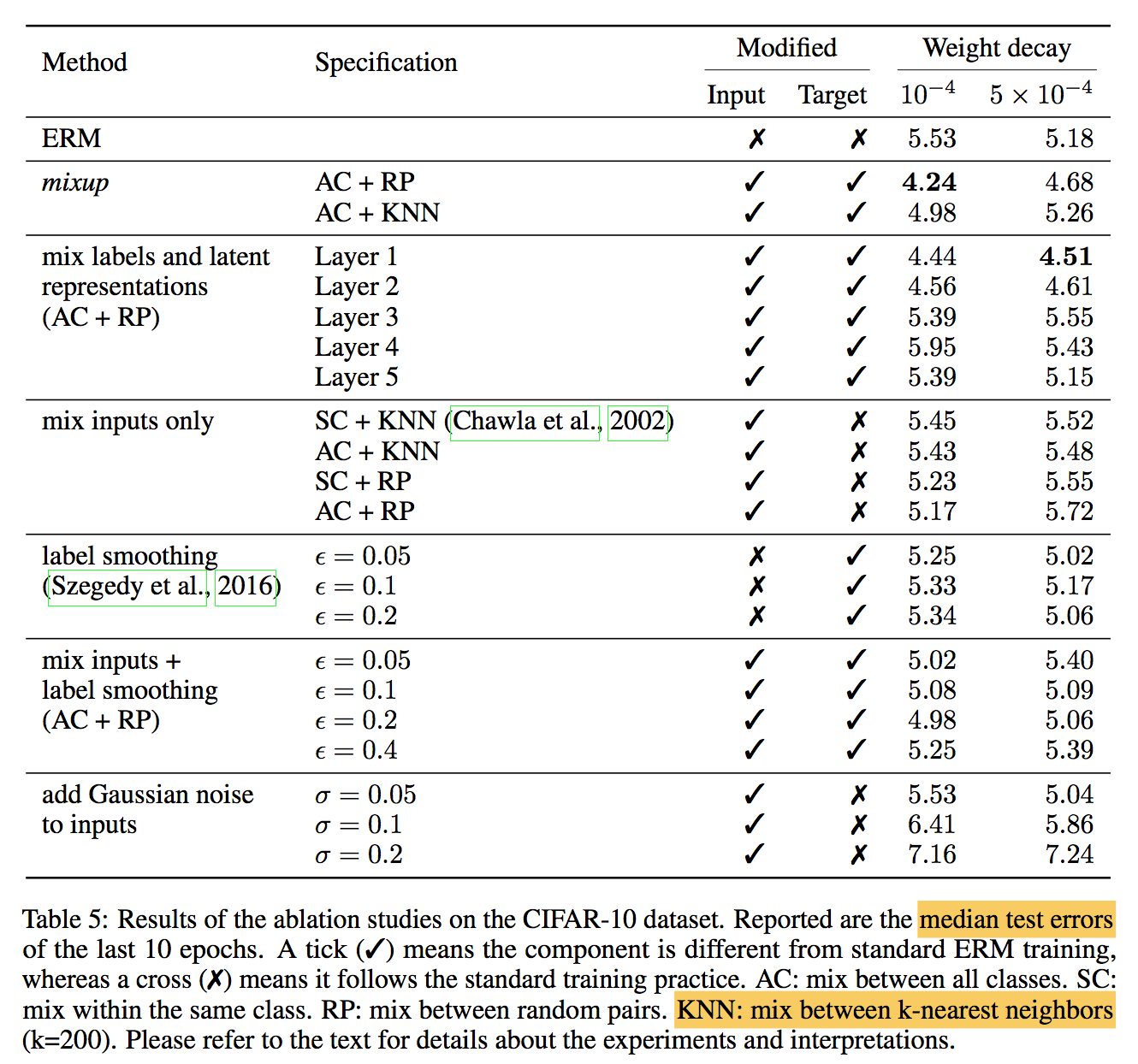
ablation study
mixup is the best:绝对领先第二mix input + label smoothing
the effect of regularization
- ERM需要大weight decay,mixup需要小的——说明mixup本身的regularization effects更强
- 高层特征mixup需要更大的weight decay——随着层数加深regularization effects减弱
AC+RP最强
label smoothing和add Gaussian noise to inputs 相对比较弱
- mix inputs only(SMOTE) shows no gain
MixMatch: A Holistic Approach to Semi-Supervised Learning
动机
- semi-supervised learning
- unify previous methods
- proposed mixmatch
- guessing low-entropy labels
- mixup labeled and unlabeled data
- useful for differentially private learning
论点
- semi-supervised learning add a loss term computed on unlabeled data and encourages the model to generalize better to unseen data
- the loss term
- entropy minimization:decision boundary应该尽可能远离数据簇,因此prediction on unlabeled data也应该是high confidence
- consistency regularization:增强前后的unlabeled data输出分布一致
- generic regularization:weight decay & mixup
- MixMatch unified all above
- introduces a unified loss term for unlabeled data
方法
overview
- given:a batch of labeled examples $X$ and a batch of labeled examples $U$
- augment+label guess:a batch of augmented labeled examples $X^{‘}$ and a batch of augmented labeled examples $U^{‘}$
- compute:separate labeled and unlabeled loss terms $L_X$ and $L_U$
combine:weighted sum

MixMatch
data augmentation
- 常规augmentation
- 作用于每一个$x_b$和$u_b$
- $u_b$做$K$次增强
label guessing
- 对增强的$K$个$u_b$分别预测,然后取平均
- average class prediction
sharpening
- reduce the entropy of the label distribution
- 拉高最大prediction,拉小其他的
- $Sharpen (p, T)_i =\frac{p_i^{\frac{1}{T}}}{\sum^{N}_j p_j^{\frac{1}{T}}} $
- $T$趋近于0的时候,processed label就接近one-hot了
mixup
slightly modified form of mixup to make the generated sample being more closer to the original

loss function
- labeled loss:typical cross-entropy loss
unlabeled loss:squared L2,bounded and less sensitive to completely incorrect predictions
hyperparameters
sharpening temperature $T$:fixed 0.5
- number of unlabeled augmentations $K$:fixed 2
- MixUp Beta parameter $\alpha$:0.75 for start
- unsupervised loss weight $\lambda_U$:100 for start
Algorithm

实验
[mosaic] from YOLOv4