动机
- to understand label smoothing
- improving generalization
- improves model calibration
- changes the representations learned by the penultimate layer of the network
- effect on knowledge distillation of a student network
- soft targets:a hard target and the uniform distribution of other classes
- to understand label smoothing
论点
- label smoothing implicitly calibrates the learned models
- 能让confidences更有解释性——more aligned with the accuracies of their predictions
- label smoothing impairs distillation——teacher用了label smoothing,student会表现变差,this adverse effect results from loss of information in the digits
- label smoothing implicitly calibrates the learned models
方法
modeling
- penultimate layer:fc with activation
- $p_k = \frac{e^{wx}}{\sum e^{wx}}$
- outputs:loss
- $H(y,p)=\sum_{k=1}^K -y_klog(p_k)$
- hard targets:$y_k$ is 1 for the correct class and 0 for the rest
- label smoothing:$y_k^{LS} = y_k(1-\alpha)+ \alpha /K$
- penultimate layer:fc with activation
visualization schem
- 将dimK activation vector投影到正交平面上,a dim2 vector per example
clusters are much tighter because label smoothing encourages that each example in training set to be equidistant from all the other class’s templates
3 classes shows triangle structure since ‘equidistant’
- predictions‘ absolute values are much bigger without LM, representing over-confident
- semantically similar classes are harder to separate,但是总体上cluster形态还是好一点
- training without label smoothing there is continuous degree of change between two semantically similar classes,用了LM以后就观察不到了——相似class之间的语义相关性被破坏了,’erasure of information’
- have similar accuracies despite qualitatively different clustering,对分类精度的提升不明显,但是从cluster形态上看更好看
model calibration
making the confidence of its predictions more accurately represent their accuracy
metric:expected calibration error (ECE)
reliability diagram
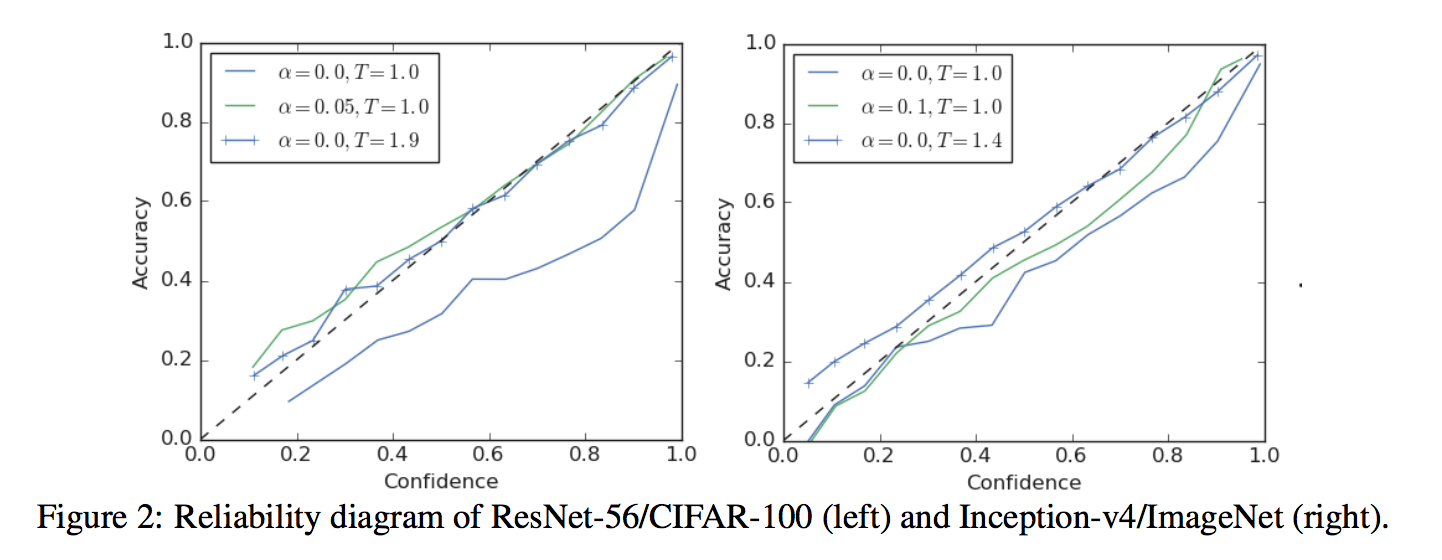
better calibration compared to the unscaled network
Despite trying to collapse the training examples to tiny clusters, these networks generalize and are calibrated:在训练集上的cluster分布非常紧凑,encourage每个样本都和其他类别的cluster保持相同的距离,但是在测试集上,样本的分布就比较松散了,不会限定在小小的一坨内,说明网络没有over-confident,representing the full range of confidences for each prediction
knowledge distillation
even when label smoothing improves the accuracy of the teacher network, teachers trained with label smoothing produce inferior student networks
As the representations collapse to small clusters of points, much of the information that could have helped distinguish examples is lost
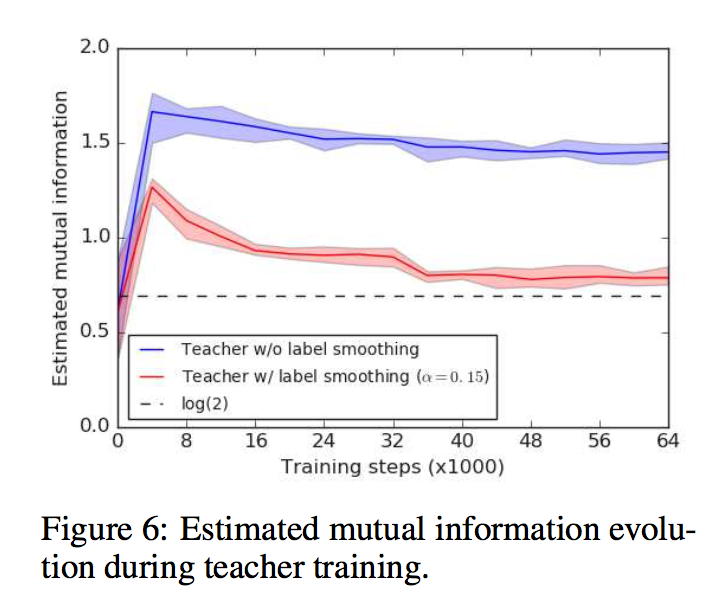
看training set的scatter,LM会倾向于将一类sample集中成为相似的表征,sample之间的差异性信息丢了:Therefore a teacher with better accuracy is not necessarily the one that distills better