Self-training with Noisy Student improves ImageNet classification
动机
- semi-supervised learning(SSL)
- semi-supervised approach when labeled data is abundant
- use unlabeled images to improve SOTA model
- improve self-training and distillation
- accuracy and robustness
- better acc, mCE, mFR
- EfficientNet model on labeled images
- student
- even or larger student model
- on labeled & pseudo labeled images
- noise, stochastic depth, data augmentation
- generalizes better
- process iteration
- by putting back the student as the teacher
论点
- supervised learning which requires a large corpus of labeled images to work well
- robustness
- noisy data:unlabeled images that do not belong to any category in ImageNet
- large margins on much harder test sets
- training process
- teacher
- EfficientNet model on labeled images
- student
- even or larger student model
- on labeled & pseudo labeled images
- noise, stochastic depth, data augmentation
- generalizes better
- process iteration
- by putting back the student as the teacher
- teacher
- improve in two ways
- it makes the student larger:因为用了更多数据
- noised student is forced to learn harder:因为label有pseudo labels,input有各类augmentation,网络有dropout/stochastic depth
- main difference compared with Knowledge Distillation
- use noise ——— KD do not use
- use equal/larger student ——— KD use smaller student to learn faster
- think of as Knowledge Expansion
- giving the student model enough capacity and difficult environments
- want the student to be better than the teacher
方法
- algorithm
- train teacher use labeled images
- use teacher to inference unlabedled images, generating pseudo labels, soft/one-hot
- train student model use labeled & unlabeld images
- make student the new teacher, jump to the inter step
- noise
- enforcing invariances:要求student网络能够对各种增强后的数据预测label一样,ensure consistency
- required to mimic a more powerful ensemble model:teacher网络在inference阶段进行dropout和stochastic depth,behaves like an ensemble,whereas the student behaves like a single model,这就push student网络去学习一个更强大的模型
- other techniques
- data filtering
- we filter images that the teacher model has low confidences
- 这部分data与training data的分布范围内
- data balancing
- duplicate images in classes where there are not enough images
- take the images with the highest confidence when there are too many
- data filtering
- soft/hard pseudo labels
- both work
- soft slightly better
- algorithm
实验
- dataset
- benchmarked dataset:ImageNet 2012 ILSVRC
- unlabeled dataset:JFT
- fillter & balancing:
- use EfficientNet-B0
- trained on ImageNet,inference over JFT
- take images with confidence over 0.3
- 130M at most per class
- models
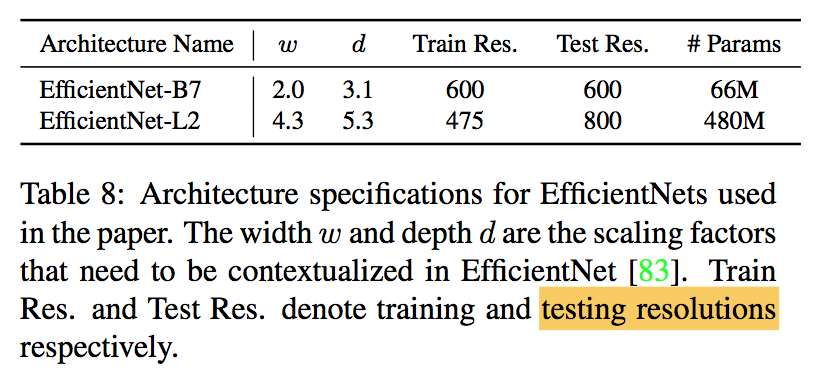
- EfficientNet-L2
- further scale up EfficientNet-B7
- wider & deeper
- lower resolution
- train-test resolution discrepancy
- first perform normal training with a smaller resolution for 350 epochs
- then finetune the model with a larger resolution for 1.5 epochs on unaugmented labeled images
- shallow layers are fixed during finetuning
- noise
- stochastic depth:stochastic depth 0.8 for the final layer and follow the linear decay rule for other layers
- dropout:dropout 0.5 for the final layer
- RandAugment:two random operations with magnitude set to 27
- EfficientNet-L2
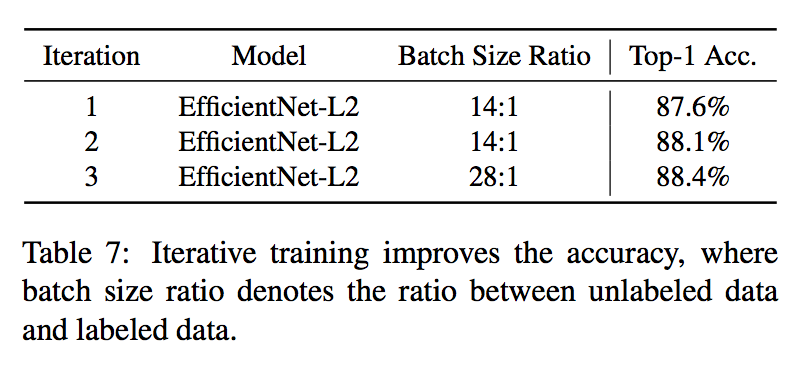
iterative training
- 【teacher】first trained an EfficientNet-B7 on ImageNet
- 【student】then trained an EfficientNet-L2 with the unlabeled batch size set to 14 times the labeled batch size
- 【new teacher】trained a new EfficientNet-L2
- 【new student】trained an EfficientNet-L2 with the unlabeled batch size set to 28 times the labeled batch size
- 【iteration】…
robustness test
- difficult images
common corruptions and perturbations

FGSM attack
metrics
- improves the top-1 accuracy
reduces mean corruption error (mCE)
reduces mean flip rate (mFR)
ablation study
- noisy
- 如果不noise the student,当student model的预测和teacher预测的unlabeled数据完全一样的情况下,loss为0,不再学习,这样student就不能outperform teacher了
- injecting noise to the student model enables the teacher and the student to make different predictions
- The student performance consistently drops with noise function removed
- removing noise leads to a smaller drop in training loss,说明noise的作用不是为了preventing overfitting,就是为了enhance model
- iteration
- iterative training is effective in producing increas- ingly better models
- larger batch size ratio for latter iteration
- noisy
- dataset