- summary
- 使用complement loss的主要动机是one-hot的label下,ce只关注拉高正样本概率,丧失掉了其他incorrect类别的信息
- 事实上对于incorrect类别,可以让其输出概率值分布的熵尽可能的大——也就是将这个分布尽可能推向均匀分布,让它们之间互相遏制从而凸显出ground truth的概率
- 但这是建立在“各个标签之间相互独立”这个假设上,如果类别间有hierarchical的关系/multi-label,就不行了。
- 在数学表达上,
- 首先仍然是用ce作用于correct label,希望正样本概率gt_pred尽可能提高,接近真实值
- 然后是作用于incorrect label的cce,在除了正例pred possibility以外的几个概率上,计算交叉熵,希望这几个概率尽可能服从均匀分布,概率接近$\frac{1-gt_pred}{K-1}$
- 我感觉这就是label smoothing,主要区别就是cce上有个norm项,label smoothin在计算ce的时候,vector中每一个incorrect label的熵都与correct label等权重,cce对整个incorrect vector的权重与correct label等同,且可以调整。
Imbalanced Image Classification with Complement Cross Entropy
动机
- class-balanced datasets
- motivated by COT(complement objective training)
- suppressing softmax probabilities on incorrect classes during training
- propose cce
- keep ground truth probability overwhelm the other classes
- neutralizing predicted probabilities on incorrect classes
论点
- class imbalace
- limits generalization
- resample
- oversampling on minority classes
- undersampling on majority classes
- reweight
- neglect the fact that samples on minority classes may have noise or false annotations
- might cause poor generalization
- observed degradation in imbalanced datasets using CE
- cross entropy mostly ignores output scores on wrong classes
- neutralizing predicted probabilities on incorrect classes helps improve accuracy of prediction for imbalanced image classification
- class imbalace
方法
complement entropy
- calculated on incorrect classes
- N samples,K-dims class vector
- $C(y,\hat y)=-\frac{1}{N}\sum_{i=1}^N\sum_{j=1,j \neq g}^K \frac{\hat y^j}{1-\hat y^g}log\frac{\hat y^j}{1-\hat y^g} $
- the purpose is to encourage larger gap between ground truth and other classes —— when the incorrect classes obey normal distribution it reaches optimal
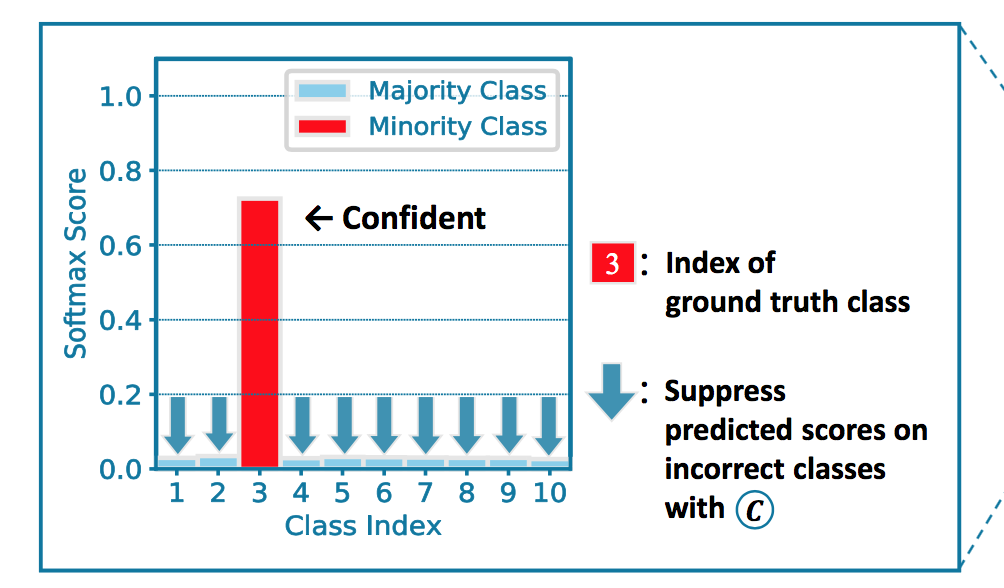
balanced complement entropy
- add balancing factor
- $C^{‘}(y,\hat y) = \frac{1}{K-1}C(y,\hat y)$
forming COT:

- twice back-propagation per each iteration
- first cross entropy
- second complement entropy
- twice back-propagation per each iteration
CCE (Complement Cross Entropy)
- add modulating factor:$\tilde C(y, \hat y) = \frac{\gamma}{K-1}C(y, \hat y)$,$\gamma=-1$
- combination:CE+CCE
实验
dataset:
- cifar
- class-balanced originally
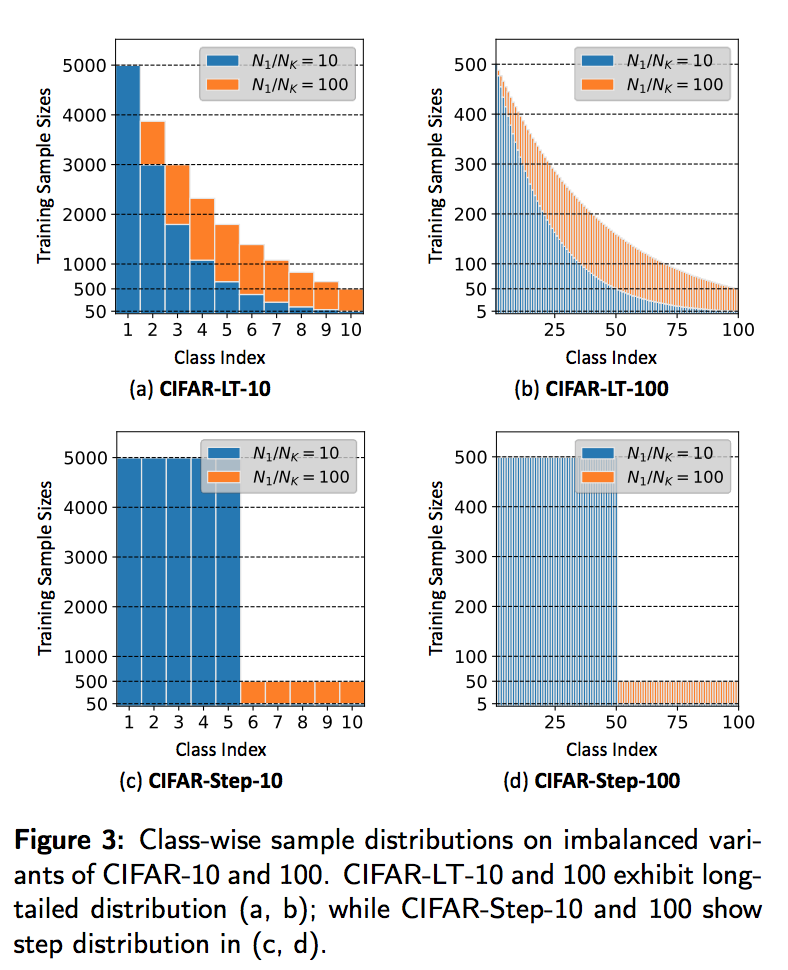
- construct imbalanced variants with imbalance ratio $\frac{N_{min}}{N_{max}}$
test acc
- 论文的实验结果都是在cifar上cce好于cot好于focal loss,在road上cce好于cot,没放fl
- 咱也不知道。。。